K8s 是一种强大的容器编排和管理平台,能够高效地调度、管理和监控容器化应用程序;其本身使用声明式语义管理着集群内所有资源模型、应用程序、存储、网络等多种资源,Node 本身又属于 K8s 计算资源,上面承载运行着各种类型的应用程序,当Node NotReady 后运行在其上面各种 Workload 类型的 Pod 都会受到影响,脱离了 K8s 生命周期的管理后将会变的不可控无法提供服务,为保障该 Node 上 Pod 的可用性及可控性,K8s 会对这个 Node 上的 Pod 进行网络、存储、副本保持等控制;因 K8s 自身 controller manager 较多加上集群管理及运维的复杂度,增加了 Node NotReady 后的理解与学习成本;本文将基于 K8s 1.24 版本对 Node NotReady 后会触发哪些行为进行详细描述。
1. 控制器探索
1.1. Node Controller
默认情况下,Kubelet 每隔 10s (--node-status-update-frequency=10s) 更新 Node 的状态(我们称之为心跳),而 kube-controller-manager 每隔 5s 检查一次 Node 的状态 (--node-monitor-period=5s)。kube-controller-manager 会在 Node 未更新状态超过 40s (--node-monitor-grace-period=40s)时 ,将其标记为 NotReady (Node Ready Condition: True on healthy, False on unhealthy and not accepting pods, Unknown on no heartbeat)。当 Node 超过 5m 未更新状态,则 kube-controller-manager 会驱逐该 Node 上的所有 Pod。
Kubernetes 会自动给 Pod 添加针对 node.kubernetes.io/not-ready 和 node.kubernetes.io/unreachable 的容忍度,且配置 tolerationSeconds=300。这里需要注意的是当 Pod 对应容忍没有配置tolerationSeconds时,该容忍生效后 K8s 不会对 Pod 进行驱逐,可以通过 tolerations 配置 Pod 的容忍度,来覆盖默认的配置:
tolerations:
- key: "node.kubernetes.io/unreachable"
operator: "Exists"
effect: "NoExecute"
tolerationSeconds: 300
- key: "node.kubernetes.io/not-ready"
operator: "Exists"
effect: "NoExecute"
tolerationSeconds: 300Node 控制器在节点异常后,会按照默认的速率(--node-eviction-rate=0.1,即每10秒一个节点的速率)进行 Node 的驱逐。Node 控制器按照 Zone 将节点划分为不同的组,再跟进 Zone 的状态进行速率调整:
-
Normal:所有节点都 Ready,默认速率驱逐。
-
PartialDisruption:即超过33% 的节点 NotReady 的状态。当异常节点比例大于 --unhealthy-zone-threshold=0.55 时开始减慢速率:
-
小集群(即节点数量小于 --large-cluster-size-threshold=50):停止驱逐
-
大集群:减慢速率为 --secondary-node-eviction-rate=0.01
-
-
FullDisruption:所有节点都 NotReady,返回使用默认速率驱逐。但当所有 Zone 都处在 FullDisruption 时,停止驱逐。
K8s 此后的所有行为将会围绕着 Pod NotReady 和被驱逐的 Pod 进行展开;从下图中我们可以看到牵涉的组件及功能较多让人感觉着实复杂,但各个功能相互独立,管理逻辑有迹可循,以下根据各个组件功能进行详细探索,为减少本文篇幅,从总体逻辑上说明白 K8s 管理 Node 及 Pod 功能,本文只做功能描述,具体代码不再详细介绍。
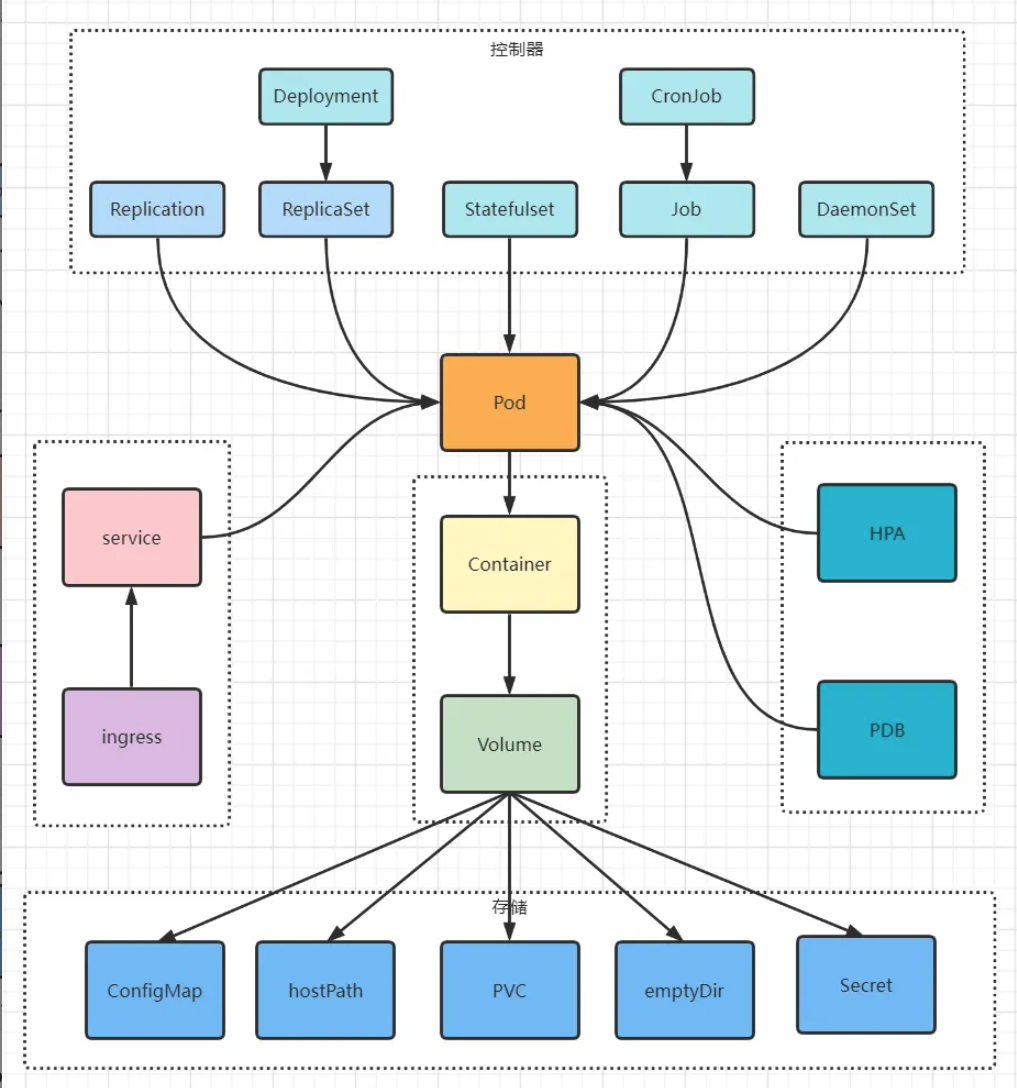
1.2. Deployment Controller
Deployment 通过管理 ReplicaSet 来完成 K8s 中微服务的版本更新、扩容缩容、滚动更新、回滚等高级功能,当 Pod NotReady 后会触发对应 ReplicaSet 的副本数保持功能;而 Deployment 只会更新自身 status 相关内容。
1.3. ReplicaSet Controller
Replicaset Controller的主要功能是确保期望的 Pod 副本数量与实际运行的 Pod 副本数量一致。因此,Replicaset Controller 会重建该 Node 上 相关的 Not Ready 的 Pod 副本以替换NotReady节点上的失效副本。Node NotReady 的 Pod 仍然会保留处于 Terminating 状态,Node 恢复后 kubelet 会执行优雅删除并强制删除该 Pod。
1.4. StatefulSet Controller
Node NotReady 同样会对 StatefulSet Pod 触发 eviction 操作,用户看到的 Pod 会一直处于 Terminating 状态。此时 StatefulSet Controller 并不会创建新的 Pod;Node 恢复后 kubelet 会执行优雅删除,detach PV,然后会重建该Pod。
1.4.1. 为什么没有重建
往往应用中有一些 Pod 没法实现多副本,但是又要保证集群能够自愈,那么这种某个节点 Down 掉或者网卡坏掉等情况,就会有很大影响,要如何能够实现自愈呢?
对于这种 Unknown 状态的 Stateful Pod ,可以通过 force delete 方式去删除。关于 ForceDelete,社区是不推荐的,因为可能会对唯一的标志符(单调递增的序列号)产生影响,如果发生,对 StatefulSet 是致命的,可能会导致数据丢失(可能是应用集群脑裂,也可能是对 PV 多写导致)。
kubectl delete pods <pod> --grace-period=0 --force但是这样删除仍然需要一些保护措施,以 Ceph RBD 存储插件为例,当执行force delete 前,根据经验,用户应该先设置 ceph osd blacklist,防止当迁移过程中网络恢复后,容器继续向 PV 写入数据将文件系统弄坏。因为 force delete 是将 PodObj 直接从 ETCD 强制清理,这样 StatefulSet Controller 将会新建新的 Pod 在其他节点, 但是故障节点的 Kubelet 清理这个旧容器需要时间,此时势必存在 2 个容器mount 了同一块 PV(故障节点Pod 对应的容器与新迁移Pod 创建的容器),但是如果此时网络恢复,那么2 个容器可能同时写入数据,后果将是严重的。
1.4.2. 社区推荐的做法
先恢复故障机器,自行完成优雅删除操作、detach PV、强制保障进程完全退出后,再由 kubuelet 将Pod进行彻底删除,最后触发 StatefulSet Controller 副本数保持功能,重建该Pod。
1.5. DaemonSet Controller
Node NotReady 对 DaemonSet 不会有影响,查询 Pod 处于 NodeLost 状态并一直保持。当 Node 恢复后该类型的Pod 会从 NodeLost 状态直接变成 Running 状态,不涉及重建。
1.6. Job Controller
Job Controller负责管理批处理任务。当NotReady节点上的Pod不可用时,Job Controller会在其他可用节点上创建新的Pod副本以完成任务。Job Controller会监控任务的进度,并确保任务在成功完成或达到重试次数限制后结束。
在 Node 重新变为 Ready 状态时,Job Controller会根据需要对Pod进行重新调度,以确保任务能够在可用资源的情况下继续执行。同时,Job Controller还会处理并发限制和任务完成后的清理工作。
2. 网络
Pod之间的网络通信在Kubernetes集群中至关重要。当 Node 变为NotReady状态时,位于该节点上的Pod可能无法与其他Pod进行通信。这可能是由于网络插件故障、网络策略限制或底层网络问题导致的。在 Node 重新变为Ready状态时,网络问题可能会得到解决,从而恢复Pod之间的通信。然而,这还取决于网络插件、配置和底层网络设施的具体情况。
2.1. Endpoints Controller
Endpoints Controller的主要职责是确保 Endpoints 对象始终与 Service 和 Pod 对象的当前状态保持一致。这是 K8s 服务发现和负载均衡功能的基础。其核心工作原理如下:
-
获取 Service 对象,当查询不到该 Service 对象时,删除同名 Endpoints 对象;
-
根据 Service 对象的.Spec.Selector,查询与 Service 对象匹配的 Pod 列表;
-
查询 Service 的 annotations 中是否配置了TolerateUnreadyEndpoints,代表允许为 unready 的 Pod 也创建 Endpoints,该配置将会影响 Endpoints 对象的 subsets 信息的计算;
-
遍历 Service 对象匹配的 Pod 列表,找出处于 Ready 状态的 Pod,并计算 Endpoints 的 subsets 信息;
-
获取 Service 同名 Endpoints 对象,没有则创建新的 Endpoints;将该Service匹配的Pod的 IP 地址和端口信息添加到 Endpoints 对象中。当一个 Service 的选择器发生变化,或与该 Service 关联的 Pod 的数量或状态发生变化时,Endpoints Controller会更新相应的Endpoints对象,以反映当前的 Pod IP 地址和端口信息。
上文已分析到 Node 变为 NotReady 后,Node Controller会更新该 Node 上的 Pod 为NotReady 状态,更新后 Endpoints Controller 会第一时刻感知到该变化,会把该 Pod 从对应的 Endpoints 的 IP list中摘除,以保证该 Pod 不会被其他 Pod 访问。
2.2. CoreDNS
CoreDNS就是DNS服务的一种,它会监视Kubernetes集群中的各种对象,包括Service、Endpoint、Pod等等。通过这些对象的更新,CoreDNS可以持续更新DNS记录,从而保证集群内的服务发现的正确性和实时性。
简单来说,当Service对象发生变化(例如,新创建了一个Service或者Service的端口、IP等发生了变化)时,CoreDNS就会根据这些变化更新相关的DNS记录。如果一个Pod被创建、删除或NotReady,CoreDNS也会及时地更新对应的DNS记录。
3. 存储
3.1. 本地存储
如果PV使用的是本地存储(例如,节点上的磁盘或目录),那么当节点变为NotReady状态时,位于该节点上的存储卷将无法访问。这可能导致使用这些存储卷的Pod无法正常运行。在这种情况下,Kubernetes不会对PV执行任何操作,因为本地存储卷与特定节点紧密相关。当节点重新变为Ready状态时,存储卷的访问可能会恢复正常。
3.2. 网络存储
对于网络存储(如NFS、iSCSI、Ceph等),当节点变为NotReady状态时,位于该节点上的Pod可能无法访问其存储卷。这可能是由于网络问题或者存储配置问题导致的。在这种情况下,Kubernetes不会对PV执行任何操作。当节点重新变为Ready状态并且网络问题得到解决时,Pod可能会重新获得对存储卷的访问。
3.3. 云存储
对于云存储(如AWS EBS、GCE PD、Azure Disk等),当节点变为NotReady状态时,Kubernetes可能会根据存储类(StorageClass)的配置自动将存储卷从不可用节点分离并附加到其他可用节点。这样,重新调度到其他节点的Pod可以继续访问其存储卷。请注意,这种行为取决于存储类的配置和云提供商的支持。
当Kubernetes集群中的节点变为NotReady状态时,对PV和PVC的影响主要取决于存储类型和配置。Kubernetes对PV的操作也因存储类型而异。在节点重新变为Ready状态时,存储访问可能会恢复正常,但这取决于具体情况。为了确保应用程序的高可用性,建议使用支持动态迁移和故障转移的存储解决方案。
3.4. 其他组件和功能
除了上述组件外,Kubernetes还有其他组件和功能可能会在节点变为NotReady状态时发生变化。例如:
Horizontal Pod Autoscaler(HPA):HPA负责根据资源利用率自动调整Pod副本数量。在节点变为NotReady状态时,HPA可能会在其他可用节点上创建新的Pod副本以满足负载需求。
Ingress Controller:Ingress Controller负责管理集群的入口流量。当节点变为NotReady状态时,Ingress Controller可能需要重新调度Ingress资源以确保流量能够正确路由到其他可用节点上的Pod。
Persistent Volumes(PV)和Persistent Volume Claims(PVC):当节点变为NotReady状态时,位于该节点上的存储卷可能会受到影响。这可能导致Pod无法访问其持久化存储。在节点重新变为Ready状态时,存储卷的访问可能会恢复正常。
总之,当Kubernetes集群中的节点变为NotReady状态时,各个组件会采取一系列行动来确保集群的稳定性和应用的正常运行。这包括重新调度Pod、确保服务可用性、维护网络通信和存储访问等。在节点重新变为Ready状态时,这些组件会根据需要进行相应的调整,以恢复正常运行。