LLMPerf-为LLM推理提供可复现的性能指标
翻译自文章:Reproducible Performance Metrics for LLM inference
结合之前的LLMPerf测试大模型API性能的文章进行查看,效果更佳。
1. 摘要
-
我们见过许多关于LLM性能的声明;然而,这些声明往往无法复现。
-
今天,我们发布了LLMPerf(https://github.com/ray-project/llmperf),这是一个开源项目,用于基准测试LLM,以使这些声明可复现。我们讨论了选择的指标以及如何测量它们。
-
有趣的见解:100个输入token对延迟的影响与一个输出token大致相同。如果你想加快速度,减少输出比减少输入更有效。
-
我们还展示了这些基准测试在一些当前LLM产品上的结果,并确定了哪些LLM目前最适合什么用途。我们重点关注了Llama 2 70b。
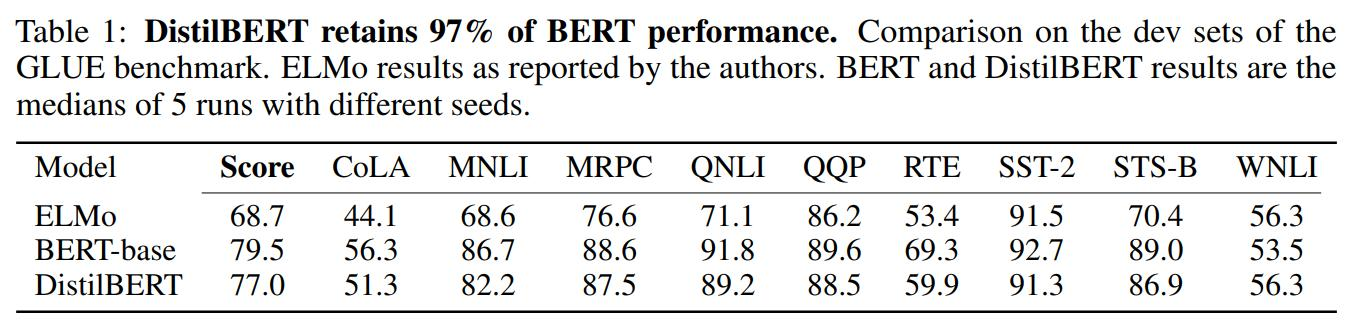
-
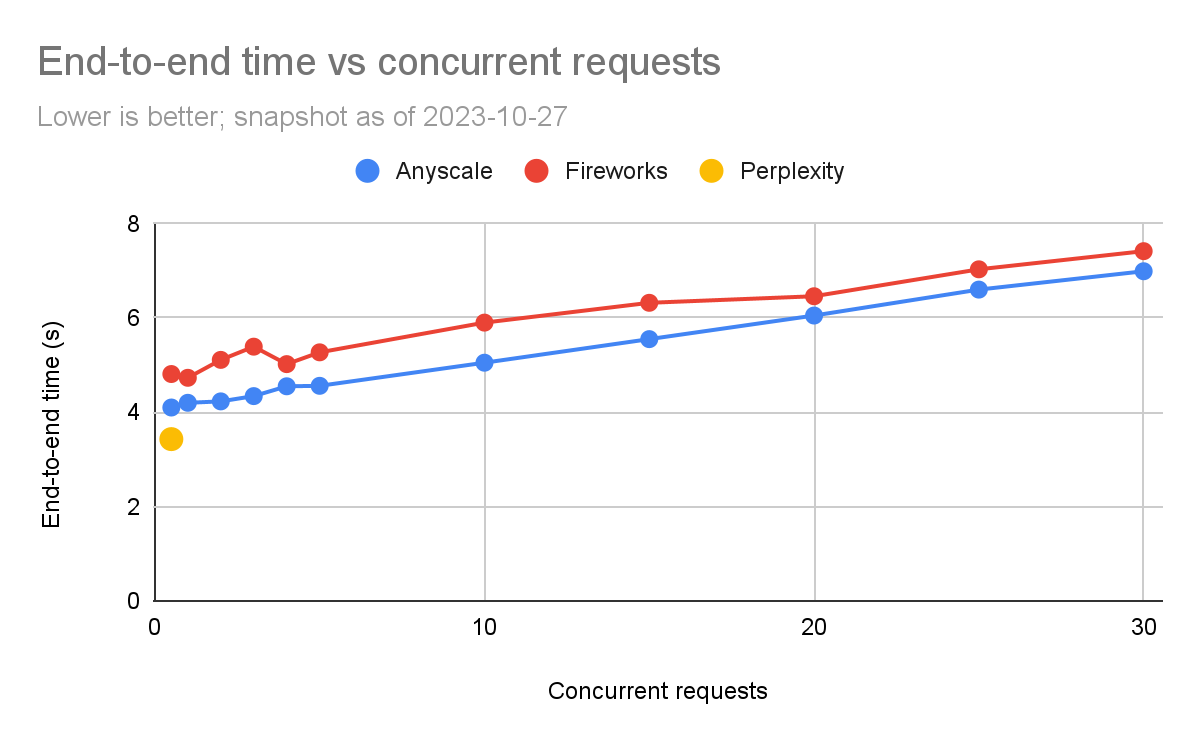
总结我们在每个token价格上的结果:Perplexity beta由于低速率限制,目前尚不适用于生产;Fireworks.ai和Anyscale Endpoints都可行,但Anyscale Endpoints在典型工作负载(550个输入token,150个输出token)的平均端到端延迟上便宜15%,快17%。在高负载水平下,Fireworks的首次token时间(TTFT)稍好。
-
特别是对于LLM,性能特性变化迅速,每个用例都有不同的需求,适用情况因人而异。
2. 问题
最近,许多人对其LLM推理性能做出了各种声明。然而,这些声明往往无法复现,并且缺乏详细信息。例如,有一篇帖子仅仅说明了结果是针对“不同输入大小”的,但其图表我们根本无法理解。
我们曾考虑发布自己的基准测试结果,但意识到仅仅这样做只会延续不可复现结果的问题。因此,除了发布结果之外,我们还将我们的内部基准测试工具开源。你可以在这里下载它。README文件中有许多示例展示了如何使用它。
在本文的其余部分,我们将讨论我们测量的关键指标以及各个供应商在这些指标上的表现。
3. LLM的定量性能指标
LLM的关键指标有哪些?我们建议标准化以下指标:
通用指标
以下指标适用于共享公共端点以及专用实例。
每分钟完成请求数
在几乎所有情况下,您都需要向系统发出并发请求。这可能是因为您正在处理来自多个用户的输入,或者您有批量推理工作负载。
在许多情况下,共享公共端点提供商会在非常低的水平上限制您的请求,除非您与他们达成额外的协议。我们曾见过一些提供商将限制设置为90秒内不超过3个请求。
第一个token的响应时间(TTFT)
在流式应用中,TTFT是指LLM返回第一个token所需的时间。我们不仅关注平均TTFT,还关注其分布情况:P50、P90、P95和P99。
token间延迟(ITL)
token间延迟是指连续token之间的平均时间。我们决定在计算token间延迟时包括TTFT。我们曾见过一些系统在端到端时间内非常晚才开始流式传输。
端到端延迟
端到端延迟应大致等于平均输出token长度乘以token间延迟。
每个典型请求的成本
API提供商通常可以在其他指标和成本之间进行权衡。例如,您可以通过在更多GPU上运行相同的模型或使用更高端的GPU来减少延迟。
4. 专用实例的附加指标
如果您使用专用计算资源运行LLM,例如使用Anyscale Private Endpoints,则有一些额外的标准需要考虑。请注意,将共享LLM实例与专用LLM实例的性能进行比较非常困难:它们的约束条件不同,并且利用率成为一个更加显著的实际问题。
配置
同样重要的是要注意,同一个模型可以有不同的配置,从而在延迟、成本和吞吐量之间做出不同的权衡。例如,一个在p4de实例上运行的CodeLlama 34B模型可以配置为8个每个使用1个GPU的副本,4个每个使用2个GPU的副本,2个每个使用4个GPU的副本,或者1个使用所有8个GPU的副本。你还可以配置多GPU用于流水线并行或张量并行。每一种配置都有不同的特性:8个每个使用1个GPU的副本可能具有最低的TTFT(因为有8个“队列”在等待输入),而1个使用8个GPU的副本可能具有最高的吞吐量(因为有更多的内存用于批处理并且实际上有8倍的内存带宽)。
每种配置都会导致不同的基准测试结果。
输出令牌吞吐量
还有一个重要的标准:总生成令牌吞吐量。这使你能够进行成本比较。
满负荷利用时每百万令牌的成本
为了比较不同配置的成本(例如,你可以在1个A10G GPU、2个A10G GPU或1个A100-40GB GPU上部署一个Llama 2 7B模型等),重要的是考虑给定输出的总部署成本。在这些比较中,我们将使用AWS一年的预留实例定价。
5. 我们考虑但未包含的指标
当然,还有其他指标可以添加到这个列表中。
预填充时间
由于预填充时间只能通过对第一个令牌生成时间相对于输入大小的回归来间接测量,我们选择在这一轮基准测试中不包括它。我们计划在未来版本的基准测试中添加预填充时间。
根据我们对当前大多数技术的经验,预填充时间(获取输入令牌、将其加载到GPU并计算注意力值)对延迟的影响不如输出令牌显著。
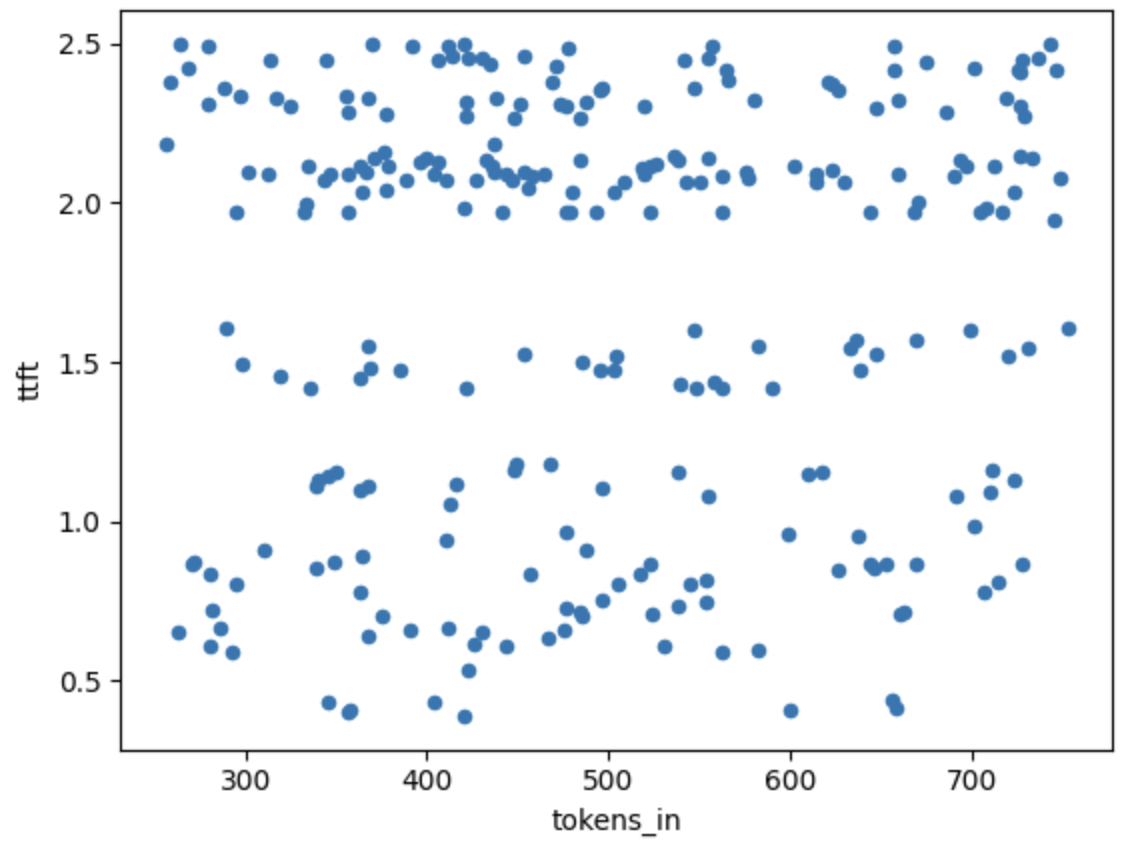
上图展示了首个令牌生成时间(TTFT)与输入大小的变化情况。所有样本均来自单次运行(5个并发请求)。所有这些数据点会被平均,以在下列图表中给出一个单一的样本点。
可以看到,在250个令牌输入到800个令牌输入之间,输入令牌数量与TTFT之间似乎没有明显关系,并且由于其他原因,TTFT中的随机噪声“掩盖”了这种关系。实际上,我们确实尝试通过比较550个输入令牌和3500个输入令牌的输出并估计梯度来用回归法估算这个关系,发现每增加一个输入令牌会增加0.3-0.7毫秒的端到端时间,而每增加一个输出令牌会增加30-60毫秒的端到端时间(针对在Anyscale Endpoints上运行的Llama 2 70b)。因此,输入令牌对端到端延迟的影响约为输出令牌的1%。我们将在未来回到这一测量。
总吞吐量(包括输入和生成的令牌)
鉴于预填充时间不可测量,并且所花费的时间更多地取决于生成令牌而不是输入大小,我们认为关注输出是正确的选择。
输入选择
在运行此测试时,我们需要选择用于测试的输入以及速率。
我们看到有人使用随机令牌生成固定大小的输入,然后使用最大令牌硬停来控制输出大小。我们认为这种方法次优,原因有二:
-
随机令牌不代表真实数据。因此,某些依赖于数据实际分布的性能优化算法(例如推测解码)在随机数据上的表现可能比在真实数据上的表现更差。
-
固定大小不代表真实数据。这意味着某些算法(例如分页注意力和连续批处理)的优势不会被体现出来:它们的很多创新在于处理输入和输出大小的变化。
因此,我们希望使用“真实”数据。显然,这因应用而异,但我们至少需要一个平均值作为起点。
输入大小
为了确定“典型”的输入和输出大小,我们查看了来自Anyscale Endpoints用户的数据。基于这些数据,我们选择了:
-
平均输入长度:550个令牌(标准差150个令牌)
-
平均输出长度:150个令牌(标准差20个令牌)
为了简化,我们假设输入和输出服从正态分布。在未来的工作中,我们将考虑更具代表性的分布,如泊松分布(其在建模令牌分布方面具有更好的属性,例如,泊松分布在负值时为0)。在计算令牌时,我们始终使用Llama 2快速分词器来估计系统独立的令牌数量——例如,我们在以往的研究中注意到,ChatGPT分词器比Llama分词器更“高效”(Llama 2为每个词1.5个令牌,而ChatGPT为每个词1.33个令牌)。ChatGPT不应该因此受到惩罚。
输入内容
为了使基准测试具有代表性,我们决定给LLM安排两个任务。
第一个任务是将数字的文字表示转换为数字表示。这实际上是一个“校验和”任务,以确保LLM功能正常:我们应该期望返回值与我们发送的值一致(根据我们的经验,在运行良好的LLM中,这种情况很少低于97%)。
第二个任务是提供更灵活的输入和输出。我们在输入中包括一定数量的莎士比亚十四行诗的行数,并要求LLM在输出中选择一定数量的行数。这给我们提供了实际的令牌和大小分布。我们还可以用这个来对LLM进行“合理性检查”——我们期望输出的行看起来与我们提供的行有一定相似度。
并发请求
一个关键特性是并发请求的数量。显然,对于固定的资源集,更多的并发请求会减慢输出速度。为了测试,我们已将标准化的关键数字定为5。
6. LLMPerf
LLMPerf实现了上述测量方法。它也是参数化的(例如允许你更改输入和输出大小以匹配你的应用程序,从而可以为你的工作运行提供商的基准测试)。
LLMPerf 可在此获取:https://github.com/ray-project/LLMPerf
7. LLM产品的基准测试结果
如我们上面提到的,比较按令牌计费的LLM产品(通常是共享的)和按时间单位计费的产品(按时间单位付费)是困难的。对于这些实验,我们关注我们知道的按令牌计费的产品。因此,我们选择了在Anyscale、Fireworks和Perplexity上的llama-2-70b-chat产品。
对于Fireworks,我们使用了Developer PRO账户(将请求速率限制增加到每分钟100次)。
每分钟完成的请求
我们使用这个来测量通过改变并发请求的数量每分钟可以进行多少请求,并观察整体时间的变化。然后,我们将完成的请求数量除以完成所有请求所需的时间(以分钟为单位)。
请注意,这可能略微保守,因为我们将并发请求分批次完成,而不是连续查询。例如,如果我们正在进行5个并发请求,其中4个在5秒内完成,而另一个在6秒内完成,那么就有1秒时间内并没有完全达到5个并发请求。
下面的图表显示了结果。
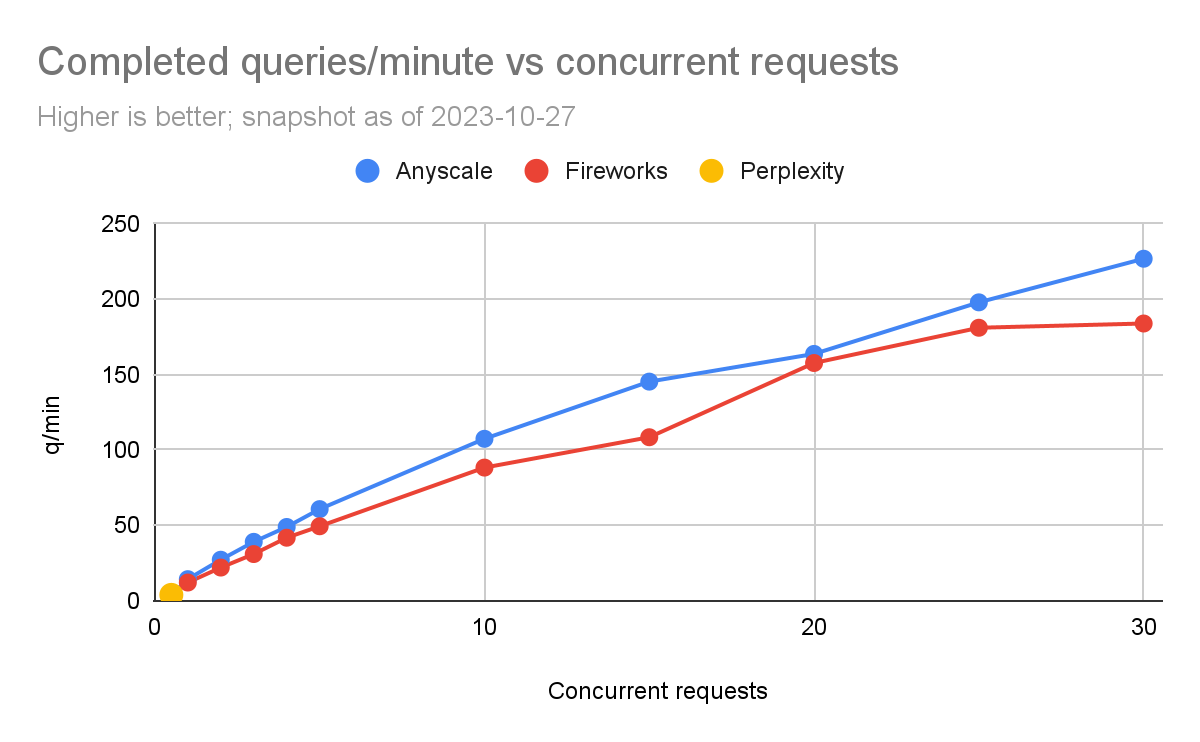
我们不得不处理的一个问题是,Perplexity的速率限制非常低。因此,我们只能在每轮之间加入15秒的暂停,才能完成一个“苹果对苹果”的比较。如果少于这个时间,我们会开始从Perplexity获得异常。我们将这个标记为每秒0.5个并发请求。我们运行实验直到开始收到异常。
我们可以看到,Fireworks和Anyscale可以扩展到每分钟完成数百个查询。Anyscale的扩展性略高一些(每分钟最多达到227个查询,而Fireworks为184个查询)。
第一个token的响应时间(TTFT)
我们比较了每个产品的TTFT。对于流式应用程序,如聊天机器人,TTFT尤为重要。
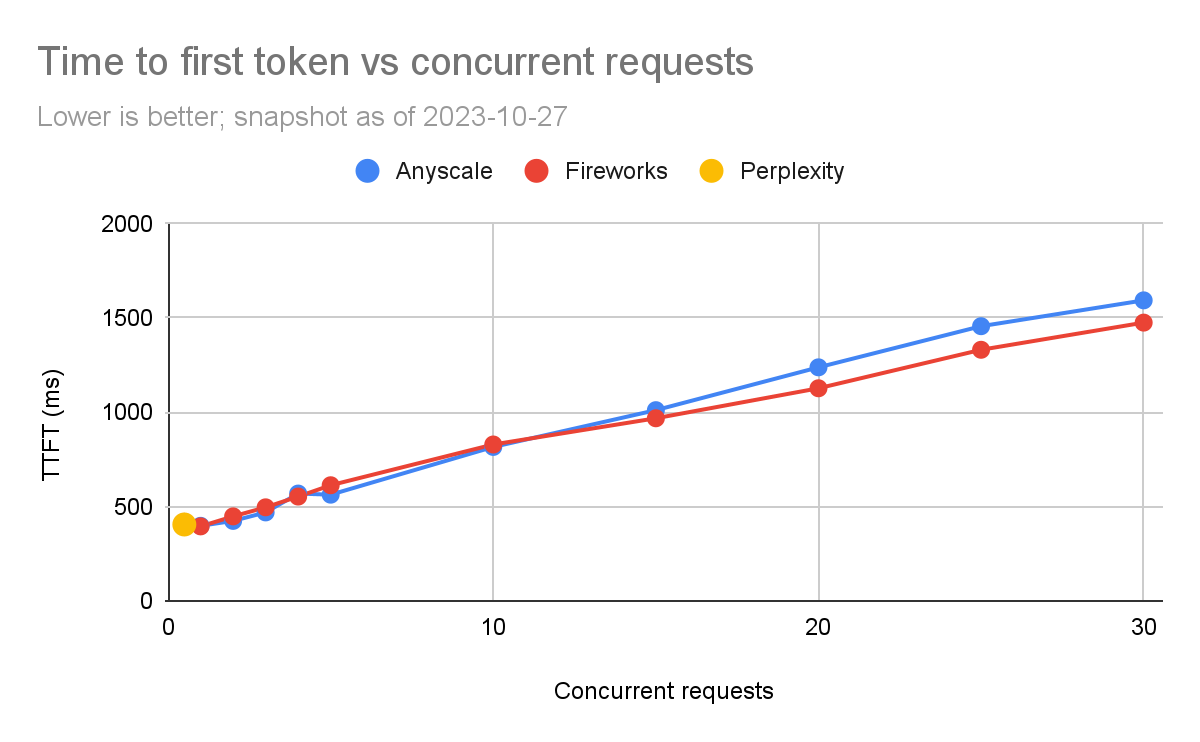
再次地,我们在测试Perplexity时有限制。在低负载水平下,Anyscale的速度较快,但随着并发请求的增加,Fireworks似乎稍微更好。在5个并发查询(我们通常关注的数量)时,延迟通常在100毫秒内(563毫秒对比630毫秒)。还必须注意,TTFT在网络情况下有很高的方差(例如,如果服务部署在附近或远处的区域)。
token间延迟(ITL)
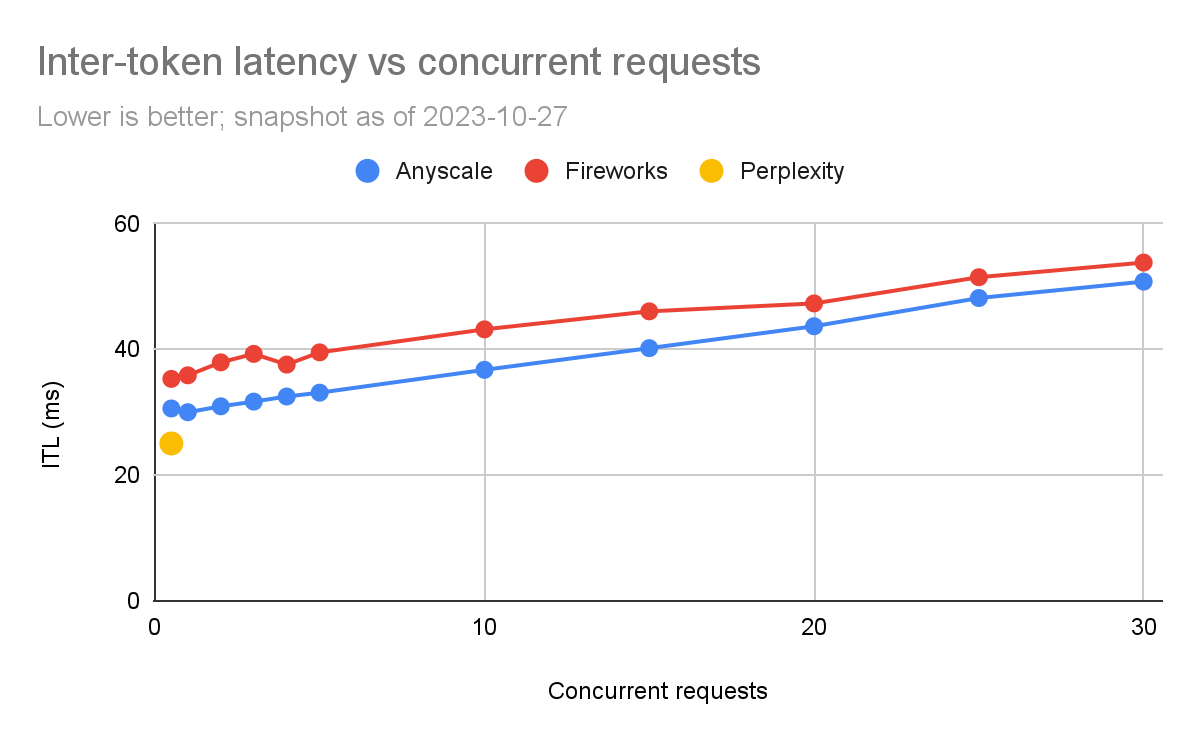
根据上面的内容,我们可以看到Anyscale的令牌间延迟一直比Fireworks好,尽管差异相对较小(约为5%到20%)。
端到端延迟
下面的图表显示完成查询所需的端到端时间。我们可以看到,端到端请求时间在噪声方面是比较敏感的一个指标。
我们可以看到,在这里,Anyscale的端到端时间一直比Fireworks的好,但随着负载水平的增加,差距在高负载下会缩小(特别是比例上)。在5个并发查询时,Anyscale为4.6秒,而Fireworks为5.3秒(快15%)。但是在30个并发查询时,差异较小(Anyscale快5%)。
每1000个请求的成本
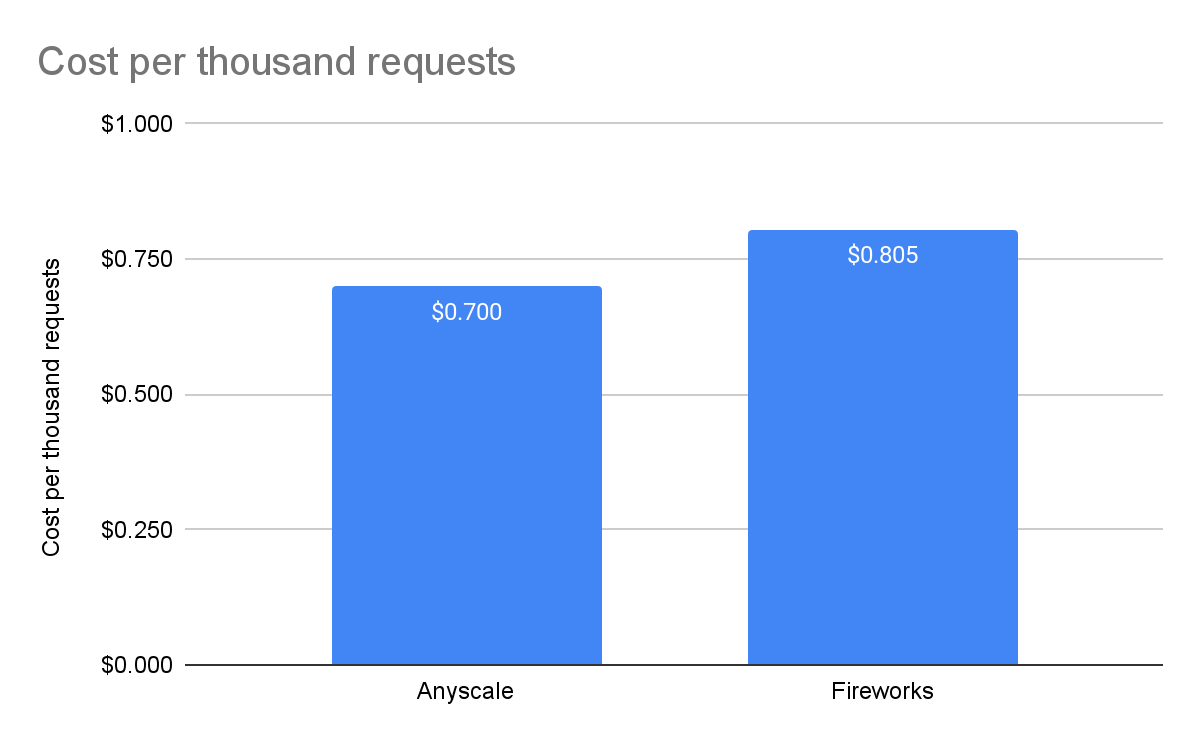
Perplexity处于公开测试阶段,因此没有价格 - 我们无法将其包括在比较中。对于Fireworks,我们使用了他们网站上列出的价格,即每百万输入令牌0.7美元,每百万输出令牌2.80美元。对于Anyscale Endpoints,我们使用了他们定价页面上列出的价格,即每百万令牌1美元,不论输入还是输出。
8. 解读这些结果
现在我们有了这些数据,我们可以确定何时使用每个LLM产品:
-
对于低流量的交互式应用程序(比如聊天机器人),这三个产品都可以胜任。ITL和TTFT足够小,不会成为主要问题,而且它们之间的差异不大,因为人类阅读大约每秒5个令牌,即使最慢的产品也是这个速度的6倍。然而,在这种工作负载下,Anyscale是这三个产品中最便宜的,便宜约15%。
-
如果你正在寻找端到端的超低延迟应用程序,并且工作量不是很大,Perplexity在公开测试结束后可能值得考虑。在Perplexity发布价格之前,很难知道这种低延迟的“代价”。
-
如果你有大量的工作负载,Anyscale和Fireworks值得考虑。然而,在这个特定的工作负载下,Anyscale便宜约15%。如果你的输入到输出比例很高,例如10个输入令牌对1个输出令牌,那么Fireworks会更便宜(Fireworks为每美元89美分,而Anyscale为每美元1美元)。极端摘要可能就是一个这样的例子。
这些考虑将帮助你根据具体的需求和预算选择合适的LLM产品。
9. 结论
LLM性能正在以令人难以置信的速度发展。我们希望社区能够发现LLMPerf基准测试工具在比较输出方面的有用性。我们将继续努力改进LLMPerf,特别是使其更容易控制输入和输出的分布,希望这将提高透明度和可重现性。我们也希望您能够使用它来模拟您特定工作负载的成本和性能。
从这个研究中我们看到,并非所有基准测试都适合所有情况,特别是在LLM的情况下,它确实取决于您的具体应用。
本文由 mdnice 多平台发布