文章目录
- 前言
- 二叉树的递归遍历
- 💖递归算法基本要素
- 代码
- 迭代遍历-需要先理清思路再写
- 前向迭代法
- 后序迭代
- 中序迭代
- 迭代法统一写法
- 总结
前言
理论基础
需要了解 二叉树的种类,存储方式,遍历方式 以及二叉树的定义
记录我容易忘记的点

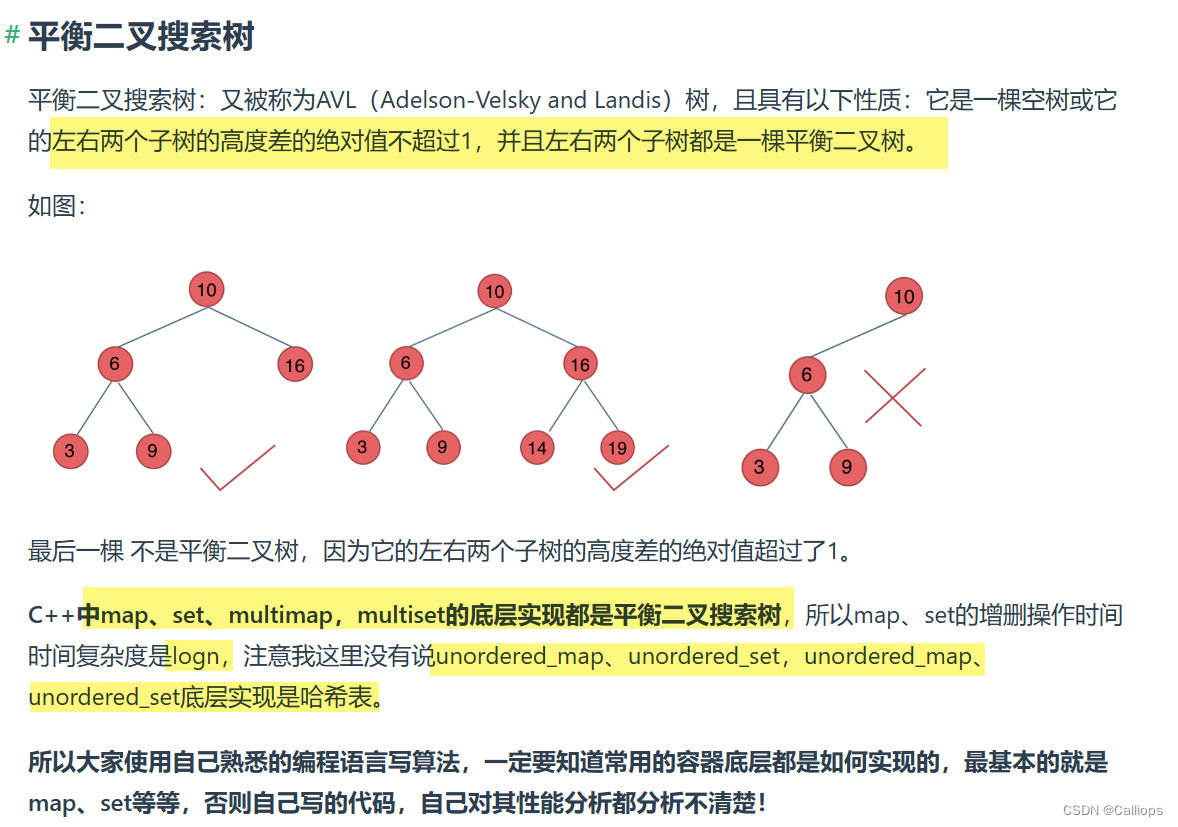
题目一半都是用链式存储来做,但是可以稍微了解一下顺序存储
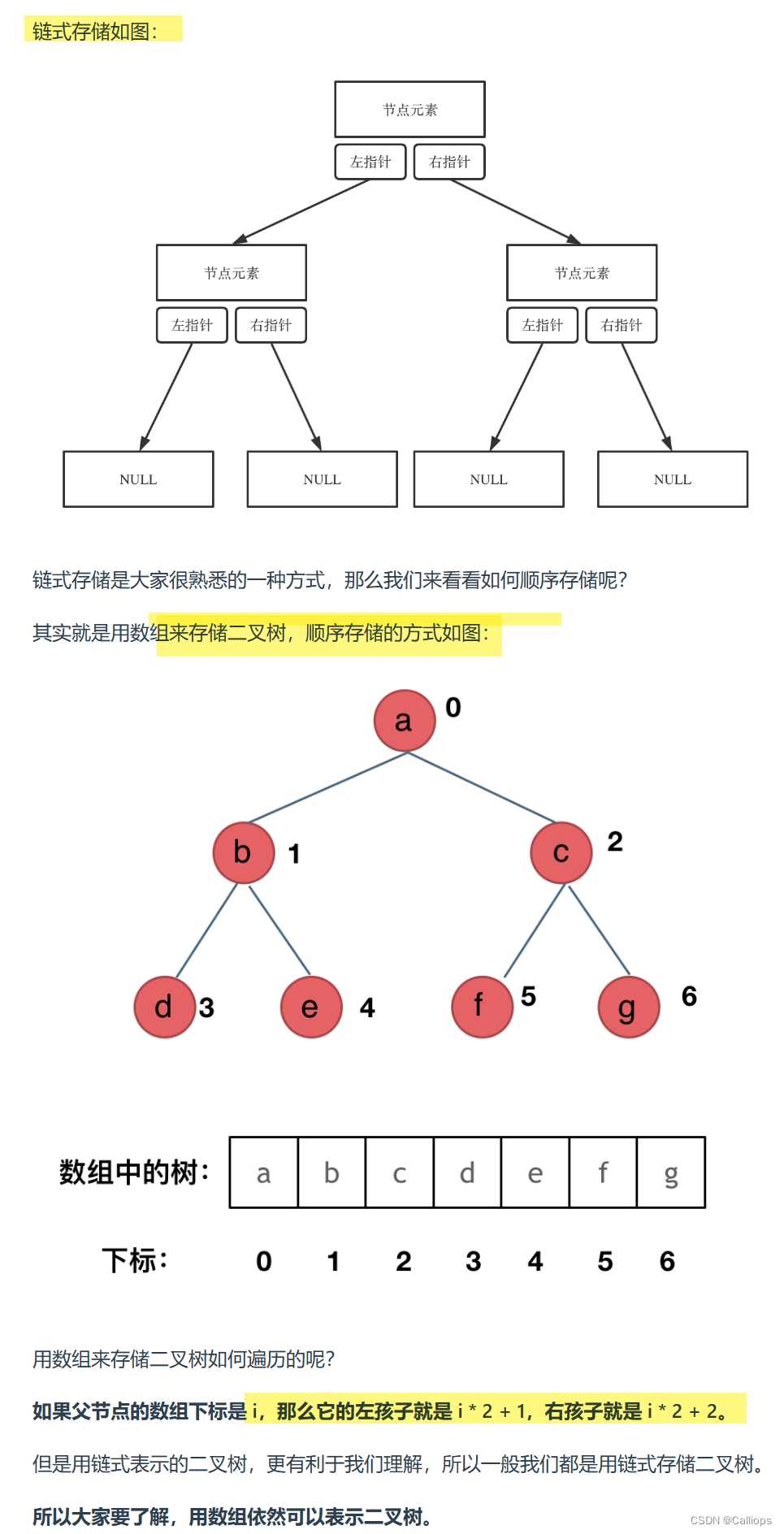
定义的代码


二叉树的递归遍历
前中后分别对应力扣的144,94,145
💖递归算法基本要素
这个主要用于打基础,后面所有二叉树的题目都需要用这个来做。
这里帮助大家确定下来递归算法的三个要素。每次写递归,都按照这三要素来写,可以保证大家写出正确的递归算法!
确定递归函数的参数和返回值: 确定哪些参数是递归的过程中需要处理的,那么就在递归函数里加上这个参数, 并且还要明确每次递归的返回值是什么进而确定递归函数的返回类型。
确定终止条件: 写完了递归算法, 运行的时候,经常会遇到栈溢出的错误,就是没写终止条件或者终止条件写的不对,操作系统也是用一个栈的结构来保存每一层递归的信息,如果递归没有终止,操作系统的内存栈必然就会溢出。
确定单层递归的逻辑: 确定每一层递归需要处理的信息。在这里也就会重复调用自己来实现递归的过程。
代码
dfs函数可以写在里面,不用额外写一个self.dfs在外面
class Solution(object):
def preorderTraversal(self, root):
"""
:type root: TreeNode
:rtype: List[int]
"""
vec = []
def dfs(node):
if not node:
return
vec.append(node.val)
dfs(node.left)
dfs(node.right)
dfs(root)
return vec
def inorderTraversal(self, root):
"""
:type root: TreeNode
:rtype: List[int]
"""
vec = []
def dfs(node):
if not node:
return
dfs(node.left)
vec.append(node.val)
dfs(node.right)
dfs(root)
return vec
def postorderTraversal(self, root):
"""
:type root: TreeNode
:rtype: List[int]
"""
vec = []
def dfs(node):
if not node:
return
dfs(node.left)
dfs(node.right)
vec.append(node.val)
dfs(root)
return vec
迭代遍历-需要先理清思路再写
为什么有了递归还要迭代:因为面试的时候有可能会问你能不能用除了递归别的方法。
递归的实现就是:每一次递归调用都会把函数的局部变量、参数值和返回地址等压入调用栈中,然后递归返回的时候,从栈顶弹出上一次递归的各项参数,所以这就是递归为什么可以返回上一层位置的原因。
此时大家应该知道我们用栈也可以是实现二叉树的前后中序遍历了。【看动图过程】
前向迭代法
根左右
首先根节点入栈,然后紧跟着弹出给到result数组里面,然后压入右节点和左【先右再左是为了出栈顺序是左右】
- 也就是压入一个根节点之后,弹出,紧跟着再压入它的左右两个节点;到下一轮循环里面,弹出根节点,然后再压入它的右左节点;
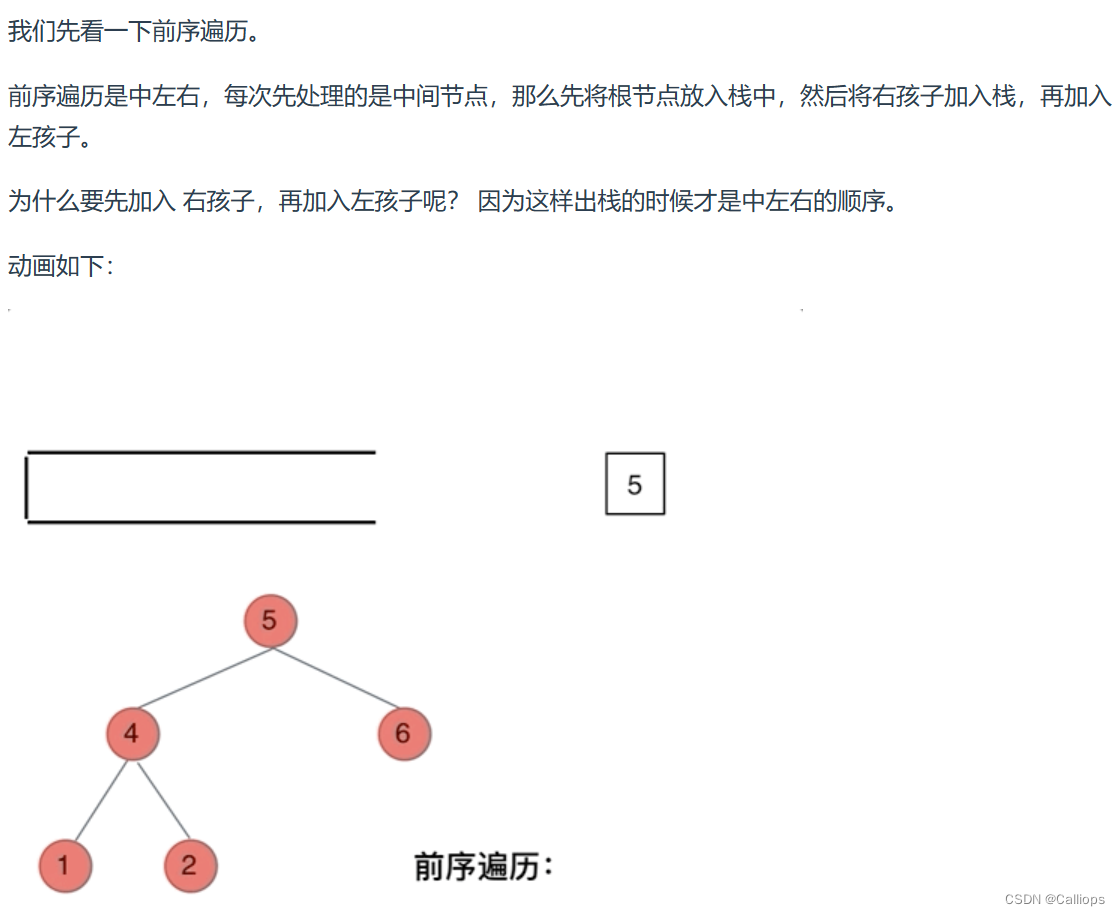

if not root: return : 这一行代码不要忘了,有可能传入的root是空的。
def preorderTraversal(self, root):
"""
:type root: TreeNode
:rtype: List[int]
"""
# 非迭代法
if not root: return
result = []
stack =[root]
while stack:#如果还有节点:
node = stack.pop()
result.append(node.val)
if node.right:
stack.append(node.right)
if node.left:
stack.append(node.left)
return result
后序迭代
左右根

只需要对先序做两个调整:交换左右,reverse result数组
def postorderTraversal(self, root):
"""
:type root: TreeNode
:rtype: List[int]
"""
# 代法
if not root: return
result = []
stack =[root]
while stack:#如果还有节点:
node = stack.pop()
result.append(node.val)
if node.left:
stack.append(node.left)
if node.right:
stack.append(node.right)
return result[::-1]
中序迭代
思路:根节点一路压栈,知道左节点为空之后,弹出该节点【已经判断了左(为空)和中(弹出)】,然后判断右节点,不为空就压入右节点,判断这个右节点;为空的话就弹出栈口的节点,再判断新弹出的右节点是否为空;
- 左节点为空之后,就从栈弹出中间节点然后判断右节点【从栈顶弹出的元素是最近访问的元素 】
具体实现:加了一个指针curr

错的地方都写了注释
# 中序遍历-迭代-LC94_二叉树的中序遍历
class Solution:
def inorderTraversal(self, root: TreeNode) -> List[int]:
if not root:#这个别忘了
return []
stack = [] # 不能提前将root结点加入stack中
result = []
cur = root
while cur or stack:#如果cur和stack都是空的话
# 先迭代访问最底层的左子树结点
if cur:
stack.append(cur)#压入的是node啊,别写成val了
cur = cur.left
# 到达最左结点后处理栈顶结点
else:
cur = stack.pop()
result.append(cur.val)
# 取栈顶元素右结点
cur = cur.right
return result
迭代法统一写法
没看。carl说这个思路有点抽象,而且面试的时候很难一下子写对,就算了吧。我也没看懂。。。。
总结
晚上无论如何也要把实习简历写一半。所以不磕了