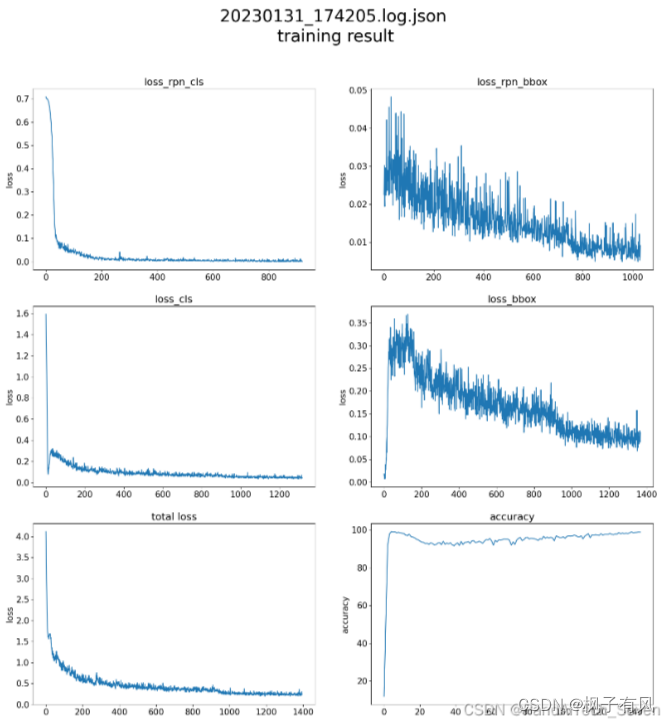
参考:https://blog.51cto.com/u_15127663/2778705
1. 背景
Fraudar 要解决的问题是:找出社交网络中最善于伪装的虚假用户簇。虚假用户会通过增加和正常用户的联系来进行伪装,而这些伪装(边)会形成一个很密集的子网络,可以通过定义一个全局度量,再移除二部图结构中的边,使得剩余网络结构对应的度量值最大,找到最紧密的子网络,即最可疑的作弊团伙。
1. 建立优先树(一种用于快速移除图结构的边的树结构);
2. 对于二部图中的任意节点,贪心的移除优先级最高的节点,直至整个网络结构为空;
3. 比较上述每一步得到的子网络对应的全局度量,取该值为最大的子网络(最密集的子网络),即最可疑的团伙。
2. 可疑程度度量
最关键的地方是定义一个描述可疑程度的度量,要求其有如下性质:
1. 可扩展性;
2. 具备理论上的“界”;
3. 对抗虚假行为的鲁棒性。
特别地,该度量可以理解成子网络中每个节点的平均可疑程度。令 代表用户节点的子集,
代表目标节点的子集,那么
,而
,
那么可疑程度的度量被定义为:。
其中: 表示S 中节点本身的可疑程度之和,
表示 S 中节点之间边的可疑程度之和,整个公式表示点和边的总可疑程度。可以得出4条性质:
1. 如果其他条件不变,包含更高可疑度节点的子网络比包含较低可疑度节点的子网络更可疑;
2. 如果其他条件不变,在子网络中增加可疑的边会使得子网络更可疑;
3. 如果节点和边的可疑程度不变,那么大的子网络比小的子网络更可疑;
4. 如果节点和边的总可疑程度相同,那么包含节点数少的子网络更可疑。
该算法的核心是:贪心地移除图中的点,使得每次变更f 的变化最大。在移除一个节点时,只有与之相邻的节点会发生变化,那么这样最多产生O(|E|)次变更,如果找到合适的数据结构使得访问节点的时间复杂度为O(log|V|),那么算法总的时间复杂度就是O(NlogN)。基于这样的考虑建立优先树(二叉树),图中的每个节点都是树的一个叶子节点,其父节点为子节点中优先级较高的节点。这棵树建完之后就可以按照O(log|V|)的速度获得优先级最高的节点。
3. 如何识别虚假行为?
可通过列权重下降的方法来实现。不能简单的将每条边的嫌疑程度设为相等,因为出度和入度大的节点,可能真的就是很受欢迎的节点。
如大V用户和销量不错的商品,这些节点都是天然存在的,并不是虚假的。如果每条边的嫌疑程度相等的话,那么在最大化可疑程度的度量时,就会聚焦于这些出度和入度较大的点,而不是聚焦于紧密的子网络。所以如果存在节点i 到一个出度和入度较大的节点j 的边,就需要将其边对应的嫌疑程度降低,这就是列权重下降法。
该方法不仅关注出度和入度较大的节点,而且更关注紧密的子网络。eg: 在邻接矩阵中,令行代表用户节点,列代表目标节点,那么虚假用户向正常的目标节点增加边并不会使得子网络的嫌疑程度变低。因为虚假用户向正常的目标增加边只会使正常目标对应的嫌疑程度下降,而嫌疑子网络内的权重却不会发生变化。实验表明,列权重下降函数选择类似TF-IDF形式的函数时,算法表现会比较好。
4. 算法优缺点
1. 优点
1. 采用了“贪心”的计算思想,运行速度很快;
2. 原理清晰明了,且能够给出理论上的“界”;
3. 能够识别虚假行为。
2. 缺点:
1. 因采用贪心算法,所以不能保证得到全局最优解;
2. 原始算法只能找出一个最紧密的子网络,即可以程度最大的子网络;
3. 只考虑了边的权重,没有考虑节点的权重(或节点的权重都设为相等的常数),且节点和边的嫌疑程度需要自定义。
5. 应用
5.1 一个改进:循环Fraudar 算法
在网络结构中找出最可疑的子网络后,移除子网络中所有相关的边,再使用Fraudar 算法对剩余的图结构进行挖掘,找出次可疑的子网络。最终得到可疑程度由高到低排列的多个子网络。
5.2 识别虚假社交关系
在社交平台和电商网络中,用户与用户或用户与商品之间会形成巨大的有向网络。而由于虚假行为的存在,这个有向网络中被注入了异常的行为模式。如:
Twitter、Facebook、微博等社交平台中会有虚假的关注、转发等;
而Amazon、淘宝等电商平台中会有误导性评论、虚假交易等。
在这些静态的有向网络中,可疑的异常行为会形成一个紧密的子网络(可通过Fraudar 算法贪心找到)。
6. CatchSync 算法
利用了两个容易被欺诈者忽视的特点,一个是同步行为特性,另一个是稀有行为特性。大多数情况下,异常的行为模式往往是稀少而集中的,可以设计算法来捕捉它们,CatchSync正是基于同步行为特性和稀有行为特性来找到有向网络中的异常行为模式的。
6.1 原理
是基于图的性质提出的异常识别算法,在有向图结构中,可以利用很多性质,如:
1. 基本的出度和入度;
2. HITS(Hyperlink-InducedTopic Search) 得分;
3. 中介中心性(betweenness centrality);
4. 节点的入权重和出权重;
5. 节点对应的左右奇异值向量的第i 个元素值。
CatchSync 算法利用了HITS得分中的权威度和入度,将其作为基本的特征。并基于此提出了两个新概念来研究源节点的特性:
1. synchronicity(同步性|一致性): 用于描述源节点u 的目标节点在特征空间中的同步性;
2. normality(正常性):用于描述源节点u 的目标节点的正常性。
在CatchSync 算法中用c(V,V*)来表示特征空间InF-plot中源节点的目标节点间的临近性(相似性)。为了快速计算,该算法将特征空间划分成G个网格,并将原有向图中的节点映射到每个网络中。有了这个网络之后,c(V,V*)的计算就非常容易了,如果两个节点在同一个网络中,那么临近性为1,否则为0。
通过synchronicity和normality就可以刻画出特征空间SN-plot,进而基于正态分布找出异常节点(高同步性和低正常性的节点)。为了评估直播业务中是否存在主播删粉丝关注量的情况,对现有直播业务中的关注关系应用CatchSync 算法进行挖掘,得到全站直播业务中关注关系的SN-plot 和 InF-plot,如图:
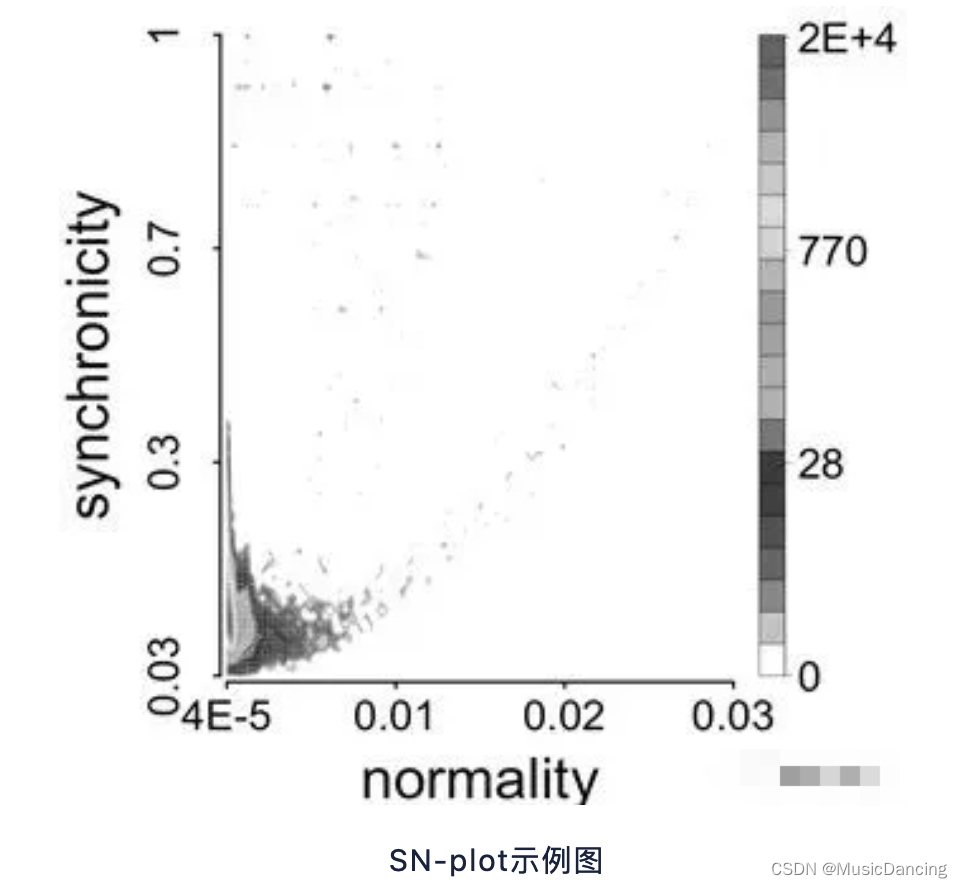
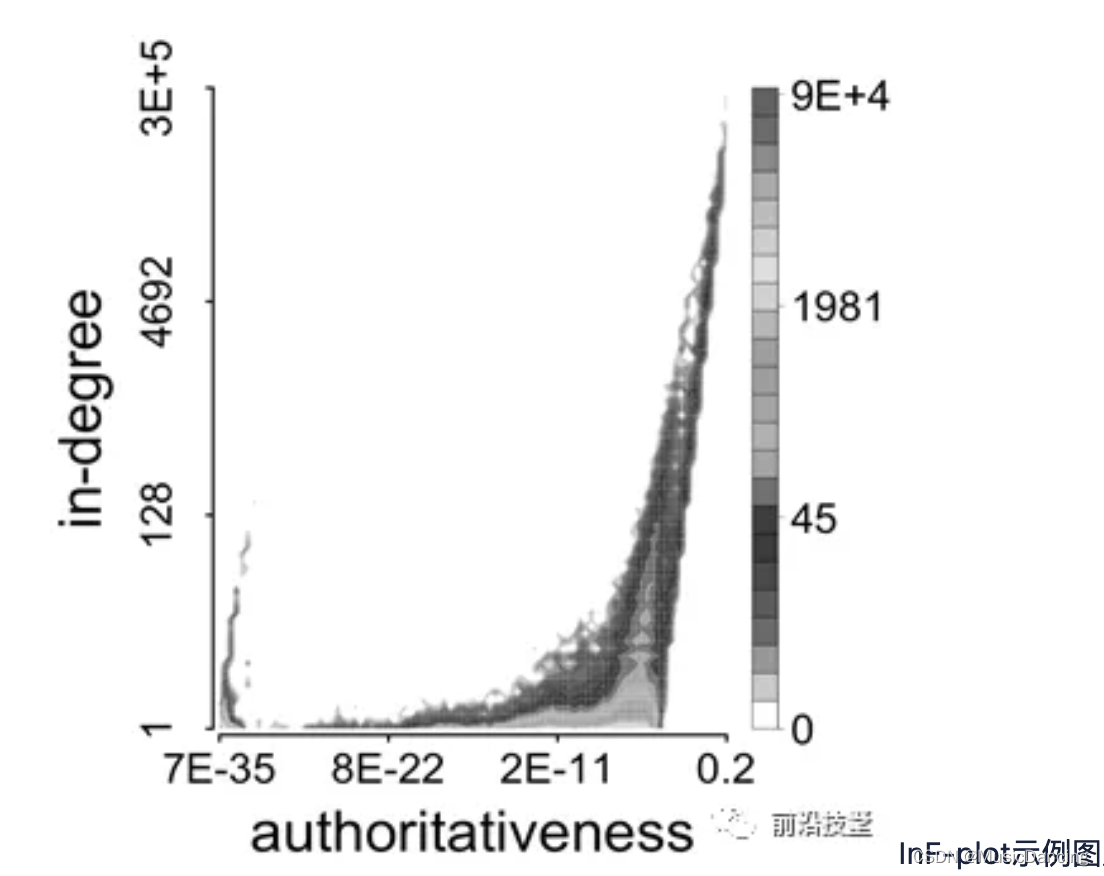
可以看出:直播业务的关注关系中存在一定的高同步性和低正常性的节点,这些节点很大程度上是可疑的。利用CatchSync提取异常节点后,人工验证,确实有问题。
7. 总结
基于图的挖掘算法上线以来,识别团伙作弊在风控中的作用越来越显著,为打击黑灰产提供了充分的技术支撑,且建立起一套较完备的风险分析技术体系,包含了主流的ML技术:统计ML方法、DL方法和基于图的挖掘算法。同时,还搭建了平台化的风控系统,把ML和人工运营有效结合起来,不仅利用有标签的数据持续提高识别能力,还干预和控制了各种风险。在和黑灰产持续对抗的道路上,需要不断优化和提升风控技术手段,以应对未来充满挑战的业务安全生态环境。