1. 交叉编译
概念:在当前编译平台下,编译出来的程序能运行在体系结构不同的另一种目标平台上,但是编译平台本身却不能运行该程序。
为什么需要交叉编译?
速度:目标平台得运行速度比主机往往慢得多,因为许多专用得嵌入式硬件被设计为低成本和低功耗,没有太高的性能
容量:整个编译过程是非常消耗资源的,嵌入式系统往往没有足够的内存或磁盘空间
可移植性:一个完整的Linux编译环境需要很多支持包,交叉编译使我们不需要花时间将各种支持包移植到目标板上
交叉编译链

交叉编译链就是为了编译跨平台体系结构的程序代码而形成的由多个子工具构成的一套完整的工具集,这个工具集主要由编译器,连接器和解释器组成。同时,它隐藏了预处理、编译、汇编、链接等细节,当我们指定了源文件(.c)时,它会自动按照编译流程调用不同的子工具,自动生成最终的二进制程序映像(.bin)。
交叉编译的命名规则:
arch-core-kernel-system
arch: 用于哪个目标平台
core: 使用的是哪个CPU core, 如Cortex M3但是这一组命名好像比较灵活,在其它厂家提供的交叉编译链中,有以厂家名称命名的,也有以开发板命名的,或者直接是none或cross的.
Kernel: 所运行的操作系统, 常见的有Linux, uclinux, bare
system:交叉编译链所选择的库函数和目标映像的规范,如gnu,gnueabi等。其中gnu等价于glibc+oabi;gnueabi等价于glibc+eabi。
例子:
如果我们想要在ARM板编译出hello程序,需要使用交叉编译工具链:
arm-buildroot-linux-gnueabihf-gcc -o hello hello.c

2 GCC编译器
gcc是GNU Complier Collection的缩写。最初是作为C语言的编译器(GNU C Compiler),现在已经支持多种语言了,如C、C++、Java、Ada、COBOL语言等。其实他就是转换成机器能够读懂的语言。

一个C/C++文件要经过如上图步骤才能转换为可执行文件。
1. 预处理: 预处理就是将要include的文件插入到源文件中,将宏定义展开,根据条件编译命令选择要使用的代码,删除注释,最后输出.i文件。
2. 编译:将.i文件转换成汇编语言,进行语法检查和语义分析,优化代码并提高效率,生成.s汇编代码文件
3. 汇编: 将汇编代码转换成机器语言,生成.o目标文件
4. 链接:将多个目标文件以及库文件链接在一起,生成可执行文件,解决外部引用,即确保程序中的每个函数和变量调用都能找到正确的定义, 处理库依赖,链接系统库和数学库等。
| 常用选项 | 描述 |
| -E |
预处理,开发过程中想快速确定某个宏可以使用“
-E -dM
”
|
| -c |
把预处理、编译、汇编都做了,但是不链接
|
| -o |
指定输出文件
|
| -I (大I) |
指定头文件目录
|
| -L |
指定链接时库文件目录
|
| -l (小l) |
指定链接哪一个库文件
|
库
库(Library)是一组预先编译好的代码,这些代码可以被多个程序共享和重用。库的主要目的是提供一种方法来避免重复编写相同的代码,同时使得程序的编译和链接更加高效。
静态库:
1. 静态库在程序编译时被链接到最终的可执行文件中
2. 它们通常以.a为文件拓展名
3. 因为静态库的代码被包含在最终的可执行文件中,所以程序的体积会更大,但运行时不需要额外的库文件。
动态库:
1. 动态库在程序运行时被加载
2. 通常以.so为文件拓展名
3. 动态库允许多个程序共享同一份库代码,节省磁盘空间和内存
静态库优点:程序运行时无需加载库,运行速度更快
静态库缺点: 程序尺寸变大,静态库升级时程序需要重新编译链接
静态库的创建:
ar rcs libxxx.a xxx.o xxx.
静态库的使用:
gcc main.c -o app -I ./include/ -L ./lib -lxxx
使用的时候-I是指定头文件引用的目录, -L是指定链接静态库的目录, -l是指定引用的静态库,通常可以省略lib前缀。
动态库的创建:
制作动态库分为两个步骤,第一步是生成与位置无关的.o文件,与位置无关就是可以存在于内存中的任何地方执行,是通过间接寻址查询到的代码,有助于创建多个程序之间共享的代码。
gcc -c -fpic hello.c
gcc -shared -o libhello.so.1 hello.o // .1 是版本号
动态库的使用:
需要动态库文件存在于可执行文件能够找到的路径中,通常包括标准库路径、环境变量LD_LIBRARY_PATH(在Linux上)或PATH(在Windows上),或者在程序启动时显式指定路径,如下所示
# ==============本终端回话使用======
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/mnt/hgfs/arm_c/HQ/1_lib/2_dynamic_lib/src/
export # 查看是否成功
# ==============本用户使用========
~/.bashrc 或~/.bash_profile 文件
sudo vim ~/.bashrc 或者~/.bash_profile
# 在尾部加一句
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/mnt/hgfs/arm_c/HQ/1_lib/2_dynamic_lib/src/
# 重启配置文件
source ~/.bashrc
# ==============所有用户使用=======
# 将链接库文件移动到标准库目录下(例如 /usr/lib、/usr/lib64、/lib、/lib64)
gcc -o myprogram main.c -L/path/to/library -lmylibrary
库的搜索顺序:
① 指定动态库的搜索路径:-Wl,-rpath=路径1 : 路径2,则有限查找。
② 查不到就到LD_LIBRARY_PATH 环境变量指明的路径中查找。
③ /ect/ld.so.conf 文件中指定的搜索路径查找。
④ /lib、/lib64、/usr/lib、/usr/lib64 中查找。
3 Makefile的使用
3.1 Makefile基本规则
基本规则:如果依赖文件比目标文件更加新,那么执行命令来重新生成目标文件(目标文件还没生成或依赖文件比目标文件新),注意命令行的起始字符必须为TAB字符。
目标(target) : 依赖(prerequiries)
<tab>命令(command)elample:

3.2 make是如何工作的
1. make首先会找到当前目录下名字叫“Makefile”和“makefile”
2. 如果找到默认会寻找第一个目标文件,除非make 接相应的目标文件则会寻找相应的目标。
3. 如果第一个目标文件不存在或是依赖文件比目标文件新那么就会执行命令生成目标文件
4. 如果依赖文件不存在或者依赖文件所依赖的比他新会执行相应的命令生成依赖文件
3.3 伪目标
“伪目标”并不是一个文件,只是一个标签,由于“伪目标”不是文件,所以make无法生成它的依赖关系和决定它是否要执行。我们只有通过显示地指明这个“目标”才能让其生效。当然,“伪目标”的取名不能和文件名重名,不然其就失去了“伪目标”的意义了。 这么做的好处是避免文件系统中存在同名文件时的冲突,并且能确保每次执行假想目标时,不论目标文件是否存在,规则都会被执行。
声明假想目标
.PHONY: clean3.4 makefile的函数
1. foreach
$(foreach var, list, text)for each var in list, change it to text, 对list中的每一个元素,取出来赋给var, 然后把var改为text所描述的形式。
objs := a.o b.o
dep_files := $(foreach f, $(objs), .$(f).d) // 最终 dep_files := .a.o.d .b.o.d
2. wildcard函数
$(wildcard pattern)src_files := $( whildcard *.c) // 最终 src_files中列出了当前目录下的所有.c文件3. patsubst
$(patsubst pattern, replacement, text)将搜索模式pattern 的格式替换成replacement的格式,替换的内容为text的内容,比如将.c结尾的文件替换成.o结尾的文件。
SRC_FILES := $(patsusbt %.c, %.o, $(wildcard src/*.c))3.5 变量
$表示取变量的值,当变量名多于一个字符时,使用“()"
$符的其他用法
$^ 表示所有的依赖文件
$@ 表示生成的目标文件
$< 代表第一个依赖文件
SRC = $(wildcard *.c)
OBJ = $(patsubst %.c, %.o, $(SRC))
ALL: hello.out
hello.out: $(OBJ)
gcc $< -o $@
%.o: %.c
gcc -c $< -o $@
3.6 变量赋值
1. Makefile 使用"="进行赋值,但是要注意的是变量的值是整个Makefile最后被指定的值
VIR_A = A
VIR_B = $(VIR_A) B
VIR_A = AA这里面要注意的是最后VIR_B的值是AA B,而不是 A B, 在make的时候makefile会整个展开决定变量的值。
2. ":=" 表示直接赋值, 赋予当前位置的值, 就是变量会立即展开, 所以下面VIR_B 应该是A B
VIR_A := A
VIR_B := $(VIR_A) B
VIR_A := AA3. "?="表示如果该变量没有被赋值,赋值于等号后面的值, 如果已经被赋值,该行就不会被执行
VIR ?= new_vlaue4. “+=” 表示将符号后面的值添加到前面的变量上
3.7 通用makefile的模板
# 可执行文件名
TARGET = main
# gcc类型
CC = gcc
# 存放中间文件的路径
BUILD_DIR = build
#存放.c 源文件的文件夹
SRC_DIR = \
./ \
./src
# 存放头文件的文件夹
INC_DIR = \
./inc
# 在头文件路径前面加入-I
INCLUDE = $(patsubst %, -I %, $(INC_DIR))
# 得到带路径的 .c 文件
CFILES := $(foreach dir, $(SRC_DIR), $(wildcard $(dir)/*.c))
# 得到不带路径的 .c 文件
CFILENDIR := $(notdir $(CFILES))
# 将工程中的.c 文件替换成 ./build 目录下对应的目标文件 .o
COBJS = $(patsubst %, ./$(BUILD_DIR)/%, $(patsubst %.c, %.o, $(CFILENDIR)))
# make 自动在源文件目录下搜索 .c 文件
VPATH = $(SRC_DIR)
$(BUILD_DIR)/$(TARGET).exe : $(COBJS)
$(CC) -o $@ $^
$(COBJS) : $(BUILD_DIR)/%.o : %.c
@mkdir -p $(BUILD_DIR)
$(CC) $(INCLUDE) -c -o $@ $<
clean:
rm -rf $(BUILD_DIR)
4. 文件IO
4.1 文件的来源
Linux的文件来源:
1.存储真实文件:磁盘、flash, SD卡, U盘
2. 内核提供的虚拟文件系统:需要先挂载
3. 特殊文件:/dev/xxx设备节点, 分为字符设备和块设备
4.2 文件I/O与标准I/O
文件I/O:
文件I/O是操作系统封装了一系列open、close、write、read等API函数构成的一套用来读、写文件的接口供应用程序使用,通过这些接口可以实现对文件的读写操作,但是效率并不是最高的。(文件I/O采用系统直接调用的方式,向系统内核发出请求之后,系统内核会收到执行相关代码处理的请求,决定是否将操作硬件资源或返回结果给应用程序。)
标准I/O:
应用层C语言库函数提供了一些用来做文件读写的函数列表,叫标准I/O。标准IO有一系列的C库函数构成(fopen,fclose,fwrite,fread),这些标准IO函数其实是由文件IO封装而来的(fopen内部还是调用了open);
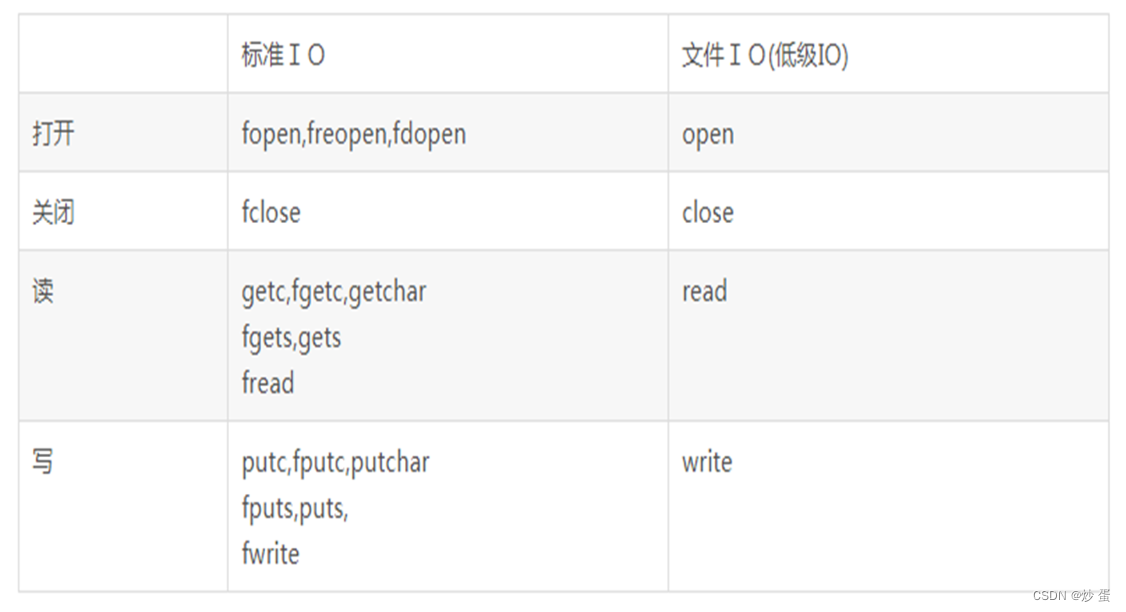
文件I/O和标准I/O的本质区别:
缓冲区:标准I/O存在缓冲区,进行操作的时候先操作缓冲区,满足一定条件才会执行系统调用。而文件I/O不存在缓冲区,直接执行系统调用。
系统开销:使用标准I/O可以减少系统调用的次数,提高系统效率。因为文件I/O会频繁调用系统调用,Linux从用户态切换到内核态,处理相应的请求,会增加系统开销。
执行开销:标准I/O每次调用写入字符,不着急写入文件,而是先放到缓冲区,直到缓冲区满足刷新的条件,再把所有数据写入文件,这个过程只用了一次系统调用,这样很大程度提高了执行效率。

4.3 文件调用的概念
1. 文件调用的基本原理
文件IO open,read, write等函数是通过glibc实现的,它们本质上还是用户层的函数,这个函数通过触发异常也就是将原因存入R7/R8的寄存器,然后指向swi 0指令,内核会识别异常原因,调用不同的处理函数,比如open对应的是sys_call_tabele[_NR_open] 和sys_open函数
2. 文件描述符fd
任何一个进程,在启动的时候都会默认打开三个文件:
- 标准输入 -- 设备文件 -> 键盘文件 0
- 标准输出 -- 设备文件 -> 显示器文件 1
- 标准错误 -- 设备文件 -> 显示器文件 2
文件描述符也是open对应的返回值,用户创建的文件返回的值是从3开始,因为0,1,2被默认打开的文件所占用了。fd的本质是数组下标。fd分配的原则是最小的 没有被使用的数组元素分配给新文件。
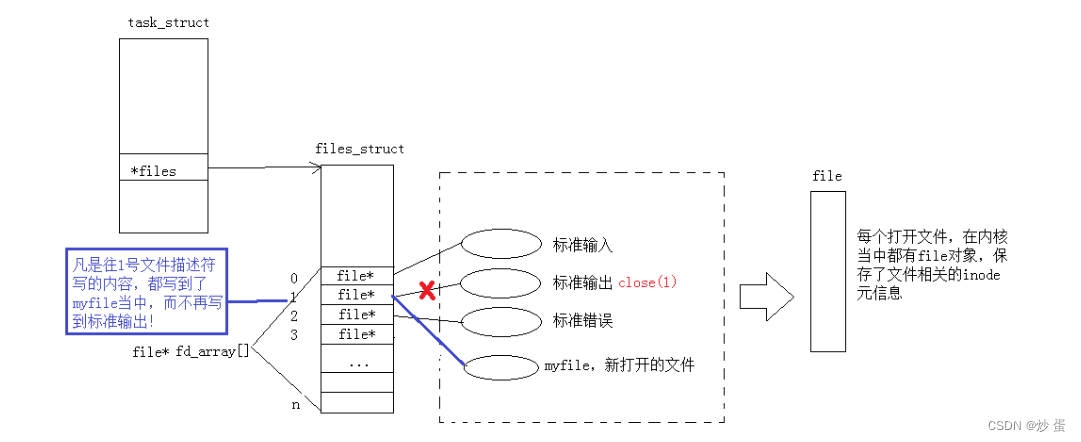
在进程中,每个进程都拥有task_struct进程控制块, task_struct里面有个指针files_struct结构体该结构体里面维护一个fd 结构体, 用于指向一张表files_struct, 该表包含了一个指针数组,而这数组里每个指针指向一个内存中的文件struct file,从而实现了进程与文件的连接,而文件描述符就是该数组的下标,只要知道文件描述符就可以找到内存中的文件。内核里面file结构体对应的是具体的文件,他的读写位置有一个变量f_pos保存读写位置。

![]()


文件流指针和文件描述符的区别
文件流指针是高级文件操作接口的表示。在许多高级编程语言和库中使用文件流指针来管理文件的读写操作。文件流指针封装了文件的缓冲区管理、字符编码处理等细节,使文件操作更加方便和安全。在c语言中,使用FILE*类型的指针,在C++中使用“ifstream”和“ofstream"类。
文件描述符是低级别操作系统接口的表示,通常用于系统调用级别的文件操作。文件流指针底层封装了文件描述符,在文件流指针结构体中可以看到 _fileno保存了fd。

3. 缓冲区的概念
行缓冲:常见的是对显示器进行刷新数据时,即必须缓冲区中一行填满了或者遇到\n才会输出到显示器。
全缓冲:对文件进行写入时采用全缓冲,即将整个缓冲区填满才会刷新到磁盘中。
无缓冲:即刷新数据时没有缓冲区
4. 文件重定向
文件重定向本质是修改files_struct表中的指针数组中指针所指向的内容。
怎么做?
在打开新的文件前,我们先close(1);关闭显示器,即上图打红叉的线被取消,所以当新的文件被打开它的文件描述符为1,即上图蓝色的线被连上,所以当往1号文件写入会被写入到log.txt而不会在显示器显示.
使用dup2系统调用实现重定向
int dup2(int oldfd, int newfd)这个函数可以理解为newfd为oldfd的拷贝,即对后者的操作变为对前者的操作。
sample
dup(fd, 1) // fd为某个新打开文件的描述符
代表本来要输出到1的内容重定向到去。
重定向定位的问题
#include<stdio.h>
#include<unistd.h>
#include<sys/types.h>
#include<sys/stat.h>
#include<fcntl.h>
int main()
{
//演示重定向基本原理
umask(0);
close(1);//关闭显示器
int fd=open("log.txt",O_WRONLY|O_CREAT,0666);//fd=1
if(fd<0){ return 1;} //打开失败
write(1,"hello world!\n",13);//写到1号文件
write(1,"hello world!\n",13);
write(1,"hello world!\n",13);
write(1,"hello world!\n",13);
write(1,"hello world!\n",13);
close(fd);
return 0;
}
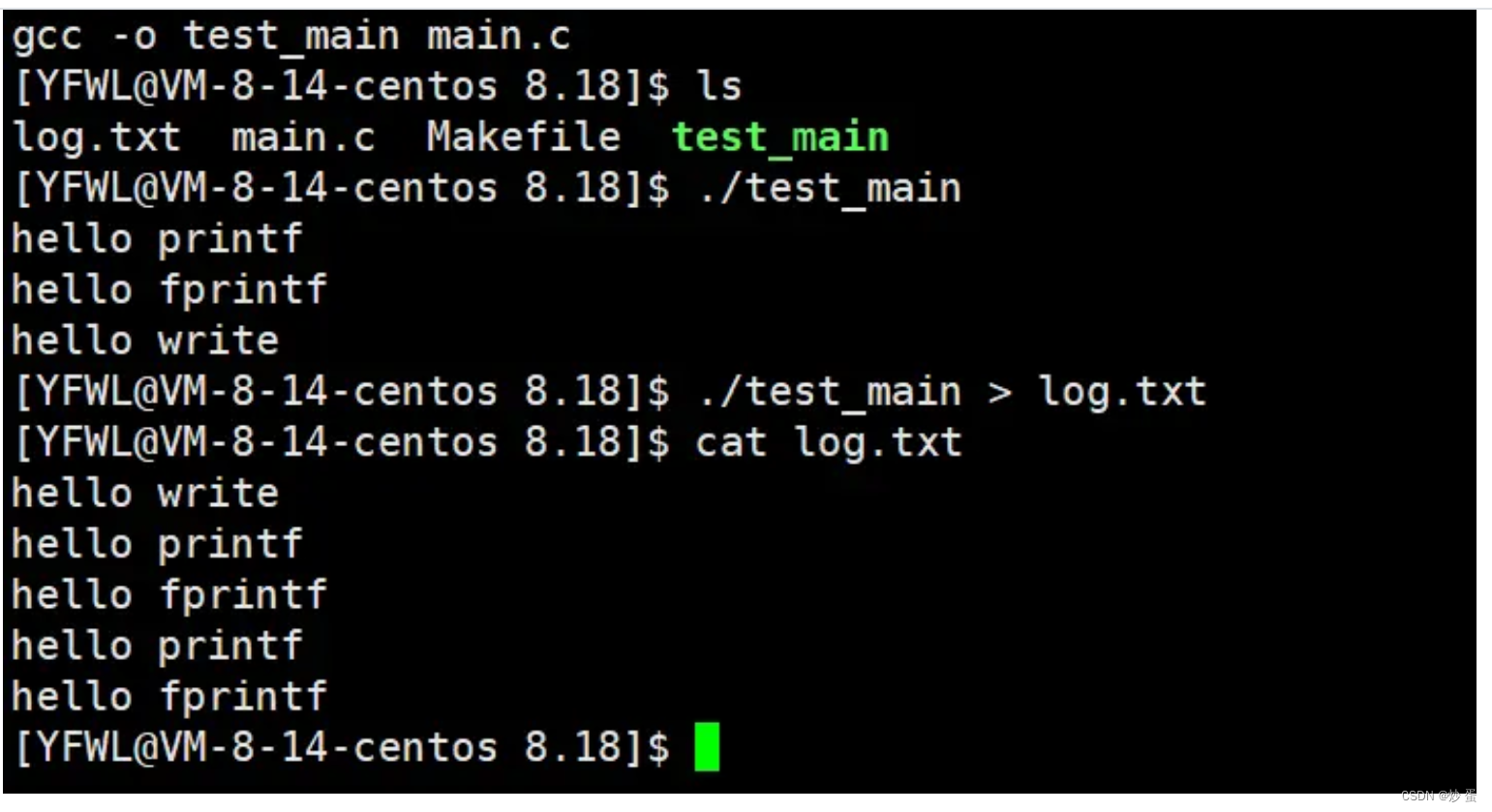
以下例子中,在第一个正常输出到显示器中,时,是正常显示三行的,但是重定向输出到文件中时,会多打印两行,当往显示器中打印时,系统采用的是行缓冲,即运行到printf等函数后,立马将数据刷新到显示器。
当重定向到文件中时,如第二个例子,缓冲方式发生变化,变为全缓冲,全缓冲会等到程序结束时,一次性将缓冲区内容打印到文件中,程序最后创建了子进程,子进程会继承父进程的缓冲区(子进程的缓冲区和父进程缓冲区内容相同,但是不是一个缓冲区,进程的独立性,发生写实拷贝)所以父进程刷新一次缓冲区后,子进程也会刷新缓冲区,所以会打印两次 C 函数的内容。因为系统函数(系统接口)没有缓冲区,所以 write函数只打印一次,并且是第一个被打印。
4.4 文件操作
打开文件open
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
打开⽂件:
int open(const char *pathname, int flags);
参数:
参数1:
const char *pathname:字符指针,表⽰的是字符的地址,
字符串的⾸地址,要打开的⽂件路径字符串的地址
参数2:
int flags:整数,打开⽂件的选项
O_RDONLY:只读
O_WRONLY:只写
O_RDWR:读写
O_TRUNC:清空⽂件(在有 写 ⽅式 有效)
O_APPEND:追加⽂件(在有 写 ⽅式 有效),在写⽂件时,在
⽂件末尾位置添加写
O_CREAT:如果⽂件不存在则,创建⽂件,存在则直接打开,
如果要使⽤当前选择,则需要第三个参数:创建⽂件权限
返回值:
失败,返回-1
成功打开⽂件,返回⽂件描述符 >= 0
创建且打开⽂件:
int open(const char *pathname, int flags, mode_t mode);读取文件 read
#include <unistd.h>
从打开的⽂件中读取⽂件内容,输⼊到程序中
ssize_t read(int fd, void *buf, size_t count);//从指定的
fd(打开的⽂件中,读取count个字节数据,存放到程序的内存buf地址开始位置)
参数:
参数1:
int fd:⽂件描述符,表⽰打开的⽂件
参数2:
void *buf:指针,表⽰把从⽂件中读取的内容,存放到程序
指定的内存地址中
参数3:
size_t count:整数,表⽰从⽂件中读取多少个字节的数据内容
返回值:
成功:返回读取到的字节数,如果返回值为0表⽰本次读取是从⽂件末尾开始读取,没有内容
失败:-1写入文件 write
#include <unistd.h>
从程序中把内存数据写⼊到⽂件中,程序输出到⽂件中
ssize_t write(int fd, const void *buf, size_t count);//把buf这个内存地址的中的数据,拿出 count字节数,写⼊到fd⽂件中
参数:
参数1:
int fd:要写⼊哪个⽂件
参数2:
const void *buf:要写⼊的内容在哪个内存地址(把哪个内存地址的内容,写⼊⽂件)
参数3:
size_t count:要写⼊内容的⼤⼩
返回值:
成功:返回写⼊的字节数
失败:返回-1关闭文件close
#include <unistd.h>
//把打开的⽂件关闭
int close(int fd);
参数:
参数1:
int fd:⽂件描述符,表⽰关闭哪个打开的⽂件
返回值:
成功:返回0
失败:返回-1设置文件偏移位置Iseek
#include <sys/types.h>
#include <unistd.h>
重新设置⽂件当前操作位置(修改偏移位置)
off_t lseek(int fd, off_t offset, int whence);//设置打开的fd⽂件的偏移位置
参数:
参数1:
int fd:表⽰打开的⽂件,要设置的⽂件
参数2:
off_t offset:整数,偏移量,表⽰偏移多少个字节
+:正数,向⽂件末尾偏移
-:负数,向⽂件开头偏移
参数3:
int whence:基准点,表⽰从哪个位置开始计算
SEEK_SET:从⽂件开始位置计算偏移
SEEK_CUR:从⽂件当前的操作位置计算偏移
SEEK_END:从⽂件末尾位置开始计算偏移
返回值:
成功:返回从⽂件开始位置到新偏移之后位置⼀共多少个字节
失败:返回-1位置偏移
#include <sys/types.h>
#include <unistd.h>
重新设置⽂件当前操作位置(修改偏移位置)
off_t lseek(int fd, off_t offset, int whence);//设置打开的fd⽂件的偏移位置
参数:
参数1:
int fd:表⽰打开的⽂件,要设置的⽂件
参数2:
off_t offset:整数,偏移量,表⽰偏移多少个字节
+:正数,向⽂件末尾偏移
-:负数,向⽂件开头偏移
参数3:
int whence:基准点,表⽰从哪个位置开始计算
SEEK_SET:从⽂件开始位置计算偏移
SEEK_CUR:从⽂件当前的操作位置计算偏移
SEEK_END:从⽂件末尾位置开始计算偏移
返回值:
成功:返回从⽂件开始位置到新偏移之后位置⼀共多少个字节
失败:返回-1目录文件操作
创建目录mkdir
#include <sys/stat.h>
#include <sys/types.h>
在指定⽬录中创建⼀个⽬录⽂件
int mkdir(const char *pathname, mode_t mode);
参数:
参数1:
const char *pathname:指针,字符串⾸地址,要创建的⽬录⽂件的路径
参数2:
mode_t mode:创建的⽬录的权限(读写执⾏)
返回值:
成功:返回0
失败:返回-1删除目录rmdir
#include <unistd.h>
int rmdir(const char *pathname);
参数:
参数1:
const char *pathname:字符串⾸地址,表⽰要删除的⽬录
返回值:
成功:返回0
失败:返回-1打开目录文件
#include <sys/types.h>
#include <dirent.h>
去打开对应路径下的⽬录
DIR *opendir(const char *name);
参数:
参数1:
const char *name:字符串⾸地址,表⽰要打开的⽬录⽂件路径
返回值:
DIR:⽬录信息结构体类型
成功:返回⽬录信息结构体的地址(指针),标识打开的⽬录⽂件
失败:返回NULL(空指针)获取打开目录中的文件readdir
#include <dirent.h>
获取打开的⽬录中,⼀个⽂件
struct dirent * readdir(DIR *dirp);
参数:
参数1:
DIR *dirp:获取哪个(打开的)⽬录中的⽂件
返回值:
成功:返回获取到的这个⽂件的描述(结构体)的地址NULL:表⽰本次获取已经获取到⽬录的结尾了没有⽂件了(已经获取完)
⽂件描述结构体
struct dirent {
ino_t d_ino;//inode号,⽂件系统中对⽂件的唯⼀编号
off_t d_off;//偏移
unsigned short d_reclen;//⻓度⼤⼩
unsigned char d_type;//⽂件类型
char d_name[256];//⽂件名
};关闭打开的目录文件closedir
#include <sys/types.h>
#include <dirent.h>
关闭打开的⽬录
int closedir(DIR *dirp);
参数:
参数1:
DIR *dirp:表⽰要关闭的⽬录⽂件
返回值:
成功:返回0
失败:返回-14.5 标准I/O
库函数:由计算机语⾔标准委员会审核通过,如 C 标准委员会,只要是使⽤ C语⾔就可以使⽤那⼀套函数
fopen打开文件
#include <stdio.h>
打开指定的⽂件
FILE *fopen(const char *pathname, const char *mode);
参数:
参数1:
const char *pathname:字符串⾸地址,表⽰要打开的⽂件路径
参数2:
const char *mode:字符串⾸地址,通过通过字符串来表⽰打开⽂件的⽅式
"r":只读⽅式打开(⽂件必须存在)---------O_RDONLY
"r+":读写⽅式打开--------O_RDWR
"w":只写⽅式打开(清空⽂件,当⽂件不存在时创建)----O_WRONLY | O_CREAT | O_TRUNC
"w+":读写⽅式打开(清空⽂件,当⽂件不存在时创建)---O_RDWR | O_CREAT | O_TRUNC
"a":追加写⽅式打开(操作位置在⽂件末尾,当⽂件不存在时创建)---O_WRONLY | O_CREAT | O_APPEND
"a+":读写⽅式打开(写为追加写操作位置在⽂件末尾,当⽂件不存在时创建)-----O_RDWR | O_CREAT |
O_APPEND
如果上述字符串中 包含'b'表⽰打开⼆进制⽂件,否则打开是⽂本⽂件
返回值:
FILE:是⼀个结构体,描述打开的⽂件信息(包括了⽂件描述符)
返回值就是返回FILE这个结构体类型变量的地址成功:返回FILE * 指针,⽂件信息结构体地址(能知
道打开的⽂件)
失败:返回NULL(空指针)关闭文件fclose
#include <stdio.h>
关闭⽂件,则会把当前打开的⽂件的缓冲区存放到⽂件中
int fclose(FILE *stream);
参数:
参数1:
FILE *stream:关闭打开的哪个⽂件
返回值:
成功:返回0
失败:返回-1(EOF)写入文件fwrite
#include <stdio.h>
把数据写⼊到⽂件
size_t fwrite(const void *ptr, size_t size, size_tnmemb,FILE *stream);
参数:
参数1:
const void *ptr:要写⼊⽂件的内容对应地址
参数2:
size_t size:每⼀个数据⼤⼩
参数3:
size_t nmemb:写⼊多少个数据
参数4:
FILE *stream:写⼊的⽂件
返回值:
成功:返回写⼊的数据的个数读取文件fread
#include <stdio.h>
从⽂件中读取数据存放到ptr
size_t fread(void *ptr, size_t size, size_t nmemb, FILE*stream);
参数:
参数1:
void *ptr:从⽂件中读取的数据存放的位置(指针)
参数2:
size_t size:每个数据⼤⼩(字节)
参数3:
size_t nmemb:读取多少个数据
参数4:
FILE *stream:读取的⽂件
返回值:
成功:返回读取的数据个数
0:表⽰读取时没有数据可读(到达⽂件末尾) , 或 读取错误读取单个字符fgetc
#include <stdio.h>
从⽂件中读取⼀个字符,以返回值形式,返回读取到的字符(int)
int fgetc(FILE *stream);
参数:
参数1:
FILE *stream:从哪个⽂件中读取
返回值:
成功:返回读取到的字符,以int类型(字符对应的ASCII码)表⽰
如果本次是在⽂件末尾位置读取(⽂件结束位置),返回EOF(-1)
如果读取失败,返回EOF需要判断 EOF到底是失败还是读取到⽂件末尾
int getc(FILE *stream); ==== fgetc
int getchar(void); == fgetc(stdin):从终端⽂件读取(输⼊)⼀个字符写入单个字符fputc
#include <stdio.h>
往⽂件中写⼊⼀个字符
int fputc(int c, FILE *stream);
参数:
参数1:
int c:要写⼊的字符的ASCII码
参数2:
FILE *stream:要写⼊的⽂件
返回值:
成功:返回写⼊的字符的ASCII码
失败:返回EOF(-1)
int putc(int c, FILE *stream); 等价于 fputc
int putchar(int c);等价于 ===== fputc(c,stdout),往终端⽂件写⼊⼀个字符读取一个字符串fgets
#include <stdio.h>
从⽂件中读取⼀个字符串
char *fgets(char *s, int size, FILE *stream);从⽂件 stream中读取内容,最多读取size-1个字符,存储到s指针这个地址中。具体读取的字符⼤⼩:⼆选⼀
1、读取到⽂件结束
2、读取到⼀⾏结束(\n)
如果在读取过程中当读取到size-1时,两个都不满⾜,则读取size-1个字符(读取最⼤⼤⼩)
注意:在读取的字符串后,加上'\0'字符,表⽰字符串的结束
返回值:
成功:返回 s 指针
NULL:本次读取在⽂件结束位置读取(已经读取到⽂件末尾)
char *gets(char *s);等价于 == fgets(s,,stdin),从终端上读取⼀个字符串,没有限制⼤⼩(没有size-1)容易越界写⼊⼀个字符串
#include <stdio.h>
把s中的字符串('\0'为⽌),写⼊到⽂件中
int fputs(const char *s, FILE *stream);
参数:
参数1:
const char *s:要写⼊的字符串,到'\0'为⽌
参数2:
FILE *stream:写⼊的⽂件
返回值:
成功:⾮负整数 >= 0
失败:EOF(-1)
int puts(const char *s);等价于 ==== fputs(s,stdout),往终端上写字符串刷新标准io缓冲区
#include <stdio.h>
主动把缓冲区的内容写⼊⽂件
int fflush(FILE *stream);判断是否错误或读取到⽂件结束
#include <stdio.h>
测试当前是否是⽂件末尾,如果是⽂件末尾返回⾮0(返回真)
int feof(FILE *stream);
测试当前是否是错误,如果是错误返回⾮0
int ferror(FILE *stream);面经:
如何操作文件以及判断文件是否存在?请说明open、read、write等函数的使用?
首先使用access函数判断文件是否存在,然后使用open函数打开文件,可以使用O_CREAT标志在不存在的时候创建函数,使用’read'函数读取文件内容,使用‘write’函数向文件写入内容,使用‘close’函数关闭文件。open函数主要用于打开文件并返回文件描述符,可以指定打开的路径和文件的打开方式,如只读,只写,读写和创建文件等。read用于从文件描述符读取数据到缓冲区,write是将缓冲区的数据写入文件描述符,这三个函数都是系统级别的调用。
链接:
【Linux】深入理解文件IO操作_linux文件io球滚动-CSDN博客