1、语义分割的概念
1.1语义分割的定义
语义分割是一种计算机视觉领域的图像分割技术,其目标是将一张图像中的每个像素分配给预定义的类别。
在图像领域,语义指的是对图像意思的理解。语义分割就是按照“语义”给图像上目标类别中的每一点打上一个标签,使得不同种类的东西在图像上被区分开来,可以理解成像素级别的分类任务。语义分割大致可分为两类,标准语义分割和实例感知语义分割。标准语义分割也称为全像素语义分割,它是将每个像素分类为属于对象类的过程;实例感知语义分割是标准语义分割或全像素语义分割的子类型,它将每个像素分类为属于对象类以及该类的实体ID。
语义分割在计算机视觉中扮演着关键角色,它为场景完整理解奠定基础,其从粗粒度推理到精细推理的演进是实现细粒度推理的必要步骤。随着技术的进步,如卷积神经网络等深层结构被广泛采用,语义分割的精度得到了显著提升。
在自动驾驶、医学影像分析、机器人视觉、视频监控和增强现实等领域,语义分割都有着广泛的应用。例如,在自动驾驶中,语义分割用于道路线识别和轨迹规划,确保车辆正确行驶在各车道内;在医学影像处理中,语义分割能有效划分和分类影像中的不同组织区域,辅助医师判断可能出现的病变;在视频监控系统中,语义分割能够增强警戒能力,对监测对象进行准确地分类和识别,进而进行行为分析和预警。
1.2 语义分割与目标检测的区别
语义分割和目标检测在计算机视觉领域都是重要的任务,但它们之间存在明显的区别。
- 任务描述:
- 目标检测:其任务是在图像或视频中定位和识别多个对象,并为每个对象提供边界框(Bounding Box)。这涉及到识别出图像中的特定对象,并用矩形框或其他形状标注出它们的位置。
- 语义分割:其任务是将图像分成多个语义区域,每个区域具有相同的语义标签。这意味着图像中的每个像素都被分类为属于特定的类别,而不仅仅是确定对象的位置。
- 输出结果:
- 目标检测:输出是一组边界框,每个边界框都标识了图像中的一个对象,并且通常还包括对象的类别标签。
- 语义分割:输出是一张图像,其中每个像素都被赋予一个语义类别标签。这意味着对于图像中的每个像素,都有一个明确的类别标签,从而形成了对图像内容的详细理解。
- 关注点:
- 目标检测:主要关注于在图像中检测和定位多个对象,并识别这些对象的类别。它关注的是对象的整体位置和类别信息。
- 语义分割:不仅关注对象的位置,而且关注图像的每一个像素,对每个像素进行类别上的分类。它提供了对图像内容的更详细和深入的理解。
总的来说,目标检测和语义分割在计算机视觉中都扮演着重要的角色,但它们的任务描述、输出结果和关注点存在明显的区别。目标检测更关注于识别和定位图像中的对象,而语义分割则更关注于对图像内容的详细和深入理解。
1.3 kerasCV的语义分割简介
语义分割是一种计算机视觉任务,它涉及将图像的每个像素分配给一个类别标签,如人、自行车或背景,从而有效地将图像划分为对应于不同对象类别或类别的区域。
KerasCV 提供了由 Google 开发的 DeepLabv3+ 模型用于语义分割。本指南将演示如何使用 KerasCV 来微调和使用 DeepLabv3+ 模型进行图像语义分割。DeepLabv3+ 的架构结合了空洞卷积(atrous convolutions)、上下文信息聚合和强大的骨干网络,以实现准确且详细的语义分割。DeepLabv3+ 模型在各种图像分割基准测试中均取得了最先进的结果。
使用 DeepLabv3+ 进行语义分割通常包括以下步骤:
-
数据准备:收集并标注用于训练和验证的图像数据。这些数据应该包含各种类别的像素级标注。
-
模型加载:在 KerasCV 中加载预训练的 DeepLabv3+ 模型。你可以使用 KerasCV 提供的函数或API来加载这个模型。
-
模型微调(如果需要):如果预训练的模型是在不同的数据集上训练的,或者你的数据集与预训练模型的数据集有显著差异,你可能需要对模型进行微调。这涉及到使用你的数据集来训练模型的顶层(或全部层),以优化模型在你的特定任务上的性能。
-
推理和预测:使用微调后的模型对新的、未见过的图像进行推理,以生成语义分割结果。这些结果将是一张与输入图像大小相同的像素级标签图。
-
评估和优化:评估模型在验证集上的性能,并根据需要调整超参数或尝试不同的模型架构来优化性能。
-
部署:将训练好的模型部署到实际应用中,如自动驾驶系统、医学影像分析等。
通过使用 KerasCV 和 DeepLabv3+ 模型,程序员可以快速而准确地实现图像语义分割任务,并在各种应用中发挥其强大的功能。
1.4 调用准备工作
安装
!pip install -q --upgrade keras-cv
!pip install -q --upgrade keras # Upgrade to Keras 3.
调用库
安装 keras-core 和 keras-cv 之后,需要为 keras-core 设置后端。本指南可以与任何后端(如 TensorFlow、JAX、PyTorch)一起运行。
简而言之,这意味着 keras-core(和通常的 Keras)是一个高层次的 API,它允许用户选择底层张量计算库(如 TensorFlow、JAX 或 PyTorch)作为其后端来执行实际的计算。在安装完 keras-core 和 keras-cv 之后,用户需要指定他们想要使用的后端,以便这些库能够正确地执行计算任务。在大多数情况下,TensorFlow 是默认的也是最常用的后端。然而,Keras 的设计允许用户根据需要更改后端。
import os
os.environ["KERAS_BACKEND"] = "jax"
import keras
from keras import ops
import keras_cv
import numpy as np
from keras_cv.datasets.pascal_voc.segmentation import load as load_voc
2、kerasCV进行语义分割的步骤
要使用预训练的 DeepLabv3+ 模型进行语义分割,程序员可以使用 KerasCV 库中的 keras_cv.models API。以下是如何构建一个已经在 PASCAL VOC 数据集上预训练的 DeepLabv3+ 模型的步骤:
2.1 构建模型
model = keras_cv.models.DeepLabV3Plus.from_preset(
"deeplab_v3_plus_resnet50_pascalvoc",
num_classes=21,
input_shape=[512, 512, 3],
)
2.2可视化预训练模型的结果
在语义分割任务中,通常的做法是将模型的预测结果(通常是每个像素的类别分数图)转换为可视化的分割图,以便更直观地理解模型对输入图像的理解。这通常涉及到将每个像素的类别分数转换为对应的类别标签,并使用不同的颜色来区分不同的类别。
filepath = keras.utils.get_file(origin="https://i.imgur.com/gCNcJJI.jpg")
image = keras.utils.load_img(filepath)
resize = keras_cv.layers.Resizing(height=512, width=512)
image = resize(image)
image = keras.ops.expand_dims(np.array(image), axis=0)
preds = ops.expand_dims(ops.argmax(model(image), axis=-1), axis=-1)
keras_cv.visualization.plot_segmentation_mask_gallery(
image,
value_range=(0, 255),
num_classes=1,
y_true=None,
y_pred=preds,
scale=3,
rows=1,
cols=1,
)

2.3下载数据
我们使用KerasCV的数据集功能来下载PASCAL VOC数据集,并将其分割为训练数据集train_ds和评估数据集eval_ds。
这里,train_ds代表训练数据集,通常用于训练模型;eval_ds代表评估数据集,用于验证模型的性能。在深度学习项目中,将数据集分割为训练集和验证集(或测试集)是一种常见的做法,以确保模型在未见过的数据上也能表现良好。
train_ds = load_voc(split="sbd_train")
eval_ds = load_voc(split="sbd_eval")
2.4数据预处理
preprocess_tfds_inputs 这个实用函数用于预处理输入数据,将其转化为一个包含图像和分割掩码的字典。图像和分割掩码都被调整到 512x512 的大小。预处理后的数据集随后被分批处理成每批包含 4 对图像和分割掩码的数据组。
这些预处理后的训练数据批次可以使用 keras_cv.visualization.plot_segmentation_mask_gallery 函数进行可视化。这个函数接受一批图像和分割掩码作为输入,并将它们以网格的形式显示出来。
def preprocess_tfds_inputs(inputs):
def unpackage_tfds_inputs(tfds_inputs):
return {
"images": tfds_inputs["image"],
"segmentation_masks": tfds_inputs["class_segmentation"],
}
outputs = inputs.map(unpackage_tfds_inputs)
outputs = outputs.map(keras_cv.layers.Resizing(height=512, width=512))
outputs = outputs.batch(4, drop_remainder=True)
return outputs
train_ds = preprocess_tfds_inputs(train_ds)
batch = train_ds.take(1).get_single_element()
keras_cv.visualization.plot_segmentation_mask_gallery(
batch["images"],
value_range=(0, 255),
num_classes=21, # The number of classes for the oxford iiit pet dataset. The VOC dataset also includes 1 class for the background.
y_true=batch["segmentation_masks"],
scale=3,
rows=2,
cols=2,
)

预处理也应用于评估数据集 eval_ds。
eval_ds = preprocess_tfds_inputs(eval_ds)
2.5数据增强
KerasCV 提供了多种图像增强选项。在这个例子中,我们将使用 RandomFlip 增强来对训练数据集进行增强。RandomFlip 增强会随机地将训练数据集中的图像进行水平或垂直翻转。这有助于提高模型对图像中物体方向变化的鲁棒性。
train_ds = train_ds.map(keras_cv.layers.RandomFlip())
batch = train_ds.take(1).get_single_element()
keras_cv.visualization.plot_segmentation_mask_gallery(
batch["images"],
value_range=(0, 255),
num_classes=21,
y_true=batch["segmentation_masks"],
scale=3,
rows=2,
cols=2,
)

2.6模型配置
请随意修改模型训练的配置,并注意观察训练结果如何变化。这是一个很好的练习,有助于你更好地理解训练流程。
学习率调度(Schedule)由优化器用来计算每个epoch的学习率。优化器随后使用这个学习率来更新模型的权重。在本例中,学习率调度使用余弦衰减(Cosine Decay)函数。余弦衰减函数开始时较高,然后随时间逐渐降低,最终降至零。VOC 数据集的样本数是 2124,批次大小是 4。数据集的样本数对于学习率衰减很重要,因为它决定了模型将训练多少步。初始学习率与 0.007 成比例,衰减步数是 2124。这意味着学习率将从 INITIAL_LR 开始,然后在 2124 步内逐渐降至零。
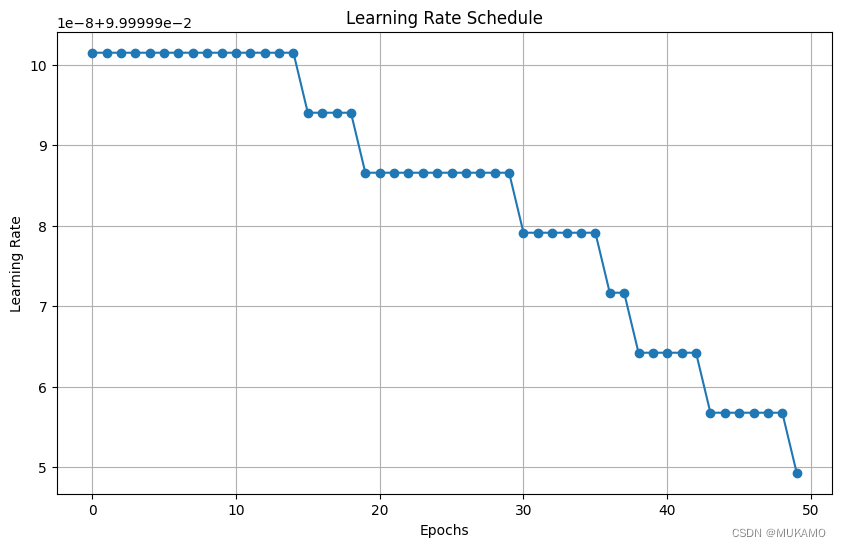
BATCH_SIZE = 4
INITIAL_LR = 0.007 * BATCH_SIZE / 16
EPOCHS = 1
NUM_CLASSES = 21
learning_rate = keras.optimizers.schedules.CosineDecay(
INITIAL_LR,
decay_steps=EPOCHS * 2124,
)
我们实例化了一个基于 ResNet50 主干网络的 DeepLabV3+ 模型,该主干网络在 ImageNet 分类任务上进行了预训练:resnet50_v2_imagenet 预训练权重将被用作 DeepLabV3Plus 模型的骨干特征提取器。num_classes 参数指定了模型将要训练的分割类别的数量。
model = keras_cv.models.DeepLabV3Plus.from_preset(
"resnet50_v2_imagenet", num_classes=NUM_CLASSES
)
Downloading data from https://storage.googleapis.com/keras-cv/models/resnet50v2/imagenet/classification-v2-notop.h5
94687928/94687928 ━━━━━━━━━━━━━━━━━━━━ 1s 0us/step
2.7编译模型
model.compile() 函数为模型设置了训练过程。它定义了以下组件:
- 优化算法 - 使用随机梯度下降(SGD)
- 损失函数 - 类别交叉熵(Categorical Cross-Entropy)
- 评估指标 - 平均交并比(Mean IoU)和类别准确率(Categorical Accuracy)
语义分割评估指标:
平均交并比(MeanIoU):MeanIoU 测量了语义分割模型在图像中识别和界定不同对象或区域的准确性。它计算预测和实际对象边界之间的重叠程度,提供一个 0 到 1 之间的分数,其中 1 表示完美匹配。
类别准确率(Categorical Accuracy):类别准确率测量了图像中正确分类的像素的比例。它给出一个简单的百分比,表示模型在整个图像中预测像素类别的准确性。
本质上,MeanIoU 强调了在识别特定对象边界时的准确性,而类别准确率则给出了像素级别整体正确性的宽泛概述。
model.compile(
optimizer=keras.optimizers.SGD(
learning_rate=learning_rate, weight_decay=0.0001, momentum=0.9, clipnorm=10.0
),
loss=keras.losses.CategoricalCrossentropy(from_logits=False),
metrics=[
keras.metrics.MeanIoU(
num_classes=NUM_CLASSES, sparse_y_true=False, sparse_y_pred=False
),
keras.metrics.CategoricalAccuracy(),
],
)
model.summary()
Model: "deep_lab_v3_plus_1"
┏━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━┓
┃ Layer (type) ┃ Output Shape ┃ Param # ┃ Connected to ┃
┡━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━┩
│ input_layer_9 │ (None, None, │ 0 │ - │
│ (InputLayer) │ None, 3) │ │ │
├─────────────────────┼───────────────────┼─────────┼──────────────────────┤
│ functional_11 │ [(None, None, │ 23,556… │ input_layer_9[0][0] │
│ (Functional) │ None, 256), │ │ │
│ │ (None, None, │ │ │
│ │ None, 2048)] │ │ │
├─────────────────────┼───────────────────┼─────────┼──────────────────────┤
│ spatial_pyramid_po… │ (None, None, │ 15,538… │ functional_11[0][1] │
│ (SpatialPyramidPoo… │ None, 256) │ │ │
├─────────────────────┼───────────────────┼─────────┼──────────────────────┤
│ encoder_output_ups… │ (None, None, │ 0 │ spatial_pyramid_poo… │
│ (UpSampling2D) │ None, 256) │ │ │
├─────────────────────┼───────────────────┼─────────┼──────────────────────┤
│ sequential_14 │ (None, None, │ 12,480 │ functional_11[0][0] │
│ (Sequential) │ None, 48) │ │ │
├─────────────────────┼───────────────────┼─────────┼──────────────────────┤
│ concatenate_1 │ (None, None, │ 0 │ encoder_output_upsa… │
│ (Concatenate) │ None, 304) │ │ sequential_14[0][0] │
├─────────────────────┼───────────────────┼─────────┼──────────────────────┤
│ sequential_15 │ (None, None, │ 84,224 │ concatenate_1[0][0] │
│ (Sequential) │ None, 21) │ │ │
└─────────────────────┴───────────────────┴─────────┴──────────────────────┘
Total params: 39,191,488 (149.50 MB)
Trainable params: 39,146,464 (149.33 MB)
Non-trainable params: 45,024 (175.88 KB)
实用函数 dict_to_tuple 有效地将训练和验证数据集的字典转换为图像和独热编码的分割掩码组成的元组。这种格式在 DeepLabv3+ 模型的训练和评估过程中被使用。
具体来说,这个函数的作用是将包含图像和分割掩码的数据集字典(通常是从 TensorFlow 数据集(tf.data.Dataset)或其他数据源中获取的)转换为更易于模型训练和评估的格式。在语义分割任务中,通常需要将分割掩码转换为独热编码(one-hot encoding)的形式,以便模型能够处理多类别的输出。
dict_to_tuple 函数会遍历数据集中的每个样本,提取图像和分割掩码,并将它们打包成一个元组。图像可能直接用于模型输入,而分割掩码则会被转换为独热编码形式,以便与模型的输出进行比较。这种元组格式方便了在训练循环中直接获取和使用图像和掩码数据。
在 DeepLabv3+ 模型的训练和评估过程中,使用这种元组格式可以简化数据处理流程,并确保模型能够正确地接收和解释输入数据。
def dict_to_tuple(x):
import tensorflow as tf
return x["images"], tf.one_hot(
tf.cast(tf.squeeze(x["segmentation_masks"], axis=-1), "int32"), 21
)
train_ds = train_ds.map(dict_to_tuple)
eval_ds = eval_ds.map(dict_to_tuple)
model.fit(train_ds, validation_data=eval_ds, epochs=EPOCHS)
2.8使用训练好的模型进行预测
现在 DeepLabv3+ 的模型训练已经完成,让我们通过在几个样本图像上进行预测来测试它。
test_ds = load_voc(split="sbd_eval")
test_ds = preprocess_tfds_inputs(test_ds)
images, masks = next(iter(train_ds.take(1)))
images = ops.convert_to_tensor(images)
masks = ops.convert_to_tensor(masks)
preds = ops.expand_dims(ops.argmax(model(images), axis=-1), axis=-1)
masks = ops.expand_dims(ops.argmax(masks, axis=-1), axis=-1)
keras_cv.visualization.plot_segmentation_mask_gallery(
images,
value_range=(0, 255),
num_classes=21,
y_true=masks,
y_pred=preds,
scale=3,
rows=1,
cols=4,
)

2.9 注意事项
以下是使用 KerasCV 的 DeepLabv3+ 模型的一些额外提示:
-
数据集选择:该模型可以在多种数据集上进行训练,包括 COCO 数据集、PASCAL VOC 数据集和 Cityscapes 数据集。
-
自定义数据集微调:模型可以在自定义数据集上进行微调,以改善在特定任务上的性能。这通常涉及使用与最终应用相似的图像和标签进行训练。
-
实时推理:模型可用于对图像进行实时推理。通过优化输入数据的预处理和后处理,以及使用适当的硬件(如 GPU),可以进一步提高推理速度。
-
尝试 KerasCV 的 SegFormer 模型:除了 DeepLabv3+ 外,KerasCV 还提供了 SegFormer 模型(
keras_cv.models.segmentation.SegFormer)。SegFormer 是一种较新的模型,在各种图像分割基准测试中均取得了最先进的结果。它基于 Swin Transformer 架构,比以前的图像分割模型更高效、更准确。 -
Swin Transformer:SegFormer 的基础架构是 Swin Transformer,这是一种高效的视觉 Transformer,它结合了局部自注意力和移位窗口机制,以在保持计算复杂度的同时捕获跨窗口的依赖关系。
-
模型效率:SegFormer 通过轻量级的解码器设计减少了计算成本,使得模型在保持高准确率的同时,能够实现较快的推理速度。
-
性能提升:在许多标准数据集上,SegFormer 已被证明在性能上优于 DeepLabv3+ 和其他传统的图像分割模型。
在使用这些模型时,请确保您了解数据集、预处理步骤、训练参数和超参数如何影响模型的性能,并根据您的特定任务进行相应的调整。
3、总结
在kerasCV中,语义分割是一个重要的图像理解任务,其目标是为图像中的每个像素分配语义标签,如道路、建筑、天空等。这种技术能够精确地标注出每个像素所属的类别,因此与图像分类相比,其输出结果更为详细。
实现语义分割的常用算法通常基于卷积神经网络(CNN),其中FCN(Fully Convolutional Networks)是一个典型的例子。FCN将传统的CNN分类器替换为卷积层,并通过反卷积层将高维特征向量转换为像素级的类别预测。
在kerasCV中,语义分割模型的构建和训练过程可以通过使用提供的工具进行简化。Keras是一个流行的深度学习框架,它支持多种后端,如TensorFlow、MXNet、CNTK和Theano,这使得Keras成为实现语义分割模型的一个很好的选择。在训练过程中,交叉熵损失函数通常被用来衡量模型输出与真实标签之间的差异,这有助于提高模型的准确性和鲁棒性。
在kerasCV的语义分割应用中,可以使用各种数据集进行训练,包括COCO、PASCAL VOC和Cityscapes等。此外,用户还可以使用自定义数据集对模型进行微调,以改善在特定任务上的性能。
除了基本的语义分割任务外,kerasCV还提供了其他与图像相关的功能,如图像生成和图像增强。例如,利用生成对抗网络(GAN)等技术可以生成逼真的图像,而通过对图像进行各种变换和增强操作,可以提高模型的泛化能力和鲁棒性。
总的来说,kerasCV为语义分割任务提供了强大的工具和支持,使用户能够轻松构建和训练高效的语义分割模型。




![[力扣]——231.2的幂](https://img-blog.csdnimg.cn/direct/13db527755ec49f7979314ecbc41e86d.png)