入坑传送门
赛事介绍
文本匹配拥有广泛的应用场景,可以用于去除重复问题和文本相似度中。在本次学习中我们将学习:
- 如何计算文本之间的统计距离
- 如何训练词向量 & 无监督句子编码
- BERT模型搭建和训练
上述步骤都是一个NLP算法工程师必备的基础,从2023.1.4~2023.2.1,我们将逐步从基础出发,逐步解决文本匹配问题。
背景介绍
文本语义匹配是自然语言处理中一个重要的基础问题,NLP 领域的很多任务都可以抽象为文本匹配任务。例如,信息检索可以归结为查询项和文档的匹配,问答系统可以归结为问题和候选答案的匹配,对话系统可以归结为对话和回复的匹配。语义匹配在搜索优化、推荐系统、快速检索排序、智能客服上都有广泛的应用。如何提升文本匹配的准确度,是自然语言处理领域的一个重要挑战。
信息检索:在信息检索领域的很多应用中,都需要根据原文本来检索与其相似的其他文本,使用场景非常普遍。
新闻推荐:通过用户刚刚浏览过的新闻标题,自动检索出其他的相似新闻,个性化地为用户做推荐,从而增强用户粘性,提升产品体验。
智能客服:用户输入一个问题后,自动为用户检索出相似的问题和答案,节约人工客服的成本,提高效率。
让我们来看一个简单的例子,比较各候选句子哪句和原句语义更相近:
原句:“车头如何放置车牌”
比较句1:“前牌照怎么装”
比较句2:“如何办理北京车牌”
比较句3:“后牌照怎么装”
比较结果:
- 比较句1与原句,虽然句式和语序等存在较大差异,但是所表述的含义几乎相同
- 比较句2与原句,虽然存在“如何” 、“车牌”等共现词,但是所表述的含义完全不同
- 比较句3与原句,二者讨论的都是如何放置车牌的问题,只不过一个是前牌照,另一个是后牌照。二者间存在一定的语义相关性
所以语义相关性,句1大于句3,句3大于句2,这就是语义匹配。
天池比赛🔗
数据集介绍
LCQMC数据集比释义语料库更通用,因为它侧重于意图匹配而不是释义。LCQMC数据集包含 260,068 个带有人工标注的问题对。
- 包含 238,766 个问题对的训练集
- 包含 8,802 个问题对的开发集
- 包含 12,500 个问题对的测试集
LCQMC文本匹配数据集下载🔗
这个数据集的标签是0,1;也就是二分类,比天池的比赛要简单。
评价指标
使用准确率Accuracy来评估,即:
准确率 ( A c c u r a c y ) = 预测正确的条目数 / 预测总条目数 准确率(Accuracy)=预测正确的条目数 / 预测总条目数 准确率(Accuracy)=预测正确的条目数/预测总条目数
也可以使用文本相似度与标签的皮尔逊系数进行评估,不匹配的文本相似度应该更低。
TASK1:数据集读取
train = pd.read_csv('https://mirror.coggle.club/dataset/LCQMC.train.data.zip',
sep='\t', names=['query1', 'query2', 'label'])
valid = pd.read_csv('https://mirror.coggle.club/dataset/LCQMC.valid.data.zip',
sep='\t', names=['query1', 'query2', 'label'])
test = pd.read_csv('https://mirror.coggle.club/dataset/LCQMC.test.data.zip',
sep='\t', names=['query1', 'query2', 'label'])
TASK2:文本数据分析
步骤1:分析赛题文本长度,相似文本对与不相似文本对的文本长度是否存在差异?
① 从train_data取出标签为1的文本对:
② 从train_data取出标签为0的文本对:
③ 比较相似文本对与不相似文本对的长度差(的绝对值)【取的前30对】
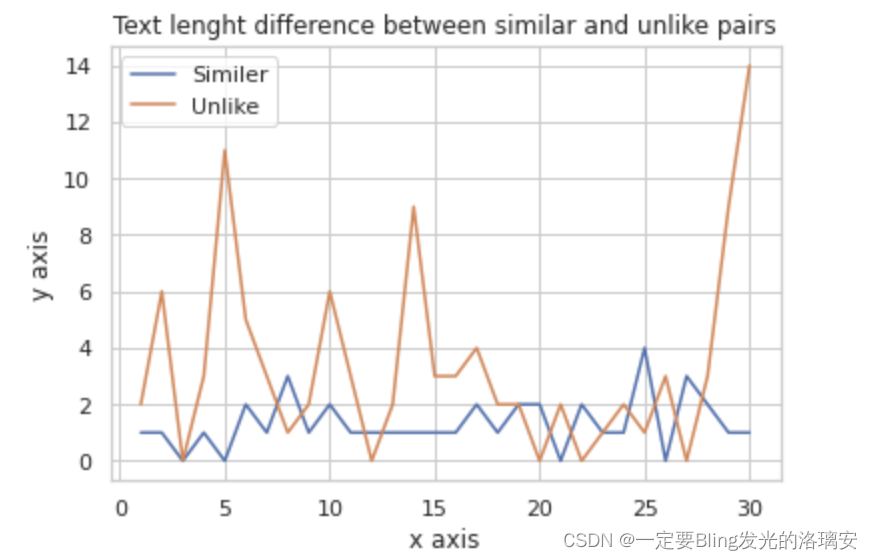
通过上图可以看出大多数不相似文本对的字数差值都在2以上。
步骤2:分析赛题单词和字符个数,在所有文本中包含多少个单词(用jieba进行分析)和字符?

train_data里面有1386901个词(结巴分词之后的结果)
TASK3:文本相似度(统计特征)
步骤1:对query1和query2计算文本统计特征
【query1和query2文本长度差】
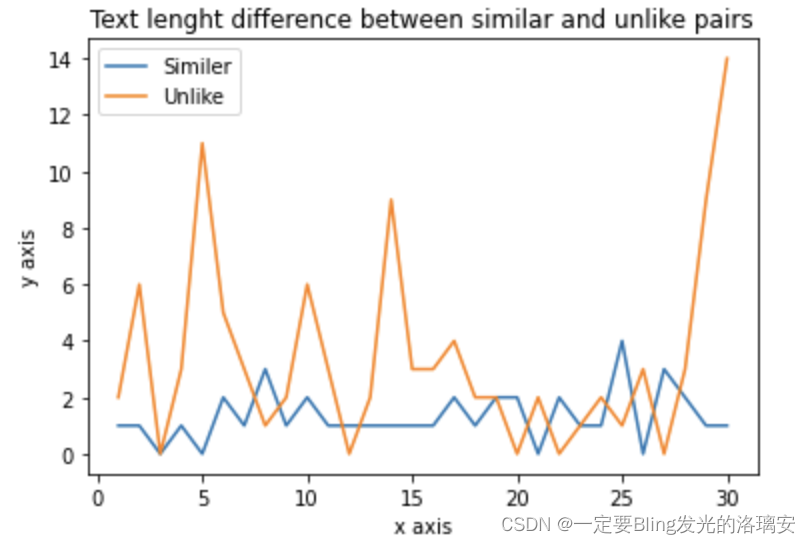
【query1和query2文本单词个数差】
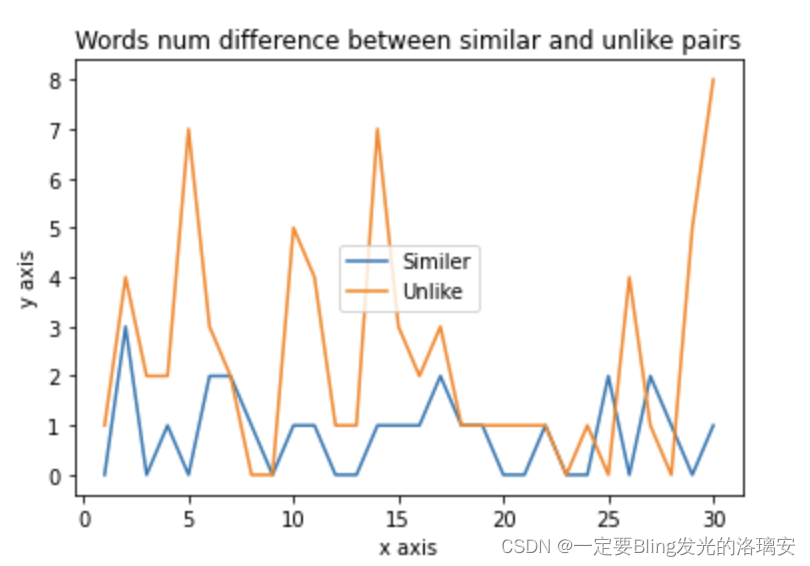
【query1和query2文本单词差异】
相似文本对:
[[‘爱’], [‘手机’, ‘了’, ‘推荐’, ‘我想’, ‘买个’, ‘新手机’, ‘换个’, ‘想’, ‘求’, ‘我’, ‘丢’], [], [‘上’], [‘怎么’, ‘怎样’], [‘的’, ‘是’], [‘一’, ‘名’], [‘的’], [], [‘位’, ‘后位’, ‘是’], [‘能’], [‘呀’, ‘啊’], [], [‘了’], [‘最’, ‘呢’, ‘他’], [‘如何’, ‘能’, ‘怎样’], [‘的’, ‘现’], [‘里’], [‘一个’], [‘这个’, ‘这’], [‘怎么’, ‘怎样’], [‘这是’, ‘是’, ‘什么’, ‘这个’, ‘请问’], [], [‘问’, ‘关于’], [‘设置’, ‘来电’, ‘三星’, ‘安卓’], [‘您’, ‘你’], [‘怎么’], [‘的’, ‘有’, ‘是’], [], [‘叫’, ‘下’, ‘是’, ‘这个’, ‘这’]]
不相似文本对:
[[‘跑’, ‘男’, ‘她’], [‘孕妇’, ‘睡觉’, ‘晚上’, ‘带’, ‘什么’, ‘戴’, ‘着’, ‘有’, ‘害处’, ‘可以’], [‘上’, ‘把’, ‘的’, ‘无线’, ‘和’, ‘带’, ‘该’, ‘设置’, ‘怎样’, ‘到’], [‘的’, ‘胃’, ‘这’, ‘写’], [‘注销’, ‘的’, ‘后’, ‘建议您’, ‘成功’, ‘可以’], [‘还是’, ‘访客’, ‘了’, ‘呢’, ‘失败’, ‘您’, ‘状态’, ‘校验’, ‘您好’], [‘啊’, ‘是’], [‘课’, ‘练习’], [‘好’, ‘前’, ‘送’, ‘时候’], [‘的’, ‘钱’, ‘欲’, ‘指’, ‘买’], [‘都’, ‘啊’, ‘电视剧’, ‘号’, ‘是’, ‘好’, ‘什么’, ‘网站’, ‘电影’, ‘现在’, ‘最近’, ‘哪些’], [‘的’, ‘有’, ‘钻’, ‘帮’, ‘卖’, ‘刷’, ‘是’, ‘你’, ‘烟’], [‘上’, ‘有’, ‘男性’, ‘耳朵’, ‘上长’, ‘看’, ‘面相’, ‘这里’], [‘的’, ‘月初’, ‘延迟’, ‘和’, ‘是’, ‘因’, ‘周日’, ‘会’, ‘不’, ‘月末’, ‘出现’, ‘小’, ‘工作日’, ‘所以’, ‘二’, ‘一下’, ‘情况’, ‘这个’, ‘属于’, ‘周六’], [‘专门’, ‘中’, ‘为’, ‘国内’, ‘有没有’, ‘好’, ‘哪家’, ‘比较’, ‘行业’], [‘用’, ‘上网卡’, ‘和’, ‘上网’], [‘左’, ‘的’, ‘啊’, ‘女’, ‘右’], [‘怎么样’, ‘的’, ‘是’, ‘刘海’, ‘净化器’, ‘这个’, ‘有用吗’], [‘找回’, ‘重置’, ‘怎么’], [‘的’, ‘挂’, ‘才能’], [‘装修’, ‘福州’, ‘转运’], [‘淘’, ‘大限’, ‘微’], [‘几则’, ‘的’, ‘投资’, ‘名人’], [‘的’, ‘里’, ‘主题曲’], [‘宝盖头’, ‘像’, ‘河水’, ‘与’], [‘的’, ‘想’, ‘骨’, ‘我’, ‘什么’, ‘官场’, ‘找’, ‘叫’], [‘哪部’, ‘动漫’, ‘最’, ‘韩剧’, ‘多’, ‘爱情’, ‘日本’], [‘啊’, ‘塞班岛’, ‘在’, ‘辑’, ‘亲有’, ‘哪位’, ‘是’, ‘张图’, ‘哪里’, ‘这’], [‘账户’, ‘通’, ‘就’, ‘麻烦’, ‘我’, ‘银行卡’, ‘添加’, ‘链接’, ‘可以’, ‘看看’], [‘的’, ‘了’, ‘麻烦’, ‘这边’, ‘操作’, ‘是’, ‘新’, ‘商家’, ‘从’, ‘您好’, ‘在’, ‘使用’, ‘红包’, ‘吗’, ‘这个’, ‘可以’, ‘只能’, ‘一下’]]
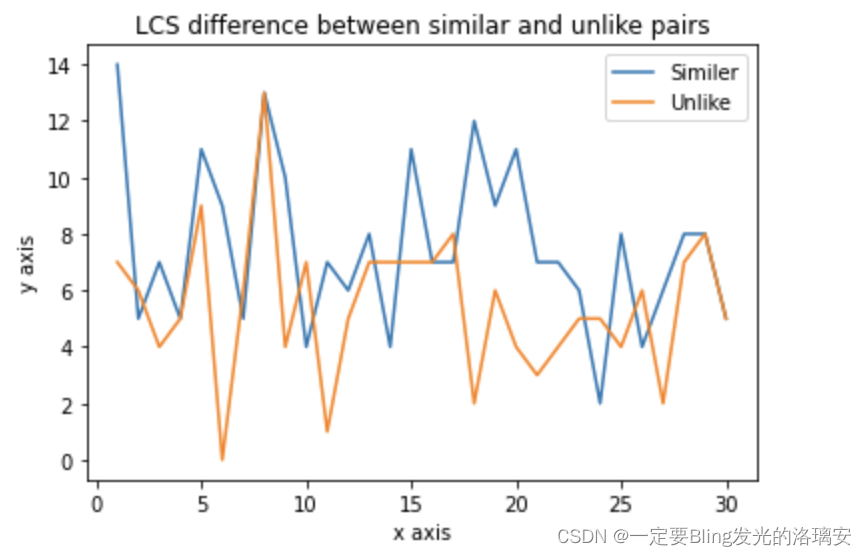
【query1和query2文本最长公用字符串长度】
【query1和query2文本的TFIDF编码相似度】
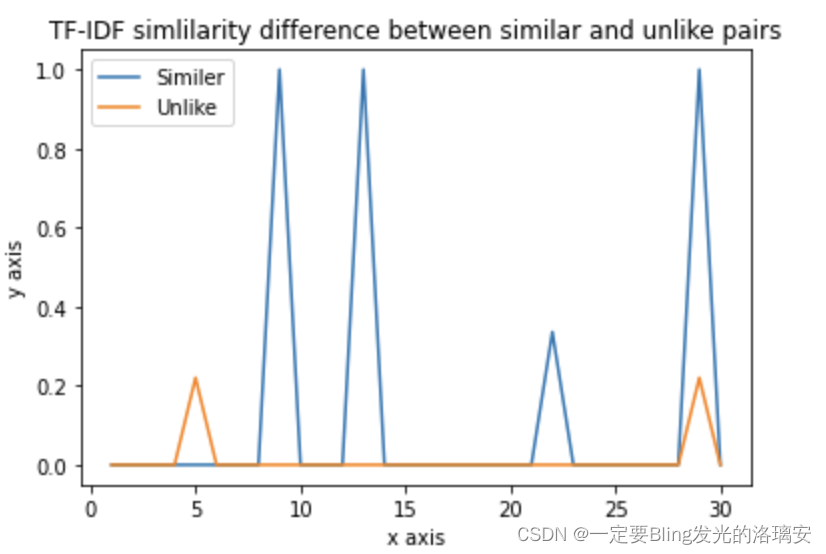
步骤2:根据相似度标签,上述哪一个特征最有区分性?
答案是:文本的TFIDF编码相似度!
TFIDF编码越相似,越有可能是标签1;相似度越低,越可能是标签0~
任务4:文本相似度(词向量与句子编码)
步骤1:使用jieba分词,然后使用word2vec训练词向量
明天写🤪





![[论文翻译] GIKT: A Graph-based Interaction Model forKnowledge Tracing](https://img-blog.csdnimg.cn/img_convert/88e82382843ebc7b2de32687e29bd416.png)