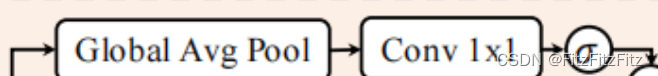前段时间,KAN突然爆火,成为可以替代MLP的一种全新神经网络架构,200个参数顶30万参数;而且,GPT-4o的生成速度也是惊艳了一众大模型爱好者。
大家开始意识到——
大模型的计算效率很重要,提升大模型的tokens生成速度是很关键的一环。
而提升大模型的tokens生成速度,除了花钱升级GPU外,更长效的做法是改善Transformer模型架构的计算效率。
今天,笔者发现,终于有团队对Transformer计算最耗时的核心组件——多头注意力模块(MHA)下手了,将Transformer的计算性能提升了有2倍之高。
通俗的讲,如果这项工作未来能落地到大模型里面,那么大模型tokens生成速度翻倍式提升的一天就不远了。

这篇论文已经被今年的机器学习顶会ICML 2024录用,拿到了7分的高分,而且还开源了。
据透露,今年ICML 2024录用的paper平均得分在4.25-6.33之间
笔者扒了下,发现这个工作的背后是一家颇具影响力的国内公司——彩云科技,没错,就是打造爆火的“彩云小梦”产品的团队。

不急,先看看这篇论文,如何将Transformer模型计算效率暴涨100%的。
论文标题:
Improving Transformers with Dynamically Composable Multi-Head Attention
论文链接:
https://arxiv.org/abs/2405.08553
开源项目地址:
https://github.com/Caiyun-AI/DCFormer
Github上已开源这项工作的代码、模型和训练数据集。
3.5研究测试:
hujiaoai.cn
4研究测试:
askmanyai.cn
Claude-3研究测试:
hiclaude3.com
我们知道,承载Transformer计算量的核心模块便是多头注意力(MHA)模块,位置(position=i)上的每一个注意力头(attention head)会与全部位置上的注意力头计算出一个注意力分布矩阵。在这个过程中,位置 i 上的各个注意力头计算出来的注意力分布矩阵是相互独立的。
忘了的小伙伴请自行扒拉Transformer论文
论文指出,这种多头独立计算的机制会带来两大问题:
-
低秩瓶颈(Low-rank Bottleneck): 注意力矩阵的秩较低,模型的表达能力受限
-
头冗余(Head Redundancy): 不同的注意力头可能会学习到相似的模式,导致冗余
因此,彩云科技提出了一种叫动态可组合多头注意力(DCMHA)的机制,DCMHA 通过一个核心的组合函数(Compose function),以输入依赖的方式转换注意力得分和权重矩阵,从而动态地组合注意力头,解决了传统MHA模块中存在的上述低秩瓶颈和头冗余问题。
值得强调的是,DCMHA旨在提高模型的表达能力,同时保持参数和计算效率,它可以作为任何Transformer架构中MHA模块的即插即用替代品,以获得相应的DCFormer模型。
论文通过实验表明,DCFormer在不同的架构和模型规模下,在语言建模方面显著优于Transformer,与计算量增加1.7倍至2倍的模型性能相匹配。例如,DCPythia-6.9B在预训练困惑度和下游任务评估方面优于开源的Pythia-12B。
DCMHA原理
DCMHA机制的核心是引入的Compose函数。这个Compose函数可以视为一个可学习的参数,它可以动态地组合不同头的QK矩阵和VO矩阵,内部通过一系列变换来分解和重构注意力向量。可以近似理解为:经过组合映射后,H个基础的注意力头可组合成多至H*H个注意力头。
你可以简单理解为,它能根据输入数据调整头之间的交互方式,一是打破头的独立性,二是可以根据输入数据动态组合,从而可以增强模型的表达能力。
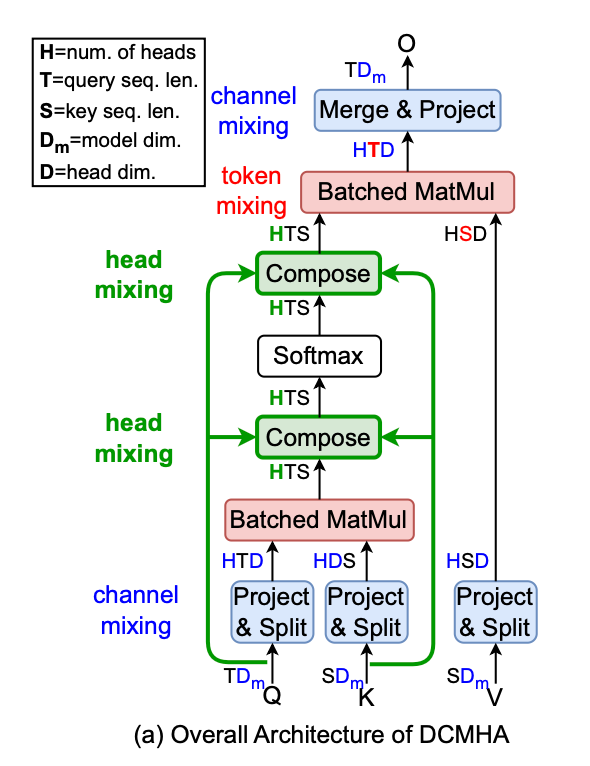
▲动态组合注意力头机制
利用矩阵分解实现高效的参数计算
尽管引入了动态组合,DCMHA的设计依旧注重参数和计算效率。通过矩阵分解DCMHA能够以较小的额外参数和计算开销实现动态组合,同时保持模型性能。
DCFormer可提高70%~100%的模型计算效率
还有很重要的一点是,DCMHA可以作为MHA的直接替代品应用于任何Transformer架构中,升级成DCFormer,实现计算效率的大幅提升,达到1.7倍-2倍的计算效率。
而且,实验结果表明在众多NLP下游任务和图像识别任务上的测评也验证了DCFormer的有效性。
1、DCFormer在不同参数规模下(405M到6.9B参数),对 Transformer 和 Transformer++ 模型的性能提升显著。
自2017年Transformer诞生至今,旋转位置编码RoPE和门控激活函数MLP被证明是最普世有效且广泛采用的改进,已融入到Transformer++架构,同时也是大名鼎鼎的Llama模型框架。
而DCFormer性能算力比的提升幅度超过这两项改进的提升幅度之和。
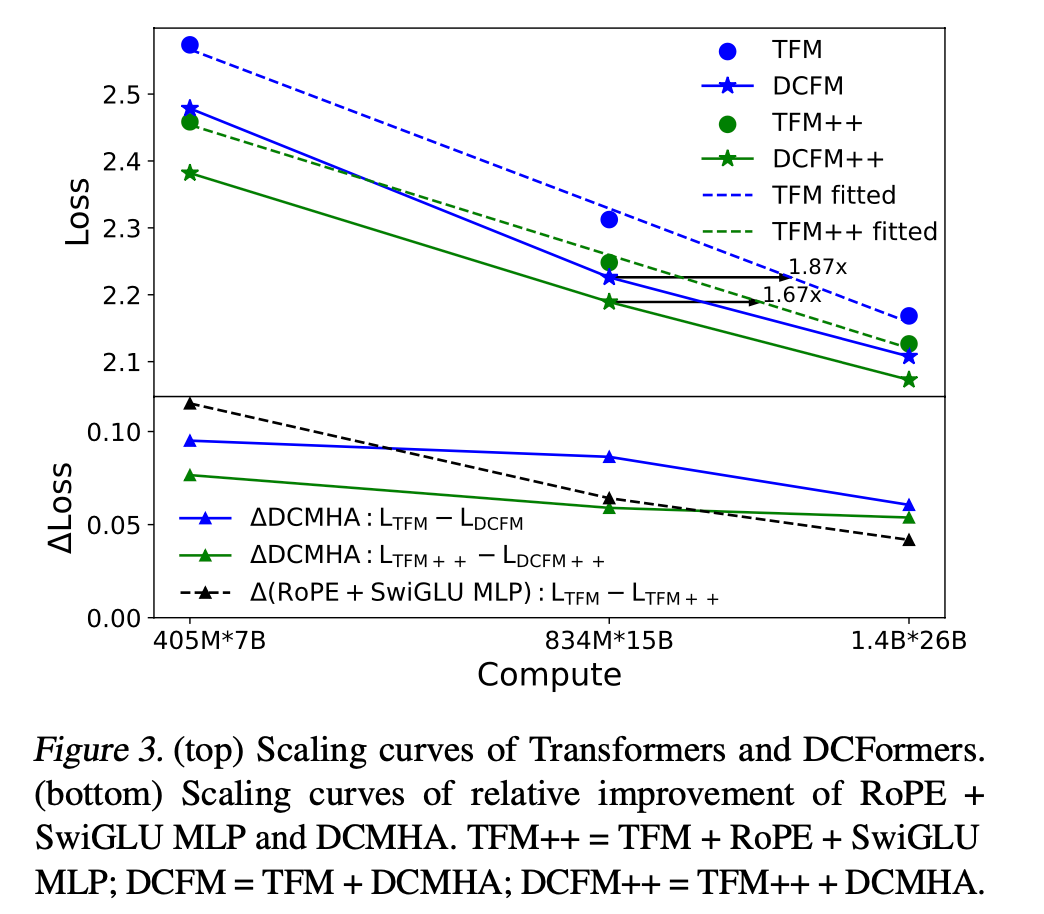
2、DCPythia-6.9B在多个下游任务中的表现优于Pythia-12B。
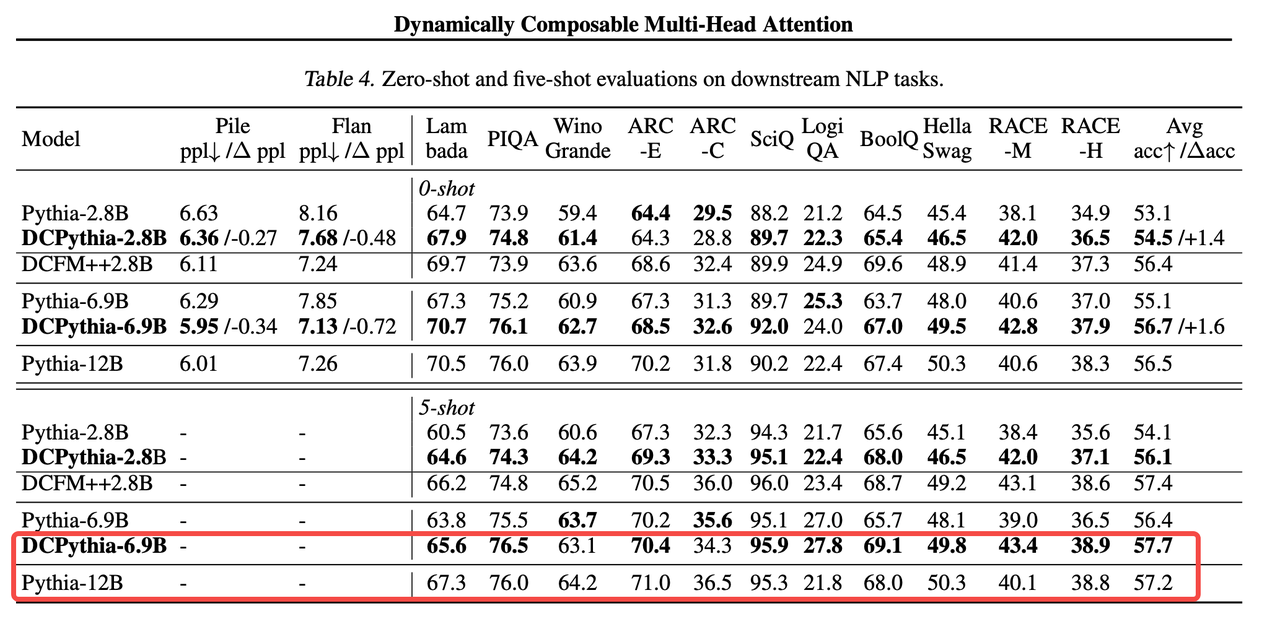
3、在ImageNet-1K数据集上的实验验证了DCMHA在非语言任务中也是有效性的。
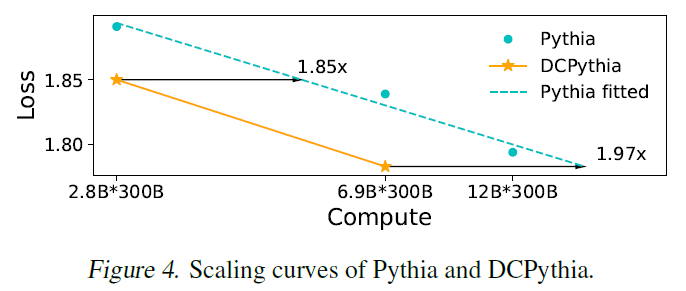
从上图可以看出,在相同训练数据和算力下,一个被本文方法改进后69亿参数的模型,却拥有比120亿参数传统模型结构更好的效果。
换句话讲:相同的参数量下,使用DCFormer将具备更强的模型表达能力;用更少的参数量,拥有相同的模型表示效果。
DCFormer在不同的架构和模型规模下,在语言建模方面显著优于Transformer,与计算量增加1.7倍至2倍的模型性能相匹配。
距离大模型“光速”生成tokens不远了
笔者觉得这个工作还是蛮扎实的,如果能像RoPE一样在国内外的主流大模型落地,大模型“光速”生成tokens的一天并不遥远,而且从AI产业对电力能源的利用效率来说,也是一个很有意义的改善。
实话说,在如今这个“资本寒冬”,愿意为前瞻技术研究投入资金、人才支持的公司非常少了,能在ICML这个高含金量机器学习顶会上跑出来高分论文的团队,背后一定离不开公司层面的支持。
在写这篇文章的时候,笔者注意到,彩云科技团队也在进行大模型对齐和测评算法研究员、大模型推理优化、AIGC产品经理、后端工程师、前端工程师、SRE工程师等职位的招聘,这里附上简历投递二维码:

倘若能进入到发表ICML高分论文的团队参与AI方向的学术研究和产品落地,属实是一个非常珍贵的职业经历,感兴趣的小伙伴抓住机会。
笔者在搜彩云科技的时候,还无意间扒出来了意想不到的东西。
笔者发现,有一款服务500+家大客户的超大型B端产品——彩云天气竟然也是彩云科技旗下的。

没准,你手机里的、汽车车载系统里的天气APP背后走的很可能就是彩云天气API。
做过ToB业务的都知道,能获得100家大客户青睐的B端产品就已经具备相当的B端影响力了,而彩云天气不仅斩获了滴滴、小米、vivo、高德、360、小鹏汽车在内的500多家大客户,其甚至早在2014年就成为了中国气象局的战略合作伙伴,曾帮助多个部门和地区避免了自然灾害风险。
不夸张的讲,彩云天气已成为了国内事实上的气象服务基础设施。
这背后,无疑是彩云科技强悍的AI算法实力和强大的工程能力。

如果你对AI ToB产品觉得陌生,那彩云科技旗下的另一款爆款AI ToC产品请让我安利下,因为——
它真的太圈粉了!
作为文字工作者,笔者自ChatGPT爆火以来,玩遍了国内外几乎所有的文字创作类产品,但给笔者留下深刻印象&能持续用起来的产品不多,彩云小梦就是其中一款。
彩云小梦是一款网文辅助写作工具,也是一个 AI RPG 平台,用户可以在里面扮演各种角色,体验不同的人生。AI 写作助手具有文风独特、可以自动续写、支持自定义开头等特点和功能。
作为曾经的RPG游戏爱好者(玩过金庸群侠传、仙剑奇侠传、武林群侠传系列的小伙伴请举手🙋🏻♀️),笔者甚至用彩云小梦将金庸群侠传游戏剧情翻写过小说,因为彩云小梦AI生成的内容太有意思了,贴一段你们自己感受下:

在写网文这块,用过彩云小梦后就再也用不回ChatGPT了,体验差别悬殊。
但最让我停不下来的,倒不是写网文。而是你可以扮演网文里面的角色:
这种沉浸式角色的体验非常神奇,经常玩半天都停不下来:
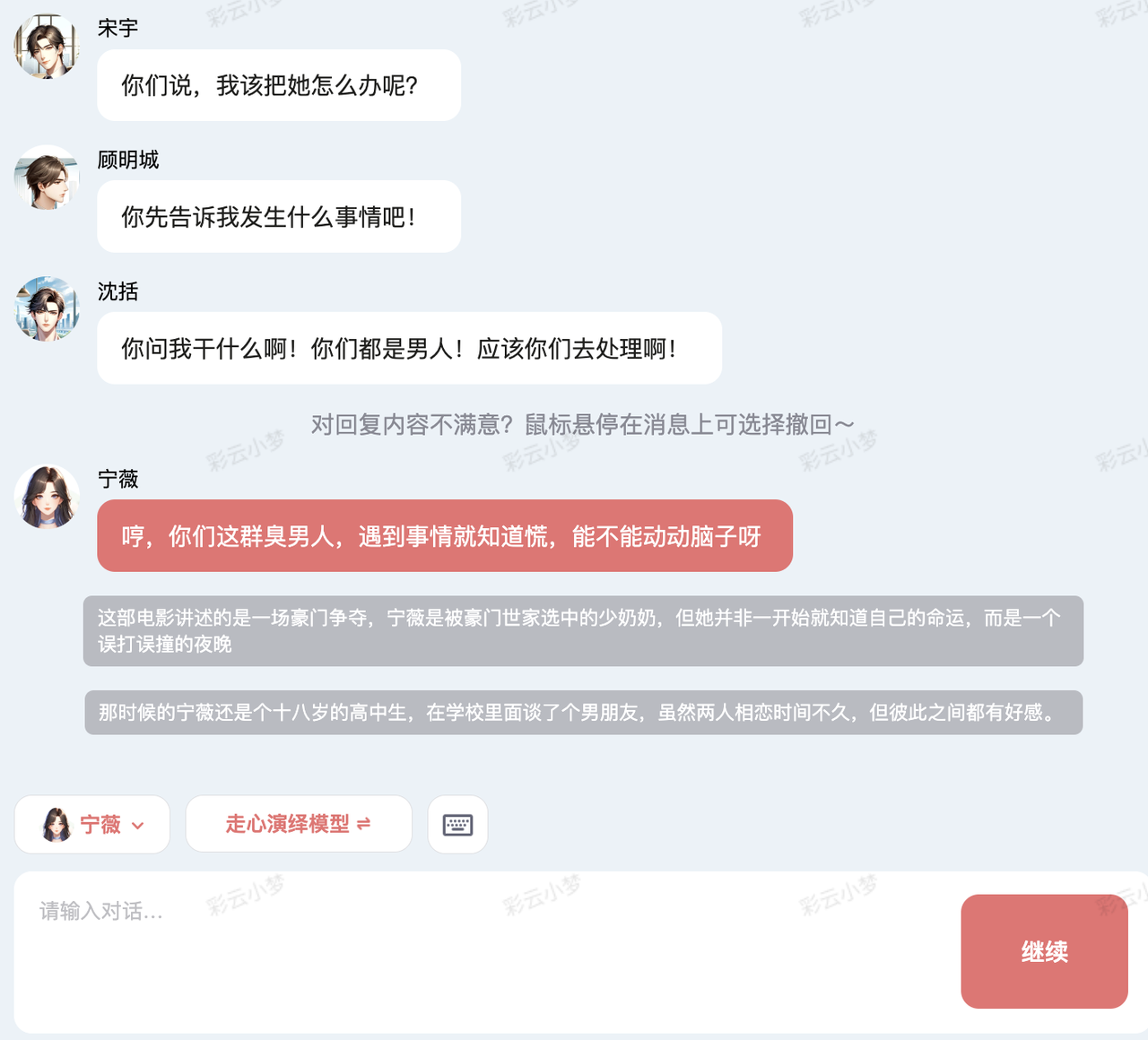
彩云小梦的产品体验非常丝滑、稳定,技术出身的笔者,能深刻的在这份丝滑背后的工程能力和产品能力有多强大。
除了彩云天气和彩云小梦外,彩云科技旗下的彩云小译也是业界有口皆碑的同声传译软件,不仅有阅文集团、360和维基百科等广泛的客户群基础,其甚至给《三体》做过翻译,篇幅原因,这里就不展开讲了。
总之,通过进一步深挖彩云科技旗下的产品,笔者深感这是一家集强大的AI算法、工程和产品能力于一身的老牌科技公司,这种低调钻研技术、打磨产品、做扎实的价值创造的宝藏团队在国内属实稀缺。深得笔者喜爱。

最后贴下彩云科技的招聘信息,多个岗位正在火热招聘中,感兴趣的小伙伴抓住机会,招聘岗位详情请点击链接进一步了解:
http://colorfulclouds.com/jobs/