文章目录
- 概述
- 原理介绍
- 网络结构
- 核心逻辑
- 迁移学习子网
- 数据拟合子网
- 环境配置
- 训练本次复现代码所用数据集
- 测试本次复现代码所用的评价指标
- 结果展示
- 在O-Haze数据集上的结果
- 在I-Haze数据集上的结果
- 小结
本文涉及的源码可从从零开始搭建图像去雾神经网络该文章下方附件获取
本文复现了一种简单而有效的基于集成学习的双分支非均匀去雾神经网络。该方法使用一个双分支神经网络分别处理上述问题,然后通过一个可学习的融合尾映射它们的不同特征。
论文地址:https://arxiv.org/pdf/2104.08902.pdf
概述
图像去雾神经网络的应用范围相当广泛:
- 交通和安全领域:在交通监控和自动驾驶系统中,清晰的图像对于准确识别和判断道路和交通状况至关重要。然而,由于雾霾的存在,图像质量下降,给交通监控和自动驾驶系统带来了困难。图像去雾技术可以应用于这些领域,提高交通监控和自动驾驶系统的可靠性和安全性。
- 航海领域:在雾霾天气下,船舶航行的安全性会受到严重影响。图像去雾技术可以提高船舶雾霾天气下入港效率,保障航行安全。
- 目标跟踪领域:在目标跟踪系统中,往往要求有较为清晰的输入。图像去雾技术可以在雾霾天气条件下为这些系统提供依旧清晰的输入,保证这类系统的正常识别跟踪。
原理介绍
网络结构
基于集成学习的双分支非均质去雾网络由两个子网络组成,即迁移学习子网和数据拟合子网。每个子网有着特定的目的:迁移学习子网利用预先训练的权重从输入图像中提取鲁棒全局表示;数据拟合子网对当前数据进行处理。融合层采用这两个子网络的级联特征图,并输出无雾图像。
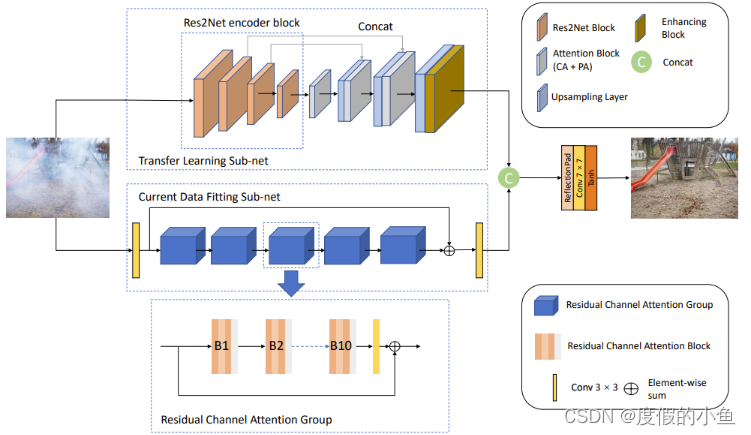
核心逻辑
迁移学习子网
迁移学习子网是一个编码器-解码器结构的网络。该子网络使用Res2Net作为编码器,因为它在分类任务上有很好的性能。具体来说,在编码器中,该网络只使用了Res2Net的前端部分,没有使用全连接层。Res2Net由ResNet改进,传统的ResNet是一个瓶颈结构,由1×1、3×3、1×1的三层不同大小的卷积层组成。Res2Net为了能够在残差模块中实现多尺度多通道,将中间的3×3模块由Bottle2neck实现。
Bottle2neck的实现代码如下,首先通过torch.split拆分特征向量,除了第一个分支经过卷积之外,拆出来的每个分支通过3x3的卷积之后与下一个分支进行拼接之后分两步,一步保存继续,一步再与下一个分支做拼接。将一个3×3卷积层替换为对每个拆分的通道的3×3卷积使得该模块在不增加额外参数量的同时,泛化性能增强。
```class Bottle2neck(nn.Module):
expansion = 4
def __init__(self, inplanes, planes, stride=1, downsample=None, baseWidth=26, scale=4, stype='normal'):
super(Bottle2neck, self).__init__()
width = int(math.floor(planes * (baseWidth / 64.0)))
self.conv1 = nn.Conv2d(inplanes, width * scale, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(width * scale)
if scale == 1:
self.nums = 1
else:
self.nums = scale - 1
if stype == 'stage':
self.pool = nn.AvgPool2d(kernel_size=3, stride=stride, padding=1)
convs = []
bns = []
for i in range(self.nums):
convs.append(nn.Conv2d(width, width, kernel_size=3, stride=stride, padding=1, bias=False))
bns.append(nn.BatchNorm2d(width))
self.convs = nn.ModuleList(convs)
self.bns = nn.ModuleList(bns)
self.conv3 = nn.Conv2d(width * scale, planes * self.expansion, kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(planes * self.expansion)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stype = stype
self.scale = scale
self.width = width
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
spx = torch.split(out, self.width, 1)
for i in range(self.nums):
if i == 0 or self.stype == 'stage':
sp = spx[i]
else:
sp = sp + spx[i]
sp = self.convs[i](sp)
sp = self.relu(self.bns[i](sp))
if i == 0:
out = sp
else:
out = torch.cat((out, sp), 1)
if self.scale != 1 and self.stype == 'normal':
out = torch.cat((out, spx[self.nums]), 1)
elif self.scale != 1 and self.stype == 'stage':
out = torch.cat((out, self.pool(spx[self.nums])), 1)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
此外,该网络采用了由通道注意力模块(CA)和像素注意力模块(PA)组成的特征注意作为注意力模块,插入在网络的高维部分以提取图像的结构特征和细节特征。
通道注意力CA的代码如下:
解码器部分,该网络使用用于图像超分辨率恢复的Pixel Shuffle作为该子网中的上采样模块。该模块可以将低分辨的特征图,通过卷积和多通道间的重组得到高分辨率的特征图,在实现时可以直接使用torch库中的nn.PixelShuffle函数,代码如下。
该网络受enhanced pix2pix dehazing network (EPDN)的启发,使用。在训练阶段,在特征进入融合层之前引入了一个增强模块。该模块使用了DCPDN中的金字塔池化模块,以两个3×3的卷积层作为开端,输出结果经平均池化层下采样为4×、8×、16×和32×四个不同尺寸的特征图。不同尺度的特征图提供不同的感受野,帮助图像在不同尺度上重建图像。之后,不同尺度的特征图由1×1卷积层进行降维并恢复到与原始图像尺寸相同的大小,最后与开端卷积层的输出进行拼接,作为最后3×3卷积层的输入。该模块将不同尺度的特征细节融入到最终的结果,起到对恢复的图像特征进行保持增强的作用。该模块的代码如下。
```class Enhancer(nn.Module):
def __init__(self, in_channels, out_channels):
super(Enhancer, self).__init__()
self.relu = nn.LeakyReLU(0.2, inplace=True)
self.tanh = nn.Tanh()
self.refine1 = nn.Conv2d(in_channels, 20, kernel_size=3, stride=1, padding=1)
self.refine2 = nn.Conv2d(20, 20, kernel_size=3, stride=1, padding=1)
self.conv1010 = nn.Conv2d(20, 1, kernel_size=1, stride=1, padding=0)
self.conv1020 = nn.Conv2d(20, 1, kernel_size=1, stride=1, padding=0)
self.conv1030 = nn.Conv2d(20, 1, kernel_size=1, stride=1, padding=0)
self.conv1040 = nn.Conv2d(20, 1, kernel_size=1, stride=1, padding=0)
self.refine3 = nn.Conv2d(20 + 4, out_channels, kernel_size=3, stride=1, padding=1)
#self.upsample = F.upsample_nearest
self.upsample=F.interpolate
self.batch1 = nn.InstanceNorm2d(100, affine=True)
def forward(self, x):
dehaze = self.relu((self.refine1(x)))
dehaze = self.relu((self.refine2(dehaze)))
shape_out = dehaze.data.size()
shape_out = shape_out[2:4]
x101 = F.avg_pool2d(dehaze, 32)
x102 = F.avg_pool2d(dehaze, 16)
x103 = F.avg_pool2d(dehaze, 8)
x104 = F.avg_pool2d(dehaze, 4)
x1010 = self.upsample(self.relu(self.conv1010(x101)), size=shape_out)
x1020 = self.upsample(self.relu(self.conv1020(x102)), size=shape_out)
x1030 = self.upsample(self.relu(self.conv1030(x103)), size=shape_out)
x1040 = self.upsample(self.relu(self.conv1040(x104)), size=shape_out)
dehaze = torch.cat((x1010, x1020, x1030, x1040, dehaze), 1)
dehaze = self.tanh(self.refine3(dehaze))
return dehaze
总览整个迁移子网络,编码器模块加载比随机初始化参数的模型更具鲁棒性的ImageNet[作为预训练参数,但由于其仅使用了Res2net的前端部分,容易使网络丢失恢复图像细节的重要信息。为了改善该问题,本方法建立了第二个子网——数据拟合子网。
数据拟合子网
数据拟合子网由多个残差注意力模块组成,每个残差注意力模块由卷积层和通道注意力组成。对于残差注意力模块的实现如下所示,通道注意力模块有两条分支,一条负责提取不同的通道特征,另一条负责生成特征权重,最后将两个结果进行融合得到通道特征权重。通道注意力的使用突出了显著特征,增强了模型对数据的拟合能力。
```class Residual_CA(nn.Module):
def __init__(self, channels):
super(Residual_CA, self).__init__()
self.PointWise = nn.Conv2d(channels, channels, 1)
self.RELU = nn.ReLU()
self.GlobalPlooling = nn.AvgPool2d(1)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
out1 = self.PointWise(x)
out1 = self.RELU(out1)
out1 = self.PointWise(out1)
out2 = self.GlobalPlooling(out1)
out2 = self.PointWise(out2)
out2 = self.RELU(out2)
out2 = self.PointWise(out2)
out2 = self.sigmoid(out2)
out = out1 * out2
out = x + out
return out
该网络为了防止梯度下降,还在不同的模块之间使用了跳跃连接。为了保留细致的特征,该子网没有使用下采样和上采样操作。这些获得的细节特征可以看作是对迁移学习子网特性的补充。由于数据拟合子网络是从零开始训练的,并且是基于全分辨率目的构建的,因此它将适合数据并提取更多指定的特征且有着优秀的拟合能力。但同时,更容易遇到过拟合问题。因此,为了改善该数据拟合子网的过拟合问题,建立迁移学习分支的作用是不可忽视的。
##融合尾
该网络的融合尾使用集成的方法产生最终的输出。具体来说,融合尾从两个分支获取特征的拼接,然后学习映射这些特征来恢复图像。融合尾由一个卷积层和一个双曲切线激活函数(Tanh)组成。该模块之所以只采用单一的卷积运算,是因为这两个分支已经为恢复清晰的图像提供了充分而鲜明的特征。相比之下,过多的融合尾会影响方法的整体泛化能力,导致性能下降。整个双分支网络的整体代码如下。
环境配置
使用Pytorch1.12和一台24GB RTX 3090 GPU来实现所有的实验。在所有的实验中,采用平滑L1损失和MS-SSIM损失作为模型的损失函数。选择ADAM优化器作为优化算法,并设置学习率为0.0001,批次大小为1。在训练过程中,降低学习率,每100个epochs降低25%。在训练过程中为了测试模型的普适性,对不同的数据集选取不同的图像大小。
训练本次复现代码所用数据集
O-Haze和I-Haze数据集是由专业雾霾机生成的真实雾霾分别在户外和室内拍摄的图像,。NH-Haze数据集是CVPR-NTRIRE2020竞赛中去雾赛道使用的数据集,具体的组成将在表1详细介绍。为了验证我们网络的鲁棒性,我们选取O-Haze的前40对有雾/无雾图像对、I-Haze的前30对有雾/无雾图像对、NH-Haze的前50对有雾/无雾图像对分别作为训练数据集。剩余有雾/无雾图像对分别作为测试数据集以验证结果。
| 数据集 | 图片数量 | 真实\合成 | 室内\室外 |
|---|---|---|---|
| O-Haze | 45 | 真实 | 室外 |
| I-Haze | 35 | 真实 | 室内 |
| NH-Haze | 55 | 真实 | 室外 |
测试本次复现代码所用的评价指标
为了评价所提出的模型及方法,本文使用常用的峰值信噪比(PSNR)和结构相似度指数(SSIM)来评价模型的性能。其中,PSNR或SSIM值越高,代表恢复的效果越好。均使用均值的形式处理测试集实验结果。
结果展示
在O-Haze数据集上的结果
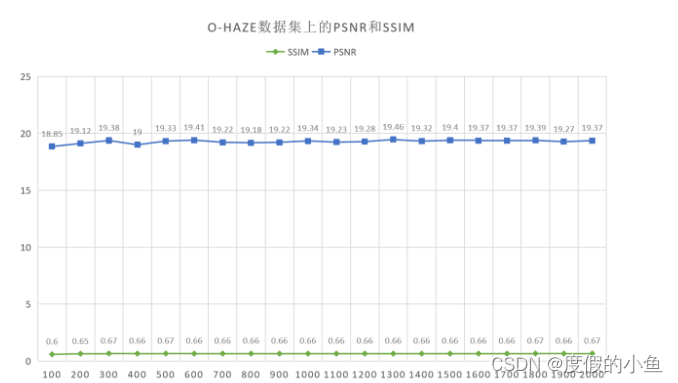
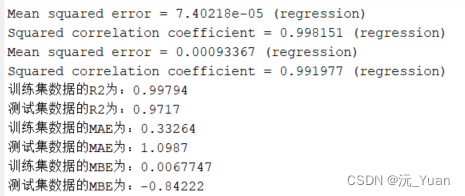
由图中的PSNR和SSIM值所示,本文方法在O-Haze数据集上表现稳定,在训练200次的时候便接近收敛,收敛速度较快;在训练300次时取得最好的模型,PSNR达到19.38,SSIM达到0.67。在剩余的1700次训练中,PSNR基本稳定在19.25左右,SSIM基本稳定在0.66左右。
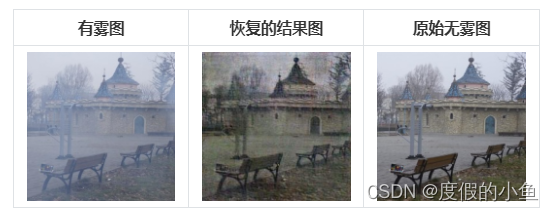
本文方法在300次训练出的模型在O-Haze[测试集上的测试结果如图3所示,第一列是原始有雾图像,第二列是本文方法的去雾结果,第三列是真实无雾图像。可以发现,本文方法得到的恢复图像对比原始有雾图像几乎没有雾霾残留,去雾效果明显。但对比真实无雾图像,可以发现,本文方法得到的恢复图像存在细节模糊,色调昏暗的缺点,饱和度较低。
综上,本文方法在O-Haze数据集上虽然能够快速收敛并表现稳定,但由于边缘模糊,色彩饱和度较低使得恢复的图像缺失愉悦的视觉感受。
在I-Haze数据集上的结果
同样,在I-Haze数据集中,选择了前30对图像用以2000次的网络训练,每100次生成一个模型。生成的20个模型在I-Haze的剩余5对图像上的测试结果如图所示。由图可以发现,在I-Haze数据集上,其收敛速度快于O-Haze数据集,仅训练了100次便趋向拟合,仅训练200次便得到最优模型,PSNR达18.71,SSIM达0.71。在之后的1800次训练中,其PSNR稳定在18.60左右,SSIM稳定在0.71左右。
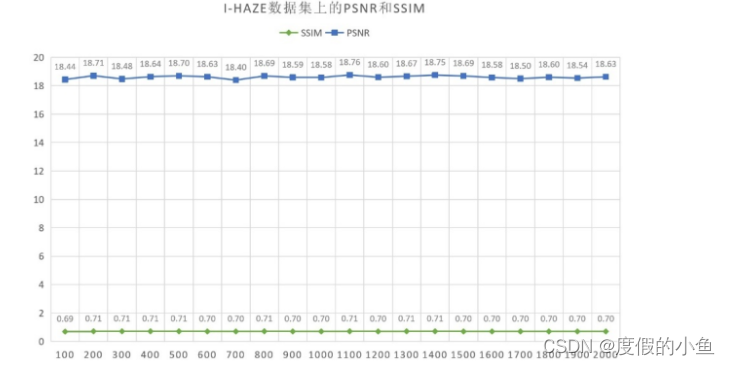
下图展示了本文方法训练得到的最优模型在I-Haze测试集上的结果,其中,第一列是原始有雾图像,第二列是本文方法的去雾结果,第三列是真实无雾图像。将本文方法的去雾结果对比原始有雾图像可以发现,本文方法能够有效的去除室内的均匀雾霾,但对白色区域的恢复效果不理想。对比真实无雾图像可以发现,本文方法恢复的图像与原图还有较大差距,有着与在O-Haze数据集上的模型相同的缺点。对于均匀雾霾室内场景下物体边缘及整体色彩的恢复表现较差。

小结
图像去雾神经网络在图像处理领域具有重要意义,主要体现在以下几个方面:
- 提升图像质量:雾天拍摄的图像通常存在对比度低、细节模糊、颜色失真等问题,这严重影响了图像中目标物体的可见性和可识别性。图像去雾神经网络能够有效地改善这些问题,通过去除或减轻图像中的雾气,提高图像的整体对比度和亮度,使原本被遮蔽的物体细节得以显现,从而提升图像质量。
- 提高目标检测准确性:在自动驾驶、视频监控、遥感探测等领域,目标检测的准确性直接影响着系统的可靠性和安全性。经过去雾处理的图像,能够让目标检测模型在不利天气条件下保持甚至提高原有的检测精度,避免因图像质量下降而导致的误检或漏检。
- 增强特征提取:目标检测算法通常依赖于从图像中提取有效的特征,例如边缘、纹理、颜色和形状等。去雾后的图像,其特征更为鲜明,有利于卷积神经网络(CNN)等深度学习模型更准确地捕获和学习目标物体的关键特征,从而提升检测的准确性。
- 提高鲁棒性:通过集成图像去雾模块,可以在前端图像预处理阶段就改善输入到目标检测模型的数据质量,增强了整个视觉系统的鲁棒性,使其能够在各种复杂的气象环境中稳定、高效地工作。
- 扩大应用场景:图像去雾技术不仅限于提高目标检测准确性,还可以应用于其他领域,如医学影像分析、遥感图像处理、安防监控等。在这些领域,图像去雾技术同样能够提升图像质量,帮助人们更准确地获取和分析图像中的信息。
图像去雾神经网络对于提升图像质量、提高目标检测准确性、增强特征提取、提高鲁棒性以及扩大应用场景等方面都具有重要意义。随着深度学习技术的不断发展,图像去雾神经网络将在更多领域发挥重要作用。