关卡四 模型训练与验证
本文是在原本闯关训练的基础上总结得来,加入了自己的理解以及疑问解答(by GPT4)
原任务链接
目录
- 关卡四 模型训练与验证
- 1. 训练
- 1.1 构建模型结构
- 1.2 模型编译
- 1.3 模型训练
- 1.4模型超参数调试
- 2. 推理
- 2.1 模型准确性评估
- 2.2 模型可靠性评估
- 2.3 模型效率评估
- 3. 作业
- STEP1: 按照要求填入下方题目结果,填完之后点击运行即可
- STEP2: 将结果保存为 csv 文件
1. 训练
选定了模型框架后,需要对神经网络模型进行训练,主要有3个步骤:
- 构建模型结构
- 模型编译
- 模型训练
接下来详细介绍这3个步骤。
1.1 构建模型结构
构建模型结构,主要有神经网络结构设计、激活函数的选择、模型权重如何初始化、网络层是否批标准化、正则化策略的设定。
由于在关卡四中介绍了神经网络结构设计和激活函数的选择,这里不过多介绍,下面简单介绍下权重初始化,批标准化和正则化策略。
权重初始化
权重参数初始化可以加速模型收敛速度,影响模型结果。常用的初始化方法有:
- uniform均匀分布初始化
- normal高斯分布初始化,需要注意的是,权重不能初始化为0,这会导致多个隐藏神经元的作用等同于1个神经元,无法收敛。
批标准化
batch normalization(BN)批标准化,是神经网络模型常用的一种优化方法。它的原理很简单,即是对原来的数值进行标准化处理:
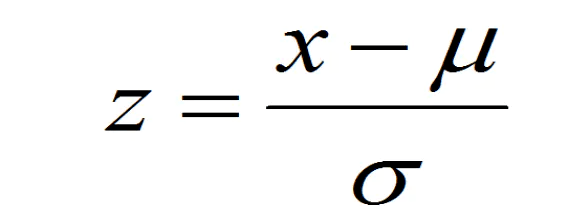
batch normalization在保留输入信息的同时,消除了层与层间的分布差异,具有加快收敛,同时有类似引入噪声正则化的效果。它可应用于网络的输入层或隐藏层,当用于输入层,就是线性模型常用的特征标准化处理。
正则化
正则化是在以(可能)增加经验损失为代价,以降低泛化误差为目的,抑制过拟合,提高模型泛化能力的方法。经验上,对于复杂任务,深度学习模型偏好带有正则化的较复杂模型,以达到较好的学习效果。常见的正则化策略有:dropout,L1、L2、earlystop方法。具体可见序列文章:一文深层解决模型过拟合
1.2 模型编译
模型编译,主要包括学习目标、优化器的设定。
深度学习的目标是极大化降低损失函数,其中包括损失函数的选择,这里不过多介绍。关于优化器的选择,可见文章:一文概览神经网络优化算法
1.3 模型训练
数据集划分
在训练模型前,把数据集分为训练集和测试集(关卡二有提到),如果有调超参数调试的需求,可再对训练集进一步分为训练集和验证集。
① 训练集(training set):用于运行学习算法,训练模型。
② 开发验证集(development set)用于调整模型超参数、EarlyStopping、选择特征等,以选择出合适模型。
③ 测试集(test set)只用于评估已选择模型的性能,但不会据此改变学习算法或参数。
数据划分方案
根据数据样本量进行划分,小样本量可以分为60%训练集,20%验证集,20%测试集,大规模样本集(百万级以上),留1w验证集和1w测试集即可。也可以根据超参数的数量来调整验证集的比例,比如超参数越少,或者容易调整的话,可以减少验证集的比例。
训练次数和迭代
epoch:整个数据集在模型上的训练次数
batch:整个数据集被打包成多个批数据
interation:每跑完一个batch都要更新参数,这个过程就是interation
在训练数据的时候,会发现数据量很大,比如训练数据有1000条,内存无法支持同时跑1000条数据,所以要分批次,因此在关卡二中提到的Dataloader里的batch_size就是一批中的数据条数,设batch_size = 10,把全部的数据都跑一遍之后,一次训练完成,就是完成一次epoch。在此过程中一个epoch需要完成100次迭代interation,才可以把所有的数据跑全。但是把整个数据集放在神经网络上训练一次是不够的,需要把整个数据集放在同一个神经网络上学习很多遍,不断迭代进行梯度下降来优化模型。模型对于样本的拟合情况会从欠拟合到理想拟合状态再到过拟合状态。因此epoch也不是设置的越多越好。
1.4模型超参数调试
模型超参数是什么?
参数和超参数
模型有参数和超参数的区别,在训练过程中学到的参数是参数,二超参数是模型学习不到的,是预先定义的模型参数。这里的模型调参指调整超参数。
参数:就是模型可以根据数据可以自动学习出的变量,应该就是参数。比如,深度学习的权重,偏差等
超参数:就是用来确定模型的一些参数,超参数不同,模型是不同的(这个模型不同的意思就是有微小的区别,比如假设都是CNN模型,如果层数不同,模型不一样,虽然都是CNN模型),超参数一般就是根据经验确定的变量。神经网络模型的超参数是比较多的:数据方面的超参数,如验证集比例、batch size等;模型方面,如单层神经元数、网络深度、选择激活函数类型、dropout率等;学习目标方面,如选择损失函数类型,正则项惩罚系数等;优化算法方面,如选择梯度算法类型、初始学习率等。
常用的超参调试有人工经验调节、网格搜索(grid search或for循环实现)、随机搜索(random search)、贝叶斯优化(bayesian optimization)等方法,方法介绍可见系列文章:一文归纳Ai调参炼丹之法。
#Ps:有用的代码片段可以点击cell右上角🌟号一键收藏哦
#模型训练样例代码
def train(cnn, iterator, optimizer, criteon):
avg_acc = []
cnn.train() #表示进入训练模式
for i, batch in enumerate(iterator):
pred = cnn(batch.text) #torch.Size([128, 2])
loss = criteon(pred, batch.label.long()) #不加.long()会报错
acc = binary_acc(torch.max(pred, dim=1)[1], batch.label) #计算每个batch的准确率
avg_acc.append(acc)
optimizer.zero_grad()
loss.backward()
optimizer.step()
avg_acc = np.array(avg_acc).mean()
return avg_acc
这段代码提供了一个用于训练神经网络(在这种情况下是一个卷积神经网络,CNN)的基本函数。这是在机器学习或深度学习项目中常见的模式。让我帮你详细解释一下这个函数的每个部分:
-
函数定义:
def train(cnn, iterator, optimizer, criteon):train函数接受四个参数:cnn: 待训练的卷积神经网络模型。iterator: 数据迭代器,用于遍历训练数据。optimizer: 优化器,用于更新模型的权重。criteon: 损失函数,用于计算预测值和真实值之间的差异。
-
初始化准确率列表:
avg_acc = []- 用于存储每个批次的准确率。
-
设置模型为训练模式:
cnn.train()- 在训练模式下,某些层(如Dropout和BatchNorm)的行为会有所不同。
-
遍历数据迭代器:
for i, batch in enumerate(iterator):- 这个循环遍历训练数据的每个批次。
-
前向传播:
pred = cnn(batch.text)- 使用模型对当前批次的数据进行预测。
-
计算损失:
loss = criteon(pred, batch.label.long())- 使用损失函数计算预测结果和实际标签之间的差异。
-
计算准确率:
acc = binary_acc(torch.max(pred, dim=1)[1], batch.label)- 这里似乎需要定义
binary_acc函数,用于计算准确率。
- 这里似乎需要定义
-
记录准确率:
avg_acc.append(acc)- 将当前批次的准确率添加到列表中。
-
反向传播和优化:
optimizer.zero_grad() loss.backward() optimizer.step()zero_grad清除过去的梯度。loss.backward()计算当前梯度。optimizer.step()更新模型的权重。
-
计算平均准确率:
avg_acc = np.array(avg_acc).mean()
- 在所有批次结束后,计算平均准确率。
需要注意的是,这段代码中有几个潜在的问题和不明确的地方:
binary_acc函数没有在这段代码中定义。它应该是一个计算二分类准确率的函数。batch.text和batch.label的具体结构依赖于数据的格式和迭代器的实现。- 这段代码专门用于处理二分类问题。如果要处理多分类问题,可能需要进行一些修改。
2. 推理
推理,指系统性地对模型的准确性、可靠性、效率进行评估。针对分类和回归问题,有不同的模型评估指标。
2.1 模型准确性评估
针对分类问题有混淆矩阵、准确率(accuracy)、精确率(precision)、召回率(recall)、F1 score、ROC、AUC、PR曲线这些指标。
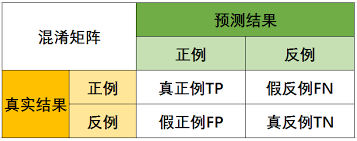
混淆矩阵
混淆矩阵是监督学习中的一种可视化工具,主要用于比较二分类结果和实例的真实信息。矩阵中的每一行代表实例的预测类别,每一列代表实例的真实类别。对于分类算法,比如分类猫和狗。在混淆矩阵中,T(True) 就是预测类别和真实类别一致,F(False) 就是预测类别和真实类别不一致;预测值为正例(Positive),预测值为负例(Negative)。
准确率(accuracy):正确分类的样本个数占总样本个数, accuracy = (TP+TN)/(P+N)
精确率(precision):预测正确的正例数据占预测为正例数据的比例,precision = TP/(TP+FP)
召回率(recall):预测为正确的正例数据占实际为正例数据的比例,recall = TP/(TP+FN)
F1 值(F1 score):精确率和召回率的调和平均。F1认为精确率和召回率同等重要。F1-Score的值在0到1之间,越大越好。
计算公式为:F1 = (2 × precision × recall)/(precision + recall)
ROC:采用不分类阈值时的TPR(真正例率)与FPR(假正例率)围成的曲线,以FPR为横坐标,TPR为纵坐标。如果 ROC 是光滑的,那么基本可以判断没有太大的overfitting(过拟合)。
TPR=TP/(TP+FN),代表分类器预测的正类中实际正实例占所有正实例的比例。
FPR=FP/(FP+TN),代表分类器预测的正类中实际负实例占所有负实例的比例,FPR越大,预测正类中实际负类越多。
AUC:计算从(0, 0)到(1, 1)之间整个ROC曲线一下的整个二维面积,用于衡量二分类问题其机器学习算法性能的泛化能力。其另一种解读方式可以是模型将某个随机正类别样本排列在某个随机负类别样本之上的概率。
PR曲线:横轴召回率,纵轴精确率。综合评价整体结果的评估指标。
# 模型推理样例代码
def eval(data_iter, model):
print("Start evaluating ...")
model.eval() #模型评估
corrects, avg_loss = 0, 0
for batch in data_iter:
feature, target = batch.text, batch.label
feature.data.t_(), target.data.sub_(1) # batch first, index align
logit = model(feature)
loss = F.cross_entropy(logit, target, size_average=False)
avg_loss += loss.data.item()
corrects += (torch.max(logit, 1)[1].view(target.size()).data == target.data).sum()
size = len(data_iter.dataset)
avg_loss /= size
accuracy = 100.0 * corrects/size
print('Evaluation - loss: {:.6f} acc: {:.4f}%'.format(avg_loss, accuracy))
print("Evaluating finished.")
return accuracy
这个eval函数是用来评估一个训练好的模型的性能的。它接受两个参数:data_iter,一个用于提供评估数据的迭代器;model,即待评估的模型。这个函数按批次处理数据,计算模型在整个数据集上的平均损失和准确率。让我们逐步解析这个函数:
-
设置模型为评估模式:
model.eval()- 在评估模式下,所有特定于训练的层(如Dropout)将被设置为不活动。
-
初始化损失和正确预测的计数:
corrects, avg_loss = 0, 0corrects用于记录正确预测的样本数,avg_loss用于累积损失值。
-
遍历评估数据:
for batch in data_iter:- 这个循环遍历评估数据的每个批次。
-
获取特征和目标标签:
feature, target = batch.text, batch.labelfeature是模型的输入数据,target是对应的真实标签。
-
调整数据维度和标签:
feature.data.t_(), target.data.sub_(1)- 这部分代码对数据进行了转置和标签调整,具体行为取决于数据的格式和模型的需求。
-
模型推理:
logit = model(feature)- 使用模型对特征进行推理,得到预测结果。
-
计算损失:
loss = F.cross_entropy(logit, target, size_average=False)- 计算预测结果和真实标签之间的交叉熵损失。
-
累积损失和正确预测数:
avg_loss += loss.data.item() corrects += (torch.max(logit, 1)[1].view(target.size()).data == target.data).sum()- 将当前批次的损失加入总损失中。
- 计算当前批次中预测正确的样本数,并累加到
corrects中。
-
计算总体平均损失和准确率:
size = len(data_iter.dataset) avg_loss /= size accuracy = 100.0 * corrects / size- 计算整个数据集上的平均损失和准确率。
-
打印评估结果:
print('Evaluation - loss: {:.6f} acc: {:.4f}%'.format(avg_loss, accuracy))
- 打印出评估过程中的平均损失和准确率。
- 返回准确率:
return accuracy- 函数返回计算得到的准确率。
需要注意的是,这个函数适用于处理分类问题,并且假设数据以特定的方式被组织和处理。另外,F.cross_entropy需要从torch.nn.functional中导入。此外,这个函数也假定了数据集的大小可以通过len(data_iter.dataset)获取。您的数据和模型的具体情况可能需要对这个函数进行一些调整。
2.2 模型可靠性评估
可靠性指在规定的条件下和规定的时间内,深度学习算法正确完成预期功能,且不引起系统失效或异常的能力。
可靠性评估指确定现有深度学习算法的可靠性所达到的预期水平的过程。
2.3 模型效率评估
在给定的软硬件环境下,深度学习算法对给定的数据进行运算并获得结果所需要的时间。
3. 作业
STEP1: 按照要求填入下方题目结果,填完之后点击运行即可
- 用test.ipnyb跑代码,预测’sorry hate you’是负面的意思还是正面的意思(0为负面意思,1为正面意思)
answer_1 = '0' #答案放入引号内
- 用test.ipnyb训练,预测’he likes baseball’是负面的意思还是正面的意思(0为负面意思,1为正面意思)
answer_2 = '1' #答案放入引号内
STEP2: 将结果保存为 csv 文件
csv 需要有两列,列名:id、answer。其中,id列为题号,从作业1开始到作业2来表示。answer 列为各题你得出的答案选项。
import pandas as pd # 这里使用下pandas,来创建数据框
answer=[answer_1,answer_2]
answer=[x.upper() for x in answer]
dic={"id":["作业"+str(i+1) for i in range(2)],"answer":answer}
df=pd.DataFrame(dic)
df.to_csv('answer5.csv',index=False, encoding='utf-8-sig')
df
| id | answer | |
|---|---|---|
| 0 | 作业1 | 0 |
| 1 | 作业2 | 1 |