1.bert训练的方法
为了训练BERT模型,主要采用了两种方法:掩码语言模型(Masked Language Model, MLM)和下一个句子预测(Next Sentence Prediction, NSP)。
方法一:掩码语言模型(Masked Language Model, MLM)
-
掩码处理:
- 在训练过程中,随机选择输入句子中15%的词汇,并将它们用特殊标记[MASK]替换。
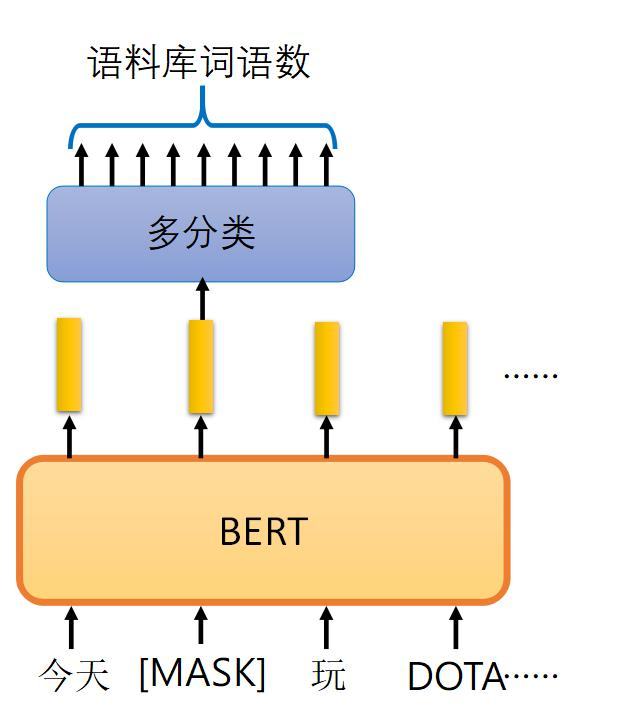
- 例如,句子“今天我玩DOTA”可能被处理成“今天[MASK]玩DOTA”。
-
预测被掩码的词汇:
- 模型需要根据上下文预测被掩码的词汇是什么。
- 图中展示了BERT模型如何处理输入序列,尝试预测被掩码的词汇,最终通过多分类层输出预测结果。
-
目标:
- 通过这种方式,模型可以学习到每个词汇在不同上下文中的表示,提高对词汇语义的理解。
方法二:下一个句子预测(Next Sentence Prediction, NSP)
-
句子对构建:
- 在训练数据中,构建句子对,其中一部分句子对是连续的(即前后两句在原文本中是连续的),另一部分是随机组合的(即前后两句在原文本中并不连续)。
-
输入处理:
- 对每对句子添加特殊标记[CLS]和[SEP],其中[CLS]标记句子的开始,[SEP]标记句子的分隔。
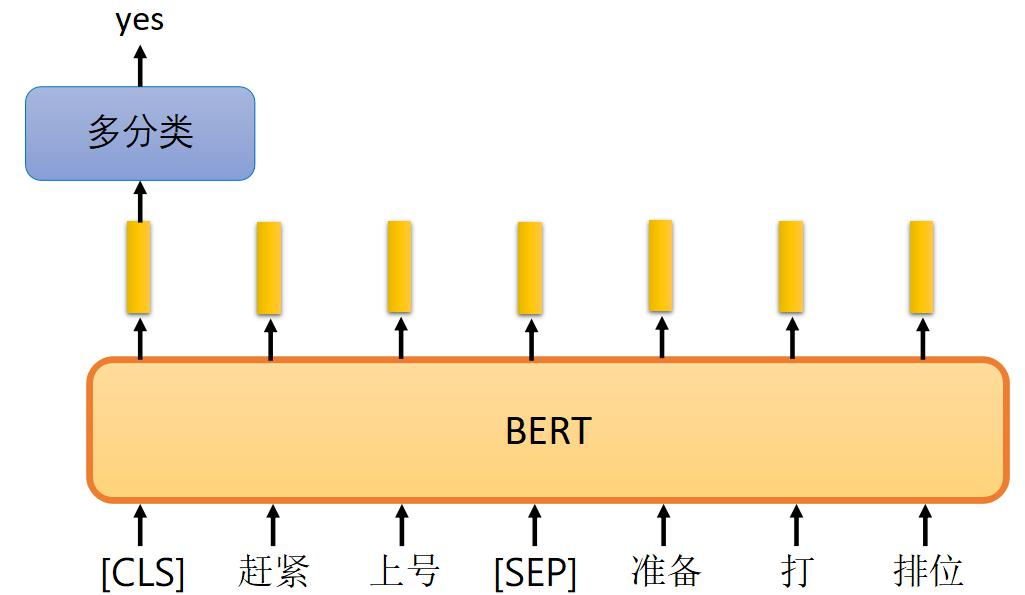
- 例如,句子对“赵紧上号准备打排位”和“老师马上点名”会被处理成“[CLS] 赵紧上号准备打排位 [SEP] 老师马上点名 [SEP]”。
-
预测句子连贯性:
- 模型需要预测两个句子是否应该连在一起。
- 图中展示了BERT如何处理句子对,通过多分类层输出预测结果,是或否。
-
目标:
- 通过预测句子对的连贯性,模型能够学习到句子级别的上下文关系,增强对文本的理解能力。
2.ALBERT
论文地址:https://arxiv.org/abs/1909.11942v1
(1)解决的问题
在自然语言处理(NLP)领域,BERT(Bidirectional Encoder Representations from Transformers)模型的出现标志着预训练技术的革命,极大地推动了该领域的发展。BERT凭借其强大的语言理解能力,在多项任务中取得了前所未有的成绩,确立了“模型越大,效果越好”的普遍认知。然而,这一规律伴随着显著的挑战:大规模模型意味着庞大的权重参数量,不仅对硬件资源,尤其是显存,提出了极高的要求,还导致训练过程异常缓慢,有时甚至需要数月之久,这对于快速迭代和实际应用构成了巨大障碍。
为了解决上述难题,研究者们开始探索如何在不牺牲过多性能的前提下,打造更为轻量级的BERT模型,即A Lite BERT。这类模型旨在通过优化结构和算法,减少模型的复杂度和参数量,同时保持其强大的表达能力。一个关键的观察是,BERT模型中的Transformer架构中,Embedding层约占总参数的20%,而Attention机制则占据了剩余的80%。这意味着,通过精简或优化这些部分,可以有效减小模型体积。
ALBERT(A Lite BERT)正是在此背景下应运而生的一个代表。它通过参数共享、跨层权重绑定等技巧大幅减少了模型的参数量,同时保持了竞争力的表现。例如,与原始BERT相比,ALBERT在保持相似性能的同时,显著降低了对计算资源的需求,加快了训练速度,使得模型能够在更短的时间内完成训练,降低了部署门槛,使得更多研究者和开发者能够受益。
此外,随着技术的进步,如优化器的创新、并行计算技术的发展以及分布式训练策略的优化,即使是大型模型的训练时间也得到了大幅缩减。从过去需要数月的训练周期,到现在某些情况下仅需几分钟,这些进步充分体现了技术革新对于加速NLP模型训练的显著影响。因此,通过不断的模型优化与算法创新,实现更快速、更高效的BERT模型训练已经成为可能,为推动NLP技术的广泛应用奠定了坚实基础。
(2)隐层特征越多,效果一定越好吗?
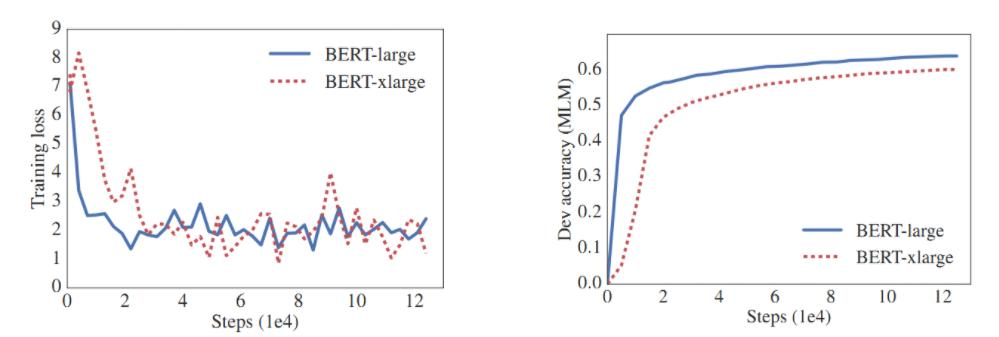
图中展示了BERT-large和BERT-xlarge模型在训练过程中的表现对比。尽管BERT-xlarge的隐藏层特征更多、参数量更大,但其在RACE数据集上的准确率(54.3%)低于BERT-large(73.9%)。这表明,模型效果并不一定随着隐藏层特征的增加而提高,合适的模型规模和结构更为重要。
 (3)重要参数
(3)重要参数
在深入理解自然语言处理(NLP)特别是Transformer模型架构时,几个核心参数扮演着至关重要的角色,分别是E、H和V:
-
E (Embedding Size): 这表示模型在将文本转换为机器可理解的形式时,每个词嵌入向量的维度。换句话说,E定义了词汇表中每个词经过词嵌入层处理后所获得的向量空间的大小。例如,如果E设置为768,那么每个词都将被映射到一个768维的向量中。
-
H (Hidden Layer Size): H是指Transformer模型中隐藏层的维度,特别是在多头自注意力(Multi-Head Attention)和前馈神经网络(Feed Forward Networks, FFNs)等组件处理后输出的向量尺寸。同样地,使用768作为一个常见例子,意味着经过这些层处理后的特征向量也是768维的。这表明,在许多标准Transformer配置中,E和H是相等的,均为768,以此确保模型内部信息传递的一致性和高效性。
-
V (Vocabulary Size): V代表了模型训练所依据的语料库中不同词项的数量。例如,如果我们的字典包含20,000个独特的词或token,则V即为20,000。这个数值直接影响到词嵌入层的初始化和大小,每个词在词嵌入矩阵中都有一个对应的、独一无二的向量表示。
(4)嵌入向量参数化的因式分解
在自然语言处理(NLP)领域,尤其是在设计高效的Transformer模型时,面对巨大的参数量挑战,研究者们探索了一种创新策略——嵌入向量参数化的因式分解。这种方法巧妙地通过引入一个中介层,将原本单层高维度的嵌入表示分解为两个低维度的步骤,从而在不严重牺牲模型性能的前提下,大幅度减少所需的参数数量。
具体来说,传统的Transformer模型中,嵌入层直接将词汇表(V)中的每个词映射到一个高维空间(H),导致参数量为V×H。而采用因式分解技术后,这一过程被重构为先通过一个较低维度的嵌入(E)表示每个词,随后再将此低维表示映射至最终的高维空间(H)。这样一来,参数总量从V×H减少到了V×E+E×H。当目标是构建轻量化模型且H远大于E时,这种方法尤其有效,能够在保持模型相对性能的同时,显著减轻硬件负担,加快训练和推理速度。
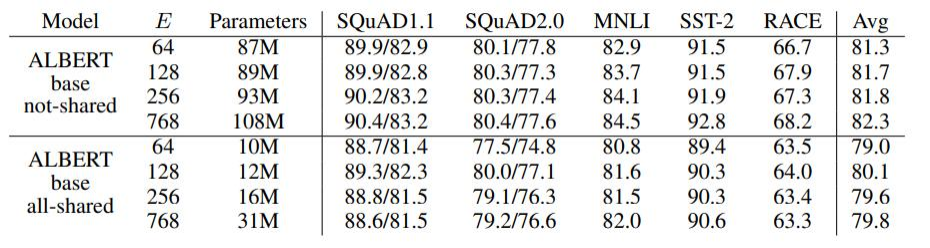
上图中展示了嵌入向量参数化对模型性能的影响。结果表明,嵌入向量维度 𝐸的变化对性能有一定影响,但并不显著。在所有参数共享的情况下,尽管参数量减少,模型的平均性能仅略微下降,这表明模型在保持较少参数量的情况下仍能保持较好的性能。
(5)跨层参数共享
参数共享的方法有很多,ALBERT选择了全部共享,FFN和ATTENTION的都共享。
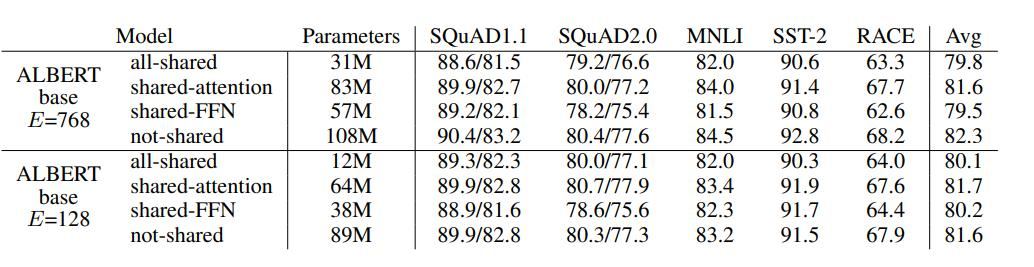
结果显示,全部共享(all-shared)的方法在减少参数数量的同时,依然保持了较高的性能。例如,对于嵌入维度为768的ALBERT模型,全部共享方法的平均性能(Avg)为79.8,而未共享的性能为82.3。尽管未共享的方法性能稍高,但参数量显著增加(108M vs. 31M)。这表明参数共享方法,尤其是全部共享方法,可以在保持模型性能的前提下显著减少参数量。
论文还展示了模型层数和隐藏层特征大小对性能的影响。结果表明,层数和隐藏层特征越多,模型性能越好。例如,层数为24时,模型在多个数据集上的平均性能最高(82.1)。同时,隐藏层特征从1024增加到4096时,模型性能也显著提升。这说明增加层数和隐藏层特征可以有效提高模型性能。


3.Robustly optimized BERT approach
https://arxiv.org/pdf/1907.11692v1
在持续探索提升自然语言处理(NLP)模型训练效率的过程中,优化训练策略尤其是设计更有效的masking机制成为了研究的焦点。传统上,BERT等模型采用静态masking策略,在输入序列中随机掩盖部分词汇,促使模型学习预测这些缺失部分,以此增强语言理解能力。然而,这种方法存在局限性,其生成的mask模式固定且与真实应用场景可能存在偏差。
近期的研究工作则聚焦于动态masking技术,这正是某篇论文探讨的核心创新点。与静态masking相比,动态masking在每次训练迭代时依据特定策略灵活调整掩盖模式,旨在模拟更加多样和贴近实际的语言情境。这一变化直觉上看似简单,实则蕴含深刻:通过引入动态性,模型被鼓励学习更广泛和复杂的上下文依赖,从而可能在语言建模能力上实现更显著的提升。
此外,该研究还揭示了一个有趣的发现:取消BERT原始训练目标之一的**Next Sentence Prediction (NSP)**任务,即判断两个句子是否连续,竟然能带来意想不到的效果提升。NSP任务本意是为了增强模型对句子间关系的理解,但在实际操作中,它的贡献似乎不如预期,并可能引入不必要的复杂性。移除NSP后,模型能够更加专注于核心的语言建模任务,这不仅简化了训练流程,还可能促进了模型性能的优化。
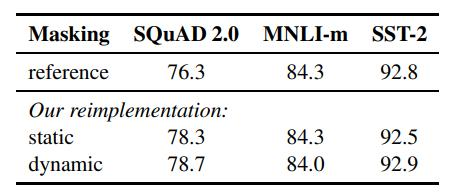
(1)优化点
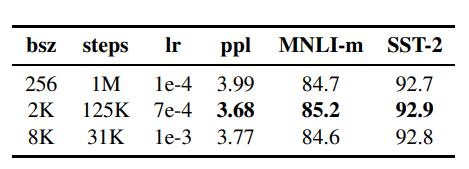
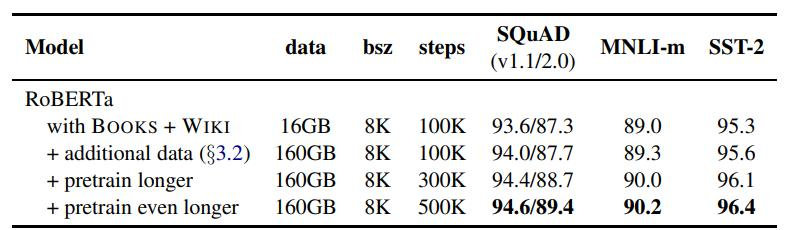
首先,增加BatchSize(批处理大小)被认为是提高模型性能的有效方法。其次,使用更多的数据集并延长训练时间也能提升效果。最后,对分词方式进行改进,使英文拆分更细致,从而提高模型在SQuAD、MNLI和SST-2数据集上的性能。总的来看,这些优化措施显著增强了模型的表现。
(2) RoBERTa-wwm
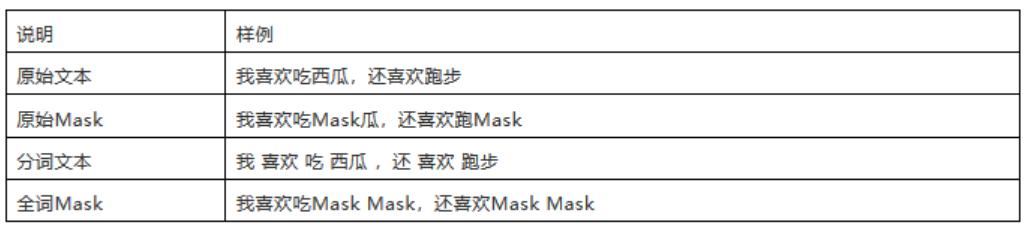
RoBERTa-wwm是一种针对中文场景优化的预训练语言模型,其中的"wwm"代表"whole word mask",即全词掩码策略。这一策略特别关键,因为它考虑到了中文词语不像英语那样由空格分隔的特点,往往一个词汇由多个字符组成。在预训练过程中,全词掩码会将整个词汇作为一个单位进行掩盖,而非单独遮蔽单个字符,这样能更准确地保留和学习中文词汇的完整性及上下文语境,对于提升模型在中文自然语言处理任务上的性能至关重要。因此,对于面向中文场景的训练任务,采用如RoBERTa-wwm这样的全词掩码模型是极为重要的优化措施。
4.A distilled version of BERT: smaller,faster, cheaper and lighter
2019年,自然语言处理(NLP)领域见证了模型规模不断膨胀的趋势,学界普遍认同“越大越强”的理念,认为通过增加模型容量可以获得更优的性能表现,体现了一种“大力出奇迹”的学术探索精神。然而,在实际应用层面,这引发了对计算资源、存储需求以及能源消耗的深切关注。工程实践迫切需要找到平衡点:如何在保持模型相对小巧的同时,确保其具备强大的语言处理能力。
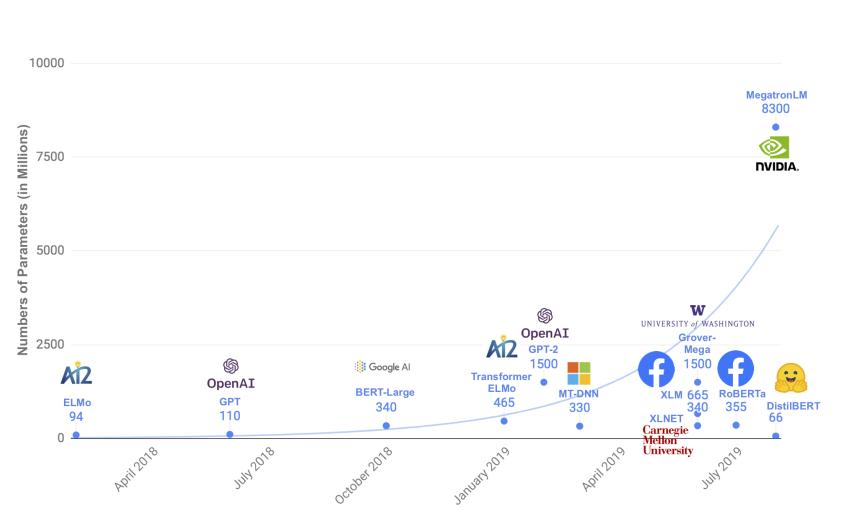
DistilBERT是BERT的一个蒸馏版本,具有更小的模型尺寸、更快的推理速度和更低的成本。
-
参数减少:
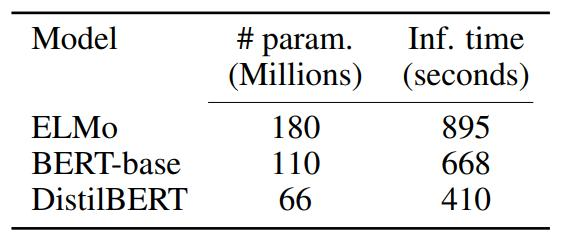
- DistilBERT的参数数量减少了大约40%,主要是为了提高预测速度。
- 具体参数数量对比:
- ELMo:180百万参数,推理时间895秒。
- BERT-base:110百万参数,推理时间668秒。
- DistilBERT:66百万参数,推理时间410秒。
-
性能保留:
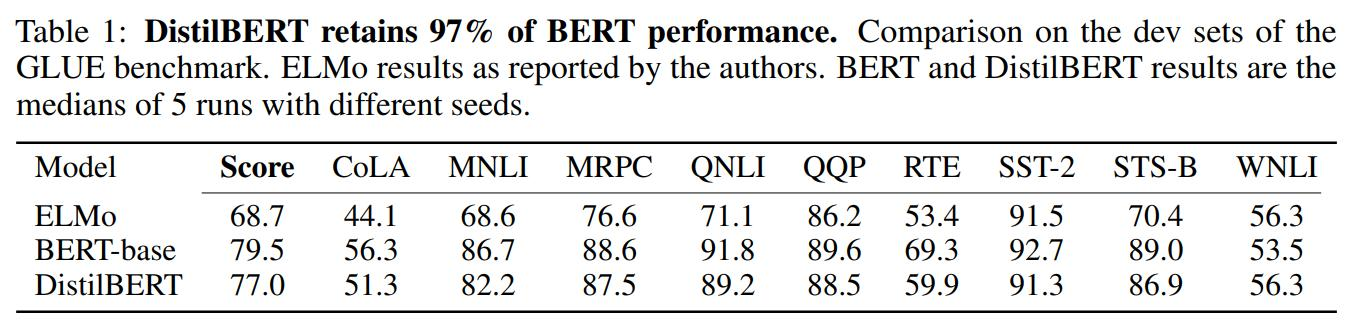
- 尽管DistilBERT进行了大幅度的模型精简,它仍能保留97%的BERT性能。
- 在GLUE基准测试中的表现(表1所示):
- 总体得分:DistilBERT为77.0,BERT-base为79.5。
- 各子任务得分接近,如MNLI、MRPC、QNLI等任务上DistilBERT表现均较好。