本系列用于Bert模型实践实际场景,分别包括分类器、命名实体识别、选择题、文本摘要等等。(关于Bert的结构和详细这里就不做讲解,但了解Bert的基本结构是做实践的基础,因此看本系列之前,最好了解一下transformers和Bert等)
本篇主要讲解情感分类应用场景。本系列代码和数据集都上传到GitHub上:https://github.com/forever1986/bert_task
目录
- 1 环境说明
- 2 前期准备
- 2.1 了解Bert的输入输出
- 2.2 数据集与模型
- 2.3 任务说明
- 2.4 实现关键
- 3 关键代码
- 3.1 数据集处理
- 3.2 模型加载
- 3.3 评估函数
- 4 整体代码
- 5 运行效果
1 环境说明
1)本次实践的框架采用torch-2.1+transformer-4.37
2)另外还采用或依赖其它一些库,如:evaluate、pandas、datasets、accelerate等
2 前期准备
Bert模型是一个只包含transformer的encoder部分,并采用双向上下文和预测下一句训练而成的预训练模型。可以基于该模型做很多下游任务。
2.1 了解Bert的输入输出
Bert的输入:input_ids(使用tokenizer将句子向量化),attention_mask,token_type_ids(句子序号)、labels(结果)
Bert的输出:
last_hidden_state:最后一层encoder的输出;大小是(batch_size, sequence_length, hidden_size)
pooler_output:这是序列的第一个token(classification token)的最后一层的隐藏状态,输出的大小是(batch_size, hidden_size),它是由线性层和Tanh激活函数进一步处理的。(通常用于句子分类,至于是使用这个表示,还是使用整个输入序列的隐藏状态序列的平均化或池化,视情况而定)。(注意:这是关键输出,本次分类任务就需要获取该值,并进行一次线性层处理)
hidden_states: 这是输出的一个可选项,如果输出,需要指定config.output_hidden_states=True,它也是一个元组,它的第一个元素是embedding,其余元素是各层的输出,每个元素的形状是(batch_size, sequence_length, hidden_size)
attentions:这是输出的一个可选项,如果输出,需要指定config.output_attentions=True,它也是一个元组,它的元素是每一层的注意力权重,用于计算self-attention heads的加权平均值。
2.2 数据集与模型
1)数据集:weibo_senti_100k(微博公开数据集),这里只是演示,使用其中2400条数据
2)模型:bert-base-chinese
注意:本次练习都是采用本地数据集和本地权重模型,不直接从hf下载,因为速度过慢
2.3 任务说明
情感分类任务其实就是将输出的结果映射到一个0或者1的标签上
2.4 实现关键
由于我们是判断整个句子的分类,因此需要的是输出序列的第一个token(参考Bert的输入输出),也就是pooler_output。将pooler_output输出转化为我们所需要的label值,因此需要 一个线性层实现(这一步下面我们利用transformers框架帮我们实现好的类)
3 关键代码
3.1 数据集处理
weibo_senti_100k是一个有2列数据分别label,review,其中label是结果,review则是input。我们需要做3个事情:读取数据、划分数据集、tokenizer
# 读取数据集
df = pd.read_csv(data_path)
dataset = load_dataset("csv", data_files=data_path, split='train')
dataset = dataset.filter(lambda x: x["review"] is not None)
# 划分数据集
datasets = dataset.train_test_split(test_size=0.1)
# 数据集进行tokenizer
def process_function(datas):
tokenized_datas = tokenizer(datas["review"], max_length=256, truncation=True)
tokenized_datas["labels"] = datas["label"]
return tokenized_datas
tokenized_datasets = datasets.map(process_function, batched=True, remove_columns=datasets["train"].column_names)
3.2 模型加载
model = BertForSequenceClassification.from_pretrained(model_path, num_labels=2)
注意:这里使用的是transformers中的BertForSequenceClassification,该类对bert的分类进行封装。如果我们不使用该类,需要自己定义一个model,继承bert,增加分类线性层(就是2.4中提到的实现关键)。另外使用AutoModelForSequenceClassification也可以,其实AutoModel最终返回的也是BertForSequenceClassification,它是根据你config中的model_type去匹配的。
这里列一下BertForSequenceClassification的关键源代码说明一下transformers帮我们做了哪些关键事情
# 在__init__方法中增加dropout和分类线性层
self.dropout = nn.Dropout(classifier_dropout)
# 注意此处的num_labels可以在config中配置(使用标签:id2label),或者在from_pretrained传入,默认是2,当多分类的时候可以自己定义
self.classifier = nn.Linear(config.hidden_size, config.num_labels)
# 在forward方法中,将bert输出outputs中的第二个值(也就是前面讲到的pooler_output),进行dropout处理并关联线性层
pooled_output = outputs[1]
pooled_output = self.dropout(pooled_output)
logits = self.classifier(pooled_output)
3.3 评估函数
这里采用evaluate库加载accuracy准确度计算方式来做评估,本次实验将accuracy的计算py文件下载下来,因此也是本地加载
# 评估函数:此处的评估函数可以从https://github.com/huggingface/evaluate下载到本地
acc_metric = evaluate.load("./evaluate/metric_accuracy.py")
def evaluate_function(prepredictions):
predictions, labels = prepredictions
predictions = predictions.argmax(axis=1)
acc = acc_metric.compute(predictions=predictions, references=labels)
return acc```
## 3.4 设置TrainingArguments
```python
# step 5 创建TrainingArguments
# 2400条数据,其中train和test比例9:1,因此train数据为2160条,batch_size=32,因此step=68,
train_args = TrainingArguments(output_dir="./checkpoints", # 输出文件夹
per_device_train_batch_size=32, # 训练时的batch_size
# gradient_accumulation_steps=2, # *** 因为显存够用,本次实验没有使用梯度累积 ***
gradient_checkpointing=True, # *** 梯度检查点 ***
per_device_eval_batch_size=32, # 验证时的batch_size
num_train_epochs=3, # 训练轮数
logging_steps=20, # log 打印的频率
evaluation_strategy="epoch", # 评估策略
save_strategy="epoch", # 保存策略
save_total_limit=3, # 最大保存数
learning_rate=2e-5, # 学习率
weight_decay=0.01, # weight_decay
metric_for_best_model="accuracy", # 设定评估指标
load_best_model_at_end=True) # 训练完成后加载最优模型
4 整体代码
"""
基于BERT做情感分析
1)数据集来自:weibo_senti_100k(微博公开数据集),这里只是演示,使用2400条数据
2)模型权重使用:bert-base-chinese
"""
# step 1 引入数据库
import evaluate
import pandas as pd
from datasets import load_dataset
from transformers import BertTokenizer, BertForSequenceClassification, TrainingArguments, Trainer, \
DataCollatorWithPadding, pipeline
model_path = "./model/tiansz/bert-base-chinese"
data_path = "./data/weibo_senti_100k.csv"
# step 2 数据集处理
df = pd.read_csv(data_path)
dataset = load_dataset("csv", data_files=data_path, split='train')
dataset = dataset.filter(lambda x: x["review"] is not None)
datasets = dataset.train_test_split(test_size=0.1) # 划分数据集
print("train data size:", len(datasets["train"]["label"]))
tokenizer = BertTokenizer.from_pretrained(model_path)
def process_function(datas):
tokenized_datas = tokenizer(datas["review"], max_length=256, truncation=True)
tokenized_datas["labels"] = datas["label"]
return tokenized_datas
new_datasets = datasets.map(process_function, batched=True, remove_columns=datasets["train"].column_names)
# step 3 加载模型
model = BertForSequenceClassification.from_pretrained(model_path, num_labels=2)
# step 4 评估函数:此处的评估函数可以从https://github.com/huggingface/evaluate下载到本地
acc_metric = evaluate.load("./evaluate/metric_accuracy.py")
def evaluate_function(prepredictions):
predictions, labels = prepredictions
predictions = predictions.argmax(axis=1)
acc = acc_metric.compute(predictions=predictions, references=labels)
return acc
# step 5 创建TrainingArguments
# 2400条数据,其中train和test比例9:1,因此train数据为2160条,batch_size=32,每个epoch的step=68,epoch=3,因此总共step=204,
train_args = TrainingArguments(output_dir="./checkpoints", # 输出文件夹
per_device_train_batch_size=32, # 训练时的batch_size
# gradient_accumulation_steps=2, # *** 梯度累加 ***
gradient_checkpointing=True, # *** 梯度检查点 ***
per_device_eval_batch_size=32, # 验证时的batch_size
num_train_epochs=3, # 训练轮数
logging_steps=20, # log 打印的频率
evaluation_strategy="epoch", # 评估策略
save_strategy="epoch", # 保存策略
save_total_limit=3, # 最大保存数
learning_rate=2e-5, # 学习率
weight_decay=0.01, # weight_decay
metric_for_best_model="accuracy", # 设定评估指标
load_best_model_at_end=True) # 训练完成后加载最优模型
# step 6 创建Trainer
trainer = Trainer(model=model,
args=train_args,
train_dataset=new_datasets["train"],
eval_dataset=new_datasets["test"],
data_collator=DataCollatorWithPadding(tokenizer=tokenizer),
compute_metrics=evaluate_function,
)
# step 7 训练
trainer.train()
# step 8 模型评估
evaluate_result = trainer.evaluate(new_datasets["test"])
print(evaluate_result)
# step 9:模型预测
id2_label = {0: "消极", 1: "积极"}
model.config.id2label = id2_label
pipe = pipeline("text-classification", model=model, tokenizer=tokenizer)
sen = "不止啦,金沙 碧水 翠苇 飞鸟 游鱼 远山 彩荷七大要素哒"
print(pipe(sen))
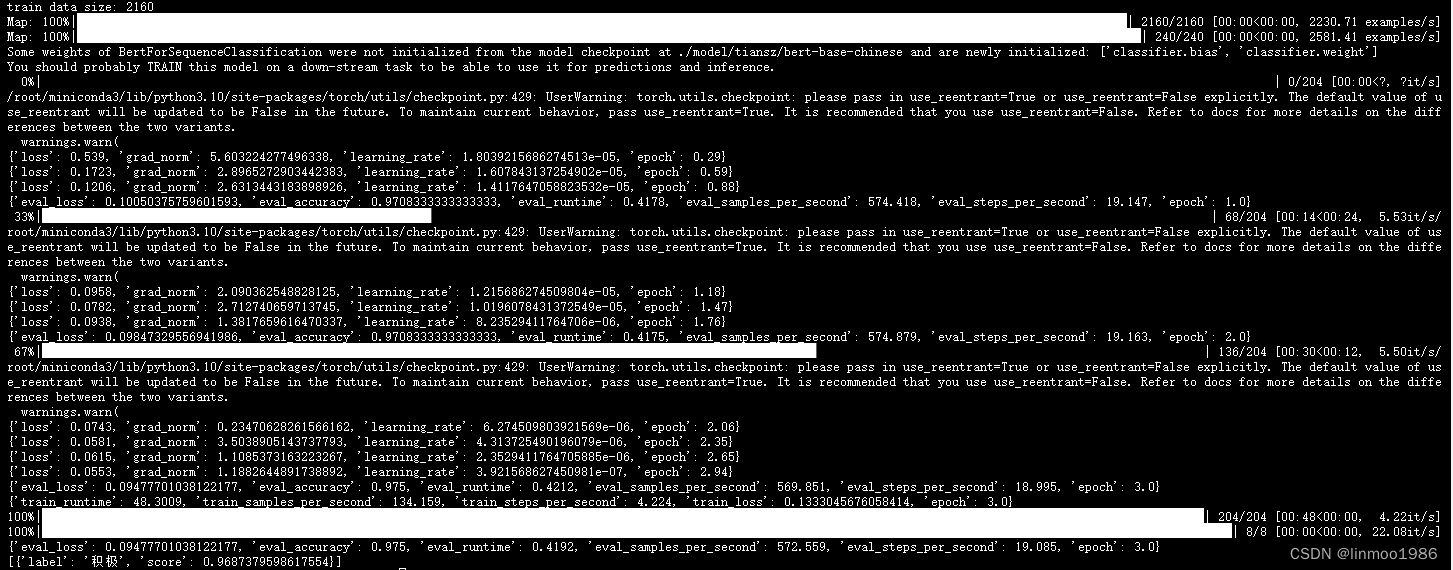
5 运行效果
注:本文参考来自大神:https://github.com/zyds/transformers-code