神经网络优化算法
文章目录
- 神经网络优化算法
- 梯度下降算法
- 批量梯度下降法
- 随机梯度下降法
- 小批量随机梯度下降法
- 动量法
- NAG
- AdaGrad
- RMSProp
- ADADELTA
- ADAM
- NADAM
梯度下降算法
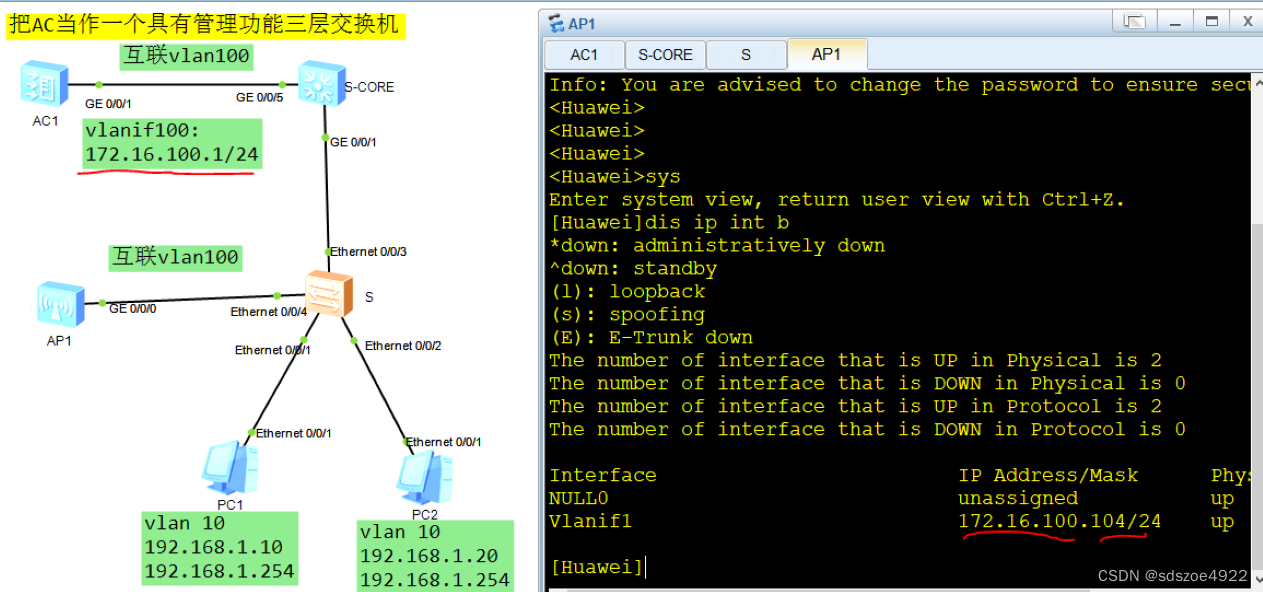
以 f ( x ) = 1 2 x 2 f(x)=\frac12x^2 f(x)=21x2为例展示了梯度下降法中梯度下降的实际情况,图中的箭头表示梯度下降的方向。可以将 x x x往 导数的反方向移动一小步来减小 f ( x ) f( x) f(x)即取 x ′ = x − ϵ f ′ ( x ) x^{\prime}=x-\epsilon f^{\prime}(x) x′=x−ϵf′(x)为新的参考点,这种技术称为梯度下降。
梯度下降的步骤如下:
- 初始化参数值。
- 计算当前参数下损失函数的梯度。
- 按照梯度的方向和学习率对参数进行更新,学习率决定了每一步参数 调整的大小。
- 重复步骤2和3,直到达到预定的停止条件(如达到最大迭代次数或损 失函数收敛到指定的值)。
- 通过不断更新参数,梯度下降法能够使模型逐渐朝着更小的损失函数 值移动,从而找到损失函数的局部最小值或全局最小值。
需要注意的是,梯度下降法可能会陷入局部最小值而无法到达全局最小值。 为了解决这个问题,可以使用不同的改进方法,
- 批量梯度下降法(Batch Gradient Descent,BGD)
- 随机梯度下降法(Stochastic Gradient Descent,SGD)
- 小批量随机梯度下降法(Mini-batch Stochastic Gradient Descent, mini-batch SGD)
批量梯度下降法
批量梯度下降法(Batch Gradient Descent,BGD)是在更新参数的时候 使用所有的样本进行更新,假设一个批次中有𝑛个样本,则计算梯度的时候 使用这个批次中所有𝑛个样本的梯度数据,计算公式:
x
′
=
x
−
ϵ
∑
j
=
1
n
∇
x
j
f
(
x
j
)
x^{\prime}=x-\epsilon\sum_{j=1}^n\nabla_{x_j}f(x_j)
x′=x−ϵj=1∑n∇xjf(xj)
因为需要计算整个批次的梯度来执行一次更新,所以批量梯度下降法可能非常缓慢,并且对于内存不适合的数据集来说是难以处理的,而且批量梯 度下降法也不允许在线更新模型。
随机梯度下降法
随机梯度下降法(Stochastic Gradient Descent,SGD)与批量梯度下降法相对应,区别在于求梯度时没有用一个批次中的所有𝑛个样本数据,而是随机选取其中一个样本来求梯度,计算公式:
x
′
=
x
−
ϵ
∇
x
j
f
(
x
j
)
x^{\prime}=x-\epsilon\nabla_{x_j}f(x_j)
x′=x−ϵ∇xjf(xj)
由于每次仅采用一个样本来迭代,训练速度很快。但是基于这种方法的模型对每个实例都非常敏感,造成了收敛中的不稳定,来回波动,当然实例引发的波动可能使模型跳过皱褶,找到更好的局部最小值。
已有研究表明,当缓慢降低学习率时,SGD表现出与批量梯度下降法相同的收敛行为,对于非凸优化和凸优化,几乎可以分别收敛到局部最小值或全局最小值。
小批量随机梯度下降法
小批量随机梯度下降法(Mini-batch Stochastic Gradient Descent, mini-batch SGD)是批量梯度下降法和随机梯度下降法的折衷,也就是对于一个批次中的所有𝑛个样本,采用𝑘个样本来迭代:
x
′
=
x
−
ϵ
∑
j
=
t
t
+
k
−
1
∇
x
j
f
(
x
j
)
x^{\prime}=x-\epsilon\sum_{j=t}^{t+k-1}\nabla_{x_j}f(x_j)
x′=x−ϵj=t∑t+k−1∇xjf(xj)
小批量随机梯度下降法一方面减少了参数更新的方差,使得损失函数更稳定的收敛,另一方面可以利用最先进的深度学习库中常见的矩阵优化,使梯度的计算非常高效。常见的小批量大小在50-256之间,但不同的数据集可能会有所不同。
动量法
随机梯度下降法容易导致模型陷入局部最优或者鞍点,且梯度更新不稳定, 容易陷入震荡。
针对此问题,动量(Momentum)法提出在随机梯度下降法的基础上,引入动量的概念,使用指数移动平均值取代梯度计算,计算公式
x
′
=
x
−
ϵ
m
t
=
x
−
ϵ
(
β
m
t
−
1
+
∇
x
j
f
(
x
j
,
t
)
)
x^{\prime}=x-\epsilon m_t=x-\epsilon\left(\beta m_{t-1}+\nabla_{x_j}f(x_j,t)\right)
x′=x−ϵmt=x−ϵ(βmt−1+∇xjf(xj,t))
其中
ϵ
\epsilon
ϵ表示学习率,
m
t
m_t
mt即为引入的动量,它累加了过去的梯度信息
m
t
=
β
m
t
−
1
+
∇
x
j
f
(
x
j
,
t
)
=
β
(
β
m
t
−
2
+
∇
x
j
f
(
x
j
,
t
−
1
)
)
+
∇
x
j
f
(
x
j
,
t
)
=
∑
τ
=
0
t
−
1
β
τ
∇
x
j
f
(
x
j
,
t
−
τ
)
\\m_t=\beta m_{t-1}+\nabla_{x_j}f(x_j,t)=\beta\left(\beta m_{t-2}+\nabla_{x_j}f(x_j,t-1)\right)+\nabla_{x_j}f(x_j,t)= \sum_{\tau=0}^{t-1}\beta^\tau\nabla_{x_j}f(x_j,t-\tau)
mt=βmt−1+∇xjf(xj,t)=β(βmt−2+∇xjf(xj,t−1))+∇xjf(xj,t)=τ=0∑t−1βτ∇xjf(xj,t−τ)
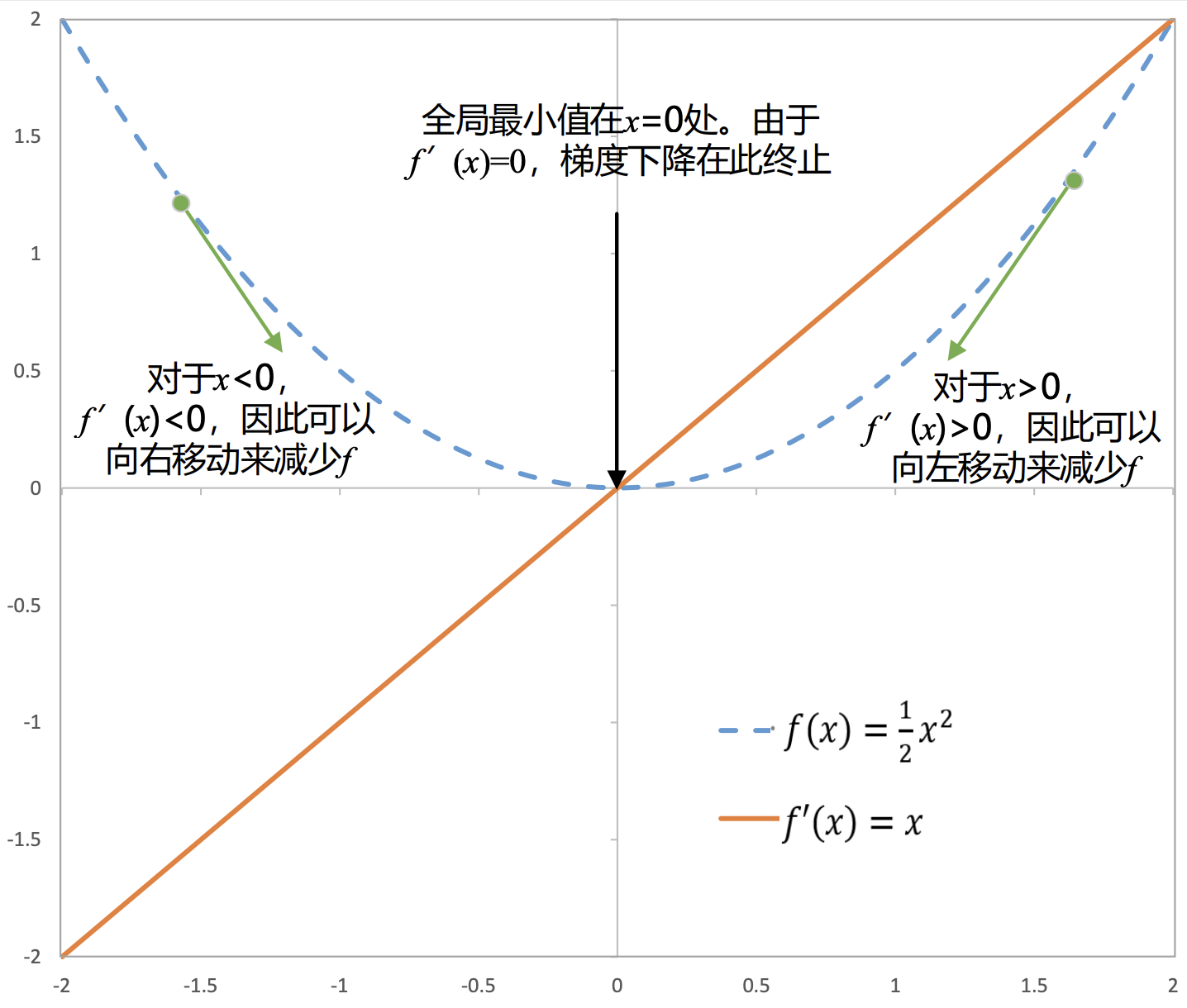
直观来看,动量在当前时刻的梯度上,增加了与先前时刻梯度相关的
β
m
t
−
1
\beta m_{t-1}
βmt−1,增加了与先前时刻梯度相关的
β
m
t
−
1
\beta m_{t-1}
βmt−1,即当前时刻参数的更新方向不仅由当前梯度方向决定,也与之前累积的梯度方向(动量方向)相关。如图所示,对于参数中梯度方向变化不大的维度,动量的引入可以加速参数收敛;而针对梯度方向变化较大的维度,则可以缓解震荡现象。
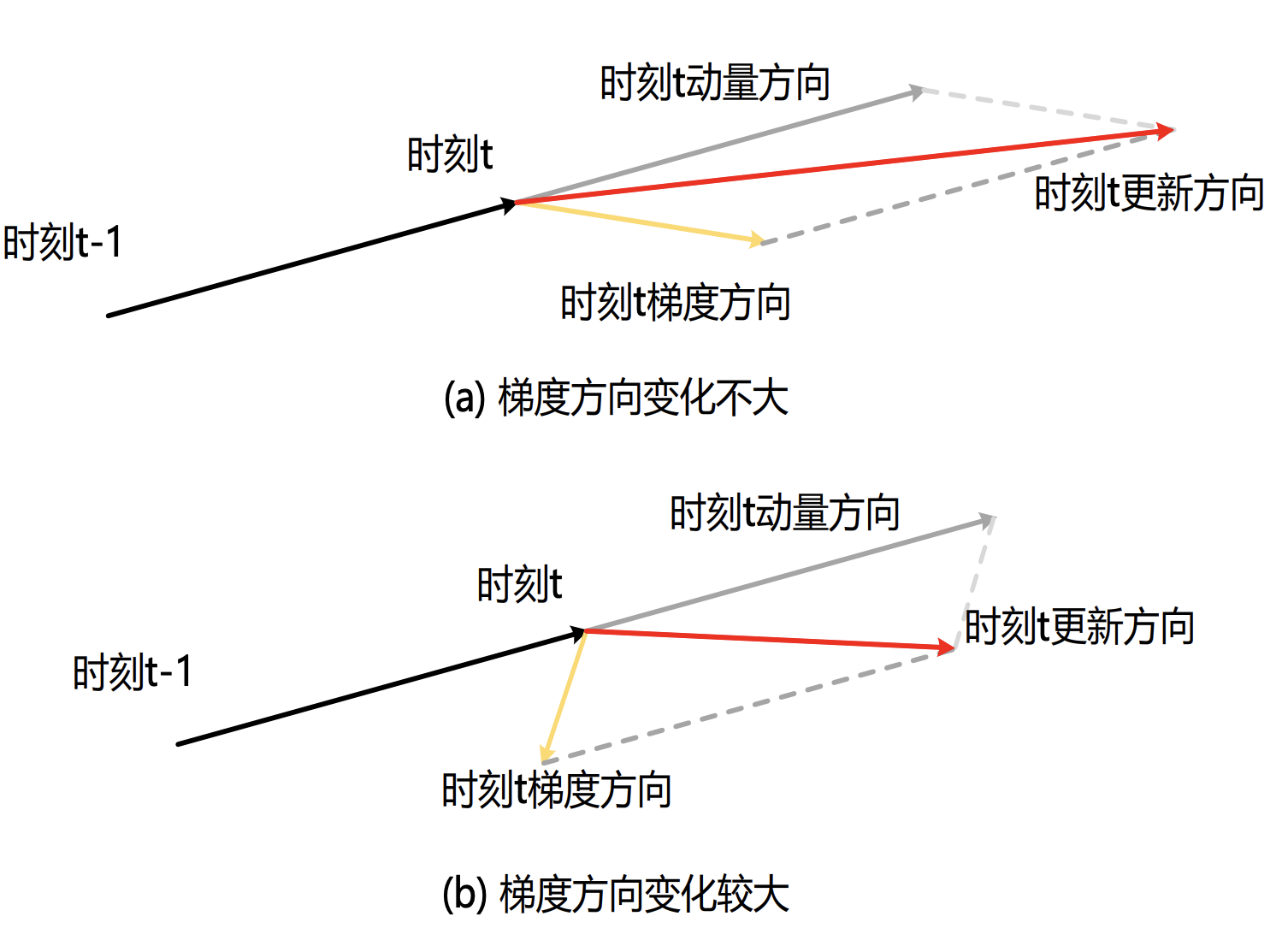
NAG
NAG(Nesterov Accelerated Gradient)针对动量法进行了进一步改进,动量法中计算的为当前时刻的梯度,NAG提出计算参数经过更新之后时刻的梯度:
x
′
=
x
−
ϵ
m
t
=
x
−
ϵ
(
β
m
t
−
1
+
∇
x
j
f
(
x
j
−
β
m
t
−
1
,
t
)
)
x'=x-\epsilon m_t=x-\epsilon\left(\beta m_{t-1}+\nabla_{x_j}f\left(x_j-\beta m_{t-1},t\right)\right)
x′=x−ϵmt=x−ϵ(βmt−1+∇xjf(xj−βmt−1,t))
动量法与NAG参数更新方向的比较如图所示,对于动量法,参数更新方向1由当前步的动量方向和梯度方向1决定。对于NAG,其相较于动量法多了一步前瞻操作,即先对当前步应用动量方向进行参数更新以得到梯度方向2,然后结合动量方向得到参数更新方向2。
AdaGrad
以上方法均使用相同的学习率对所有参数进行更新,但是对于不常见的参数,由于其更新频率低可能导致其无法更新到较好的状态。解决此问题的一个思路是在训练过程中对不同参数的学习率进行动态调整: 对于常见参数,由于其更新频率高从而调低其学习率;对于不常见参数, 由于其更新频率低从而调高其学习率。
可以记录截至第 t t t步参数 x x x被更新的次数 s ( Θ , t ) s(\Theta,t) s(Θ,t),并将其学习率设置为 ϵ = ϵ 0 s ( Θ , t ) + c \epsilon=\frac{\epsilon_0}{\sqrt{s(\Theta,t)+c}} ϵ=s(Θ,t)+cϵ0其中, ϵ 0 \epsilon_0 ϵ0为设置的初始全局学习率, c c c为一个较小的正数,常设置为 10 − 6 {10}^{-6} 10−6用于保证数值稳定性,避免分母为零。
AdaGrad (Adaptive Gradient) 算法提出使用梯度的平方和作为
s
(
Θ
,
t
)
s(\Theta,t)
s(Θ,t)的
替换估计,记为
s
t
:
s_t:
st:
x
′
=
x
−
ϵ
0
s
t
+
c
∇
x
j
f
(
x
j
,
t
)
s
t
=
s
t
−
1
+
∇
x
j
f
(
x
j
,
t
)
2
\begin{aligned} x^{\prime}&=x-\frac{\epsilon_0}{\sqrt{s_t+c}}\nabla_{x_j}f(x_j,t)\\ s_t&=s_{t-1}+\nabla_{x_j}f\left(x_j,t\right)^2 \end{aligned}
x′st=x−st+cϵ0∇xjf(xj,t)=st−1+∇xjf(xj,t)2
AdaGrad也存在一定问题:首先AdaGrad依赖于初始全局学习率 ϵ 0 \epsilon_0 ϵ0,如果初始全局学习率太大,会使得训练初期对梯度的调节太大;此外随着训练次数的迭代,累积的梯度平方和会越来越大,会使得学习率单调递减至0,从而导致训练提前结束。
RMSProp
为解决AdaGrad中存在的梯度累计导致的学习率递减至0的问题 ,RMSProp(Root Mean Square Prop)改用指数移动平均改善学习率动态调整过程:
x
′
=
x
−
ϵ
0
s
t
+
c
∇
x
j
f
(
x
j
,
t
)
s
t
=
γ
s
t
−
1
+
(
1
−
γ
)
∇
x
j
f
(
x
j
,
t
)
2
\begin{aligned} x^{\prime}&=x-\frac{\epsilon_0}{\sqrt{s_t+c}}\nabla_{x_j}f(x_j,t)\\ s_t&=\gamma s_{t-1}+(1-\gamma)\nabla_{x_j}f\left(x_j,t\right)^2 \end{aligned}
x′st=x−st+cϵ0∇xjf(xj,t)=γst−1+(1−γ)∇xjf(xj,t)2
其中, γ \gamma γ为指数移动平均的加权系数,且 γ ∈ [ 0 , 1 ] \gamma\in[0,1] γ∈[0,1]。RMSProp改善了AdaGrad存在的问题,但是仍然需要手动指定初始学习率 ϵ 0 \epsilon_0 ϵ0。
ADADELTA
ADADELTA是AdaGrad的另一种变体,同时使用了两个状态变量, s t s_t st与RMSProp一样用于存储梯度平方和(二阶动量)的指数移动平均值, Δ x t \Delta x_t Δxt 用于存储模型本身参数更新变量平方和的指数移动平均值。
其中
x
′
=
x
−
Δ
x
t
−
1
+
c
s
t
+
c
∇
x
j
f
(
x
j
,
t
)
s
t
=
γ
s
t
−
1
+
(
1
−
γ
)
∇
x
j
f
(
x
j
,
t
)
2
Δ
x
t
−
1
=
γ
Δ
x
t
−
2
+
(
1
−
γ
)
g
t
−
1
2
g
t
−
1
=
Δ
x
t
−
2
+
c
s
t
−
1
+
c
∇
x
j
f
(
x
j
,
t
−
1
)
\begin{aligned} x^{\prime}&=x-\frac{\sqrt{\Delta x_{t-1}+c}}{\sqrt{s_t+c}}\nabla_{x_j}f(x_j,t)\\ s_t&=\gamma s_{t-1}+(1-\gamma)\nabla_{x_j}f(x_j,t)^2\\ \Delta x_{t-1}&=\gamma\Delta x_{t-2}+(1-\gamma)g_{t-1}^2\\ g_{t-1}&=\frac{\sqrt{\Delta x_{t-2}+c}}{\sqrt{s_{t-1}+c}}\nabla_{x_j}f(x_j,t-1) \end{aligned}
x′stΔxt−1gt−1=x−st+cΔxt−1+c∇xjf(xj,t)=γst−1+(1−γ)∇xjf(xj,t)2=γΔxt−2+(1−γ)gt−12=st−1+cΔxt−2+c∇xjf(xj,t−1)
从上式可看出,ADADELTA无需人工指定学习率。
ADAM
动量法在SGD的基础上引入了一阶动量,AdaGrad、RMSProp和ADADELTA则引入了二阶动量。ADAM (Adaptive Moment)则同时利用了梯度的一阶动量和二阶动量,其参数更新公式如下:
x
′
=
x
−
ϵ
m
^
t
s
^
t
+
c
m
t
=
β
1
m
t
−
1
+
(
1
−
β
1
)
∇
x
j
f
(
x
j
,
t
)
,
m
^
t
=
m
t
1
−
β
1
t
s
t
=
β
2
s
t
−
1
+
(
1
−
β
2
)
∇
x
j
f
(
x
j
,
t
)
2
,
s
^
t
=
s
t
1
−
β
2
t
\begin{aligned} x^{\prime}&=x-\epsilon\frac{\widehat{m}_t}{\sqrt{\hat{s}_t}+c}\\ m_t&=\beta_1m_{t-1}+(1-\beta_1)\nabla_{x_j}f(x_j,t),\quad\widehat{m}_t=\frac{m_t}{1-\beta_1^t}\\ s_t&=\beta_2s_{t-1}+(1-\beta_2)\nabla_{x_j}f\left(x_j,t\right)^2,\quad\hat{s}_t=\frac{s_t}{1-\beta_2^t} \end{aligned}
x′mtst=x−ϵs^t+cm
t=β1mt−1+(1−β1)∇xjf(xj,t),m
t=1−β1tmt=β2st−1+(1−β2)∇xjf(xj,t)2,s^t=1−β2tst
其中,
β
1
\beta_{1}
β1 和
β
2
\beta_{2}
β2 为非负超参数,默认设置
β
1
=
0.9
,
β
2
=
0.999
\beta_{1}=0.9 ,\beta_{2}=0.999
β1=0.9,β2=0.999,
m
t
m_{t}
mt 和
s
t
s_{t}
st为参数梯度的一阶动量和二阶动量的指数移动平均值,即对参数梯度的一阶动量期望和二阶动量期望的估计。
但是由于初始值 m 0 m_{0} m0和 s 0 s_{0} s0设置为0 ,当 t t t较小时存在较大的初始偏差,从而估计值并不准确。例如,当 β 1 = 0.9 \beta_{1}=0.9 β1=0.9时 m 1 = 0.1 ∇ x j f ( x j , 1 ) m_{1}=0.1\nabla_{x_{j}} f\left(x_{j}, 1\right) m1=0.1∇xjf(xj,1) 。为消除这样的影响,研究人员提出使用 m t m_{t} mt 和 s t s_{t} st的偏差修正值 m ^ t \widehat{m}_{t} m t 和 s ^ t \hat{s}_{t} s^t对参数进行更新。
NADAM
NADAM (Nesterov ADAM) 在ADAM的基础上引入了NAG的思想,引入 “未来时刻”的梯度,首先将ADAM中的
m
^
t
\widehat{m}_t
m
t展开,参数更新公式:
x
′
=
x
−
ϵ
1
s
^
t
+
c
(
β
1
m
t
−
1
1
−
β
1
t
+
(
1
−
β
1
)
∇
x
j
f
(
x
j
,
t
)
1
−
β
1
t
)
x^{\prime}=x-\epsilon\frac1{\sqrt{\hat{s}_t}+c}\left(\frac{\beta_1m_{t-1}}{1-\beta_1^t}+\frac{(1-\beta_1)\nabla_{x_j}f(x_j,t)}{1-\beta_1^t}\right)
x′=x−ϵs^t+c1(1−β1tβ1mt−1+1−β1t(1−β1)∇xjf(xj,t))
NADAM则是将其中的一阶动量
m
t
−
1
m_t-1
mt−1替换为
m
t
m_t
mt(前瞻计算):








![[STM32-HAL库]0.96寸OLED显示屏-模拟IIC-STM32CUBEMX开发-HAL库开发系列-主控STM32F103C8T6](https://img-blog.csdnimg.cn/direct/8dd1e8ac30a94d15bce0cf020eb2a692.png)