文章目录
- 十五、map和set
- 1. 关联式容器
- 2. set的介绍
- 3. set的使用
- 4. multiset
- 5. map的介绍
- 6. map的使用
- 7. multimap
- 8. map中重载的operator[]
- 未完待续
十五、map和set
1. 关联式容器
我们已经接触过STL中的部分容器,比如:vector 、list 、deque 等,这些容器统称为 序列式容器 。序列式容器底层的数据结构里面存储的是元素本身。
关联式容器也是用来存储数据的,与序列式容器不同的是,其 里面存储的是<key, value>结构的键值对 ,即底层的数据结构包含两个值,key代表键值 ,value代表与key对应的信息 。
在数据检索时关联式容器比序列式容器效率更高。
而set和map就是STL中的 树形结构的关联式容器 。底层是平衡二叉树(红黑树)。
2. set的介绍
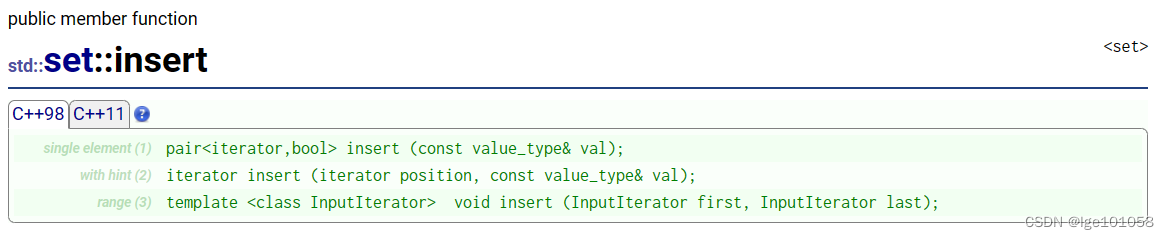
set文档
3. set的使用
使用set记得包含 set 头文件哦。

#include<iostream>
#include<set>
using namespace std;
void test01()
{
set<int> s;
s.insert(5);
s.insert(2);
s.insert(4);
s.insert(1);
s.insert(3);
s.insert(2);
s.insert(1);
set<int>::iterator it = s.begin();
while (it != s.end())
{
cout << *it << " ";
++it;
}
cout << endl;
for (auto e : s)
{
cout << e << " ";
}
cout << endl;
}
int main()
{
test01();
return 0;
}
对于 insert 的使用我们已经轻车熟路了。
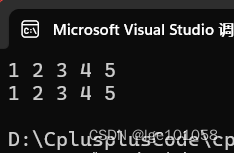
我们发现结果跟插入的数据好像不匹配,这是因为set底层是平衡二叉树,自带排序属性,而且遇到重复的值不会再次插入,所以 set具有 排序 + 去重 的功能。
#include<iostream>
#include<set>
using namespace std;
void test03()
{
set<int> s;
s.insert(5);
s.insert(2);
s.insert(4);
s.insert(1);
s.insert(3);
s.insert(2);
s.insert(1);
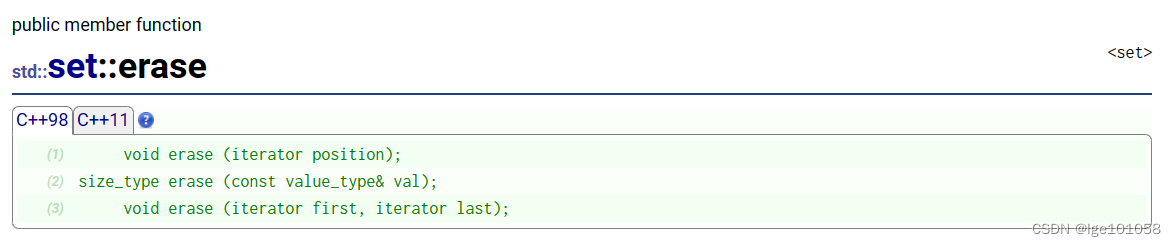
set<int>::iterator it = s.find(5);
// 使用迭代器进行删除时必须保证迭代器有效
s.erase(it);
// 使用指定value进行删除,如果该值存在则删除,不存在不做任何处理
s.erase(666);
for (auto e : s)
{
cout << e << " ";
}
cout << endl;
}
int main()
{
test03();
return 0;
}
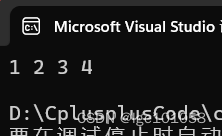
当使用迭代器进行删除时确保迭代器有效,否则会报错。
#include<iostream>
#include<set>
using namespace std;
void test02()
{
set<int> s;
s.insert(5);
s.insert(2);
s.insert(4);
s.insert(1);
s.insert(3);
s.insert(2);
s.insert(1);
set<int>::iterator it = s.find(5);
if (it != s.end())
{
cout << "找到了" << endl;
}
}
int main()
{
test02();
return 0;
}
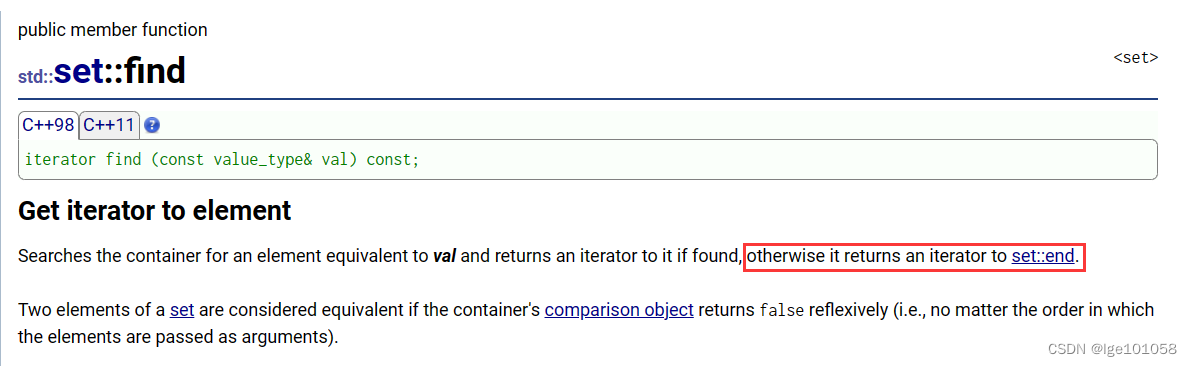
find查找到元素会返回一个指向元素的迭代器,没找到则返回指向end()的迭代器。

count()会返回这个值有几个。
#include<iostream>
#include<set>
using namespace std;
void test04()
{
set<int> s;
s.insert(5);
s.insert(2);
s.insert(4);
s.insert(1);
s.insert(3);
s.insert(2);
s.insert(1);
cout << s.count(1) << endl;
cout << s.count(77) << endl;
}
int main()
{
test04();
return 0;
}


#include<iostream>
#include<set>
using namespace std;
void test05()
{
set<int> s;
s.insert(5);
s.insert(2);
s.insert(4);
s.insert(1);
s.insert(6);
s.insert(2);
s.insert(1);
// lower_bound返回 容器里第一个 >= value的值
auto start = s.lower_bound(3);
// opper_bound返回 容器里第一个 > value的值
auto finish = s.upper_bound(5);
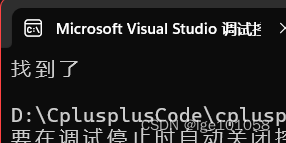
cout << *start << endl;
cout << *finish << endl;
// 迭代器区间删除
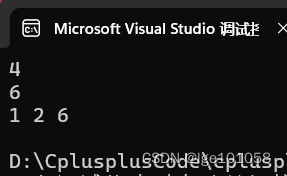
s.erase(start, finish);
for (auto e : s)
{
cout << e << " ";
}
cout << endl;
}
int main()
{
test05();
return 0;
}
lower_bound返回 容器里第一个 >= value的值
opper_bound返回 容器里第一个 > value的值
4. multiset
multiset的用法与set基本一样,只是 multiset允许出现重复值 。
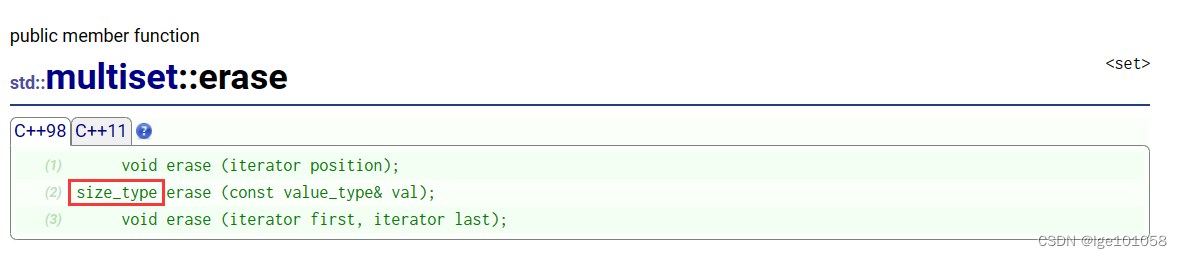
此时这里的返回值就有了意义,返回删除的元素个数。

当有重复值时,find返回的迭代器指向中序遍历的第一个要查找的值。
5. map的介绍
map文档

map底层其实是 pair 。而 pair 其实是一个类模板。

成员变量有两个,一个first,一个second,在map里,first一般存的是key,second存的是value。

6. map的使用
使用map时记得包含 map 头文件哦。
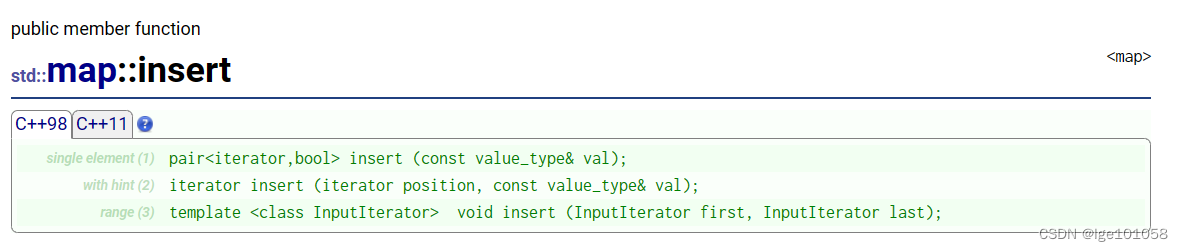
#include<iostream>
#include<map>
using namespace std;
void test01()
{
map<string, string> dict;
dict.insert(pair<string, string>("sort", "排序"));
dict.insert(pair<string, string>("string", "字符串"));
dict.insert({ "apple", "苹果" });
dict.insert(make_pair("sort", "排序"));
map<string, string>::iterator it = dict.begin();
while (it != dict.end())
{
// 两种获取key和value的方法
cout << (*it).first << " " << it->second << endl;
++it;
}
}
int main()
{
test01();
return 0;
}
make_pair是一个模板函数,跟pair那种写法没区别。

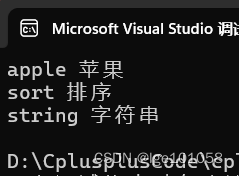
map同样具有 排序 + 去重 的功能,排序的依据是map的 key 。
#include<iostream>
#include<map>
using namespace std;
void test02()
{
map<string, string> dict;
dict.insert(make_pair("sort", "排序"));
dict.insert(make_pair("string", "字符串"));
dict.insert(make_pair("sort", "xxxx"));
for (auto& e : dict)
{
cout << e.first << " " << e.second << endl;
}
}
int main()
{
test02();
return 0;
}
此时第三个插入并不会插入,也不会更新。
map的其他成员函数基本没啥大的变化,我们不再赘述。
7. multimap
multimap跟map的区别与multiset与set的区别类似。

#include<iostream>
#include<map>
using namespace std;
void test03()
{
multimap<string, string> dict;
dict.insert(make_pair("sort", "排序"));
dict.insert(make_pair("string", "字符串"));
dict.insert(make_pair("sort", "xxxx"));
dict.insert(make_pair("sort", "排序"));
for (auto& e : dict)
{
cout << e.first << " " << e.second << endl;
}
}
int main()
{
test03();
return 0;
}
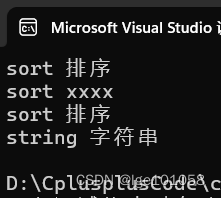
此时就可以插入重复值了。(排序时只看key)
8. map中重载的operator[]
map的普通统计次数:
#include<iostream>
#include<map>
using namespace std;
void test04()
{
string arr[] = { "苹果","西瓜","苹果","西瓜","苹果","苹果","西瓜","苹果","香蕉","苹果","西瓜","香蕉","草莓" };
map<string, int> countMap;
for (auto& e : arr)
{
// 查找
map<string, int>::iterator it = countMap.find(e);
// 有则数量+1
if (it != countMap.end())
{
it->second++;
}
// 没有则插入
else
{
countMap.insert(make_pair(e, 1));
}
}
for (auto& e : countMap)
{
cout << e.first << " " << e.second << endl;
}
}
int main()
{
test04();
return 0;
}
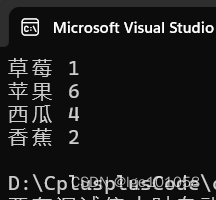

当key存在时,operator[]可以返回这个key所映射的value的引用。
operator[]的访问原型:
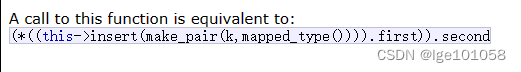
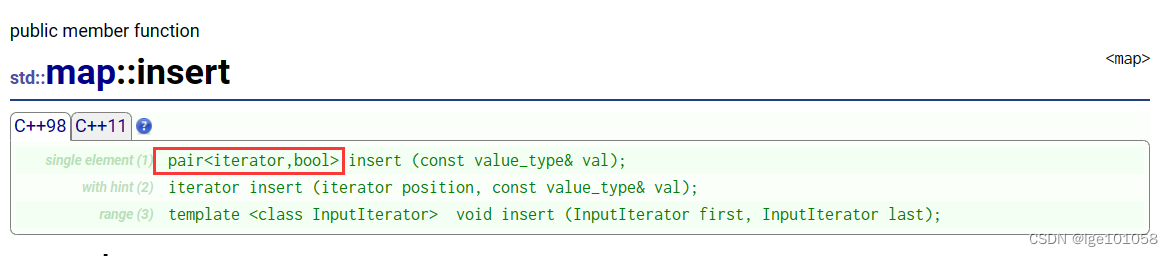
map的insert函数返回一个pair,第二个数据代表是否插入成功,如果成功(第一次出现)则返回 true 。第一个数据代表指向这个key的迭代器(已经存在的或新插入的)。
所以上面的统计次数代码可以改成:
#include<iostream>
#include<map>
using namespace std;
void test05()
{
string arr[] = { "苹果","西瓜","苹果","西瓜","苹果","苹果","西瓜","苹果","香蕉","苹果","西瓜","香蕉","草莓" };
map<string, int> countMap;
for (auto& e : arr)
{
pair<map<string, int>::iterator, bool> ret;
ret = countMap.insert(make_pair(e, 1));
// 已经存在
if (ret.second == false)
{
// 迭代器指向的value + 1
ret.first->second++;
}
}
for (auto& e : countMap)
{
cout << e.first << " " << e.second << endl;
}
}
int main()
{
test05();
return 0;
}
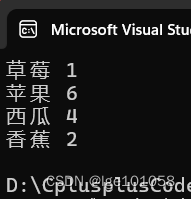
所以operator[]的访问就跟insert差不多,插入的value是类型的默认构造值。所以上面的统计代码也可以写成:
#include<iostream>
#include<map>
using namespace std;
void test06()
{
string arr[] = { "苹果","西瓜","苹果","西瓜","苹果","苹果","西瓜","苹果","香蕉","苹果","西瓜","香蕉","草莓" };
map<string, int> countMap;
for (auto& e : arr)
{
countMap[e]++;
}
for (auto& e : countMap)
{
cout << e.first << " " << e.second << endl;
}
}
int main()
{
test06();
return 0;
}
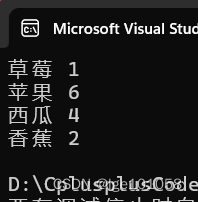
于是,插入也可以写成这样:
void test07()
{
map<string, string> dict;
// 插入
dict["sort"];
// 查找
cout << dict["sort"] << endl;
// 修改
dict["sort"] = "xxx";
// 插入 + 修改
dict["apple"] = "苹果";
}