前言
文章性质:学习笔记 📖
学习资料:吴茂贵《 Python 深度学习基于 PyTorch ( 第 2 版 ) 》【ISBN】978-7-111-71880-2
主要内容:根据学习资料撰写的学习笔记,该篇主要介绍了目标检测的相关概念及主要挑战。
第九章の开篇
在第六章中介绍了如何对图像进行分类,由于图像分类任务涉及的图像中只有一个主要物体对象,可以把识别对象作为分类任务。
1. 目标检测:图像中往往有多个我们感兴趣的目标 ,我们不仅想知道它们的 类别 ,还想知道它们在图像中的 具体位置 。
2. 语义分割:像素级别的图像分类任务 。
近年来,目标检测 和 语义分割 受到越来越多的关注。
作为场景理解的重要组成部分,它们广泛应用于现代生活中的安全领域、军事领域、交通领域、医疗领域和生活领域等许多领域。
懒人装备の获取
参考代码:基于 PyTorch 的 Python 深度学习 09 Code · GitHub
推荐网站:https://colab.research.google.com/
一、目标检测及主要挑战
目标检测的主要任务:确定目标位置、对确定位置后的目标进行分类。
如何确定目标位置?如何对目标进行分类?确定位置属于定位问题,对目标分类属于识别问题。
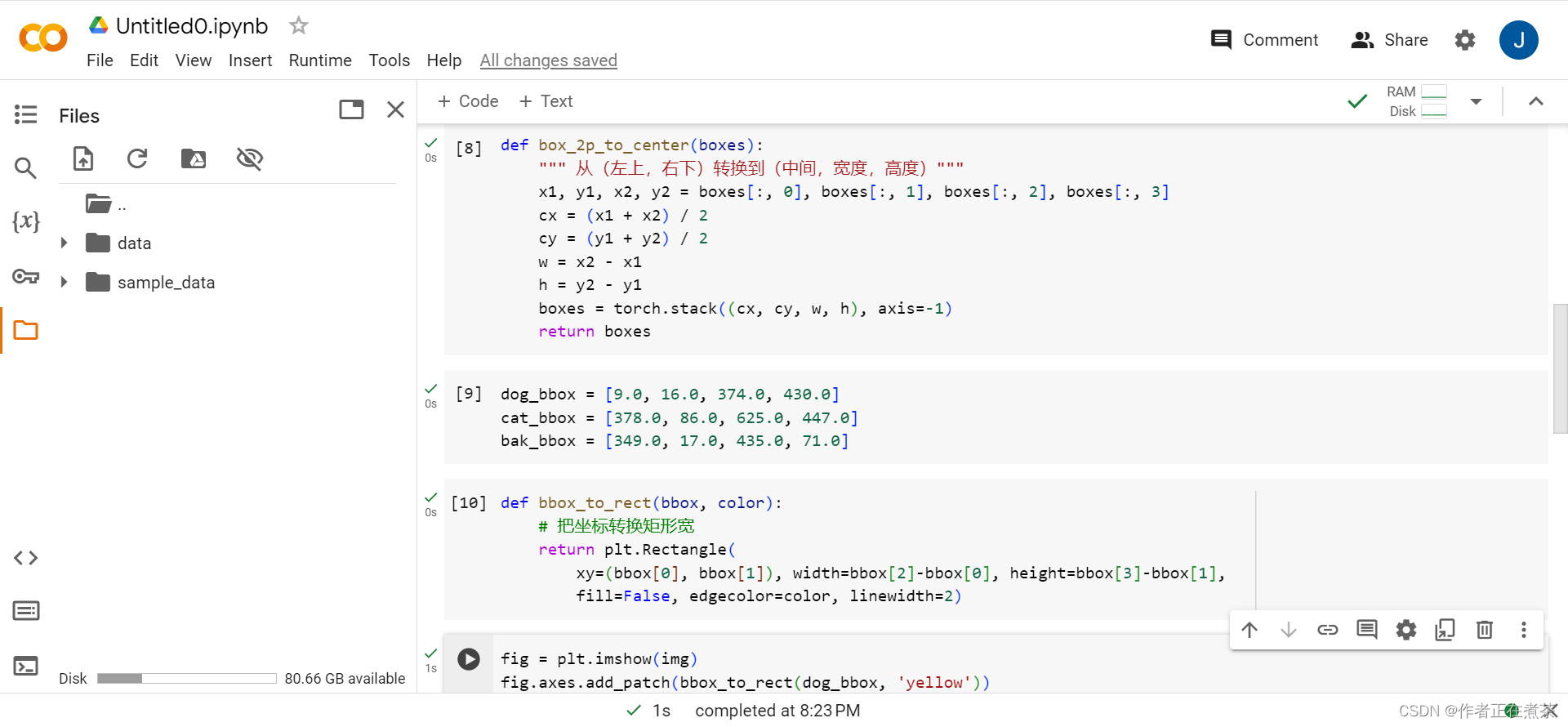
假设图像中只有 1 个目标对象或 2 个目标对象,对这个图像进行检测的目标就是,用矩形框界定目标对象,如图 9-1 所示。
把要检测的目标用矩阵图框定,然后对框定的目标进行分类。分类是对各矩形框进行识别,属于背景?具体对象?如图 9-2 所示。
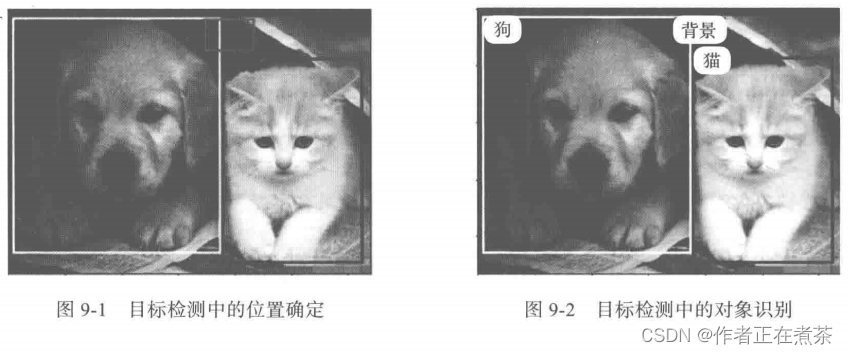
对于具体对象,通常使用矩形作为 边界框 Bounding Box 。边界框的具体表示方法将在下节介绍。
1、边界框的表示
在目标检测中,我们通常使用边界框来表示对象的空间位置。边界框有两种表示方法:
1. 用边界框 左上角的坐标 ( x1, y1 ) 以及 右下角的坐标 ( x2, y2 ) 来确定。 → 两点表示法
2. 用边界框 中心坐标 ( x, y ) 以及边界框的 宽度 和 高度 来确定。
其中,第一种方法比较好定位,在使用第一种方法后再使用一个转换函数 box_2p_to_center 就可以将其转换为第二种方法。
矩形框用长度为 4 的张量表示,详细实现过程如下:
① 导入需要的库:
%matplotlib inline
import numpy as np
import torch
from utils.config import Config
from utils.data import Dataset
from utils.data import vis
from matplotlib import pyplot as plt② 加载原图像:
img = plt.imread('../data/cat-dog.jpg')
plt.imshow(img);
③ 定义把两点表示法转换为中心及高宽表示法的转换函数:
def box_2p_to_center(boxes):
""" 从(左上,右下)转换到(中间,宽度,高度)"""
x1, y1, x2, y2 = boxes[:, 0], boxes[:, 1], boxes[:, 2], boxes[:, 3]
cx = (x1 + x2) / 2
cy = (y1 + y2) / 2
w = x2 - x1
h = y2 - y1
boxes = torch.stack((cx, cy, w, h), axis=-1)
return boxes④ 确定各边框的两点坐标:
dog_bbox = [9.0, 16.0, 374.0, 430.0]
cat_bbox = [378.0, 86.0, 625.0, 447.0]
bak_bbox = [349.0, 17.0, 435.0, 71.0]⑤ 把边框转换为矩形:
def bbox_to_rect(bbox, color):
# 把坐标转换矩形宽
return plt.Rectangle(
xy=(bbox[0], bbox[1]), width=bbox[2]-bbox[0], height=bbox[3]-bbox[1],
fill=False, edgecolor=color, linewidth=2)⑥ 可视化边界框:
fig = plt.imshow(img)
fig.axes.add_patch(bbox_to_rect(dog_bbox, 'yellow'))
fig.axes.add_patch(bbox_to_rect(bak_bbox, 'red'))
fig.axes.add_patch(bbox_to_rect(cat_bbox, 'blue'));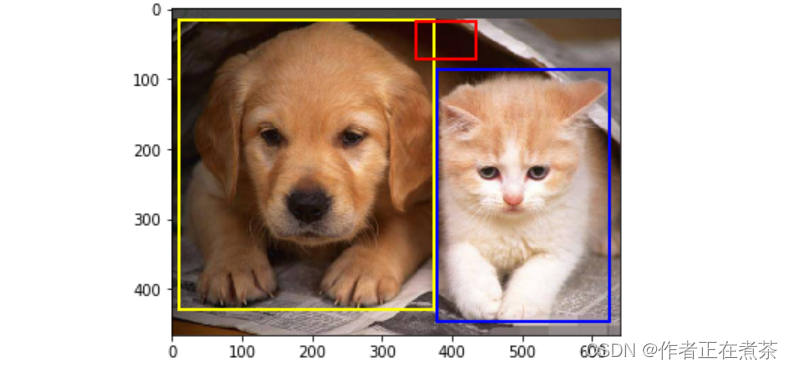
【补充】定义把中心及高宽表示法转换为两点表示法的转换函数:
def box_center_to_2p(boxes):
"""从(中间,宽度,高度)转换到(左上,右下)"""
cx, cy, w, h = boxes[:, 0], boxes[:, 1], boxes[:, 2], boxes[:, 3]
x1 = cx - w/2
y1 = cy - h/2
x2 = cx + w/2
y2 = cy + h/2
boxes = torch.stack((x1, y1, x2, y2), axis=-1)
return boxes2、手工标注图像的真实值
虽然在实际进行目标检测时,我们不能手工去画出各种边框,但我们依旧说明几种画边框的方法。
实际上,目标检测也是有监督学习的。所以在训练前,我们需要用到图像的 真实值 Ground Truth 。
如何手工制作图像的真实值?想手工标注图像的真实值,就需要确定图像中各具体类别的边界框的左上坐标和右下坐标,并把这些信息存放到 xml 文件中,然后在相关的配置文件中添加 xml 文件的序号,以便进行训练。具体文件及存放目录等信息如下:
① 原图像存放在 VOC2007 / JPEGImages 目录下,这里假设图像文件名称为 000001.jpg 。
② xml 存放路径。新生成的 xml 文件名称为 000001.xml ,存放在 VOC2007 / Annotations / 目录下,主要内容如下:
<annotation>
<folder>VOC2007</folder>
<filename>000001.jpg<filename>
<source>
<database>The VOC2007 Database</database>
<annotation>PASCAL VOC2007</annotation>
<image>flickr</image>
<flickrid>325443404</flickrid>
</source>
<owner>
<flickrid>autox4u</flickrid>
<name>Perry Aidelbaum</name>
</owner>
<size>
<width>640</width>
<height>466</height>
<depth>3</depth>
</size>
<segmented>0</segmented>
<object>
<name>dog</name>
<pose>Right</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>9</xmin>
<ymin>16</ymin>
<xmax>374</xmax>
<ymax>430</ymax>
</bndbox>
</object>
<object>
<name>cat</name>
<pose>Left</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>378</xmin>
<ymin>86</ymin>
<xmax>625</xmax>
<ymax>447</ymax>
</bndbox>
</object>
</annotation>③ 修改涉及训练的相关文件。为说明图像中具体类别,需要修改 ImageSets 目录下的两个文件。
说明文件将参与训练:
- 修改目录 VOC2007\ImageSets\Layout 下的 trainval 文件,添加一条记录( xml 文件名称):000001
- 修改目录 VOC2007\ImageSets\Main 下的 trainval 文件,添加一条记录( xml 文件名称):000001
说明图像中的具体类别:
- 修改目录 VOC2007\ImageSets\Main 下的 cat_trainval 和 dog_trainval 这两个文件,分别添加一条记录:000001 0
接下来我们将用具体代码展示图像的真实值。
① 读取配置文件,读取输入数据形状及所在路径的配置信息:
config = Config()
config._parse({})② 导入数据集:
# 导入 VOC2007 数据集
dataset = Dataset(config)
# 获取数据集中第 0 张图片和对应的标签
img, bboxes, labels, scale = dataset[0]【说明】根据 VOC2007 文件的实际路径,修改配置文件 utils/config.py 和 utils/data.py 。
③ 说明数据集的各类别放在一个元组中:
# 假设数据集中有 20 种类别
VOC_BBOX_LABEL_NAMES = (
'aeroplane', 'bicycle', 'bird', 'boat', 'bottle', 'bus', 'car', 'cat',
'chair', 'cow', 'diningtable', 'dog', 'horse', 'motorbike', 'person',
'pottedplant', 'sheep', 'sofa', 'train', 'tvmonitor')④ 显示图像的具体信息:
for x in (img, bboxes, labels):
print('shape:', x.shape, 'max:', torch.max(torch.as_tensor(x)).numpy(),
'min:', torch.min(torch.as_tensor(x)).numpy())
print(scale)运行结果如下:
shape: torch.Size([466, 640, 3]) max: 2.64 min: -2.0494049
shape: (2, 4) max: 624.0 min: 8.0
shape: (2,) max: 11 min: 7
1.0运行结果说明:
img 的形状为 (466, 640, 3) ,分别代表了图像的高和宽,通道数。
bboxes 的类数及坐标信息,形状为 (n, 4) ,这里的 n 表示该图像所包含的类别总数,最大为 20(不包括背景)。
labels 的形状为 (n, ) ,表示该图像所包含的类别总数、类别代码,从元组 VOC_BBOX_LABEL_NAMES 可以看到索引 11 表示狗。
⑤ 可视化真实标注框:
# 可视化图片及目标位置
vis(img, bboxes, labels)运行结果如下:

3、主要挑战
在前面的简单示例中,我们用边界框界定了图像中小猫、小狗的具体位置。然而,实际情况往往往往更加复杂,面临更大挑战:
- 图像中的对象有不同大小。
- 图像中的对象有很多种类,相同种类也可能有多个。
- 图像中存在遮掩、光照等问题。
图像中的目标有不同的大小,我们可以使用不同大小的框,然后采用移动的方法框定目标。这种产生候选框的方法在理论上是可行的,但这样产生的框将很大,而且这种方法不管图像中有几个对象,都需要如此操作,效率非常低。
To 解决这个问题,人们研究了很多方法,且目前还在不断更新迭代中。接下来我们简单介绍几种典型方法。
在 框定目标 与 识别目标 这两个任务中,框定目标是关键。如何框定目标呢?我们先从简单的情况开始,再考虑复杂的情况。
假设图像中只有单个目标,我们最先想到的方法是使用一个框,从左向右移动,直到框定目标,如图 9-6 所示。这是非常理想的情况,即使用的框正好能框住目标。候选框确定后,就可以针对每个框使用分类模型计算各框为猫的概率,如图 9-7 所示,中间框的内容对象为猫的概率最大。框确定后,意味着这个框的左上点的坐标 ( x, y ) 及这个框的高 ( h ) 与宽 ( w ) 也就确定了。

若遇到更复杂的情况,该如何界定图像中的对象?有哪些有效方法?接下来我们将介绍几种寻找图像中可能对象或候选框的方法。
4、选择性搜索
选择性搜索(Selective Search, SS)方法是如何对图像进行划分的呢?
SS 方法不是通过大小网格的方式,而是通过图像中的纹理、边缘和颜色等信息对图像进行自底向上的分割,然后对分割区域进行不同尺度的合并,生成的每个区域即一个候选框,如图 9-8 所示。这种方法基于传统特征,速度较慢。

SS 方法的基本思想:
1. 首先通过基于图的图像分割方法将图像分割成很多小块;
2. 使用贪婪策略,基于相似度(如颜色相似度、尺寸相似度、纹理相似度等)合并一些区域。
5、锚框
使用选择性搜索方法(SS)将产生大量重叠的候选框,提取特征时效率不高。这里介绍另一种方法:
该方法以每个像素为中心,生成多个缩放比和宽高比(Ratio)不同的边界框,这些边界框被称为 锚框(Anchor Box)。
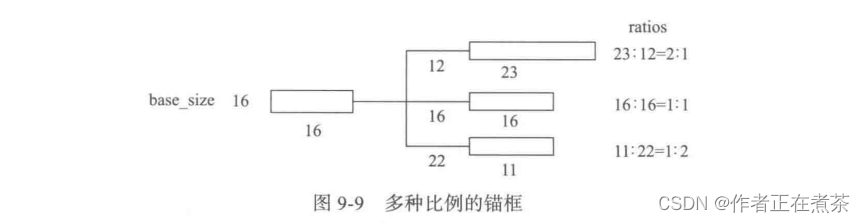
锚框的主要意义就在于它可以根据特征图在原图像上划分出很多大小、宽高比不相同的边界框。等边界框确定后,再利用不同算法对这些框进行粗略的分类(如是否存在目标对象)与回归,选取若干微调过的包含前景的正类别框和包含背景的负类别框,送入后面的网络结构参与训练。锚框的产生过程如图 9-9 所示,主要参数分析如下:
1. batch_size 参数代表的是网络特征提取过程中图像缩小的倍数,与网络结构有关。
- 假设缩小倍数为 16 ,说明最终特征图的一个像素可以映射到原图 16×16 区域的大小。
2. ratios 参数指的是要将 16×16 的区域,按照比例进行变换,如按照 1 : 2 ,1 : 1 ,2 : 1 这三种比例进行变换。
3. scales 参数是要将输入区域的宽和高进行缩放的倍数,如按照 8 、16 、32 这三种倍数放大。
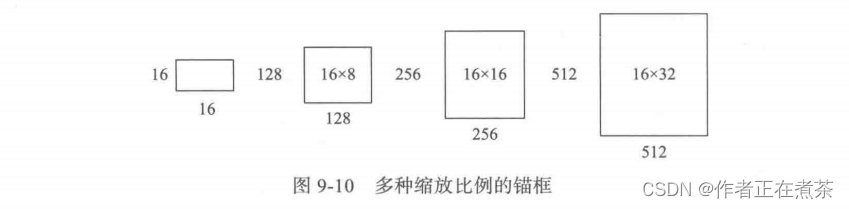
- 假设按照 08 倍放大,说明要将 16×16 的区域变成 (16×08) × (16×08) = 128×128 的区域,如图 9-10 所示。
- 假设按照 16 倍放大,说明要将 16×16 的区域变成 (16×16) × (16×16) = 256×256 的区域,如图 9-10 所示。
- 假设按照 32 倍放大,说明要将 16×16 的区域变成 (16×32) × (16×32) = 512×512 的区域,如图 9-10 所示。
通过 batch_size 、ratios 、scales 这三个参数,针对特征图上的任意一个像素点,首先映射到原图像中一个 16×16 的区域,然后以这个区域的中心点为变换中心,将其变为 3 种宽高比的区域,再分别将这 3 种区域的面积扩大 8 、16 、32 倍,最终该像素点将对应到原图像的 9 个不同的矩形框,这些框就叫做锚框,如图 9-11 所示。
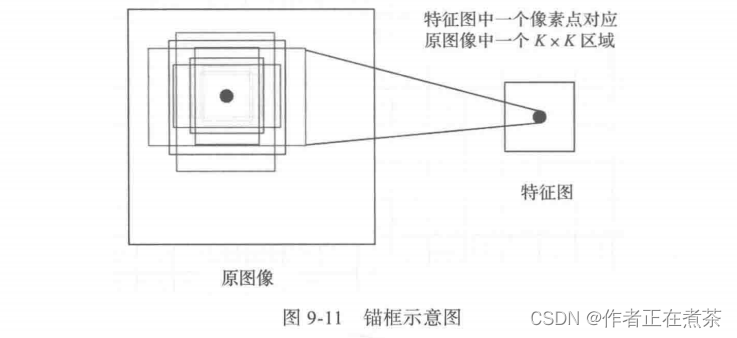
图 9-12 是 000001.jpg 图像对应特征图中第一个像素点的 9 个锚框。

【注意】将不完全在图像内部(初始化的锚框的 4 个坐标点均超出图像边界)的锚框都过滤掉,通常过滤后只会有原来 1 / 3 左右的锚框。如果不将这部分锚框过滤掉,则会使训练过程难以收敛。
锚框是目标检测中的重要概念,通常是人为设计的一组框,作为 分类和回归的基准框 。
无论是单阶段检测器还是两阶段检测器,都广泛地使用了锚框:
1. 两阶段检测器的第一阶段通常采用 RPN 生成候选框,是对锚框进行分类和回归的过程,即 锚框 → 候选框 → 检测器 ;
2. 大部分单阶段检测器是直接对锚框进行分类和回归,即 锚框 → 检测器 。
常见的锚框生成方式:滑窗 。首先定义 k 个特定尺度 scale 和长宽比 aspect ratio 的锚框,然后在全图中以一定的步长进行滑动。
滑窗 sliding window 这种生成锚框的方式广泛应用于 Faster R-CNN 、YOLO v2+ 、SSD 、RetinaNet 等经典检测方法中。
6、RPN
选择性搜索方法(SS)采用传统的特征提取方法,而且非常耗时。是否有更有效的方法呢?
Faster R-CNN 中提出了一种基于神经网络的生成候选框的方法,即 区域候选网络(Region Proposal Network, RPN)。
RPN 层用于生成候选框,并利用 softmax 判断候选框是检查对象(或前景)还是背景,从中选取对象候选框,再利用边框回归调整候选框的位置,从而得到特征子图(候选框)。RPN 架构如图 9-13 所示。
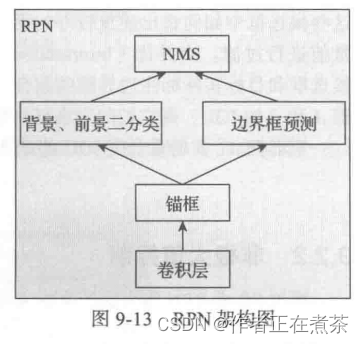
首先经过一个 3×3 的卷积操作,得到通道数为 256 的特征图,尺寸和公共特征图相同,假设是 256×(H×W) 。然后经过两条线:
1. 上面一条支线通过 softmax 来分类锚框获得前景和背景(检测目标是前景)。
2. 下面一条支线用于计算锚框的边框偏移量,以获得精确的候选框。
最后的候选框层则负责综合前景锚框 Foreground Anchor 和偏移量获取候选框,同时剔除太小和超出边界的候选框。
其实整个网络到了候选框层这里,就完成了目标定位的功能。

由于共享特征图的大小约为 40×60 ,所以 RPN 生成的初始锚框的总数约为 20,000 个 (40×60×9) 。其实 RPN 最终就是在原图尺度上设置密密麻麻的候选锚框,进而判断锚框到底是前景还是背景,即判断这个锚框到底有没有覆盖目标,并为属于前景的锚框进行第一次坐标修正。图 9-14 是图像经 RPN 处理得到的候选框,其中外部较大的框表示目标框或前景框,中间较小的框表示背景框。