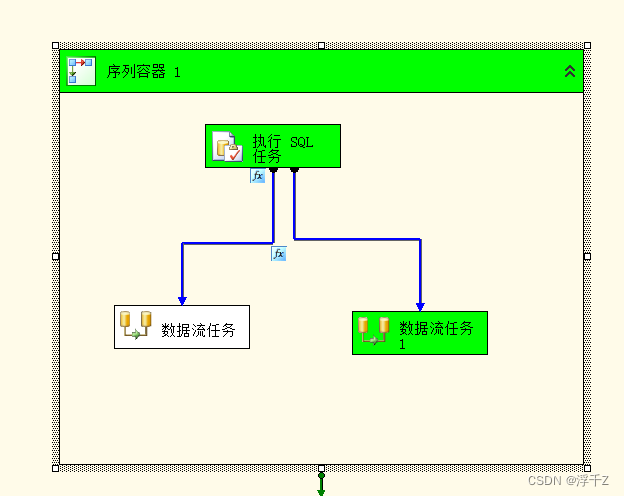
目录
- gcc/g++的使用
- gcc/g++是如何生成可执行文件的
- 预处理
- 编译
- 汇编
- 链接
- 库
- .o文件是如何与库链接的?
- debug版本和release版本
gcc/g++的使用
在windows中,我们在VS中编写好了代码之后就可以直接在VS中对源码进行编译等操作后运行
而在Linux下,我们可以使用gcc/g++编译器
gcc只能处理C语言代码
g++可以处理C++代码,也兼容C语言
对于一些指令和选项,在gcc和g++中是一样的,所以本文只介绍gcc的用法
假如现在,我们已经写好了一个C语言代码mycode.c,那么怎么将这个代码进行一些列处理,最后去运行它呢?
下面一条指令就可以:
gcc mycode.c
这条指令会默认让其可执行文件命名为a.out
如果想要自定义可执行程序,可以使用选项-o
gcc mycode.c -o mycode
这样,生成的可执行文件就叫做mycode了,并且这个写法是最推荐的写法
gcc -o mycode mycode.c这样的写法也可,记住-o选项后面永远跟着重命名的可执行程序名
接下来想要执行这个文件,执行指令:./mycode
gcc/g++是如何生成可执行文件的
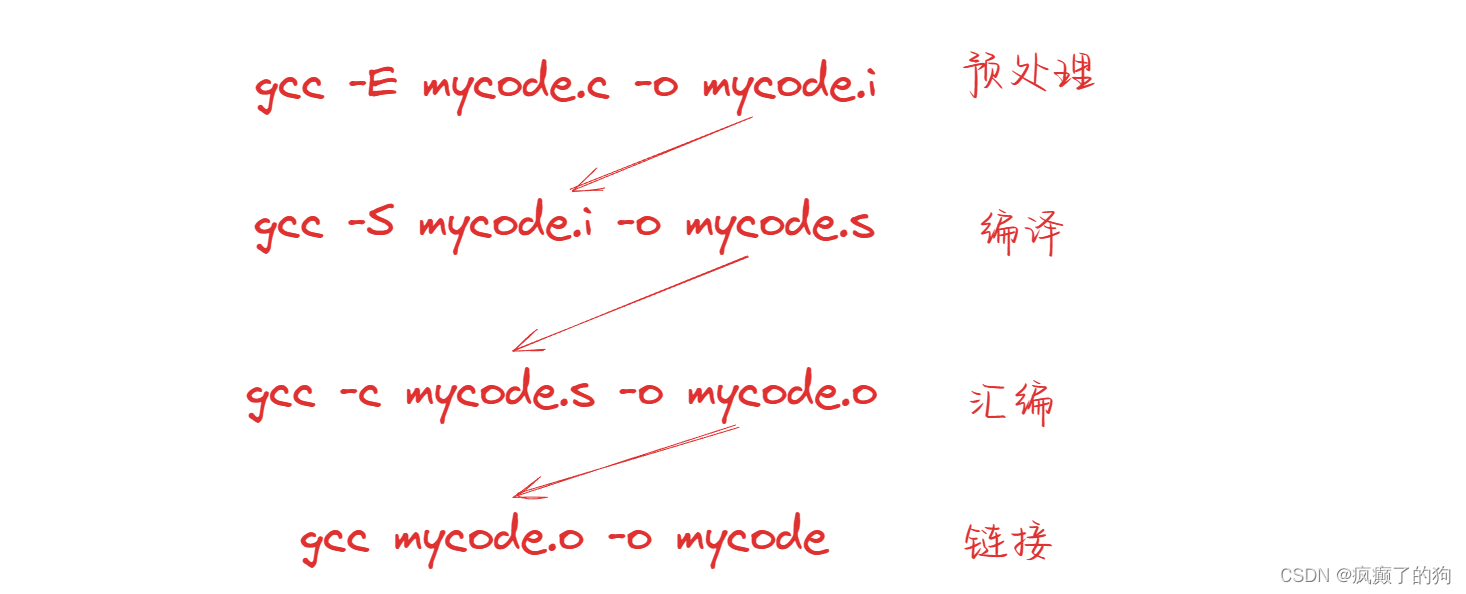
从源码开始,经过预处理,编译,汇编,链接四个步骤后,才能生成可执行程序
在gcc中,也有相应的选项去对文件进行只预处理,只编译,只汇编,只链接
下面介绍一下每个步骤的主要功能以及在gcc中相应操作
我们使用的源码很简单:
#include<stdio.h>
#define N 10
//主函数
int main()
{
for(int i = 0;i<N;i++)
{
printf("%d ",i);
}
return 0;
}
预处理
在预处理阶段,主要功能包括:展开头文件,宏替换,去注释,条件编译
gcc中的选项为-E
-E选项告诉gcc,从现在开始进行程序的翻译,将预处理做完就停下来,不再往后走
我们常将预处理后的文件命名为以.i后缀结尾的文件
gcc -E mycode.c -o mycode.i
其实,预处理后的文件还是c语言的代码,只是将头文件展开,宏替换,去注释,条件编译
我们可以用vim查看mycode.i文件
我们可以发现,mycode.i的代码有800多行,原因就是将头文件stdio.h进行了展开
查看最后面,我们可以看见自己写的代码,可以发现我们写的注释消失了,并且宏N也被替换成了10,说明也发生了去注释和宏替换
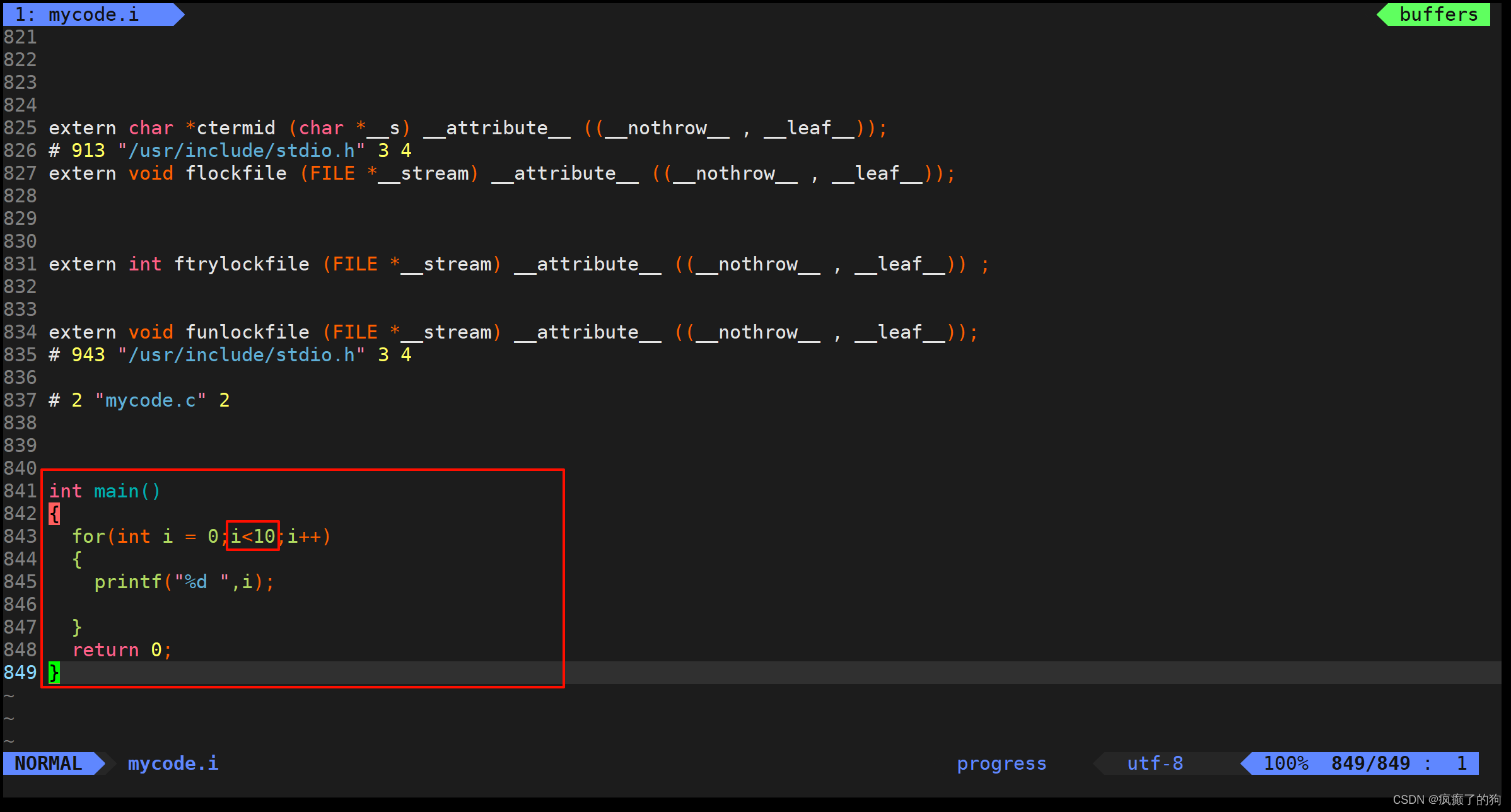
因为文中的代码没有涉及条件编译,所以这里显现不出条件编译的结果
在这一阶段,我们还可以使用-D选项进行添加宏
gcc -E mycode.c -o mycode.i -D DEBUG #添加宏DEBUG
编译
在这个阶段,gcc首先要检查代码的规范性,是否有语法的错误,以确定代码的实际要做的工作,在检查无误后,gcc把代码翻译成汇编语言
gcc中,选项- S,告诉gcc,从现在开始进行程序的翻译,将编译工作做完就停下来,不要往后走了
我们通常将编译后的汇编语言文件命名为.s后缀的文件
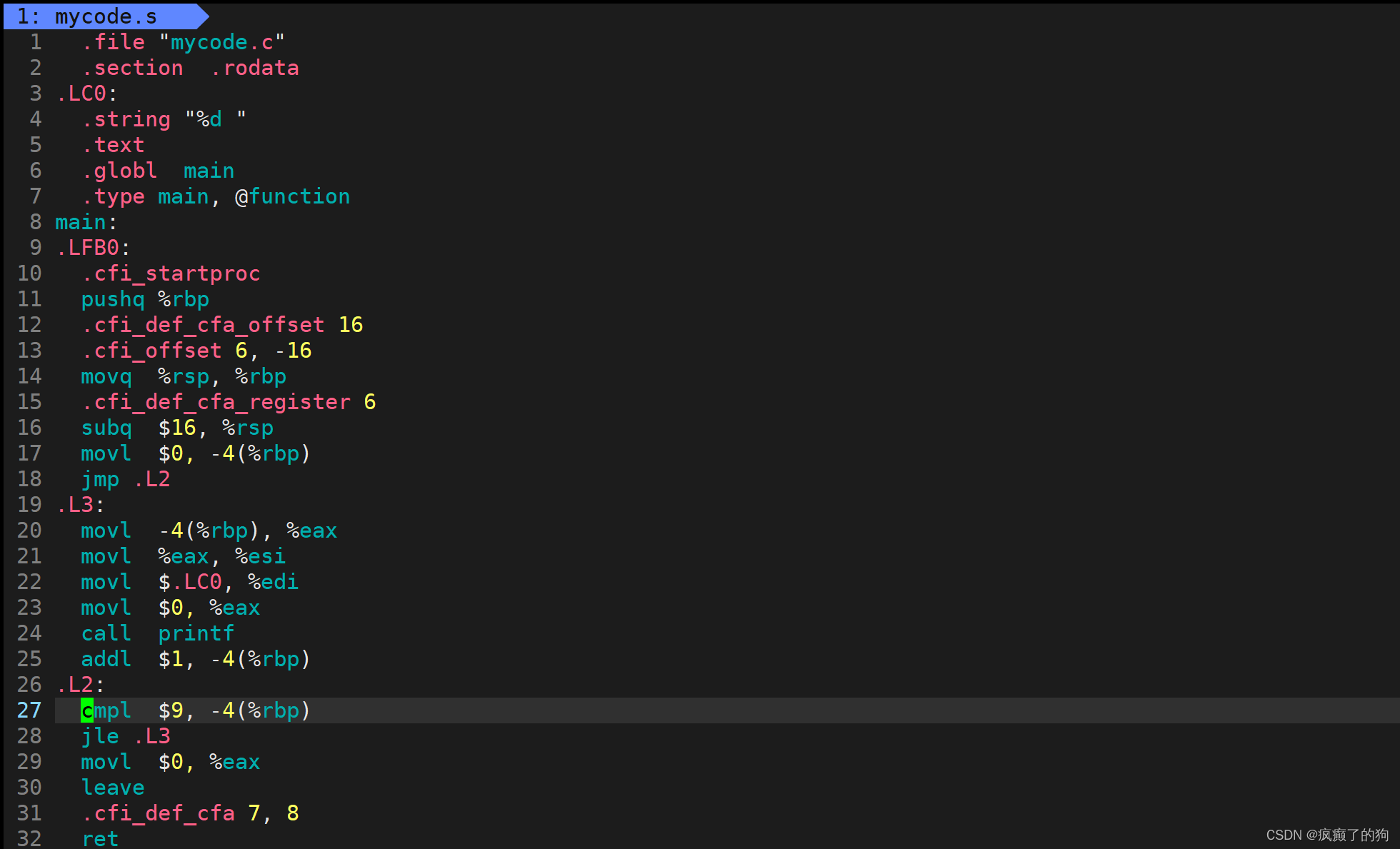
下面将mycode.i进行编译:
gcc -S mycode.i -o mycode.s
#从mycode.c还是也可以
gcc -S mycode.c -o mycode.s
进入mycode.s查看,可以看出里面是汇编代码
汇编
汇编阶段就是把汇编代码转化成机器可以识别的二进制代码
gcc中,选项-c,告诉gcc,从现在开始进行程序的翻译,将汇编工作做完就停下来,不要往后走了
我们通常将编译后的二进制机器码文件命名为.o后缀的文件
.o文件也叫做可重定位目标二进制文件,简称目标文件,即windows下的.obj文件,虽然是二进制,但还不可以独立执行,需要链接
gcc -c mycode.s -o mycode.o
用vim查看mycode.o文件,发现全是乱码

其实这是正确的现象,因为汇编之后文件中全是二进制的代码,而我们用的vim是文本编辑器,它将文件以文本的形式打开,所以会将二进制代码识别为对应的字符或符号
所以许多二进制转化为字符或符号后,它们就会组成一篇乱码,正如图片所示
链接
这个步骤,是将可重定位二进制文件与库进行连接成可执行文件
gcc中,连接没有选项
gcc mycode.o -o mycode
此时,预处理,编译,汇编,链接就都完成了,成功生成了可执行文件
readelf -S指令可以读取可执行文件对应二进制构成
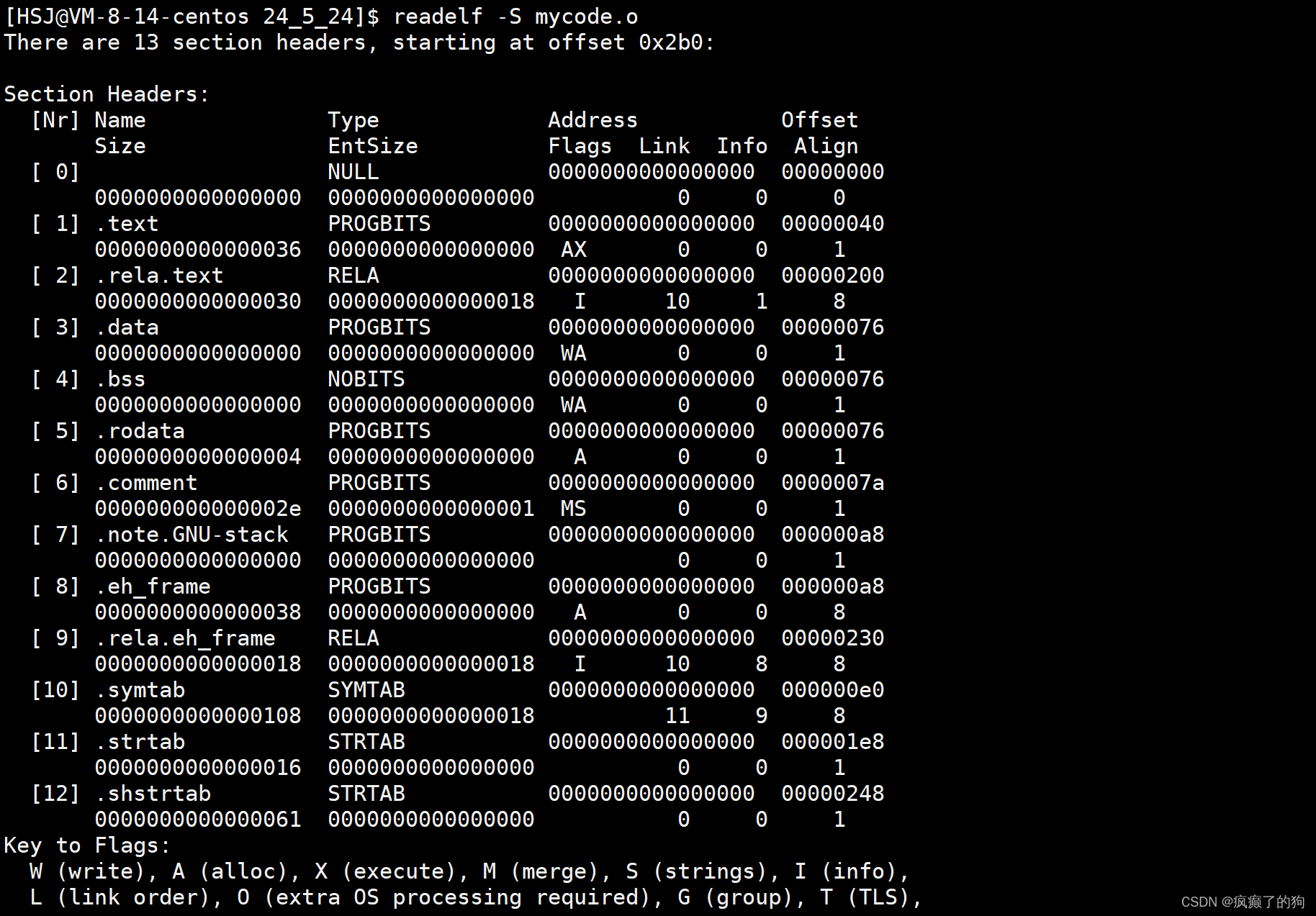
最后,总结一下:
库
前面讲链接的时候提到了库。什么是库呢?
在C程序中,我们时常使用一些库函数,实际上,我们使用库函数只是在调用函数,这些库函数的声明在头文件中,而库函数的实现就是在库中
Linux中,存放库的目录为/usr/lib64下
C语言的标准库:/usr/lib64/libc.so
其实库的本质就是一个文件
在Linux中,动态库以.so为结尾,静态库以.ac结尾
在Windows中,动态库以.dll为结尾,静态库以.lib结尾
在Linux中,库是有自己的命名规则的,拿动态库为例:libname.so.xxx
而在Linux中,默认只有动态库,静态库是没有安装的
安装静态库:
yum install -y glibc-static
yum install -y libstdc++-static
为什么在下载完VS IDE后就可以写程序了呢?
原因是,编译型语言,安装开发包,必定下载对应的头文件和库文件,所以可以直接进行编写代码
而库就是把源文件,经过一定的翻译,然后打包成库,这样就可以提供一个库文件,不用提供太多的源文件,同时也达到了隐藏源文件的目的
头文件提供方法的声明,库文件提供方法的实现+自己的代码 = 自己的程序
库的最主要功能就是避免重复工作,将已经实现的功能进行打包,供别人调用使用
.o文件是如何与库链接的?
有2中链接方式:1.动态链接 2.静态链接
动态链接:
动态链接就是所有的代码都共用一个动态库,所以动态库也叫做共享库
动态链接将动态库所处的位置拷贝到可执行文件中,在运行程序时到调用库函数的时候,会跳转到库中执行,执行完毕后,再跳会代码的调用处,继续向下执行
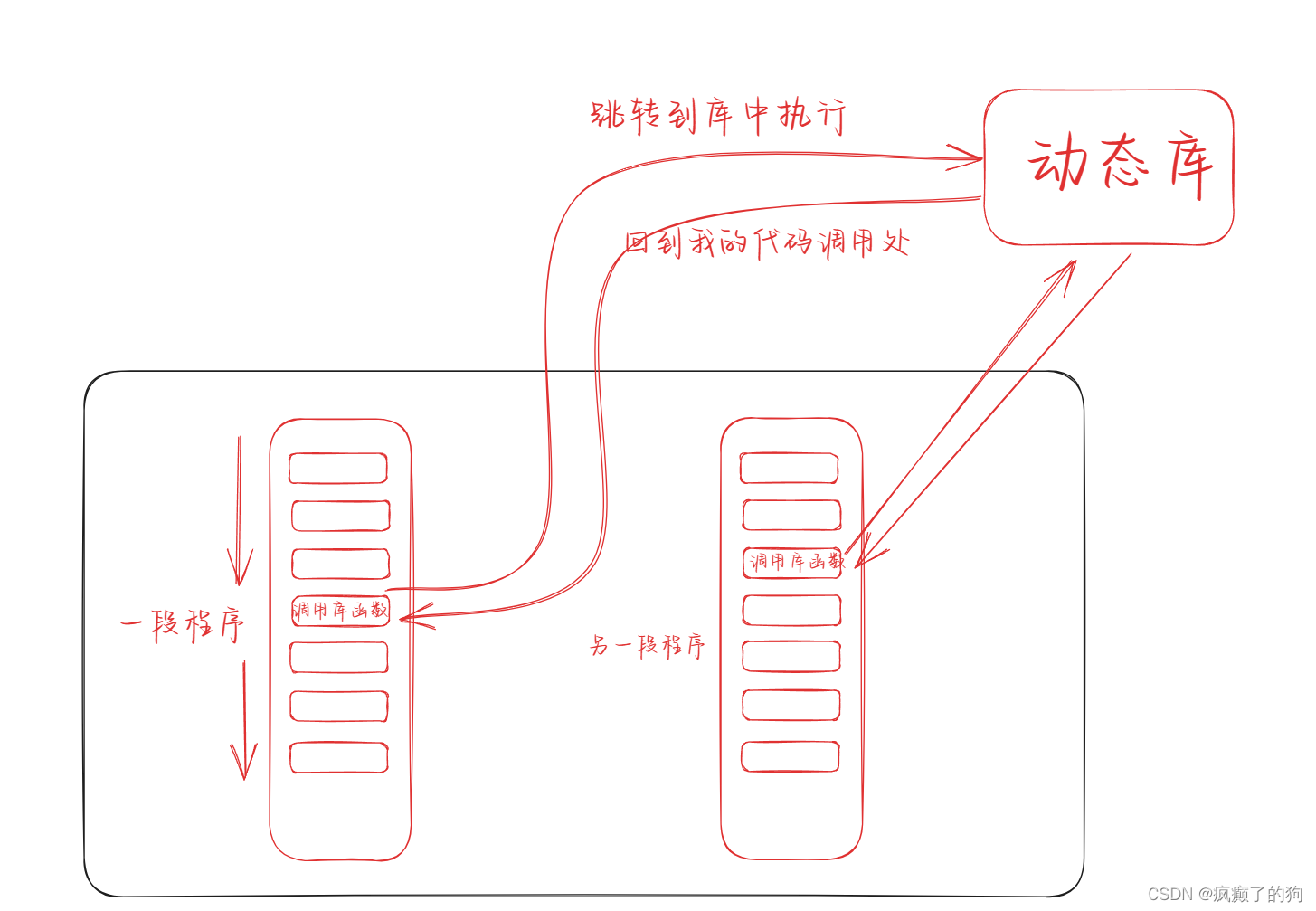
动态库不能缺失,一旦动态库缺失,影响的不止是一个程序,会导致许多程序无法正常运行
在Linux中,更不能随意删除动态库,因为Linux和Unix本身就是用C/C++编写的,其中许多的命令都会调用库函数,如果删除了动态库,不仅我们自己的代码会无法运行,就连内置的命令都无法运行,此时的Linux就可以算是废了
用指令
ldd可以查看可执行程序依赖的动态库

静态链接:
在编译器使用静态库进行静态链接时,会将自己的方法拷贝到目标程序中,使程序不再依赖静态库
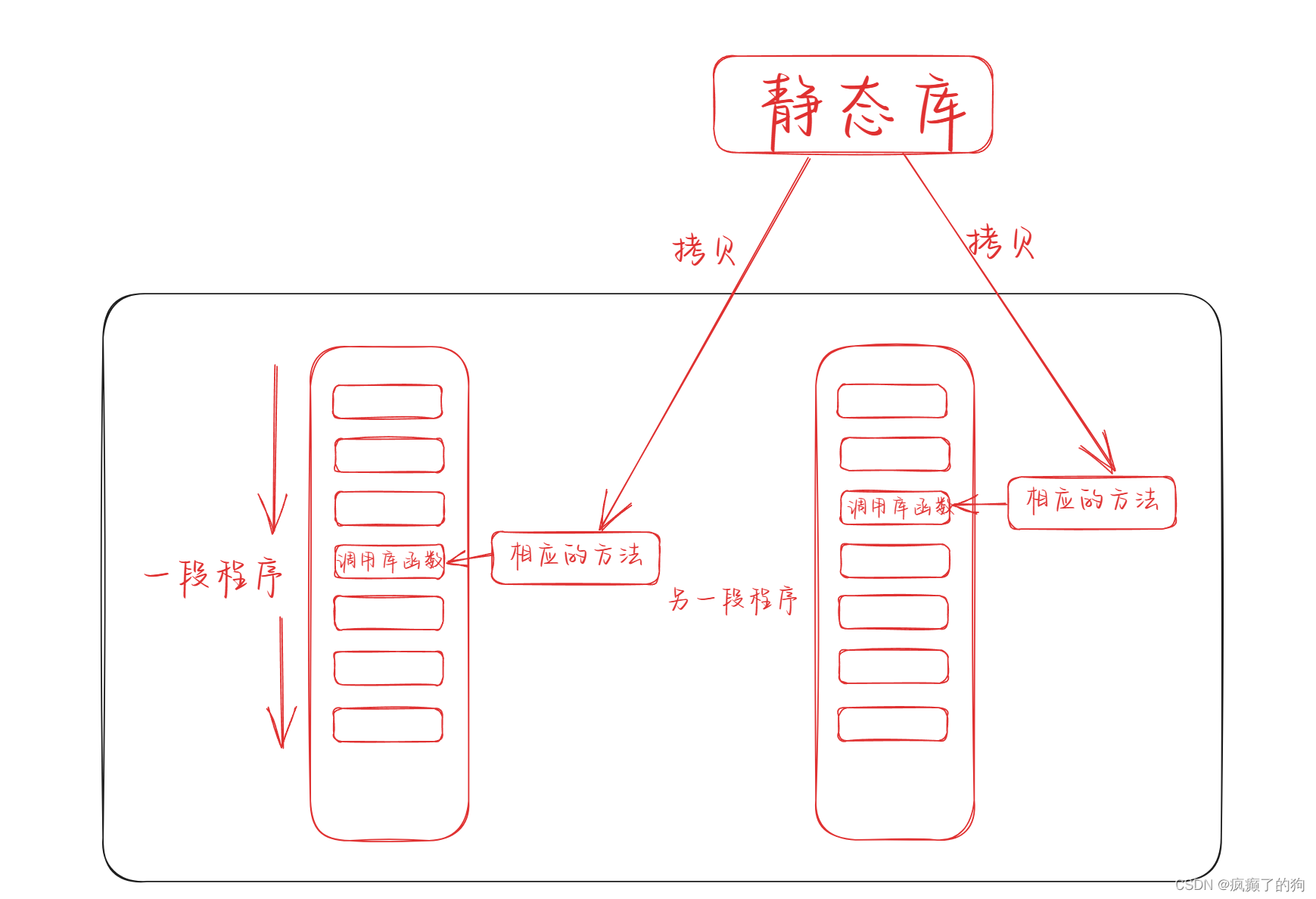
总结一下动态链接/库 和 静态链接/库
- 不论是动态库还是静态库,本质上就是2个文件,里面包含了各种的源码
- 静态链接:链接时,把库中代码拷贝自己的可执行程序里
- 动态链接:在可执行程序中不拷贝实现,只是把实现所在的位置拷贝到可执行文件中
- 静态链接后,程序不再依赖静态库
- 动态链接后,程序仍依赖动态库
Linux中,编译行程可执行代码,默认采用动态链接
通过ldd指令可以看出,我们前面生成的可执行程序mycode依赖的是动态库

在Linux中,如果要使用静态链接,要手动添加-static,并且同时系统中要有静态库,因为静态库不是系统默认提供的
下面我们将mycode.o进行静态链接
gcc mycode.o -o mycode_static -static
用ldd查看,可以看出它使用静态链接

同时,应为与动态链接相比,静态链接是将静态库中的方法实现拷贝到了可执行文件中,所以采用静态链接的可执行文件的大小一定大于采用动态链接的可执行文件大小
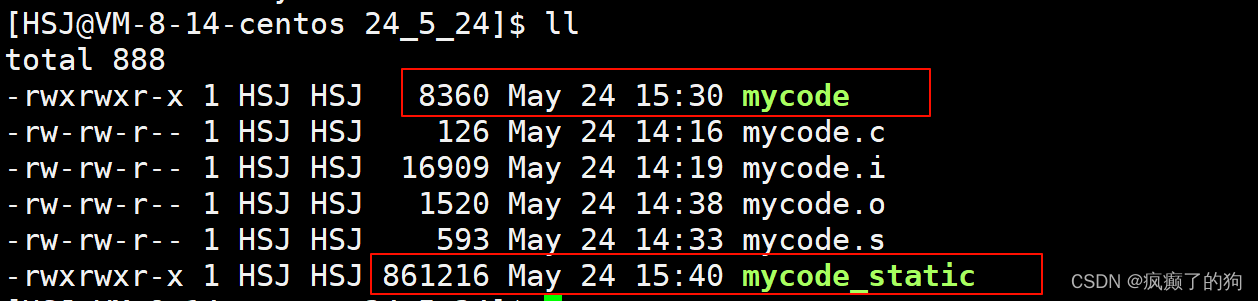
因为采取静态链接会使可执行文件大小大很多,对于传输和下载这个文件会消耗许多时间和网络,所以动态链接并不常用
用file指令可以查看一个可执行程序是动态链接的还是静态链接的

有几点需要注意:
- 如果没有静态库,还添加
-static,是不行的 - 如果没有如果没有动态库,只有动态库,并且
gcc能找到,不添加-static是可以的,因为gcc默认优先动态链接,没有动态库,就使用静态链接,而添加-static本质上是改变优先级 - 一个可执行程序不一定全部是动态链接或静态链接,也可以是混合的,因为我们的程序可能依赖各种的库,有的库提供了动态库,可能有的库没有提供,所以可以混合使用。如果加了
-static,则是让所有链接都变为动态链接,如果库不存在,则会报错
动态链接和静态链接比较:
动态链接的优点:动态库是共享的,可以有效地节省资源(硬盘空间,内存空间,网络空间等)
动态链接的缺点:动态库一旦缺失,程序将无法正常运行
静态链接的优点:不依赖库,一旦形成可执行文件,可以独立运行,可以在同平台环境下随便运行
静态链接的缺点:体积大,占空间
debug版本和release版本
gcc默认以release模式生成可执行文件
要以debug版本生成可执行文件:
gcc mycode.c -o mycode_debug -g
mycode_debug文件占的空间会比release版本大,因为debug可以被追踪、调试,生成可执行文件时,向里面添加了debug信息