目录
- 造数据
- 查看耗时
- 优化方案
- 总结
造数据
- 我用MySQL存储过程生成了100多万条数据,存储过程如下。
DELIMITER $$
USE `test`$$
DROP PROCEDURE IF EXISTS `proc_user`$$
CREATE PROCEDURE `proc_user`()
BEGIN
DECLARE i INT DEFAULT 1;
WHILE i <= 1000000 DO
INSERT INTO `test`.`t_user`(`name`) VALUES ( '张三'),
('李四'),
('王五'),
('赵六');
SET i=i+1;
END WHILE;
END$$
CALL `proc_user`();
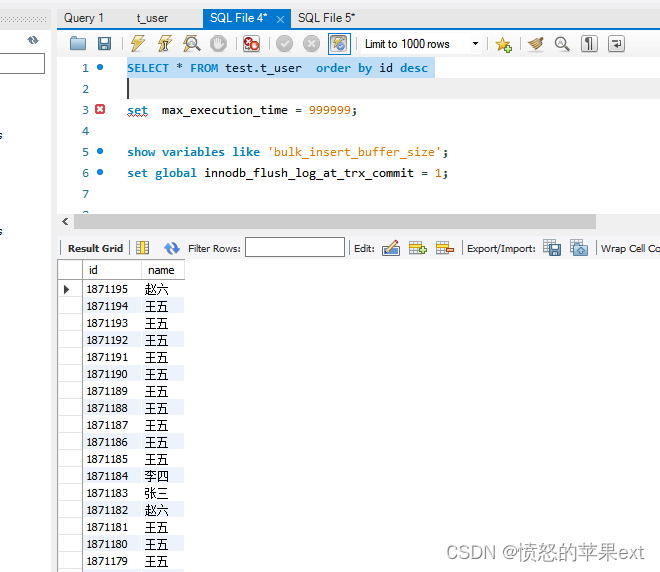
查看耗时
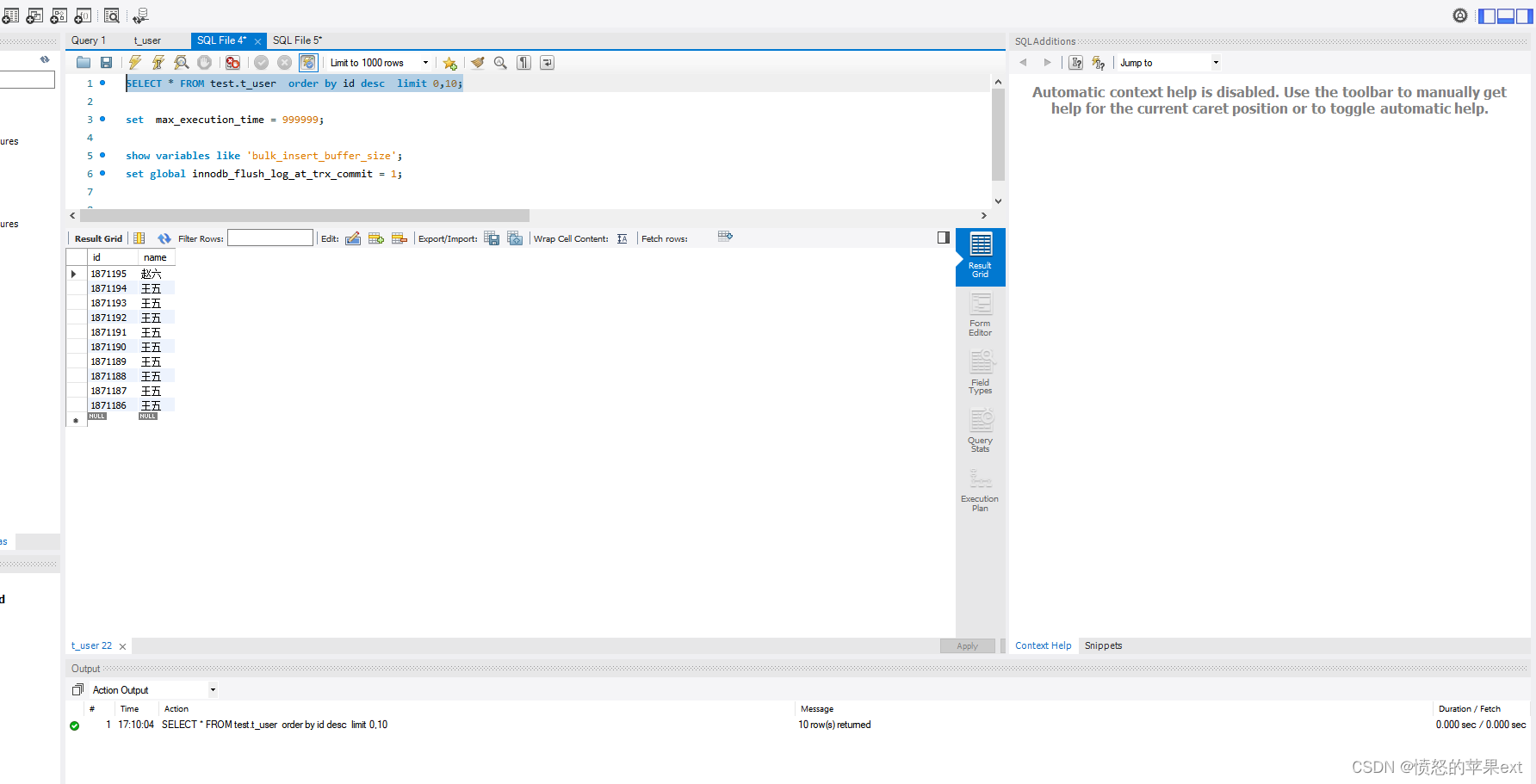
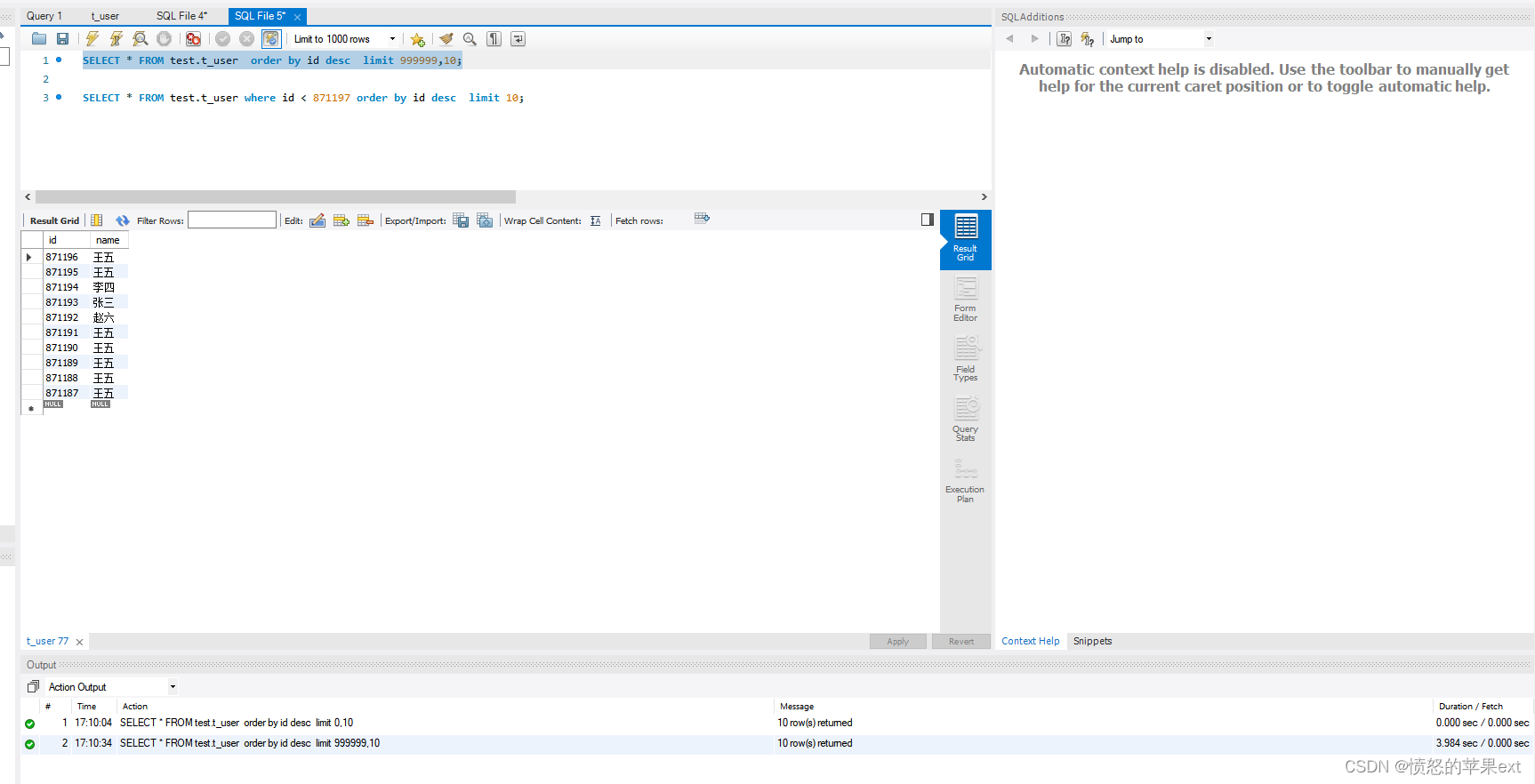
- 可以看出偏移量越大,后面耗时就越多。
优化方案
- 我们从下面两条SQL可以看出一些规律。
SELECT * FROM test.t_user order by id desc limit 0,10;
SELECT * FROM test.t_user order by id desc limit 10,10;
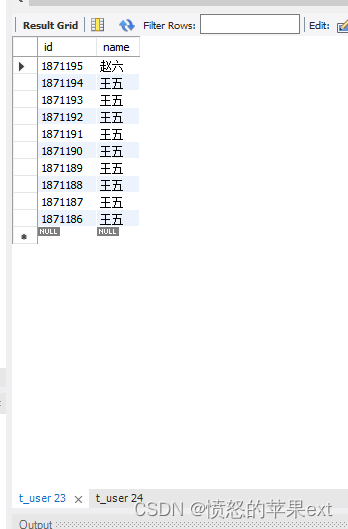
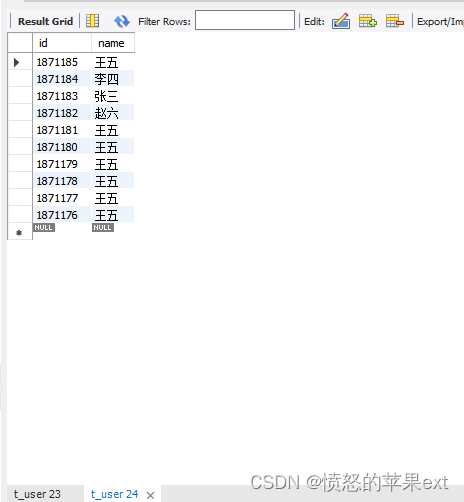
- 我是SQL是
order by id desc,第二页id,始终小于第一页的最后一条数据id。那么我们可以用一下主键索引,SQL改变一下。
SELECT * FROM test.t_user where id < 871197 order by id desc limit 10;
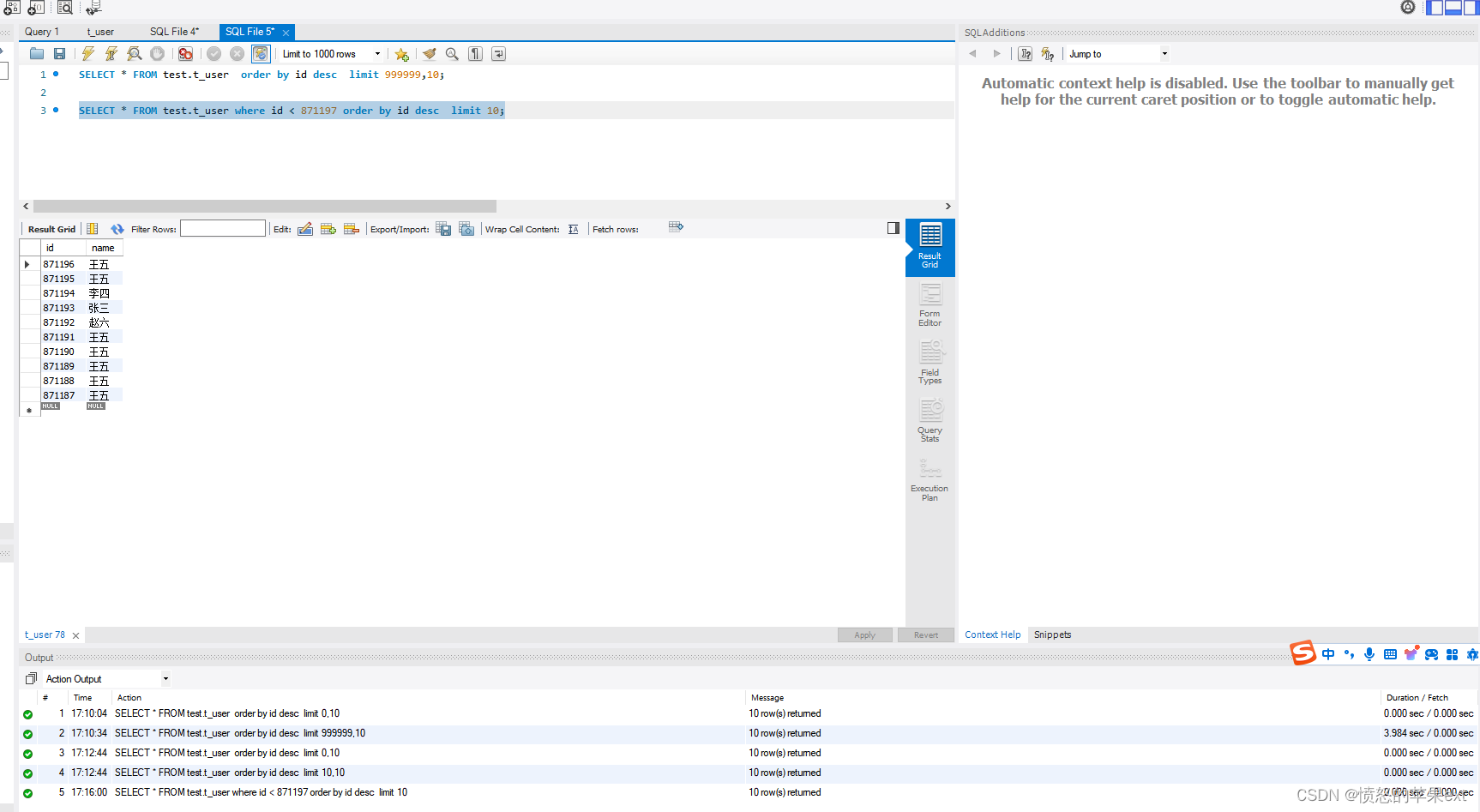
- 现在分页SQL是每次要传入上一页最后一条数据的id,利用索引很快就查出来了。
总结
- 大数据量分页查询MySQL的offset值越大,查询时间就越慢,我们可以寻找规律转变一下思路利用索引去优化查询。