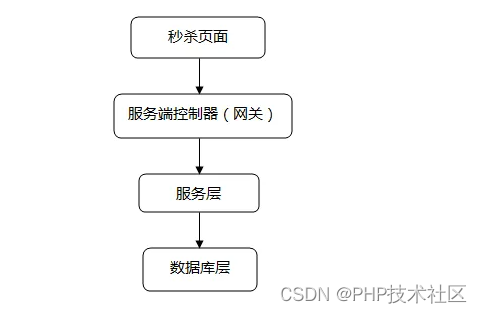
一、背景
在Java中,Iterator是一种设计模式,用于提供一种按顺序访问集合中元素的方式,而不暴露集合的底层表示。Iterator接口主要用于遍历集合,它定义了两种方法:hasNext()和next()。
借助于迭代器Iterator,可以逐页迭代API返回的数据,而不需要用户手动处理分页逻辑。
二、迭代器Iterator
迭代器模式是一种行为设计模式, 让你能在不暴露集合底层表现形式 (列表、 栈和树等) 的情况下遍历集合中所有的元素。
- hasNext()
目的:hasNext()方法用来检测迭代器是否还有下一个元素可以迭代。
返回值:返回一个布尔值,如果存在下一个元素则返回true,否则返回false。
使用场景:在调用next()方法之前使用hasNext()可以避免发生NoSuchElementException。 - next()
目的:next()方法用来获取迭代器当前指向的下一个元素。
返回值:返回迭代器中的下一个元素。
异常:如果没有下一个元素,即在hasNext()返回false的情况下调用next(),将抛出NoSuchElementException。 - 示例用法
Iterator<String> iterator = someCollection.iterator();
while(iterator.hasNext()) {
String element = iterator.next();
// 对element进行操作
}
三、自动分页查询
下图是一个迭代器的框架
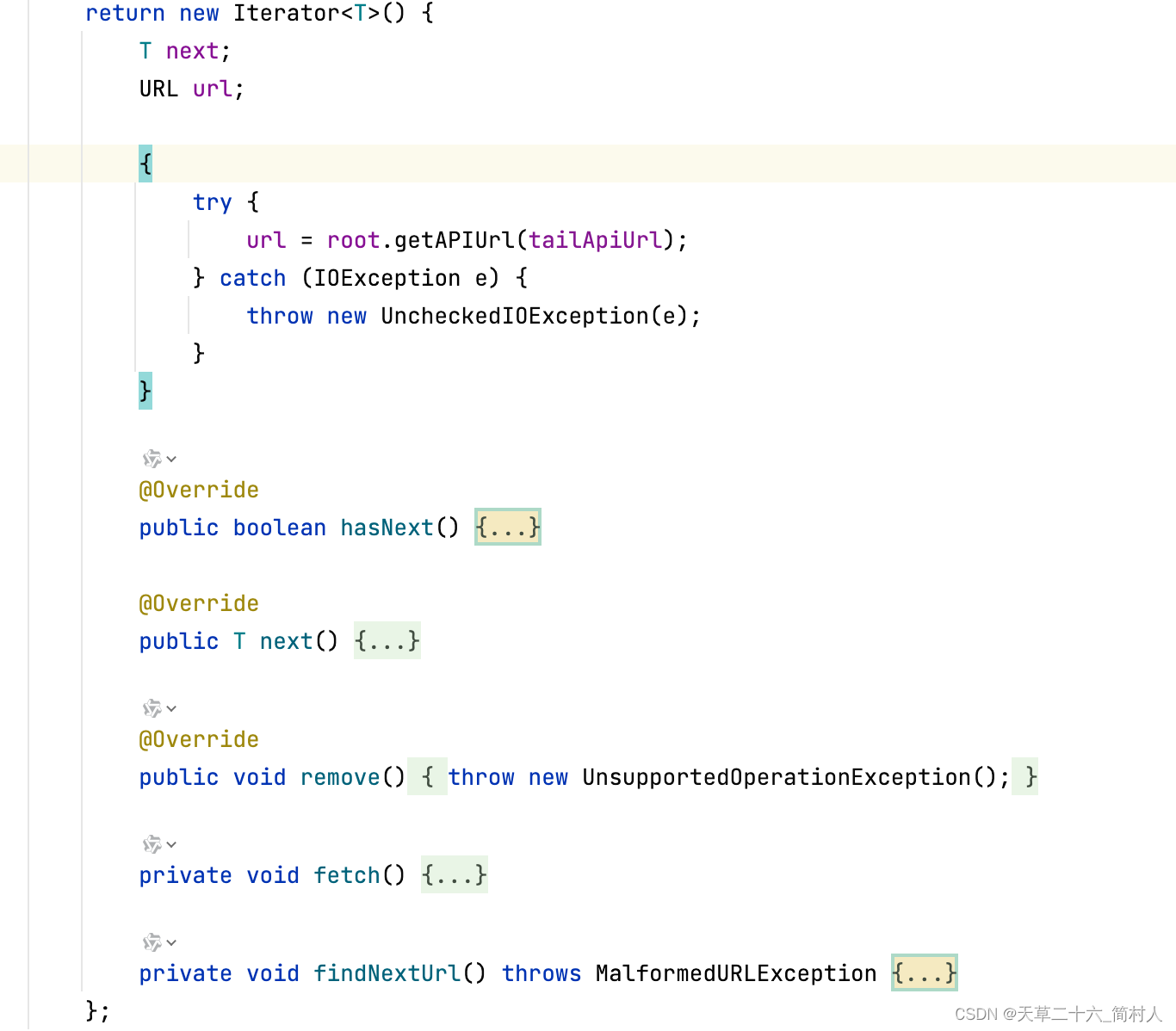
1、遍历每页,直到下一页的数据为空
因为查询是通用的功能,所以这里使用的是泛型,而非具体类。
public <T> List<T> getAll(final String url, final Class<T[]> type) {
List<T> results = new ArrayList<>();
Iterator<T[]> iterator = asIterator(url, type);
while (iterator.hasNext()) {
T[] requests = iterator.next();
if (requests.length > 0) {
results.addAll(Arrays.asList(requests));
}
}
return results;
}
2、实现迭代器
- 有两个成员变量:next(下一个要返回的对象)和url(当前要请求的URL)
- hasNext(),先调用fetch()方法来获取下一个数据,当返回的数组类型,则要求数组的长度大于0;否则next对象必须非空。
- next(),它先调用fetch()来确保next已经被赋值,返回next,并将next重置为null。所以,本方法额外使用了一个变量record,用来存储本次查询返回值。- - 不能直接使用next对象。
public <T> Iterator<T> asIterator(final String requestUrl, final Class<T> type) {
return new Iterator<T>() {
T next;
URL url = new URL(requestUrl);
@Override
public boolean hasNext() {
fetch();
if (next != null && next.getClass().isArray()) {
Object[] arr = (Object[]) next;
return arr.length != 0;
} else {
return next != null;
}
}
@Override
public T next() {
fetch();
T record = next;
if (record == null) {
throw new NoSuchElementException();
}
next = null;
return record;
}
@Override
public void remove() {
throw new UnsupportedOperationException();
}
};
}
- fetch()方法,它会对next进行赋值,如果已有值,则返回。同时,它会组装好查询下一页的请求url。
private void fetch() {
if (next != null) {
return;
}
if (url == null) {
return;
}
try {
try {
next = query(url, type);
assert next != null;
findNextUrl();
} catch (IOException e) {
handleAPIError(e, connection);
}
} catch (IOException e) {
throw new UncheckedIOException(e);
}
}
- findNextUrl(),组装下一页的请求url。使用了正则表达式PAGE_PATTERN来查找和替换URL中的分页页码,即参数page。
private static final Pattern PAGE_PATTERN = Pattern.compile("([&|?])page=(\\d+)");
private void findNextUrl() throws MalformedURLException {
String url = this.url.toString();
this.url = null;
/* Increment the page number for the url if a "page" property exists,
* otherwise, add the page property and increment it.
* The Gitlab API is not a compliant hypermedia REST api, so we use
* a naive implementation.
*/
Matcher matcher = PAGE_PATTERN.matcher(url);
if (matcher.find()) {
Integer page = Integer.parseInt(matcher.group(2)) + 1;
this.url = new URL(matcher.replaceAll(matcher.group(1) + "page=" + page));
} else {
// Since the page query was not present, its safe to assume that we just
// currently used the first page, so we can default to page 2
this.url = new URL(url + (url.indexOf('?') > 0 ? '&' : '?') + "page=2");
}
}
四、另一种分页查询的实现
使用spring 的 Pageable逐页查询,Jpa的实现示例见下:
import org.springframework.data.domain.Page;
import org.springframework.data.domain.Pageable;
Page<Course> findByModifiedDateGreaterThanEqualAndModifiedDateLessThanEqual(Date startDate, Date endDate, Pageable request);
和迭代器Iterator的实现类似,这里使用do…while循环,利用next()方法一直往后查询,直到记录为空。
private void sync(Date lastSyncDate, Date thisSyncDate) {
Page<Course> coursePage;
Pageable page = PageRequest.of(0, 100, Sort.Direction.ASC, "modifiedDate");
do {
coursePage = courseRepository.findByModifiedDateGreaterThanEqualAndModifiedDateLessThanEqual(
lastSyncDate,
thisSyncDate,
page);
List<Course> list = coursePage.getContent();
page = page.next();
} while (!coursePage.isEmpty());
}