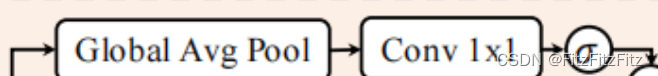BEVFusion总体结构如下图所示,在相机和lidar的输入都已经被网络提取特证之后,就要对两种特征进行融合,
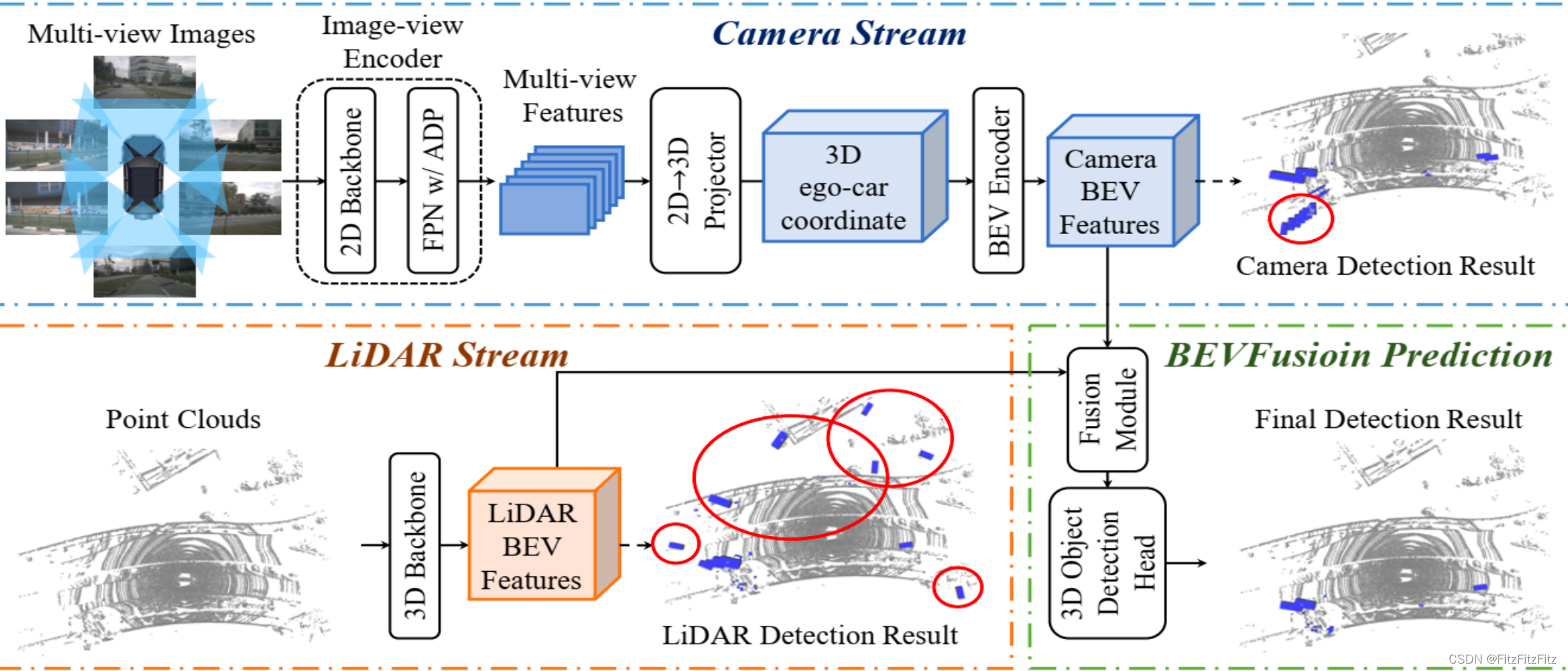
在BEV Fusion中图像支路得到的是 Camera BEV Features,点云支路得到的是 LiDAR BEV Features,除了2d和3d各自的检测支路之外,下一步我们要做什么呢,那就是融合,也就是 Fusion Module 模块。接下里啊就来仔细来看下这个模块。
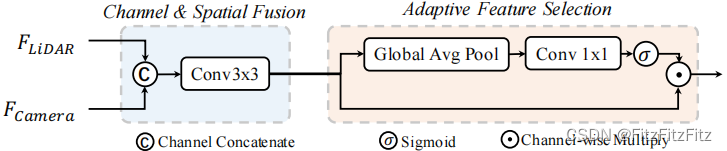
特征融合是怎么进行的呢?
融合其实很简单,一个级联,一个是卷积做一下特征提取就结束了。
然后我们引入了一个叫 Adaptive Feature Selection,翻译过来叫做特征的自适应选择,其实这就是一个 Attention组件,使用的就是注意力机制
谓的注意力机制包括空间注意力、通道注意力、混合注意力还有 self-attention 等等,关于这些attention就看一下另一个帖子我不赘述了。
空间注意力、通道注意力、混合注意力和 Self-Attention
稍微整理了一个回答,贴在了下面
BEVFusion 中引入的 Adaptive Feature Selection其实偏向通道层面,对通道维度进行了加权,考虑的是哪个通道更重要, 是点云上的通道呢,还是图像上的通道呢,
通过这样一个权重的预测,对通道特征去进行重新的加权, 我们从图中可以看到 ⊙ 是一个 Channel-wise 的,是一个通道的相乘,会关注一个重要的通道而忽略不重要的通道所以在这里融合模块其实可以一定程度上体现 BEVFusion 的作者在 Motivation中阐述的一个想法,那就是点云和图像是没有主次之分的,可能对于这个场景而言,我们可能认为点云更重要,我们喜欢点云,可能对于下一个场景而言图像更重要,我们喜欢图像,那我们就多关注一点图像,那无论怎么做,它是一种网络自适应的过程,而不是说我们人为定义好了,比如我们就用点云或者就用图像,或者从点云到图像或者从图像到点云,它不是这么做的,它是一种自适应挑选的过程。那融合完成后,我们就可以得到融合特征,自然就可以用来做预测。
出处https://blog.csdn.net/qq_40672115/article/details/134891133
说的还是比较清楚的,细究的话那就是在经过了channel的直接拼接(级联)之后,我们通过这一段输出的其实就是对于通道的权重了,在这里学习注意力之后,再与下面一行相乘,得到的就是带有通道注意力的特征了。