文章目录
- 1 数据集描述
- 2 GPU设置
- 3 设置Dataset类
- 4 设置辨别器类
- 5 辅助函数与辅助类
1 数据集描述
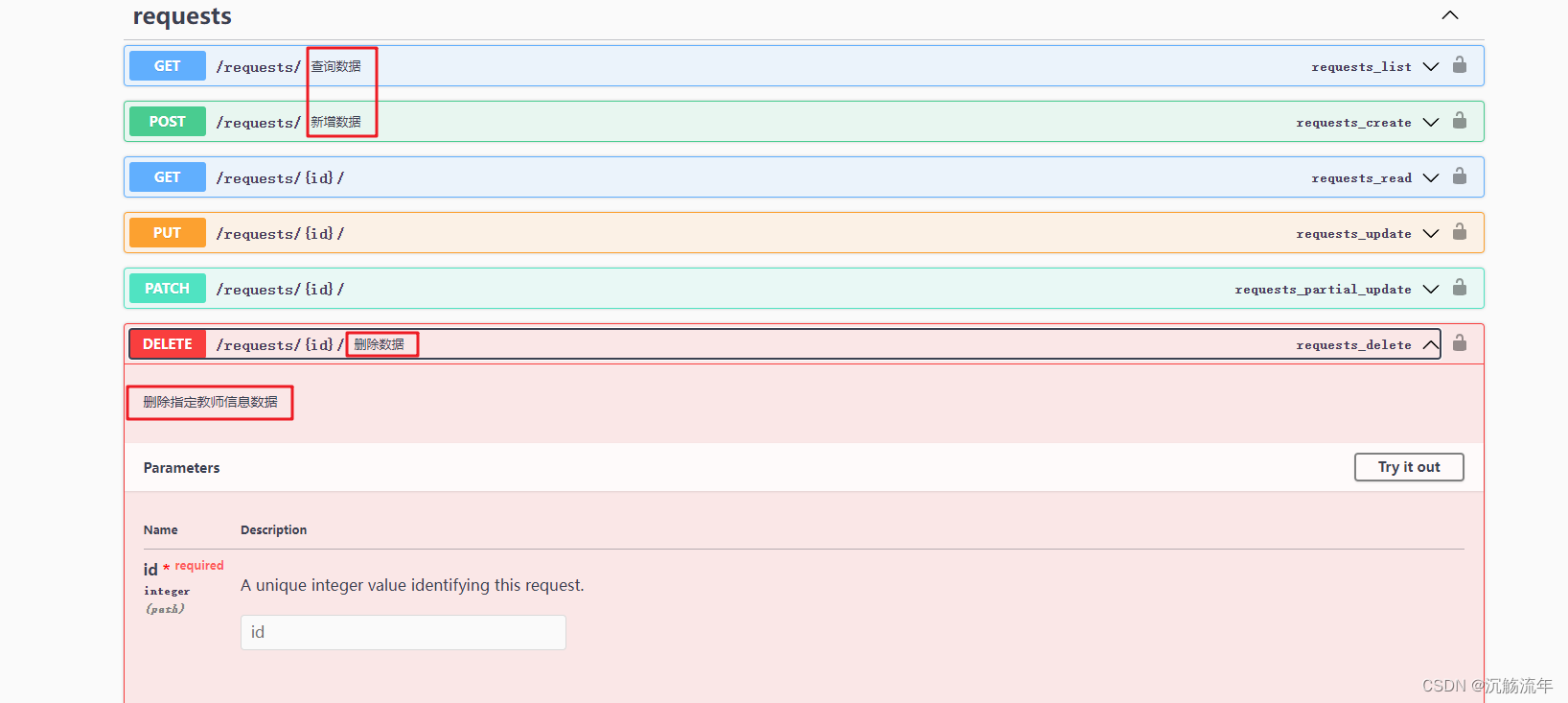
此项目使用的是著名的celebA(CelebFaces Attribute)数据集。其包含10,177个名人身份的202,599张人脸图片,每张图片都做好了特征标记,包含人脸bbox标注框、5个人脸特征点坐标以及40个属性标记,数据由香港中文大学开放提供(不包含商业用途的使用)。
在实际训练前,已经将数据处理成了HDF5的数据集格式。使用h5py处理HDF5数据集可以提供很多方便,使得数据处理更加高效、灵活、可扩展,显著提升训练过程的文件读取速度。可以使用h5py包自行对数据进行处理,也可直接下载我已经处理好的HDF5数据格式。
如需了解更多h5py相关知识,可以查看HDF5补充知识。
2 GPU设置
前面几篇博客的内容,都是对手写数字这个数据集的处理,CPU还能吃得消。这次数据输入明显增加,需要使用GPU处理数据。如电脑无NAVIDIA独显,建议使用Google Colab执行代码,Colab提供了免费的GPU算力。
if torch.cuda.is_available():
torch.set_default_tensor_type(torch.cuda.FloatTensor)
print("using cuda:", torch.cuda.get_device_name(0))
pass
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
这段代码的作用是,如果当前设备有可用的CUDA,则将默认的张量类型设置为CUDA浮点张量并输出使用的CUDA设备的名称。然后,它将设备设置为CUDA设备(如果有)或CPU。
3 设置Dataset类
基于面向对象编程的基本原则,我们建立一个Dataset类,使类具有数据读取、获取指定索引的数据与绘制指定索引的图像,具体代码如下:
class CelebADataset(Dataset):
def __init__(self, file):
self.file_object = h5py.File(file, 'r')
self.dataset = self.file_object['img_align_celeba']
pass
def __len__(self):
return len(self.dataset)
def __getitem__(self, index):
if index >= len(self.dataset):
raise IndexError()
img = numpy.array(self.dataset[str(index) + '.jpg'])
return torch.cuda.FloatTensor(img) / 255.0
def plot_image(self, index):
plt.imshow(numpy.array(self.dataset[str(index) + '.jpg']), interpolation='nearest')
plt.show()
在获取指定索引对应的数据时,如果指定数大于索引的最大值,我们命令程序返回一个IndexError()错误,以便于快速查找问题所在。
为了理解这一数据类,我们对类进行使用:
celeba_dataset = CelebADataset('文件地址.h5py')
这里创建了一个名为celeba_dataset 的CelebADataset类,并传入了文件的所在路径file。在__init__中,使用h5py.File方法读取路经所在的文件。
celeba_dataset.plot_image(66)
绘制数据集中66.jpg图形。如果前面代码正确,此处将绘制出数据集中的人脸头像。如果为绘制出图形并产生报错,考虑路径是否有误以及数据格式是否正确。

4 设置辨别器类
本项目的核心类为鉴别器类与生成器类,下面开始编写鉴别器类。首先建立神经网络框架:
class Discriminator(nn.Module):
def __init__(self):
# 父类继承
super().__init__()
# 神经网络定义
self.model = nn.Sequential(
View(218 * 178 * 3),
nn.Linear(3 * 218 * 178, 100),
nn.LeakyReLU(),
nn.LayerNorm(100),
nn.Linear(100, 1),
nn.Sigmoid()
)
# 创建损失函数
self.loss_function = nn.BCELoss()
# 创建优化器
self.optimiser = torch.optim.Adam(self.parameters(), lr=0.0001)
# 初始化计数器
self.counter = 0
self.progress = []
这段代码定义了一个名为Discriminator的类,继承了PyTorch中nn.Module类。在__init__函数中,通过nn.Sequential定义了一个神经网络模型,包括三个线性层,两个激活函数,一个归一化层。一开始的View(218*178*3)是新代码。它的作用是将大小为(218, 178, 3) 的三维图像张量重塑成一个长度为218×178×3的一维张量。基于自上而下的编程习惯,我们会在后面对View进行定义。
在此基础上,定义了损失函数nn.BCELoss()和优化器Adam,并定义了一个计数器和一个存储进度的列表。
class Discriminator(nn.Module):
def forward(self, inputs):
# simply run model
return self.model(inputs)
def train(self, inputs, targets):
# calculate the output of the network
outputs = self.forward(inputs)
# calculate loss
loss = self.loss_function(outputs, targets)
# increase counter and accumulate error every 10
self.counter += 1
if (self.counter % 10 == 0):
self.progress.append(loss.item())
if (self.counter % 1000 == 0):
print("counter = ", self.counter)
# 梯度归零,向后传递,优化执行
self.optimiser.zero_grad()
loss.backward()
self.optimiser.step()
def plot_progress(self):
df = pandas.DataFrame(self.progress, columns=['loss'])
df.plot(ylim=(0), figsize=(16, 8), alpha=0.1, marker='.', grid=True, yticks=(0, 0.25, 0.5, 1.0, 5.0))
接下来定义forward功能,train功能,plot_progress功能。在forward()函数中,它只是让模型对输入数据进行前向传播并返回网络的输出。在train()函数中,它使用输入数据和目标数据来计算网络的损失,并使用优化器来更新网络的参数。最后,plot_progress()函数可以用来绘制训练进度。以上类方法与手写字体识别博文中的定义完全相同,如有需要可找到对应博文查看。
5 辅助函数与辅助类
class View(nn.Module):
def __init__(self, shape):
super().__init__()
self.shape = shape, # 逗号不是多打的
def forward(self, x):
return x.view(*self.shape)
在前面定义鉴别器类时,我们已经使用了View,此处对View进行补充定义。在 forward 方法中,它对输入的 x 应用了 view 方法,并将 shape 属性作为参数传入。这个模型的作用是将输入的张量的形状调整为 shape 属性所指定的形状。
def generate_random_image(size):
random_data = torch.rand(size)
return random_data
def generate_random_seed(size):
random_data = torch.randn(size)
return random_data
以上两个随机张量生成器,其作用与手写数字识别中的作用完全相同,在此不再赘述。后续在使用时也会再进行介绍。
截至目前,我们已经建立好了模型所必需的鉴别器类与Dataset类。下一篇会讲解最重要的鉴别器类以及对模型的训练与使用。