目录
- 前言
- 一、分析前准备
- 1.1、准备测试表和数据
- 1.2、插入测试数据
- 1.3、测试环境说明
- 二、具体业务分析
- 2.1、单次查询耗时分析
- 2.2、无索引并发查询服务器CPU占用率分析
- 2.3、添加索引并发查询服务器CPU占用率分析
- 三、总结
前言
在一次节日活动我们系统访问量到达了平时的两倍,我们线上高峰期数据库CPU使用率从平常的20%左右飙升到了65%左右,数据库用的是阿里云的RDS-MySQL配置是32核 128G,并且为了应对活动我们还开启了SQL洞察(用于分析SQL的执行时间、次数、耗时比等),通过耗时比例能找到一个SQL占用整体耗时比例极高,并且执行次数比例不高,数据扫描行挺高的接近40w,查询调整是没有索引的,但是平均查询耗时在230ms并没有触发我们的慢SQL阈值,从平均查询耗时来看好像没什么问题,但是如果这张表是一张访问频率很高的表,那么问题就大了,最开始这张表预计存储数据量在1k左右,因为后面业务发展表的数据量有所增长,虽然单次查询耗时不高,但是扫描行很高导致CPU使用率飙升,下面开始对数据量很小的表是否有必要添加索引问题分析。
一、分析前准备
1.1、准备测试表和数据
这里准备一个门店信息表。
CREATE TABLE `shop_info` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '门店ID',
`origin_id` varchar(100) DEFAULT NULL COMMENT '门店唯一编号',
`phone` varchar(100) DEFAULT NULL COMMENT '手机号',
`location` varchar(100) DEFAULT NULL COMMENT '门店经纬度',
`city_info` varchar(100) DEFAULT NULL COMMENT '城市信息',
`create_time` bigint(20) DEFAULT NULL COMMENT '创建日期',
`update_time` bigint(20) DEFAULT NULL COMMENT '更新日期',
PRIMARY KEY (`id`)
) ENGINE=InnoDB COMMENT='门店信息表';
1.2、插入测试数据
我这里在表里面插入了1000条数据用于测试,我这里用的MyBatis-Plus只提供核心业务插入代码,有需要自己插入即可。
public void batchInsert(int num) {
ArrayList<ShopInfo> shopInfos = new ArrayList<>();
for (int i = 0; i < num; i++) {
ShopInfo shopInfo = new ShopInfo();
shopInfo.setOriginId(RandomUtil.randomString(20));
shopInfo.setPhone("186"+RandomUtil.randomNumbers(8));
shopInfo.setLocation("114."+RandomUtil.randomNumbers(6)+","+"23."+RandomUtil.randomNumbers(6));
shopInfo.setCityInfo("xxx");
long time = System.currentTimeMillis();
shopInfo.setCreateTime(time);
shopInfo.setUpdateTime(time);
shopInfos.add(shopInfo);
}
this.saveBatch(shopInfos);
}
1.3、测试环境说明
- 服务器:阿里云CentOS7 2核4G
- 数据库:MySQL8.0
- 测试客户端:SpringBoot + MyBatis-Plus + druid
这里测试时我是通过本地直接连接云服务进行的测试,部分耗时可能会高一点。
二、具体业务分析
2.1、单次查询耗时分析
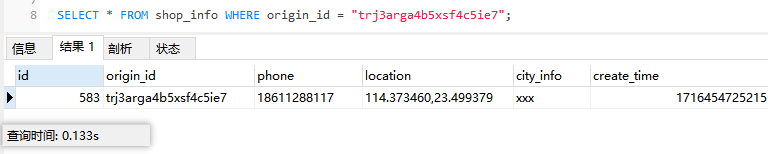
这里我进行了多次查询,每次查询基本上都在0.13s左右,查询响应时间还能接受。
SELECT * FROM shop_info WHERE origin_id = "trj3arga4b5xsf4c5ie7";
2.2、无索引并发查询服务器CPU占用率分析
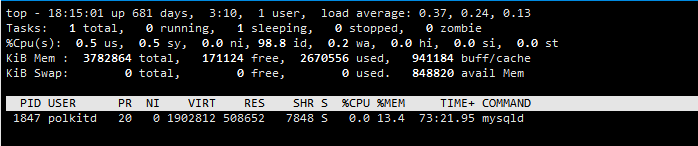
- 1、通过
top -p pid可以看到当前MySQL占用CPU为0
- 2、并发查询测试,这里线程池核心线程数为100,数据源的最大连接数设置的也为100
@Test
public void t1() throws InterruptedException {
// 查询出所有的门店数据用于测试查询
List<ShopInfo> list = shopInfoService.list();
List<String> originIdList = list.stream().map(ShopInfo::getOriginId).collect(Collectors.toList());
long startTime = System.currentTimeMillis();// 开始时间戳
ThreadPoolExecutor executor = new ThreadPoolExecutor(100, 100, 10, TimeUnit.SECONDS, new LinkedBlockingQueue<>());
int num = 10000;
CountDownLatch countDownLatch = new CountDownLatch(num);
for (int i = 0; i <num; i++) {
executor.execute(()->{
ShopInfo shopInfo = shopInfoService.selectByOriginId(originIdList.get(RandomUtil.randomInt(originIdList.size() - 1)));
log.info("shopInfo:{}",shopInfo);
countDownLatch.countDown();
});
}
countDownLatch.await();
executor.shutdown();
long endTime = System.currentTimeMillis();// 结束时间戳
log.info("查询耗时:{}",endTime - startTime);
}
2024-05-23 18:19:25.747 | INFO [ main] com.kerwin.dbshop.ShopInfoTest 63 -| 查询耗时:8669
这里10000次查询耗时8669毫秒。
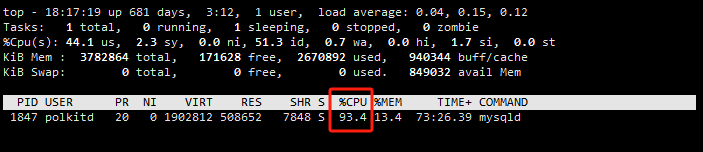
- 3、查询时MySQL占用CPU峰值达到了90%多
2.3、添加索引并发查询服务器CPU占用率分析
这里给origin_id字段添加一个普通索引。
ALTER TABLE `shop_info` ADD INDEX `idx_origin_id`(`origin_id`);
- 1、添加索引后单次查询耗时在0.117s的样子,比不加索引只快了一点,因为数据量比较少单次查询耗时不明显。

- 2、并发查询测试,测试代码和之前一样
2024-05-23 18:30:59.734 | INFO [ main] com.kerwin.dbshop.ShopInfoTest 63 -| 查询耗时:7754
这里不加索引和加索引并发查询耗时其实区别不大,因为数据量比较少,而且MySQL也会将读取出来的数据进行缓存处理,走索引快速定位某一行和全表扫描在我这个测试程序下查询耗时区别很小。
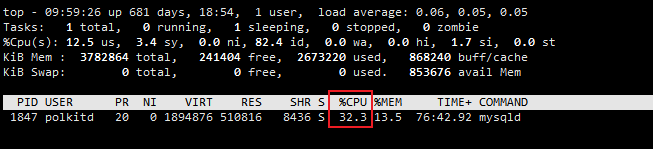
- 3、查询时MySQL占用CPU峰值只有32.3%,相比于不加索引CPU使用率降低了非常多。
三、总结
-
通过上面不太全面的分析,大致可以得出一个结论,被频繁访问的小表如果没有索引,那么高并发查询时CPU使用率会非常高,添加上对应查询索引后CPU使用率下降了非常多。
-
当然并不是所有小表都适合或者说有必要加索引,比如表数据非常少,预计最多几十条添不添加其实没什么差别,就算全表扫描和走索引区别也不大,可以加但是没太大必要,索引查询后还需要根据数据ID进行回表查询,MySQL优化器可能会选择直接进行全表扫描,还有一些情况其实不适合添加索引,比如查询字段为大量重复数据的列,比如状态字段(启用、停用),这种类型的字段区分度不高不适合作为查询的索引,不过也要分业务,在某些时候可能的确需要。
-
再换个思路,一般什么样的表数据量会比较少?一般都是一些配置表、方案表等,而这些类型的表都有一个特点,数据变化不频繁,而数据变化不频繁的配置信息是非常合适添加一个中间缓存的比如Redis,那么就算配置表有1000条数据,那么将活跃数据缓存到Redis中那么流量就不会打到数据库了,那么对于这样的设计,会被频繁访问小表也是可以不用添加索引的。