欢迎大家点赞、收藏、关注、评论啦 ,由于篇幅有限,只展示了部分核心代码。
文章目录
- 一项目简介
- 二、功能
- 三、系统
- 四. 总结
一项目简介
一、项目背景
随着医疗技术的快速发展,CT(Computed Tomography)影像已成为医生诊断疾病的重要工具之一。然而,由于CT影像的数据量大、信息复杂,医生在阅片时可能面临较高的工作量和压力。因此,利用深度学习技术自动对CT影像进行识别分类,辅助医生进行诊断,具有重要的实际应用价值。本项目旨在基于TensorFlow深度学习框架,利用预训练的VGG16卷积神经网络模型,开发一个CT影像识别分类系统。
二、项目目标
构建一个基于VGG16卷积神经网络的CT影像识别分类模型,实现对CT影像的自动分类。
通过训练和优化模型,提高CT影像识别的准确率和效率。
为医生提供一个高效、准确的辅助诊断工具,减轻医生的工作负担。
三、项目内容
数据集准备:
收集包含不同疾病类型的CT影像数据集,并进行必要的预处理,如图像缩放、归一化等。
将数据集划分为训练集、验证集和测试集,用于模型的训练、验证和测试。
模型构建:
基于TensorFlow深度学习框架,利用预训练的VGG16卷积神经网络模型作为特征提取器。
在VGG16模型的基础上,添加适当的全连接层或全局平均池化层,以适应CT影像分类任务。
确定模型的超参数,如学习率、批处理大小、训练轮数等。
模型训练:
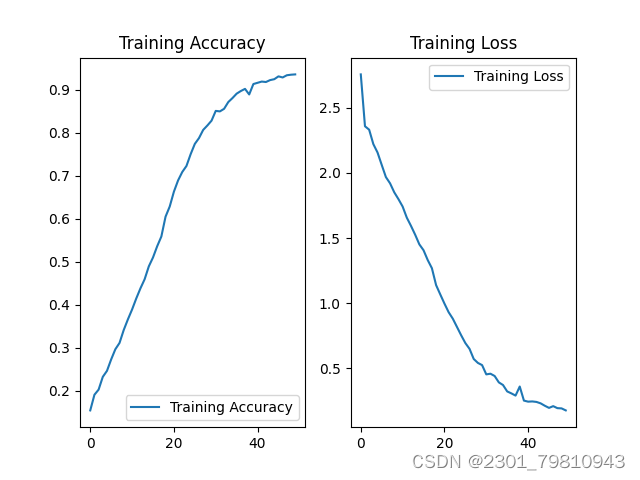
使用训练集对模型进行训练,通过前向传播计算预测结果,根据预测结果和真实标签计算损失函数。
利用反向传播算法和梯度下降优化器更新模型参数,以最小化损失函数。
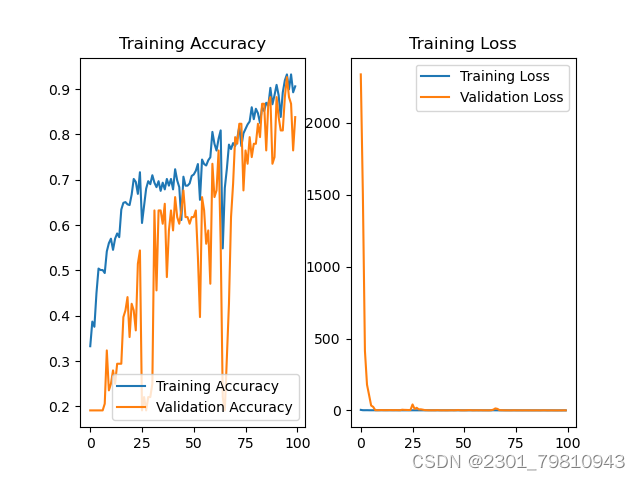
在训练过程中,使用验证集对模型进行性能评估,包括准确率、召回率、F1值等指标。
根据验证集的性能表现,调整超参数和学习策略,以优化模型的性能。
模型评估与优化:
使用测试集对训练好的模型进行最终评估,计算模型的识别准确率和其他性能指标。
分析模型的性能表现,找出可能的改进方向,如调整网络结构、增加数据增强策略等。
根据评估结果对模型进行优化和改进,以提高识别准确率和泛化能力。
系统实现与测试:
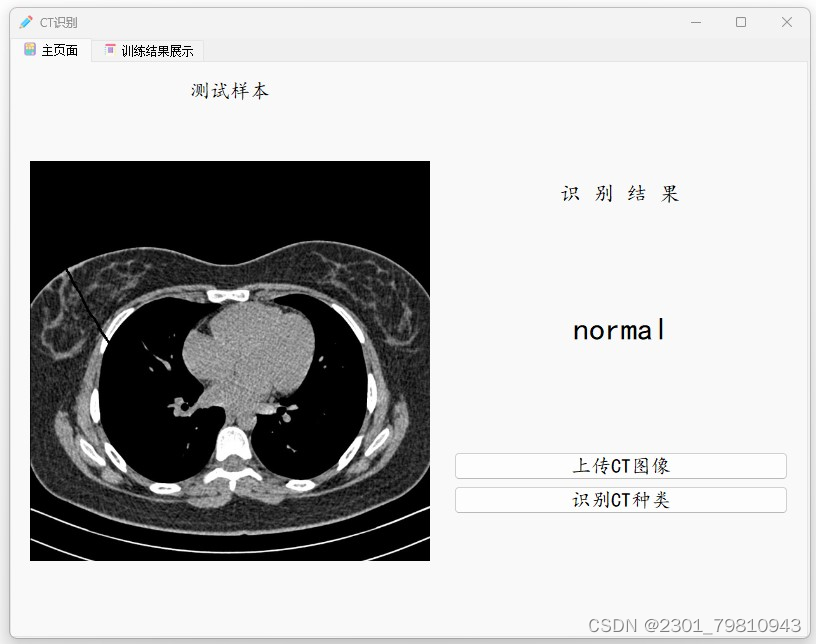
将训练好的模型集成到一个完整的CT影像识别分类系统中,实现用户上传CT影像、系统自动识别并输出分类结果的功能。
对系统进行功能测试和性能测试,确保系统能够稳定运行并满足实际应用需求。
四、项目意义
提高医疗诊断效率:通过自动化识别分类CT影像,可以大大缩短医生阅片时间,提高医疗诊断效率。
辅助医生进行诊断:为医生提供一个高效、准确的辅助诊断工具,帮助医生更准确地判断疾病类型和程度。
推动医疗智能化发展:本项目的研究和探索有助于推动医疗智能化的发展,为未来的医疗技术创新提供新的思路和方法。
二、功能
深度学习基于Tensorflow卷积神经网络VGG16的CT影像识别分类
三、系统
四. 总结
扩展数据集:收集更多类型的CT影像数据集,以涵盖更多的疾病类型和变异情况,进一步提高模型的泛化能力。
改进模型结构:探索更先进的卷积神经网络结构或集成其他深度学习技术,以提高模型的识别准确率和鲁棒性。
多模态融合:将CT影像与其他医学图像或临床数据相结合,进行多模态融合分析,以获取更丰富的信息和更准确的诊断结果。
部署到实际场景:将本项目的研究成果部署到实际医疗场景中,为医生提供更实用的辅助诊断工具,并不断改进和优化系统的性能和功能。