创作灵感来源于个人项目的一个稳定性规划,单节点的项目稳定性方面可能有很大的缺漏,因此需要升级为多节点,保证服务故障后,依然有其他服务可用,不会给前端用户造成影响。
(前面讲选型,想直接看操作的可以跳转到:操作步骤 1、下载Tengine)
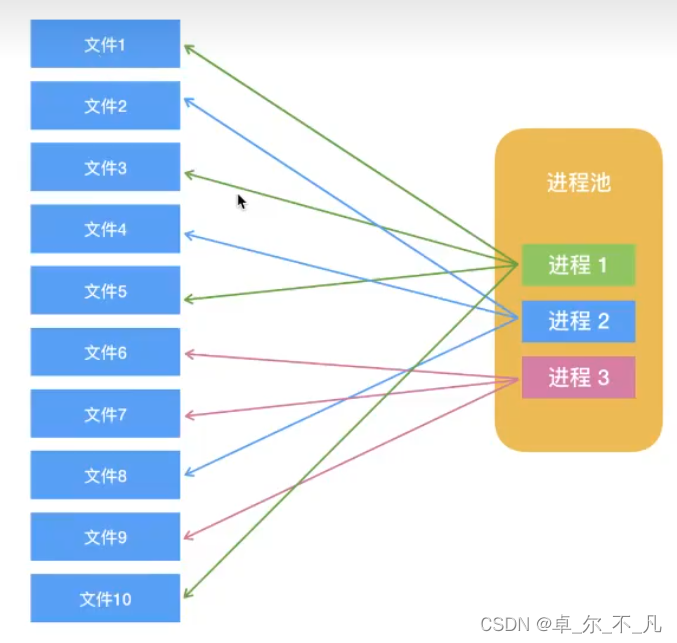
这次的目标是实现负载均衡与故障检查自动切换,主要有 3 个方案:
1、使用Nginx,通过将访问个人项目路径的URL转发到其他机器上实现
2、使用微服务模式,通过启动单个服务的多个实例,利用微服务Gateway中Ribbon的负载均衡
DNS其实也想过,但是DNS可玩性太低,无法实现故障的自动切换,不符合需求,排除!
都可以实现,但是明显第一种成本低,第二种需要加服务加注册中心改造较大,耗资源较多;
操作开始:使用Nginx实现负载均衡与故障检查自动切换
别看题目是叫这个名,但是实际上最终使用的是Tenginx;什么??我怎么没听过???为啥要用这玩意儿!??不是说好的Nginx吗?
别急,听我慢慢跟你说,我一开始也是想用Nginx的,毕竟服务部署起来一直用的就是Nginx,但是特么的使用Nginx的这个健康检查功能,是不支持的,得上Nginx-Plus,这得收费;
先看看如何配置多节点和健康检查:

但是这样会因为check指令启动失败,如何在 yum install nginx得到的nginx上再加上健康检查模块?GPT的回答如下:

然后就把我的注意力转移到了Nginx-Plus,什么玩意儿,让我们看看Nginx-Plus
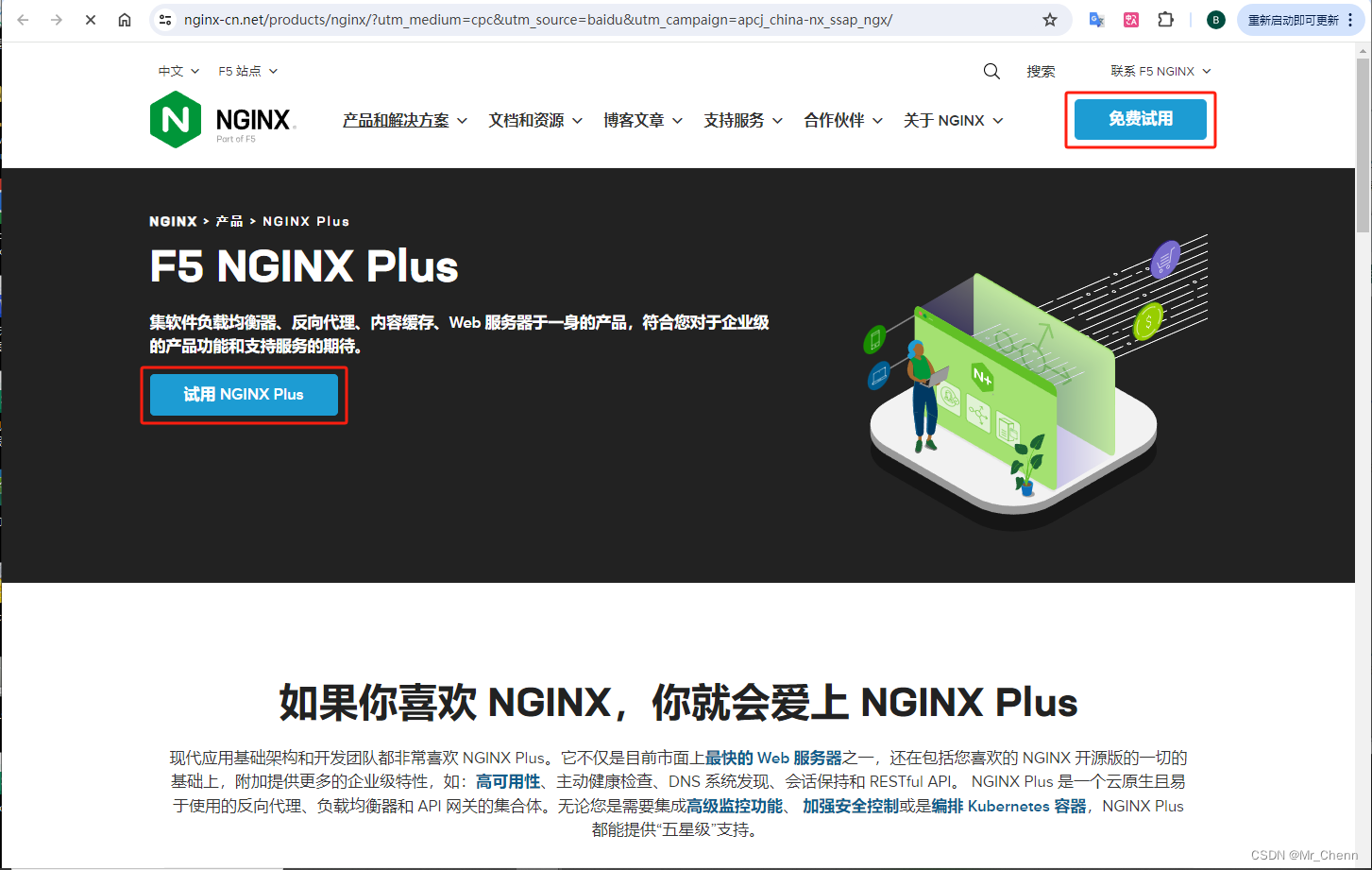
什么?免费试用??果然要收费,操
最后通过这篇文章了解到,淘宝的tengine开发的nginx_upstream_check_module模块可以实现对后端节点做健康检查,不得不说阿里在软件基础设施方面真的做出了巨大贡献,阿里牛逼!
然后去tengine官网看看,看描述Tenginx应该是Nginx1.2.4版本分支切出来开发的
- All features of Nginx-1.24.0 are inherited, i.e., it is compatible with Nginx.
- Tengine is a web server originated by Taobao, the largest e-commerce website in Asia. It is based on the Nginx HTTP server and has many advanced features.
话不多说,直接下载安装,替换掉这个无法支持健康检查模块的nginx!
下面是密集的操作步骤:
1、下载Tengine
我是先下载到win,然后传到linux
再解压zip,得到tengine文件夹

2、开始安装
其实都有文档,我在安装步骤由于使用默认文档的安装方式,少安装了一些模块导致无法启动,在这里我直接省略我踩坑的步骤,上正确路径:
2.1 编译
./configure --with-http_v2_module --with-http_ssl_module --add-module=./modules/ngx_http_upstream_check_module2.2 安装
makemake install安装好后,你的tenginx配置目录在 /usr/local/nginx,配置目录在conf下
然后你的tenginx运行的pid文件在/run/nginx.pid
2.3 注册服务、开机自启等(无需求可不做,直接在sbin目录启动也可)
2.3.1 创建 systemd 单元文件
vi /etc/systemd/system/tengine.service写入内容:
[Unit]
Description=Tengine HTTP Server
After=network.target
[Service]
Type=forking
PIDFile=/run/nginx.pid
ExecStart=/usr/local/nginx/sbin/nginx
ExecReload=/bin/kill -s HUP $MAINPID
ExecStop=/bin/kill -s QUIT $MAINPID
TimeoutStopSec=5
KillMode=process
PrivateTmp=true
[Install]
WantedBy=multi-user.target
2.3.2 重新加载 systemd 并启动服务
sudo systemctl daemon-reload
sudo systemctl start tengine
2.3.3 停止和重启服务
sudo systemctl stop tengine
sudo systemctl restart tengine
这样,你就可以方便地使用 systemd 来管理 Tengine 服务了。
3、编辑配置
3.1 配置负载均衡
编辑tenginx的配置文件
vi /usr/local/nginx/conf/nginx.conf按语法加入upstream模块,健康检查规则,健康检查状态定义
这个在http { } 中
upstream backend {
server 127.0.0.1:8000;
server 10.0.4.15:8000;
# 健康检查配置
check interval=3000 rise=2 fall=2 timeout=1000 type=http;
# interval: 检查间隔时间,单位为毫秒
# rise: 连续成功次数达到这个值后,服务器被认为是健康的
# fall: 连续失败次数达到这个值后,服务器被认为是不健康的
# timeout: 健康检查超时时间,单位为毫秒
# type: 检查类型,这里是http类型
check_http_send "GET / HTTP/1.0\r\n\r\n";
check_http_expect_alive http_2xx http_3xx;
}下面这个在server{} 中
location /chris-admin/ {
proxy_pass http://backend/; #这里的端口记得改成项目对应的哦
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "Upgrade";
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}/chris-admin/是我的业务请求前缀,这里通过 proxy_pass转发到http://backend/实现负载均衡
3.2 配置健康检查
其实在3.1中已经配置了健康检查的内容,但是那只是配置检查节点健康状态的逻辑,那么如何知道当前配置的几个节点,有哪些是在线,哪些是挂掉的呢?
在server {} 内配置如下内容:
#配置nginx节点健康状态
location /status/ {
check_status;
access_log off;
# 设置允许访问的IP地址,或使用allow all
#allow 127.0.0.1;
#deny all;
}然后就可以通过访问 “服务器IP:80/status” 这个路径来实现;如下图:
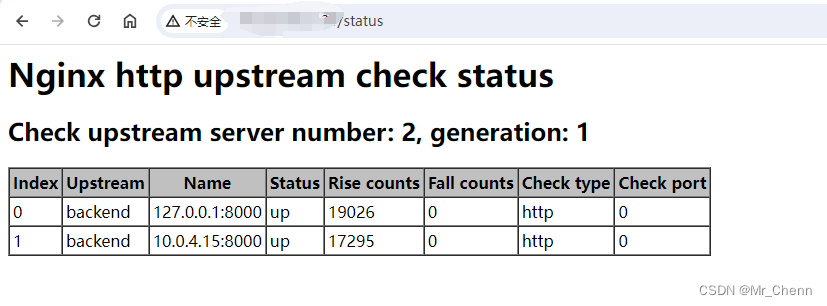
我已经试过了,服务down了之后,可以实现故障检查与自动切换,下线一个,服务可正常访问,下线俩才会GG;
这里不再记录这些无关紧要的测试步骤截图了,不过你们搭建完一定记得自测一下哦
到这里,这篇教程记录就结束了,这全都是我自己踩坑后总结的正确路径;
如果喜欢可以点赞 + 关注 + 收藏 ~