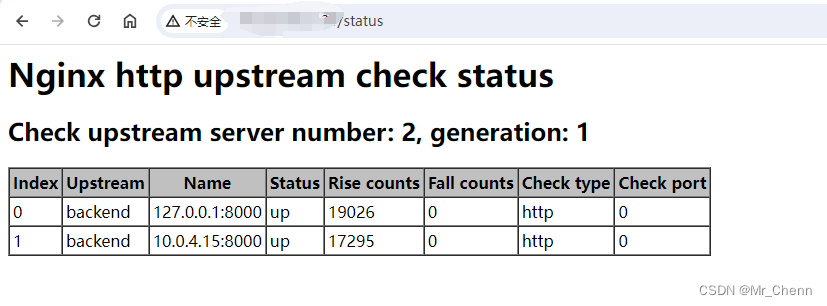
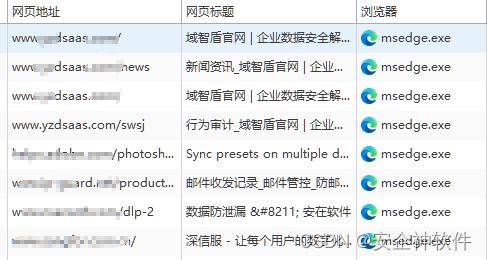
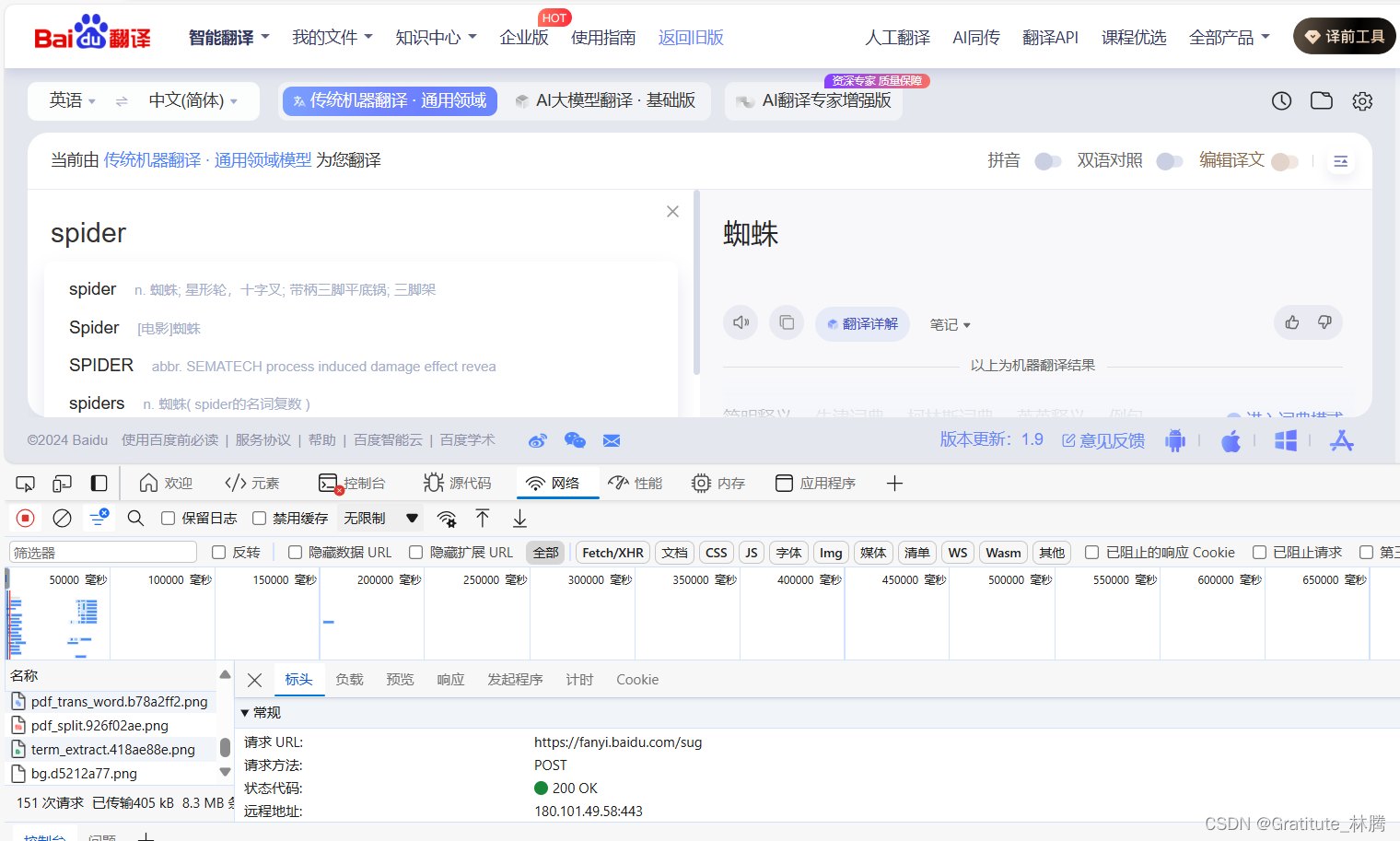
打开百度翻译,并打开控制台,输入spider,然后在网络中找到对应的接口,可以看出,该url是post请求
在此案例中找到的接口为sug,依据为:
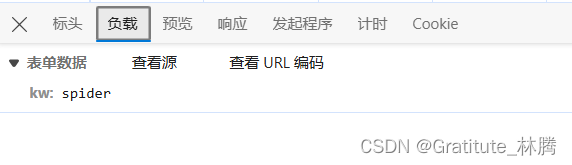

可以看到,传递的数据为kw : XXX,
所以在代码中,data数据需要以“kw”为键进行构造,如:
data = {
"kw" : "spider"
}然后请求对象的定制还需要用到url,headers(请求头),如下:
url='https://fanyi.baidu.com/sug'
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0"
}因为是post请求,data还需要进行编码,如下:
data = urllib.parse.urlencode(data).encode("utf-8")然后就是请求对象的定制,post请求,除了url,headers外,还要指明data,即请求数据
request = urllib.request.Request(url=url,data=data,headers=headers)发起请求,得到想要内容
reponse = urllib.request.urlopen(request)获取页面源码
content = reponse.read().decode("utf-8")如果直接对内容打印,会发现有些内容看不懂:

可以看到这个内容是json格式的,使用json.loads(),将其转成python对象。json.loads() 函数用于将一个JSON格式的字符串转换为相应的Python对象。loads 是 "load string" 的缩写。
obj = json.loads(content)
print(obj)打印结果:

完整代码:
import urllib.request
import urllib.parse
import json
url='https://fanyi.baidu.com/sug'
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0"
}
data = {
"kw" : "spider"
}
data = urllib.parse.urlencode(data).encode("utf-8")
request = urllib.request.Request(url=url,data=data,headers=headers)
reponse = urllib.request.urlopen(request)
content = reponse.read().decode("utf-8")
obj = json.loads(content)
print(obj)