文章目录
- opencv
- rectangle
- circle
- 保存图像
- PIL
- resize
- 与Opencv的互操作
- torch
- tensor的创建和定义
- Torch的自动梯度计算
- Torch的模块
- torch的训练流程
opencv
- plt.imshow 以RGB形式显示
- cv2.imread 读取的是BGR
import cv2
image = cv2.imread('image.png') #加载图像
print(image.shape, image.dtype, type(image))
# (528, 604, 3), dtype('uint8'), numpy.ndarray
plt.imshow(image[:, :, [2, 1, 0]]) # 利用了numpy的选择功能实现BGR和RGB对调
hsv = cv2.cvtColor(image, cv2.COLOR_BGR2HSV) #
plt.imshow(hsv)
plt.show()
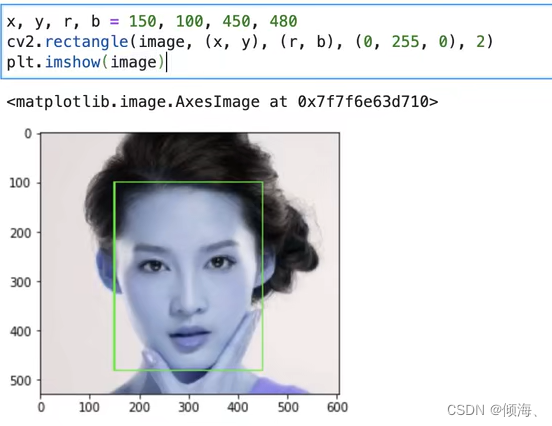
rectangle
circle
circle(img, center, radius, color[, thickness[, lineType[, shift ] ] ])
x, y = 230, 270
cv2.circle(image, (x, y), 16, (0, 0, 255), -1, lineType=16)
保存图像
cv2.imwrite('image_change.png', image)
PIL
Python标准图像处理库
from PIL import Image
img = Image.open('image.png')
plt.imshow(img)
print(type(img)) # PIL.PngImagePlugin.PngImageFile
resize
resized = img.resize((600, 300))
与Opencv的互操作
cv_img = cv2.imread('image.png')
pil_img = Image.fromarray(cv_img)
plt.imshow(pil_img)
torch
numpy重点在cpu,而torch重点在gpu
import torch
tensor的创建和定义
tensor(data, dtype=None, device=None, requires_grad=False, pin_memory=False)
a = torch.tensor([1, 2, 3], dtype=torch.float32)
print(a, a.shape, a.dtype)
# tensor([1., 2., 3.]) torch.Size([3]) torch.float32
a = torch.zeros((3, 3))[.long(), float(), ...]
a = torch.tensor([[2, 3, 2], [2, 2, 1]]).float()
a = torch.rand((3, 3))
a = torch.ones((3, 3))
a = torch.eye(3, 3) #单位阵
k = a[None, :, :, None]
u = k.squeeze() # 去掉为1的维度
l = u.unsqueeze(2) # 增加维度
Torch的自动梯度计算
a = torch.tensor(10.,requires_grad=True)
b = torch.tensor(5.,requires_grad=True)
c = a * (b * 1.5)
c.backward()
print(a.grad, b.grad)
Torch的模块
import torch.nn as nn
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.conv1 = nn.Conv2d(3, 64, 3)
self.relu1 = nn.ReLU(True)
def forward(self, x):
self.conv1(x)
self.relu1(x)
return x
model = Model()
dir(model)
['T_destination', '__annotations__', '__call__', '__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattr__', '__getattribute__', '__getstate__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__setstate__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__', '_apply', '_backward_hooks', '_backward_pre_hooks', '_buffers', '_call_impl', '_compiled_call_impl', '_forward_hooks', '_forward_hooks_always_called', '_forward_hooks_with_kwargs', '_forward_pre_hooks', '_forward_pre_hooks_with_kwargs', '_get_backward_hooks', '_get_backward_pre_hooks', '_get_name', '_is_full_backward_hook', '_load_from_state_dict', '_load_state_dict_post_hooks', '_load_state_dict_pre_hooks', '_maybe_warn_non_full_backward_hook', '_modules', '_named_members', '_non_persistent_buffers_set', '_parameters', '_register_load_state_dict_pre_hook', '_register_state_dict_hook', '_replicate_for_data_parallel', '_save_to_state_dict', '_slow_forward', '_state_dict_hooks', '_state_dict_pre_hooks', '_version', '_wrapped_call_impl', 'add_module', 'apply', 'bfloat16', 'buffers', 'call_super_init', 'children', 'compile', 'conv1', 'cpu', 'cuda', 'double', 'dump_patches', 'eval', 'extra_repr', 'float', 'forward', 'get_buffer', 'get_extra_state', 'get_parameter', 'get_submodule', 'half', 'ipu', 'load_state_dict', 'modules', 'named_buffers', 'named_children', 'named_modules', 'named_parameters', 'parameters', 'register_backward_hook', 'register_buffer', 'register_forward_hook', 'register_forward_pre_hook', 'register_full_backward_hook', 'register_full_backward_pre_hook', 'register_load_state_dict_post_hook', 'register_module', 'register_parameter', 'register_state_dict_pre_hook', 'relu1', 'requires_grad_', 'set_extra_state', 'share_memory', 'state_dict', 'to', 'to_empty', 'train', 'training', 'type', 'xpu', 'zero_grad']
for name, layer in model._modules.items():
print(name, layer)
model.state_dict() # 模型中的参数状态
conv1_weight = model.state_dict()['conv1.weight']
print(conv1_weight.shape) # torch.Size([64, 3, 3, 3])
torch的训练流程
- 定义数据集Dataset
import torchvision.transforms.functional as T
class MyDataset:
def __init__(self, directory):
self.directory = directory
self.files = load_files(directory)
def __len__(self):
return len(self.files)
def __getitem__(self, index):
return T.to_tensor(image), label
dataset = MyDataset()
dataset_length = len(dataset)
dataset_item = dataset[10]
- 定义模型结构
import torch.nn as nn
class ResNet18(nn.Module):
def __init__(self, num_classes):
super(ResNet18, self).__init__()
# 定义每个层的信息
self.conv1 = nn.Conv2d(3, self.inplanes, kernel_size=7, stride=2, padding=3)
self.bn1 = norm_layer(self.inplanes)
# ...省略
self.fc = nn.Linear(512 * block.expansion, num_classes)
def forward():
x = self.conv1(x)
x = self.bn1(x)
...
x = x.reshape(x.size(0), -1)
x = self.fc(x)
return x
def __call__(self, x):
return forward(x) #model(image)类似这样执行
- 定义Dataset实例和DataLoader实例
train_dataset = MyDataset("./train")
train_dataloader = DataLoader(dataset=train_dataset, batch_size=64, shuffle=True,num_workers=24)
# DataLoader实现了多进程数据并行加载
# window下num_workers=0最好给0,支持不好 linux正常
- 定义模型实例
model = ResNet18(1000)
model.cuda() # 转到cuda
- 定义loss函数
loss_function = nn.CrossEntropyLoss() #交叉熵损失
---------
predict = torch.tensor([0.1, 0.1, 0.5]).requires_grad_(True)
ground_thruth_one_hot = torch.tensor([0, 0, 1])
loss2 = -torch.sum(torch.log(torch.softmax(predict, 1)[ground_thruth_one_hot > 0]))
loss2.backward()
predict.grad
- 定义优化器optimizer
op = torch.optim.SGD(model.parameters(), lr=1e-3, momentum=0.9, weight_decay=1e-5)
- 循环执行优化过程
lr_schedule = {
10: 1e-4
20: 1e-5
}
total_epoch = 30
for epoch in range(total_epoch):
if epoch in lr_schedule:
new_lr = lr_schedule[epoch]
for param_group in op.param_groups:
param_group['lr'] = new_lr
for index_batch, (images, labels) in enumerate(train_dataloader):
# images.shape 64, 3, 300, 300
# labels.shape 64, 1
# 数据转到cuda
images = images.cuda()
labels = labels.cuda()
output = model(images)
loss = loss_function(output,labels)
# 优化三部曲
# 1、梯度清空
op.zero_grad()
# 2、loss函数反向传播
loss.backward()
# 3、应用梯度并进行更新
op.step()
print('epoch: {}, loss:{}'.format(epoch, loss.item()))
- 模型的测试
model = ResNet18(1000)
model.cuda()
model.eval() # 进入评估模式
trans = torchvision.transforms.Compose([
torchvision.transforms.Resize(256),
torchvision.transforms.ToTensor(),
torchvision.Normalize([0.485,0.456,0.406][0.229,0.224,0.225])
])
# 禁止模型执行过程中为计算梯度而使用更多显存存储中间过程
with torch.no_grad():
for file in files:
image = cv2.imread(file)
image = trans(image) # 归一化
outputs = model(image)
predict_label = outputs.argmax(dim=1).cpu()
- 模型的保存和加载
torch.save(model.state_dict(), 'my_model.pth')
checkpoint = torch.load('my_model.pth')
model.load_state_dict(checkpoint)