目录
- 1、聚合函数
- 1.1、SQL 类别高难度试卷得分的截断平均值(较难)
- 1.2、统计作答次数
- 1.3、得分不小于平均分的最低分
- 2、分组查询
- 2.1、平均活跃天数和月活人数
- 2.2、月总刷题数和日均刷题数
- 2.3、未完成试卷数大于 1 的有效用户(较难)
- 3、嵌套子查询
- 3.1、月均完成试卷数不小于 3 的用户爱作答的类别(较难)
- 3.2、试卷发布当天作答人数和平均分
- 3.3、作答试卷得分大于过 80 的人的用户等级分布
- 4、合并查询
- 4.1、每个题目和每份试卷被作答的人数和次数
- 4.2、分别满足两个活动的人
- 5、连接查询
- 5.1、满足条件的用户的试卷完成数和题目练习数(困难)
- 5.2、每个 6/7 级用户活跃情况(困难)
1、聚合函数
1.1、SQL 类别高难度试卷得分的截断平均值(较难)
描述:要查看大家在 SQL 类别中高难度试卷的得分情况。
请从exam_record数据表中计算所有用户完成 SQL 类别高难度试卷得分的截断平均值(去掉一个最大值和一个最小值后的平均值)。
示例数据:examination_info(exam_id 试卷 ID, tag 试卷类别, difficulty 试卷难度, duration 考试时长, release_time 发布时间)
| id | exam_id | tag | difficulty | duration | release_time |
|---|---|---|---|---|---|
| 1 | 9001 | SQL | hard | 60 | 2020-01-01 |
| 2 | 9002 | 算法 | medium | 80 | 2020-08-02 |
示例数据:exam_record(uid 用户 ID, exam_id 试卷 ID, start_time 开始作答时间, submit_time 交卷时间, score 得分)
| id | uid | exam_id | start_time | submit_time | score |
|---|---|---|---|---|---|
| 1 | 1001 | 9001 | 2020-01-02 09:01:01 | 2020-01-02 09:21:01 | 80 |
| 2 | 1001 | 9001 | 2021-05-02 10:01:01 | 2021-05-02 10:30:01 | 81 |
| 3 | 1001 | 9001 | 2021-06-02 19:01:01 | 2021-06-02 19:31:01 | 84 |
| 4 | 1001 | 9002 | 2021-09-05 19:01:01 | 2021-09-05 19:40:01 | 89 |
| 5 | 1001 | 9001 | 2021-09-02 12:01:01 | (NULL) | (NULL) |
| 6 | 1001 | 9002 | 2021-09-01 12:01:01 | (NULL) | (NULL) |
| 7 | 1002 | 9002 | 2021-02-02 19:01:01 | 2021-02-02 19:30:01 | 87 |
| 8 | 1002 | 9001 | 2021-05-05 18:01:01 | 2021-05-05 18:59:02 | 90 |
| 9 | 1003 | 9001 | 2021-09-07 12:01:01 | 2021-09-07 10:31:01 | 50 |
| 10 | 1004 | 9001 | 2021-09-06 10:01:01 | (NULL) | (NULL) |
根据输入你的查询结果如下:
| tag | difficulty | clip_avg_score |
|---|---|---|
| SQL | hard | 81.7 |
从examination_info表可知,试卷 9001 为高难度 SQL 试卷,该试卷被作答的得分有[80,81,84,90,50],去除最高分和最低分后为[80,81,84],平均分为 81.6666667,保留一位小数后为 81.7
输入描述:
输入数据中至少有 3 个有效分数
思路一: 要找出高难度 sql 试卷,肯定需要联 examination_info 这张表,然后找出高难度的课程,由 examination_info 得知,高难度 sql 的 exam_id 为 9001,那么等下就以 exam_id = 9001 作为条件去查询;
先找出 9001 号考试 select * from exam_record where exam_id = 9001
然后,找出最高分 select max(score) 最高分 from exam_record where exam_id = 9001
接着,找出最低分 select min(score) 最低分 from exam_record where exam_id = 9001
在查询出来的分数结果集当中,去掉最高分和最低分,最直观能想到的就是 NOT IN 或者 用 NOT EXISTS 也行,这里以 NOT IN 来做
首先将主体写出来select tag, difficulty, round(avg(score), 1) clip_avg_score from examination_info info INNER JOIN exam_record record
小 tips : MYSQL 的 ROUND() 函数 ,ROUND(X)返回参数 X 最近似的整数 ROUND(X,D)返回 X ,其值保留到小数点后 D 位,第 D 位的保留方式为四舍五入。
再将上面的 “碎片” 语句拼凑起来即可, 注意在 NOT IN 中两个子查询用 UNION ALL 来关联,用 union 把 max 和 min 的结果集中在一行当中,这样形成一列多行的效果。
答案一:
SELECT tag,difficulty,ROUND(AVG(score),1) clip_avg_score
FROM examination_info info INNER JOIN exam_record record
WHERE info.exam_id = record.exam_id
AND record.exam_id = 9001
AND record.score NOT IN (SELECT MAX(score)
FROM exam_record
WHERE exam_id = 9001
UNION ALL
SELECT MIN(score)
FROM exam_record
WHERE exam_id = 9001)
这是最直观,也是最容易想到的解法,但是还有待改进,这算是投机取巧过关,其实严格按照题目要求应该这么写:
SELECT info.tag, info.difficulty,ROUND(AVG(score),1) clip_avg_score
FROM examination_info info
INNER JOIN exam_record record
WHERE info.exam_id = record.exam_id
AND record.exam_id =
(SELECT examination_info.exam_id
FROM examination_info
WHERE tag = 'SQL'
AND difficulty = 'hard')
AND record.score NOT IN (
SELECT MAX(score)
FROM exam_record
WHERE exam_id =
(SELECT examination_info.exam_id
FROM examination_info
WHERE tag = 'SQL'
AND difficulty = 'hard')
UNION ALL
SELECT MIN(score)
FROM exam_record
WHERE exam_id =
(SELECT examination_info.exam_id
FROM examination_info
WHERE tag = 'SQL'
AND difficulty = 'hard'))
GROUP BY info.tag, info.difficulty;
然而你会发现,重复的语句非常多,所以可以利用WITH来抽取公共部分
WITH 子句介绍:
WITH 子句,也称为公共表表达式(Common Table Expression,CTE),是在 SQL 查询中定义临时表的方式。它可以让我们在查询中创建一个临时命名的结果集,并且可以在同一查询中引用该结果集。
基本用法:
WITH cte_name (column1, column2, ..., columnN) AS (
-- 查询体
SELECT ...
FROM ...
WHERE ...
)
-- 主查询
SELECT ...
FROM cte_name
WHERE ...
WITH 子句由以下几个部分组成:
cte_name: 给临时表起一个名称,可以在主查询中引用。(column1, column2, ..., columnN): 可选,指定临时表的列名。AS: 必需,表示开始定义临时表。CTE查询体: 实际的查询语句,用于定义临时表中的数据。
WITH 子句的主要用途之一是增强查询的可读性和可维护性,尤其在涉及多个嵌套子查询或需要重复使用相同的查询逻辑时。通过将这些逻辑放在一个命名的临时表中,我们可以更清晰地组织查询,并消除重复代码。
此外,WITH 子句还可以在复杂的查询中实现递归查询。递归查询允许我们在单个查询中执行对同一表的多次迭代,逐步构建结果集。这在处理层次结构数据、组织结构和树状结构等场景中非常有用。
小细节:MySQL 5.7 版本以及之前的版本不支持在 WITH 子句中直接使用别名。
下面是改进后的答案:
WITH t1 AS (
SELECT record.*,
info.tag,
info.difficulty
FROM exam_record record
INNER JOIN examination_info info ON record.exam_id = info.exam_id
WHERE info.tag = 'SQL'
AND info.difficulty = 'hard'
)
SELECT tag,
difficulty,
ROUND(AVG(score), 1) AS clip_avg_score
FROM t1
WHERE score NOT IN (
SELECT MAX(score)
FROM t1
UNION ALL
SELECT MIN(score)
FROM t1
)
GROUP BY tag, difficulty;
思路二:
- 筛选 SQL 高难度试卷:
where tag="SQL" and difficulty="hard" - 计算截断平均值:(和-最大值-最小值) / (总个数-2):
(sum(score) - max(score) - min(score)) / (count(score) - 2)- 有一个缺点就是,如果最大值和最小值有多个,这个方法就很难筛选出来, 但是题目中说了----->去掉一个最大值和一个最小值后的平均值, 所以这里可以用这个公式。
答案二:
SELECT info.tag,
info.difficulty,
ROUND((SUM(record.score)-MIN(record.score)-MAX(record.score))/(COUNT(record.score)-2),1) AS clip_avg_score
FROM examination_info info,
exam_record record
WHERE info.exam_id = record.exam_id
AND info.tag = 'SQL'
AND info.difficulty = 'hard';
1.2、统计作答次数
有一个试卷作答记录表 exam_record,请从中统计出总作答次数 total_pv、试卷已完成作答数 complete_pv、已完成的试卷数 complete_exam_cnt。
示例数据 exam_record 表(uid 用户 ID, exam_id 试卷 ID, start_time 开始作答时间, submit_time 交卷时间, score 得分):
| id | uid | exam_id | start_time | submit_time | score |
|---|---|---|---|---|---|
| 1 | 1001 | 9001 | 2020-01-02 09:01:01 | 2020-01-02 09:21:01 | 80 |
| 2 | 1001 | 9001 | 2021-05-02 10:01:01 | 2021-05-02 10:30:01 | 81 |
| 3 | 1001 | 9001 | 2021-06-02 19:01:01 | 2021-06-02 19:31:01 | 84 |
| 4 | 1001 | 9002 | 2021-09-05 19:01:01 | 2021-09-05 19:40:01 | 89 |
| 5 | 1001 | 9001 | 2021-09-02 12:01:01 | (NULL) | (NULL) |
| 6 | 1001 | 9002 | 2021-09-01 12:01:01 | (NULL) | (NULL) |
| 7 | 1002 | 9002 | 2021-02-02 19:01:01 | 2021-02-02 19:30:01 | 87 |
| 8 | 1002 | 9001 | 2021-05-05 18:01:01 | 2021-05-05 18:59:02 | 90 |
| 9 | 1003 | 9001 | 2021-09-07 12:01:01 | 2021-09-07 10:31:01 | 50 |
| 10 | 1004 | 9001 | 2021-09-06 10:01:01 | (NULL) | (NULL) |
示例输出:
| total_pv | complete_pv | complete_exam_cnt |
|---|---|---|
| 10 | 7 | 2 |
解释:表示截止当前,有 11 次试卷作答记录,已完成的作答次数为 7 次(中途退出的为未完成状态,其交卷时间和份数为 NULL),已完成的试卷有 9001 和 9002 两份。
思路: 这题一看到统计次数,肯定第一时间就要想到用COUNT这个函数来解决,问题是要统计不同的记录,该怎么来写?使用子查询就能解决这个题目(这题用 case when 也能写出来,解法类似,逻辑不同而已);首先在做这个题之前,让我们先来了解一下COUNT的基本用法;
COUNT() 函数的基本语法如下所示:
COUNT(expression)
其中,expression 可以是列名、表达式、常量或通配符。下面是一些常见的用法示例:
- 计算表中所有行的数量:
SELECT COUNT(*) FROM table_name;
- 计算特定列非空(不为 NULL)值的数量:
SELECT COUNT(column_name) FROM table_name;
- 计算满足条件的行数:
SELECT COUNT(*) FROM table_name WHERE condition;
- 结合
GROUP BY使用,计算分组后每个组的行数:
SELECT column_name, COUNT(*) FROM table_name GROUP BY column_name;
- 计算不同列组合的唯一组合数:
SELECT COUNT(DISTINCT column_name1, column_name2) FROM table_name;
在使用COUNT()函数时,如果不指定任何参数或者使用 COUNT(*),将会计算所有行的数量。而如果使用列名,则只会计算该列非空值的数量。
另外,COUNT() 函数的结果是一个整数值。即使结果是零,也不会返回 NULL,这点需要谨记。
答案:
SELECT
COUNT(*) total_pv,
(SELECT COUNT(*) FROM exam_record WHERE submit_time IS NOT NULL) complete_pv,
(SELECT COUNT(DISTINCT exam_id, score IS NOT NULL OR NULL) FROM exam_record) complete_exam_cnt
FROM exam_record
这里着重说一下COUNT( DISTINCT exam_id, score IS NOT NULL OR NULL )这一句,判断 score 是否为 null ,如果是即为真,如果不是返回 null;注意这里如果不加 or null 在不是 null 的情况下只会返回 false 也就是返回 0;
COUNT本身是不可以对多列求行数的,distinct的加入是的多列成为一个整体,可以求出现的行数了;count distinct在计算时只返回非 null 的行, 这个也要注意;
另外通过本题 get 到了------>count 加条件常用句式count( 列判断 or null)
1.3、得分不小于平均分的最低分
描述: 请从试卷作答记录表中找到 SQL 试卷得分不小于该类试卷平均得分的用户最低得分。
示例数据 exam_record 表(uid 用户 ID, exam_id 试卷 ID, start_time 开始作答时间, submit_time 交卷时间, score 得分):
| id | uid | exam_id | start_time | submit_time | score |
|---|---|---|---|---|---|
| 1 | 1001 | 9001 | 2020-01-02 09:01:01 | 2020-01-02 09:21:01 | 80 |
| 2 | 1002 | 9001 | 2021-09-05 19:01:01 | 2021-09-05 19:40:01 | 89 |
| 3 | 1002 | 9002 | 2021-09-02 12:01:01 | (NULL) | (NULL) |
| 4 | 1002 | 9003 | 2021-09-01 12:01:01 | (NULL) | (NULL) |
| 5 | 1002 | 9001 | 2021-02-02 19:01:01 | 2021-02-02 19:30:01 | 87 |
| 6 | 1002 | 9002 | 2021-05-05 18:01:01 | 2021-05-05 18:59:02 | 90 |
| 7 | 1003 | 9002 | 2021-02-06 12:01:01 | (NULL) | (NULL) |
| 8 | 1003 | 9003 | 2021-09-07 10:01:01 | 2021-09-07 10:31:01 | 86 |
| 9 | 1004 | 9003 | 2021-09-06 12:01:01 | (NULL) | (NULL) |
examination_info 表(exam_id 试卷 ID, tag 试卷类别, difficulty 试卷难度, duration 考试时长, release_time 发布时间)
| id | exam_id | tag | difficulty | duration | release_time |
|---|---|---|---|---|---|
| 1 | 9001 | SQL | hard | 60 | 2020-01-01 |
| 2 | 9002 | SQL | easy | 60 | 2020-02-01 |
| 3 | 9003 | 算法 | medium | 80 | 2020-08-02 |
示例输出数据:
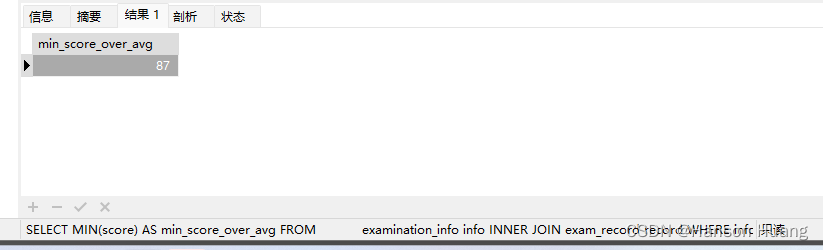
| min_score_over_avg |
|---|
| 87 |
解释:试卷 9001 和 9002 为 SQL 类别,作答这两份试卷的得分有[80,89,87,90],平均分为 86.5,不小于平均分的最小分数为 87
思路:这类题目第一眼看确实很复杂, 因为不知道从哪入手,但是当我们仔细读题审题后,要学会抓住题干中的关键信息。以本题为例:请从试卷作答记录表中找到SQL试卷得分不小于该类试卷平均得分的用户最低得分。你能一眼从中提取哪些有效信息来作为解题思路?
第一条:找到SQL试卷得分
第二条:该类试卷平均得分
第三条:该类试卷的用户最低得分
然后中间的 “桥梁” 就是不小于
将条件拆分后,先逐步完成
-- 找出tag为‘SQL’的得分 【80, 89,87,90】
SELECT record.score
FROM exam_record record,examination_info info
WHERE record.exam_id = info.exam_id AND info.tag = 'SQL' AND record.score IS NOT NULL
-- 再算出这一组的平均得分
SELECT ROUND(AVG(score),1)
FROM examination_info info
INNER JOIN exam_record record
WHERE info.exam_id = record.exam_id
AND tag= 'SQL'
然后再找出该类试卷的最低得分,接着将结果集【80, 89,87,90】 去和平均分数作比较,方可得出最终答案。
答案:
SELECT MIN(score) AS min_score_over_avg
FROM examination_info info
INNER JOIN exam_record record
WHERE info.exam_id = record.exam_id
AND info.tag = 'SQL'
AND score > (
SELECT ROUND(AVG(score),1) from examination_info info INNER JOIN exam_record record
where info.exam_id = record.exam_id
and tag= 'SQL'
)
其实这类题目给出的要求看似很 “绕”,但其实仔细梳理一遍,将大条件拆分成小条件,逐个拆分完以后,最后将所有条件拼凑起来。反正只要记住:抓主干,理分支,问题便迎刃而解。
2、分组查询
2.1、平均活跃天数和月活人数
描述:用户在试卷作答区作答记录存储在表exam_record中,内容如下:
exam_record 表(uid 用户 ID, exam_id 试卷 ID, start_time 开始作答时间, submit_time 交卷时间,score 得分)
| id | uid | exam_id | start_time | submit_time | score |
|---|---|---|---|---|---|
| 1 | 1001 | 9001 | 2021-07-02 09:01:01 | 2021-07-02 09:21:01 | 80 |
| 2 | 1002 | 9001 | 2021-09-05 19:01:01 | 2021-09-05 19:40:01 | 81 |
| 3 | 1002 | 9002 | 2021-09-02 12:01:01 | (NULL) | (NULL) |
| 4 | 1002 | 9003 | 2021-09-01 12:01:01 | (NULL) | (NULL) |
| 5 | 1002 | 9001 | 2021-07-02 19:01:01 | 2021-07-02 19:30:01 | 82 |
| 6 | 1002 | 9002 | 2021-07-05 18:01:01 | 2021-07-05 18:59:02 | 90 |
| 7 | 1003 | 9002 | 2021-07-06 12:01:01 | (NULL) | (NULL) |
| 8 | 1003 | 9003 | 2021-09-07 10:01:01 | 2021-09-07 10:31:01 | 86 |
| 9 | 1004 | 9003 | 2021-09-06 12:01:01 | (NULL) | (NULL) |
| 10 | 1002 | 9003 | 2021-09-01 12:01:01 | 2021-09-01 12:31:01 | 81 |
| 11 | 1005 | 9001 | 2021-09-01 12:01:01 | 2021-09-01 12:31:01 | 88 |
| 12 | 1006 | 9002 | 2021-09-02 12:11:01 | 2021-09-02 12:31:01 | 89 |
| 13 | 1007 | 9002 | 2020-09-02 12:11:01 | 2020-09-02 12:31:01 | 89 |
请计算 2021 年每个月里试卷作答区用户平均月活跃天数 avg_active_days 和月度活跃人数 mau,上面数据的示例输出如下:
| month | avg_active_days | mau |
|---|---|---|
| 202107 | 1.50 | 2 |
| 202109 | 1.25 | 4 |
解释:2021 年 7 月有 2 人活跃,共活跃了 3 天(1001 活跃 1 天,1002 活跃 2 天),平均活跃天数 1.5;2021 年 9 月有 4 人活跃,共活跃了 5 天,平均活跃天数 1.25,结果保留 2 位小数。
注:此处活跃指有交卷行为。
思路:读完题先注意高亮部分;一般求天数和月活跃人数马上就要想到相关的日期函数;这一题我们同样来进行拆分,把问题细化再解决;首先求活跃人数,肯定要用到COUNT(),那这里首先就有一个坑,不知道大家注意了没有?用户 1002 在 9 月份做了两种不同的试卷,所以这里要注意去重,不然在统计的时候,活跃人数是错的;第二个就是要知道日期的格式化,如上表,题目要求以202107这种日期格式展现,要用到DATE_FORMAT来进行格式化。
基本用法:
DATE_FORMAT(date_value, format)
date_value参数是待格式化的日期或时间值。format参数是指定的日期或时间格式(这个和 Java 里面的日期格式一样)。
答案:
SELECT
DATE_FORMAT(submit_time,'%Y%m') month,
COUNT(DISTINCT uid,DATE_FORMAT(submit_time, '%Y%m%d'))/COUNT(DISTINCT UID) avg_active_days,
COUNT(DISTINCT uid) mau
FROM exam_record
WHERE YEAR(submit_time) = '2021'
GROUP BY month

这里多说一句, 使用COUNT(DISTINCT uid, DATE_FORMAT(submit_time, '%Y%m%d') 可以统计在 uid 列和 submit_time 列按照年份、月份和日期进行格式化后的组合值的数量。
2.2、月总刷题数和日均刷题数
描述:现有一张题目练习记录表 practice_record,示例内容如下:
| id | uid | question_id | submit_time | score |
|---|---|---|---|---|
| 1 | 1001 | 8001 | 2021-08-02 11:41:01 | 60 |
| 2 | 1002 | 8001 | 2021-09-02 19:30:01 | 50 |
| 3 | 1002 | 8001 | 2021-09-02 19:20:01 | 70 |
| 4 | 1002 | 8002 | 2021-09-02 19:38:01 | 70 |
| 5 | 1003 | 8002 | 2021-08-01 19:38:01 | 80 |
请从中统计出 2021 年每个月里用户的月总刷题数 month_q_cnt 和日均刷题数 avg_day_q_cnt(按月份升序排序)以及该年的总体情况,示例数据输出如下:
| submit_month | month_q_cnt | avg_day_q_cnt |
|---|---|---|
| 202108 | 2 | 0.065 |
| 202109 | 3 | 0.100 |
| 2021 汇总 | 5 | 0.161 |
解释:2021 年 8 月共有 2 次刷题记录,日均刷题数为 2/31=0.065(保留 3 位小数);2021 年 9 月共有 3 次刷题记录,日均刷题数为 3/30=0.100;2021 年共有 5 次刷题记录(年度汇总平均无实际意义,这里我们按照 31 天来算 5/31=0.161)
如果您采用最新的 Mysql 版本,如果您运行结果出现错误:ONLY_FULL_GROUP_BY,意思是:对于 GROUP BY
聚合操作,如果在 SELECT 中的列,没有在 GROUP BY 中出现,那么这个 SQL 是不合法的,因为列不在 GROUP BY
从句中,也就是说查出来的列必须在 group by 后面出现否则就会报错,或者这个字段出现在聚合函数里面。
思路:
看到实例数据就要马上联想到相关的函数,比如submit_month就要用到DATE_FORMAT来格式化日期。然后查出每月的刷题数量。
每月的刷题数量
SELECT MONTH ( submit_time ), COUNT( question_id )
FROM
practice_record
GROUP BY
MONTH (submit_time)

接着第三列这里要用到DAY(LAST_DAY(date_value))函数来查找给定日期的月份中的天数。
示例代码如下:
SELECT DAY(LAST_DAY('2023-07-08')) AS days_in_month;
-- 输出:31
SELECT DAY(LAST_DAY('2023-02-01')) AS days_in_month;
-- 输出:28 (闰年中的二月份)
SELECT DAY(LAST_DAY(NOW())) AS days_in_current_month;
-- 输出:31 (当前月份的天数)
使用 LAST_DAY() 函数获取给定日期的当月最后一天,然后使用 DAY() 函数提取该日期的天数。这样就能获得指定月份的天数。
需要注意的是,LAST_DAY() 函数返回的是日期值,而 DAY() 函数用于提取日期值中的天数部分。
有了上述的分析之后,即可马上写出答案,这题复杂就复杂在处理日期上,其中的逻辑并不难。
答案:
SELECT DATE_FORMAT(submit_time, '%Y%m') submit_month,
count(question_id) month_q_cnt,
ROUND(COUNT(question_id) / DAY (LAST_DAY(submit_time)), 3) avg_day_q_cnt
FROM practice_record
WHERE DATE_FORMAT(submit_time, '%Y') = '2021'
GROUP BY submit_month
UNION ALL
SELECT '2021汇总' AS submit_month,
count(question_id) month_q_cnt,
ROUND(COUNT(question_id) / 31, 3) avg_day_q_cnt
FROM practice_record
WHERE DATE_FORMAT(submit_time, '%Y') = '2021'
ORDER BY submit_month
在实例数据输出中因为最后一行需要得出汇总数据,所以这里要 UNION ALL加到结果集中;别忘了最后要排序!
2.3、未完成试卷数大于 1 的有效用户(较难)
描述:现有试卷作答记录表 exam_record(uid 用户 ID,exam_id试卷 ID,start_time开始作答时间, submit_time 交卷时间, score 得分),示例数据如下:
| id | uid | exam_id | start_time | submit_time | score |
|---|---|---|---|---|---|
| 1 | 1001 | 9001 | 2021-07-02 09:01:01 | 2021-07-02 09:21:01 | 80 |
| 2 | 1002 | 9001 | 2021-09-05 19:01:01 | 2021-09-05 19:40:01 | 81 |
| 3 | 1002 | 9002 | 2021-09-02 12:01:01 | (NULL) | (NULL) |
| 4 | 1002 | 9003 | 2021-09-01 12:01:01 | (NULL) | (NULL) |
| 5 | 1002 | 9001 | 2021-07-02 19:01:01 | 2021-07-02 19:30:01 | 82 |
| 6 | 1002 | 9002 | 2021-07-05 18:01:01 | 2021-07-05 18:59:02 | 90 |
| 7 | 1003 | 9002 | 2021-07-06 12:01:01 | (NULL) | (NULL) |
| 8 | 1003 | 9003 | 2021-09-07 10:01:01 | 2021-09-07 10:31:01 | 86 |
| 9 | 1004 | 9003 | 2021-09-06 12:01:01 | (NULL) | (NULL) |
| 10 | 1002 | 9003 | 2021-09-01 12:01:01 | 2021-09-01 12:31:01 | 81 |
| 11 | 1005 | 9001 | 2021-09-01 12:01:01 | 2021-09-01 12:31:01 | 88 |
| 12 | 1006 | 9002 | 2021-09-02 12:11:01 | 2021-09-02 12:31:01 | 89 |
| 13 | 1007 | 9002 | 2020-09-02 12:11:01 | 2020-09-02 12:31:01 | 89 |
还有一张试卷信息表examination_info 表(exam_id 试卷 ID, tag 试卷类别, difficulty 试卷难度, duration 考试时长, release_time 发布时间)
示例数据如下:
| id | exam_id | tag | difficulty | duration | release_time |
|---|---|---|---|---|---|
| 1 | 9001 | SQL | hard | 60 | 2020-01-01 |
| 2 | 9002 | SQL | easy | 60 | 2020-02-01 |
| 3 | 9003 | 算法 | medium | 80 | 2020-08-02 |
请统计 2021 年每个未完成试卷作答数大于 1 的有效用户的数据(有效用户指完成试卷作答数至少为 1 且未完成数小于 5),输出用户 ID、未完成试卷作答数、完成试卷作答数、作答过的试卷 tag 集合,按未完成试卷数量由多到少排序。示例数据的输出结果如下:
| uid | incomplete_cnt | complete_cnt | detail |
|---|---|---|---|
| 1002 | 2 | 4 | 2021-09-01:算法;2021-07-02:SQL;2021-09-02:SQL;2021-09-05:SQL;2021-07-05:SQL |
解释:2021 年的作答记录中,除了 1004,其他用户均满足有效用户定义,但只有 1002 未完成试卷数大于 1,因此只输出 1002,detail 中是 1002 作答过的试卷{日期:tag}集合,日期和 tag 间用 : 连接,多元素间用 ; 连接。
思路:
仔细读题后,分析出:首先要联表,因为后面要输出tag;
筛选出 2021 年的数据
SELECT *
FROM exam_record er
LEFT JOIN examination_info ei ON er.exam_id = ei.exam_id
WHERE YEAR(er.start_time) = '2021'
根据 uid 进行分组,然后对每个用户进行条件进行判断,题目中要求完成试卷数至少为1,未完成试卷数要大于1,小于5
那么等会儿写 sql 的时候条件应该是:未完成 > 1 and 已完成 >=1 and 未完成 < 5
因为最后要用到字符串的拼接,而且还要组合拼接,这个可以用GROUP_CONCAT函数,下面简单介绍一下该函数的用法:
基本格式:
GROUP_CONCAT([DISTINCT] expr [ORDER BY {unsigned_integer | col_name | expr} [ASC | DESC] [, ...]] [SEPARATOR sep])
expr:要连接的列或表达式。DISTINCT:可选参数,用于去重。当指定了 DISTINCT,相同的值只会出现一次。ORDER BY:可选参数,用于排序连接后的值。可以选择升序 (ASC) 或降序 (DESC) 排序。SEPARATOR sep:可选参数,用于设置连接后的值的分隔符。(本题要用这个参数设置 ; 号 )
GROUP_CONCAT() 函数常用于 GROUP BY 子句中,将一组行的值连接为一个字符串,并在结果集中以聚合的形式返回。
答案:
SELECT a.uid,
SUM(CASE
WHEN a.submit_time IS NULL THEN 1
END) AS incomplete_cnt,
SUM(CASE
WHEN a.submit_time IS NOT NULL THEN 1
END) AS complete_cnt,
GROUP_CONCAT(DISTINCT CONCAT(DATE_FORMAT(a.start_time,'%Y-%m-%d'),':',b.tag)
ORDER BY start_time SEPARATOR ';') AS detail
FROM exam_record a
LEFT JOIN examination_info b ON a.exam_id = b.exam_id
WHERE YEAR (a.start_time)= 2021
GROUP BY a.uid
HAVING incomplete_cnt > 1
AND complete_cnt >=1
AND incomplete_cnt < 5
ORDER BY incomplete_cnt DESC

SUM(CASE WHEN a.submit_time IS NULL THEN 1 END)统计了每个用户未完成的记录数量。SUM(CASE WHEN a.submit_time IS NOT NULL THEN 1 END)统计了每个用户已完成的记录数量。GROUP_CONCAT(DISTINCT CONCAT(DATE_FORMAT(a.start_time, '%Y-%m-%d'), ':', b.tag) ORDER BY a.start_time SEPARATOR ';')将每个用户的考试日期和标签以逗号分隔的形式连接成一个字符串,并按考试开始时间进行排序。
3、嵌套子查询
3.1、月均完成试卷数不小于 3 的用户爱作答的类别(较难)
描述:现有试卷作答记录表 exam_record(uid:用户 ID, exam_id:试卷 ID, start_time:开始作答时间, submit_time:交卷时间,没提交的话为 NULL, score:得分),示例数据如下:
| id | uid | exam_id | start_time | submit_time | score |
|---|---|---|---|---|---|
| 1 | 1001 | 9001 | 2021-07-02 09:01:01 | (NULL) | (NULL) |
| 2 | 1002 | 9003 | 2021-09-01 12:01:01 | 2021-09-01 12:21:01 | 60 |
| 3 | 1002 | 9002 | 2021-09-02 12:01:01 | 2021-09-02 12:31:01 | 70 |
| 4 | 1002 | 9001 | 2021-09-05 19:01:01 | 2021-09-05 19:40:01 | 81 |
| 5 | 1002 | 9002 | 2021-07-06 12:01:01 | (NULL) | (NULL) |
| 6 | 1003 | 9003 | 2021-09-07 10:01:01 | 2021-09-07 10:31:01 | 86 |
| 7 | 1003 | 9003 | 2021-09-08 12:01:01 | 2021-09-08 12:11:01 | 40 |
| 8 | 1003 | 9001 | 2021-09-08 13:01:01 | (NULL) | (NULL) |
| 9 | 1003 | 9002 | 2021-09-08 14:01:01 | (NULL) | (NULL) |
| 10 | 1003 | 9003 | 2021-09-08 15:01:01 | (NULL) | (NULL) |
| 11 | 1005 | 9001 | 2021-09-01 12:01:01 | 2021-09-01 12:31:01 | 88 |
| 12 | 1005 | 9002 | 2021-09-01 12:01:01 | 2021-09-01 12:31:01 | 88 |
| 13 | 1005 | 9002 | 2021-09-02 12:11:01 | 2021-09-02 12:31:01 | 89 |
试卷信息表 examination_info(exam_id:试卷 ID, tag:试卷类别, difficulty:试卷难度, duration:考试时长, release_time:发布时间),示例数据如下:
| id | exam_id | tag | difficulty | duration | release_time |
|---|---|---|---|---|---|
| 1 | 9001 | SQL | hard | 60 | 2020-01-01 10:00:00 |
| 2 | 9002 | C++ | easy | 60 | 2020-02-01 10:00:00 |
| 3 | 9003 | 算法 | medium | 80 | 2020-08-02 10:00:00 |
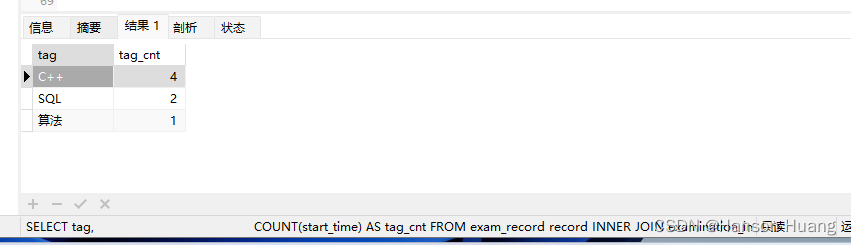
请从表中统计出 “当月均完成试卷数”不小于 3 的用户们爱作答的类别及作答次数,按次数降序输出,示例输出如下:
| tag | tag_cnt |
|---|---|
| C++ | 4 |
| SQL | 2 |
| 算法 | 1 |
解释:用户 1002 和 1005 在 2021 年 09 月的完成试卷数目均为 3,其他用户均小于 3;然后用户 1002 和 1005 作答过的试卷 tag 分布结果按作答次数降序排序依次为 C++、SQL、算法。
思路:这题考察联合子查询,重点在于月均回答>=3, 但是个人认为这里没有表述清楚,应该直接说查 9 月的就容易理解多了;这里不是每个月都要>=3 或者是所有答题次数/答题月份。不要理解错误了。
先查询出哪些用户月均答题大于三次
SELECT uid
FROM exam_record
GROUP BY uid,MONTH(start_time)
HAVING COUNT(submit_time) >= 3

有了这一步之后再进行深入,只要能理解上一步(我的意思是不被题目中的月均所困扰),然后再套一个子查询,查哪些用户包含其中,然后查出题目中所需的列即可。记得排序!!
SELECT tag,
COUNT(start_time) AS tag_cnt
FROM exam_record record
INNER JOIN examination_info info ON record.exam_id = info.exam_id
WHERE uid IN (
SELECT uid
FROM exam_record
GROUP BY uid,MONTH(start_time)
HAVING COUNT(submit_time) >= 3
)
GROUP BY tag
ORDER BY tag_cnt DESC
3.2、试卷发布当天作答人数和平均分
描述:现有用户信息表 user_info(uid 用户 ID,nick_name 昵称, achievement 成就值,level等级, job 职业方向, register_time 注册时间),示例数据如下:
| id | uid | nick_name | achievement | level | job | register_time |
|---|---|---|---|---|---|---|
| 1 | 1001 | 机器人 1 号 | 3100 | 7 | 算法 | 2020-01-01 10:00:00 |
| 2 | 1002 | 机器人 2 号 | 2100 | 6 | 算法 | 2020-01-01 10:00:00 |
| 3 | 1003 | 机器人 3 号 | 1500 | 5 | 算法 | 2020-01-01 10:00:00 |
| 4 | 1004 | 机器人 4 号 | 1100 | 4 | 算法 | 2020-01-01 10:00:00 |
| 5 | 1005 | 机器人 5 号 | 1600 | 6 | C++ | 2020-01-01 10:00:00 |
| 6 | 1006 | 机器人 6 号 | 3000 | 6 | C++ | 2020-01-01 10:00:00 |
释义:用户 1001 昵称为机器人 1 号,成就值为 3100,用户等级是 7 级,职业方向为算法,注册时间 2020-01-01 10:00:00
试卷信息表 examination_info(exam_id:试卷 ID, tag:试卷类别, difficulty:试卷难度, duration:考试时长, release_time:发布时间),示例数据如下:
| id | exam_id | tag | difficulty | duration | release_time |
|---|---|---|---|---|---|
| 1 | 9001 | SQL | hard | 60 | 2021-09-01 06:00:00 |
| 2 | 9002 | C++ | easy | 60 | 2020-02-01 10:00:00 |
| 3 | 9003 | 算法 | medium | 80 | 2020-08-02 10:00:00 |
试卷作答记录表 exam_record(uid 用户 ID,exam_id 试卷 ID, start_time 开始作答时间, submit_time 交卷时间, score 得分) 示例数据如下:
| id | uid | exam_id | start_time | submit_time | score |
|---|---|---|---|---|---|
| 1 | 1001 | 9001 | 2021-09-01 09:01:01 | 2021-09-01 09:41:01 | 70 |
| 2 | 1002 | 9003 | 2021-09-01 12:01:01 | 2021-09-01 12:21:01 | 60 |
| 3 | 1002 | 9002 | 2021-09-02 12:01:01 | 2021-09-02 12:31:01 | 70 |
| 4 | 1002 | 9001 | 2021-09-01 19:01:01 | 2021-09-01 19:40:01 | 80 |
| 5 | 1002 | 9003 | 2021-08-01 12:01:01 | 2021-08-01 12:21:01 | 60 |
| 6 | 1002 | 9002 | 2021-08-02 12:01:01 | 2021-08-02 12:31:01 | 70 |
| 7 | 1002 | 9001 | 2021-09-01 19:01:01 | 2021-09-01 19:40:01 | 85 |
| 8 | 1002 | 9002 | 2021-07-06 12:01:01 | (NULL) | (NULL) |
| 9 | 1003 | 9002 | 2021-09-07 10:01:01 | 2021-09-07 10:31:01 | 86 |
| 10 | 1003 | 9003 | 2021-09-08 12:01:01 | 2021-09-08 12:11:01 | 40 |
| 11 | 1003 | 9003 | 2021-09-01 13:01:01 | 2021-09-01 13:41:01 | 70 |
| 12 | 1003 | 9001 | 2021-09-08 14:01:01 | (NULL) | (NULL) |
| 13 | 1003 | 9002 | 2021-09-08 15:01:01 | (NULL) | (NULL) |
| 14 | 1005 | 9001 | 2021-09-01 12:01:01 | 2021-09-01 12:31:01 | 90 |
| 15 | 1005 | 9002 | 2021-09-01 12:01:01 | 2021-09-01 12:31:01 | 88 |
| 16 | 1005 | 9002 | 2021-09-02 12:11:01 | 2021-09-02 12:31:01 | 89 |
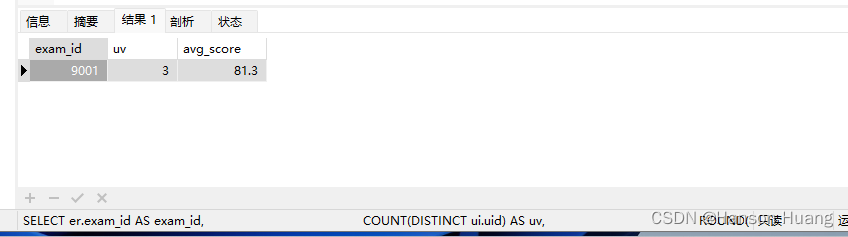
请计算每张 SQL 类别试卷发布后,当天 5 级以上的用户作答的人数 uv 和平均分 avg_score,按人数降序,相同人数的按平均分升序,示例数据结果输出如下:
| exam_id | uv | avg_score |
|---|---|---|
| 9001 | 3 | 81.3 |
解释:只有一张 SQL 类别的试卷,试卷 ID 为 9001,发布当天(2021-09-01)有 1001、1002、1003、1005 作答过,但是 1003 是 5 级用户,其他 3 位为 5 级以上,他们三的得分有[70,80,85,90],平均分为 81.3(保留 1 位小数)。
思路:这题看似很复杂,但是先逐步将“外边”条件拆分,然后合拢到一起,答案就出来,多表查询反正记住:由外向里,抽丝剥茧。
先把三种表连起来,同时给定一些条件,比如题目中要求等级> 5的用户,那么可以先查出来
SELECT DISTINCT ui.uid
FROM examination_info ei
INNER JOIN exam_record er
INNER JOIN user_info ui
WHERE ei.exam_id = er.exam_id
AND er.uid = ui.uid
AND ui.`level` > 5
接着注意题目中要求:每张sql类别试卷发布后,当天作答用户,注意其中的当天,那我们马上就要想到要用到时间的比较。
对试卷发布日期和开始考试日期进行比较:DATE(ei.release_time) = DATE(er.start_time);不用担心submit_time 为 null 的问题,后续在 where 中会给过滤掉。
答案:
SELECT er.exam_id AS exam_id,
COUNT(DISTINCT ui.uid) AS uv,
ROUND(SUM(er.score)/COUNT(ui.uid),1) AS avg_score
FROM examination_info ei
INNER JOIN exam_record er
INNER JOIN user_info ui
WHERE ei.exam_id = er.exam_id
AND er.uid = ui.uid
AND DATE(ei.release_time) = DATE(er.start_time)
AND submit_time IS NOT NULL
AND ei.tag = 'SQL'
AND ui.`level` > 5
GROUP BY er.exam_id
ORDER BY uv DESC,
avg_score ASC
注意最后的分组排序!先按人数排,若一致,按平均分排。
3.3、作答试卷得分大于过 80 的人的用户等级分布
描述:
现有用户信息表 user_info(uid 用户 ID,nick_name 昵称, achievement 成就值,level等级, job 职业方向, register_time 注册时间),示例数据如下:
| id | uid | nick_name | achievement | level | job | register_time |
|---|---|---|---|---|---|---|
| 1 | 1001 | 机器人 1 号 | 3100 | 7 | 算法 | 2020-01-01 10:00:00 |
| 2 | 1002 | 机器人 2 号 | 2100 | 6 | 算法 | 2020-01-01 10:00:00 |
| 3 | 1003 | 机器人 3 号 | 1500 | 5 | 算法 | 2020-01-01 10:00:00 |
| 4 | 1004 | 机器人 4 号 | 1100 | 4 | 算法 | 2020-01-01 10:00:00 |
| 5 | 1005 | 机器人 5 号 | 1600 | 6 | C++ | 2020-01-01 10:00:00 |
| 6 | 1006 | 机器人 6 号 | 3000 | 6 | C++ | 2020-01-01 10:00:00 |
试卷信息表 examination_info(exam_id:试卷 ID, tag:试卷类别, difficulty:试卷难度, duration:考试时长, release_time:发布时间),示例数据如下:
| id | exam_id | tag | difficulty | duration | release_time |
|---|---|---|---|---|---|
| 1 | 9001 | SQL | hard | 60 | 2021-09-01 06:00:00 |
| 2 | 9002 | C++ | easy | 60 | 2020-02-01 10:00:00 |
| 3 | 9003 | 算法 | medium | 80 | 2020-08-02 10:00:00 |
试卷作答记录表 exam_record(uid 用户 ID,exam_id 试卷 ID, start_time 开始作答时间, submit_time 交卷时间, score 得分) 示例数据如下:
| id | uid | exam_id | start_time | submit_time | score |
|---|---|---|---|---|---|
| 1 | 1001 | 9001 | 2021-09-01 09:01:01 | 2021-09-01 09:41:01 | 79 |
| 2 | 1002 | 9003 | 2021-09-01 12:01:01 | 2021-09-01 12:21:01 | 60 |
| 3 | 1002 | 9002 | 2021-09-02 12:01:01 | 2021-09-02 12:31:01 | 70 |
| 4 | 1002 | 9001 | 2021-09-01 19:01:01 | 2021-09-01 19:40:01 | 80 |
| 5 | 1002 | 9003 | 2021-08-01 12:01:01 | 2021-08-01 12:21:01 | 60 |
| 6 | 1002 | 9002 | 2021-08-02 12:01:01 | 2021-08-02 12:31:01 | 70 |
| 7 | 1002 | 9001 | 2021-09-01 19:01:01 | 2021-09-01 19:40:01 | 85 |
| 8 | 1002 | 9002 | 2021-07-06 12:01:01 | (NULL) | (NULL) |
| 9 | 1003 | 9001 | 2021-09-07 10:01:01 | 2021-09-07 10:31:01 | 86 |
| 10 | 1003 | 9003 | 2021-09-08 12:01:01 | 2021-09-08 12:11:01 | 40 |
| 11 | 1003 | 9003 | 2021-09-01 13:01:01 | 2021-09-01 13:41:01 | 81 |
| 12 | 1003 | 9001 | 2021-09-08 14:01:01 | (NULL) | (NULL) |
| 13 | 1003 | 9002 | 2021-09-08 15:01:01 | (NULL) | (NULL) |
| 14 | 1005 | 9001 | 2021-09-01 12:01:01 | 2021-09-01 12:31:01 | 90 |
| 15 | 1005 | 9002 | 2021-09-01 12:01:01 | 2021-09-01 12:31:01 | 88 |
| 16 | 1005 | 9002 | 2021-09-02 12:11:01 | 2021-09-02 12:31:01 | 89 |
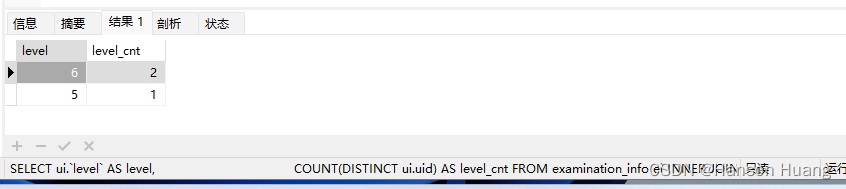
统计作答 SQL 类别的试卷得分大于过 80 的人的用户等级分布,按数量降序排序(保证数量都不同)。示例数据结果输出如下:
| level | level_cnt |
|---|---|
| 6 | 2 |
| 5 | 1 |
解释:9001 为 SQL 类试卷,作答该试卷大于 80 分的人有 1002、1003、1005 共 3 人,6 级两人,5 级一人。
思路:这题和上一题都是一样的数据,只是查询条件改变了而已,上一题理解了,这题分分钟做出来。
答案:
SELECT ui.`level` AS level,
COUNT(DISTINCT ui.uid) AS level_cnt
FROM examination_info ei
INNER JOIN exam_record er
INNER JOIN user_info ui
WHERE ei.exam_id = er.exam_id
AND er.uid = ui.uid
AND ei.tag = 'SQL'
AND er.score > 80
GROUP BY level
ORDER BY level_cnt DESC
4、合并查询
4.1、每个题目和每份试卷被作答的人数和次数
描述:
现有试卷作答记录表 exam_record(uid 用户 ID,exam_id 试卷 ID, start_time 开始作答时间, submit_time 交卷时间, score 得分) 示例数据如下:
| id | uid | exam_id | start_time | submit_time | score |
|---|---|---|---|---|---|
| 1 | 1001 | 9001 | 2021-09-01 09:01:01 | 2021-09-01 09:41:01 | 81 |
| 2 | 1002 | 9002 | 2021-09-01 12:01:01 | 2021-09-01 12:31:01 | 70 |
| 3 | 1002 | 9001 | 2021-09-01 19:01:01 | 2021-09-01 19:40:01 | 80 |
| 4 | 1002 | 9002 | 2021-09-01 12:01:01 | 2021-09-01 12:31:01 | 70 |
| 5 | 1004 | 9001 | 2021-09-01 19:01:01 | 2021-09-01 19:40:01 | 85 |
| 6 | 1002 | 9002 | 2021-09-01 12:01:01 | (NULL) | (NULL) |
题目练习表 practice_record(uid 用户 ID, question_id 题目 ID, submit_time 提交时间, score 得分):
| id | uid | question_id | submit_time | score |
|---|---|---|---|---|
| 1 | 1001 | 8001 | 2021-08-02 11:41:01 | 60 |
| 2 | 1002 | 8001 | 2021-09-02 19:30:01 | 50 |
| 3 | 1002 | 8001 | 2021-09-02 19:20:01 | 70 |
| 4 | 1002 | 8002 | 2021-09-02 19:38:01 | 70 |
| 5 | 1003 | 8001 | 2021-08-02 19:38:01 | 70 |
| 6 | 1003 | 8001 | 2021-08-02 19:48:01 | 90 |
| 7 | 1003 | 8002 | 2021-08-01 19:38:01 | 80 |
请统计每个题目和每份试卷被作答的人数和次数,分别按照"试卷"和"题目"的 uv & pv 降序显示,示例数据结果输出如下:
| tid | uv | pv |
|---|---|---|
| 9001 | 3 | 3 |
| 9002 | 1 | 3 |
| 8001 | 3 | 5 |
| 8002 | 2 | 2 |
解释:“试卷”有 3 人共练习 3 次试卷 9001,1 人作答 3 次 9002;“刷题”有 3 人刷 5 次 8001,有 2 人刷 2 次 8002
思路:这题的难点和易错点在于UNION和ORDER BY 同时使用的问题
有以下几种情况:使用union和多个order by不加括号,报错!
order by在union连接的子句中不起作用;
比如不加括号:
SELECT exam_id AS tid,
COUNT(DISTINCT UID) AS uv,
COUNT(UID) AS pv
FROM exam_record
GROUP BY exam_id
ORDER BY uv DESC,
pv DESC
UNION
SELECT question_id AS tid,
COUNT(DISTINCT UID) AS uv,
COUNT(UID) AS pv
FROM practice_record
GROUP BY question_id
ORDER BY uv DESC,
pv DESC
直接报语法错误,如果没有括号,只能有一个order by
还有一种order by不起作用的情况,但是能在子句的子句中起作用,这里的解决方案就是在外面再套一层查询。
答案:
SELECT *
FROM
(SELECT exam_id AS tid,
COUNT(DISTINCT exam_record.uid) uv,
COUNT(*) pv
FROM exam_record
GROUP BY exam_id
ORDER BY uv DESC, pv DESC) t1
UNION
SELECT *
FROM
(SELECT question_id AS tid,
COUNT(DISTINCT practice_record.uid) uv,
COUNT(*) pv
FROM practice_record
GROUP BY question_id
ORDER BY uv DESC, pv DESC) t2;

4.2、分别满足两个活动的人
描述: 为了促进更多用户在平台学习和刷题进步,我们会经常给一些既活跃又表现不错的用户发放福利。假使以前我们有两拨运营活动,分别给每次试卷得分都能到 85 分的人(activity1)、至少有一次用了一半时间就完成高难度试卷且分数大于 80 的人(activity2)发了福利券。
现在,需要你一次性将这两个活动满足的人筛选出来,交给运营同学。请写出一个 SQL 实现:输出 2021 年里,所有每次试卷得分都能到 85 分的人以及至少有一次用了一半时间就完成高难度试卷且分数大于 80 的人的 id 和活动号,按用户 ID 排序输出。
现有试卷信息表 examination_info(exam_id:试卷 ID, tag:试卷类别, difficulty:试卷难度, duration:考试时长, release_time:发布时间),示例数据如下:
| id | exam_id | tag | difficulty | duration | release_time |
|---|---|---|---|---|---|
| 1 | 9001 | SQL | hard | 60 | 2021-09-01 06:00:00 |
| 2 | 9002 | C++ | easy | 60 | 2020-02-01 10:00:00 |
| 3 | 9003 | 算法 | medium | 80 | 2020-08-02 10:00:00 |
现有试卷作答记录表 exam_record(uid 用户 ID,exam_id 试卷 ID, start_time 开始作答时间, submit_time 交卷时间, score 得分) 示例数据如下:
| id | uid | exam_id | start_time | submit_time | score |
|---|---|---|---|---|---|
| 1 | 1001 | 9001 | 2021-09-01 09:01:01 | 2021-09-01 09:31:00 | 81 |
| 2 | 1002 | 9002 | 2021-09-01 12:01:01 | 2021-09-01 12:31:01 | 70 |
| 3 | 1003 | 9001 | 2021-09-01 19:01:01 | 2021-09-01 19:40:01 | 86 |
| 4 | 1003 | 9002 | 2021-09-01 12:01:01 | 2021-09-01 12:31:01 | 89 |
| 5 | 1004 | 9001 | 2021-09-01 19:01:01 | 2021-09-01 19:30:01 | 85 |
示例数据输出结果:
| uid | activity |
|---|---|
| 1001 | activity2 |
| 1003 | activity1 |
| 1004 | activity1 |
| 1004 | activity2 |
解释:用户 1001 最小分数 81 不满足活动 1,但 29 分 59 秒完成了 60 分钟长的试卷得分 81,满足活动 2;1003 最小分数 86 满足活动 1,完成时长都大于试卷时长的一半,不满足活动 2;用户 1004 刚好用了一半时间(30 分钟整)完成了试卷得分 85,满足活动 1 和活动 2。
思路: 这一题需要涉及到时间的减法,需要用到 TIMESTAMPDIFF() 函数计算两个时间戳之间的分钟差值。
下面我们来看一下基本用法
示例:
TIMESTAMPDIFF(MINUTE, start_time, end_time)
TIMESTAMPDIFF() 函数的第一个参数是时间单位,这里我们选择 MINUTE 表示返回分钟差值。第二个参数是较早的时间戳,第三个参数是较晚的时间戳。函数会返回它们之间的分钟差值
了解了这个函数的用法之后,我们再回过头来看activity1的要求,求分数大于 85 即可,那我们还是先把这个写出来,后续思路就会清晰很多
SELECT DISTINCT uid
FROM exam_record
WHERE score >= 85
AND YEAR(start_time) = '2021'
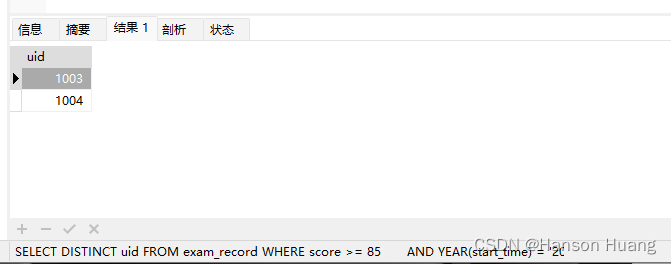
根据条件 2,接着写出在一半时间内完成高难度试卷且分数大于80的人
SELECT uid
FROM exam_record er
INNER JOIN examination_info ei
WHERE er. exam_id = ei.exam_id
AND score >= 80
AND (TIMESTAMPDIFF(MINUTE,start_time,submit_time)) < (ei.duration/2)
AND ei.difficulty = 'hard'

然后再把两者UNION 起来即可。(这里特别要注意括号问题和order by位置,具体用法在上一篇中已提及)
SELECT DISTINCT uid,'activity1' AS activity
FROM exam_record
WHERE score >= 85
AND YEAR(start_time) = '2021'
UNION
SELECT uid,'activity2' AS activity
FROM exam_record er
INNER JOIN examination_info ei
WHERE er. exam_id = ei.exam_id
AND score >= 80
AND (TIMESTAMPDIFF(MINUTE,start_time,submit_time)) < (ei.duration/2)
AND ei.difficulty = 'hard'
ORDER BY uid

5、连接查询
5.1、满足条件的用户的试卷完成数和题目练习数(困难)
描述:
现有用户信息表 user_info(uid 用户 ID,nick_name 昵称, achievement 成就值,level等级, job 职业方向, register_time 注册时间),示例数据如下:
| id | uid | nick_name | achievement | level | job | register_time |
|---|---|---|---|---|---|---|
| 1 | 1001 | 机器人 1 号 | 3100 | 7 | 算法 | 2020-01-01 10:00:00 |
| 2 | 1002 | 机器人 2 号 | 2300 | 7 | 算法 | 2020-01-01 10:00:00 |
| 3 | 1003 | 机器人 3 号 | 2500 | 7 | 算法 | 2020-01-01 10:00:00 |
| 4 | 1004 | 机器人 4 号 | 1200 | 5 | 算法 | 2020-01-01 10:00:00 |
| 5 | 1005 | 机器人 5 号 | 1600 | 6 | C++ | 2020-01-01 10:00:00 |
| 6 | 1006 | 机器人 6 号 | 2000 | 6 | C++ | 2020-01-01 10:00:00 |
现有试卷信息表 examination_info(exam_id:试卷 ID, tag:试卷类别, difficulty:试卷难度, duration:考试时长, release_time:发布时间),示例数据如下:
| id | exam_id | tag | difficulty | duration | release_time |
|---|---|---|---|---|---|
| 1 | 9001 | SQL | hard | 60 | 2021-09-01 06:00:00 |
| 2 | 9002 | C++ | hard | 60 | 2021-09-01 06:00:00 |
| 3 | 9003 | 算法 | medium | 80 | 2021-09-01 10:00:00 |
现有试卷作答记录表 exam_record(uid 用户 ID,exam_id 试卷 ID, start_time 开始作答时间, submit_time 交卷时间, score 得分) 示例数据如下:
| id | uid | exam_id | start_time | submit_time | score |
|---|---|---|---|---|---|
| 1 | 1001 | 9001 | 2021-09-01 09:01:01 | 2021-09-01 09:31:00 | 81 |
| 2 | 1002 | 9002 | 2021-09-01 12:01:01 | 2021-09-01 12:31:01 | 81 |
| 3 | 1003 | 9001 | 2021-09-01 19:01:01 | 2021-09-01 19:40:01 | 86 |
| 4 | 1003 | 9002 | 2021-09-01 12:01:01 | 2021-09-01 12:31:51 | 89 |
| 5 | 1004 | 9001 | 2021-09-01 19:01:01 | 2021-09-01 19:30:01 | 85 |
| 6 | 1005 | 9002 | 2021-09-01 12:01:01 | 2021-09-01 12:31:02 | 85 |
| 7 | 1006 | 9003 | 2021-09-07 10:01:01 | 2021-09-07 10:21:01 | 84 |
| 8 | 1006 | 9001 | 2021-09-07 10:01:01 | 2021-09-07 10:21:01 | 80 |
题目练习表 practice_record(uid 用户 ID, question_id 题目 ID, submit_time 提交时间, score 得分):
| id | uid | question_id | submit_time | score |
|---|---|---|---|---|
| 1 | 1001 | 8001 | 2021-08-02 11:41:01 | 60 |
| 2 | 1002 | 8001 | 2021-09-02 19:30:01 | 50 |
| 3 | 1002 | 8001 | 2021-09-02 19:20:01 | 70 |
| 4 | 1002 | 8002 | 2021-09-02 19:38:01 | 70 |
| 5 | 1004 | 8001 | 2021-08-02 19:38:01 | 70 |
| 6 | 1004 | 8002 | 2021-08-02 19:48:01 | 90 |
| 7 | 1001 | 8002 | 2021-08-02 19:38:01 | 70 |
| 8 | 1004 | 8002 | 2021-08-02 19:48:01 | 90 |
| 9 | 1004 | 8002 | 2021-08-02 19:58:01 | 94 |
| 10 | 1004 | 8003 | 2021-08-02 19:38:01 | 70 |
| 11 | 1004 | 8003 | 2021-08-02 19:48:01 | 90 |
| 12 | 1004 | 8003 | 2021-08-01 19:38:01 | 80 |
请你找到高难度 SQL 试卷得分平均值大于 80 并且是 7 级的红名大佬,统计他们的 2021 年试卷总完成次数和题目总练习次数,只保留 2021 年有试卷完成记录的用户。结果按试卷完成数升序,按题目练习数降序。
示例数据输出如下:
| uid | exam_cnt | question_cnt |
|---|---|---|
| 1001 | 1 | 2 |
| 1003 | 2 | 0 |
解释:用户 1001、1003、1004、1006 满足高难度 SQL 试卷得分平均值大于 80,但只有 1001、1003 是 7 级红名大佬;1001 完成了 1 次试卷 1001,练习了 2 次题目;1003 完成了 2 次试卷 9001、9002,未练习题目(因此计数为 0)
思路:
先将条件进行初步筛选,比如先查出做过高难度 sql 试卷的用户
SELECT er.uid
FROM exam_record er
INNER JOIN examination_info ei
WHERE er.exam_id = ei.exam_id
AND ei.tag = 'SQL'
AND ei.difficulty = 'hard'
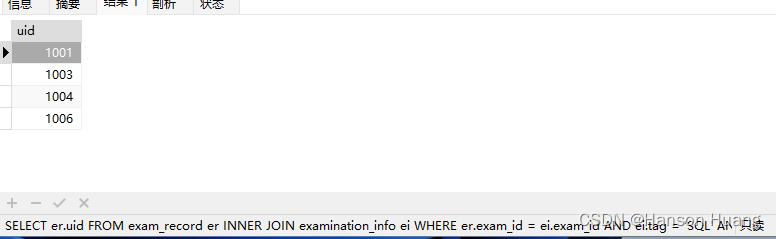
然后根据题目要求,接着再往里叠条件即可;
但是这里又要注意:
第一:不能YEAR(submit_time)= 2021这个条件放到最后,要在ON条件里,因为左连接存在返回左表全部行,右表为 null 的情形,放在 JOIN条件的 ON 子句中的目的是为了确保在连接两个表时,只有满足年份条件的记录会进行连接。这样可以避免其他年份的记录被包含在结果中。即 1001 做过 2021 年的试卷,但没有练习过,如果把条件放到最后,就会排除掉这种情况。
第二,必须是COUNT(distinct er.exam_id) exam_cnt, COUNT(distinct pr.id) question_cnt,要加 distinct,因为有左连接产生很多重复值。
答案:
SELECT er.uid,
COUNT(DISTINCT er.exam_id) AS exam_cnt,
COUNT(DISTINCT pr.id) AS question_cnt
FROM exam_record er
LEFT JOIN practice_record pr ON er.uid = pr.uid
AND YEAR(er.submit_time) = 2021
AND YEAR(pr.submit_time) = 2021
WHERE er.uid IN (
SELECT er.uid
FROM exam_record er
INNER JOIN examination_info ei ON er.exam_id = ei.exam_id
INNER JOIN user_info ui ON ui.uid = er.uid
WHERE ei.tag = 'SQL'
AND ei.difficulty = 'hard'
AND LEVEL = 7
GROUP BY er.uid
HAVING AVG(score) > 80
)
GROUP BY er.uid
ORDER BY exam_cnt,
question_cnt DESC
能细心的小伙伴会发现,为什么明明将条件限制了tag = 'SQL' AND difficulty = 'hard',但是用户 1003 仍然能查出两条考试记录,其中一条的考试tag为 C++; 这是由于LEFT JOIN的特性,即使没有与右表匹配的行,左表的所有记录仍然会被保留。
5.2、每个 6/7 级用户活跃情况(困难)
描述:
现有用户信息表 user_info(uid 用户 ID,nick_name 昵称, achievement 成就值,level等级, job 职业方向, register_time 注册时间),示例数据如下:
| id | uid | nick_name | achievement | level | job | register_time |
|---|---|---|---|---|---|---|
| 1 | 1001 | 机器人 1 号 | 3100 | 7 | 算法 | 2020-01-01 10:00:00 |
| 2 | 1002 | 机器人 2 号 | 2300 | 7 | 算法 | 2020-01-01 10:00:00 |
| 3 | 1003 | 机器人 3 号 | 2500 | 7 | 算法 | 2020-01-01 10:00:00 |
| 4 | 1004 | 机器人 4 号 | 1200 | 5 | 算法 | 2020-01-01 10:00:00 |
| 5 | 1005 | 机器人 5 号 | 1600 | 6 | C++ | 2020-01-01 10:00:00 |
| 6 | 1006 | 机器人 6 号 | 2000 | 7 | C++ | 2020-01-01 10:00:00 |
现有试卷信息表 examination_info(exam_id:试卷 ID, tag:试卷类别, difficulty:试卷难度, duration:考试时长, release_time:发布时间),示例数据如下:
| id | exam_id | tag | difficulty | duration | release_time |
|---|---|---|---|---|---|
| 1 | 9001 | SQL | hard | 60 | 2021-09-01 06:00:00 |
| 2 | 9002 | C++ | easy | 60 | 2021-09-01 06:00:00 |
| 3 | 9003 | 算法 | medium | 80 | 2021-09-01 10:00:00 |
现有试卷作答记录表 exam_record(uid 用户 ID,exam_id 试卷 ID, start_time 开始作答时间, submit_time 交卷时间, score 得分) 示例数据如下:
| uid | exam_id | start_time | submit_time | score |
|---|---|---|---|---|
| 1001 | 9001 | 2021-09-01 09:01:01 | 2021-09-01 09:31:00 | 78 |
| 1001 | 9001 | 2021-09-01 09:01:01 | 2021-09-01 09:31:00 | 81 |
| 1005 | 9001 | 2021-09-01 19:01:01 | 2021-09-01 19:30:01 | 85 |
| 1005 | 9002 | 2021-09-01 12:01:01 | 2021-09-01 12:31:02 | 85 |
| 1006 | 9003 | 2021-09-07 10:01:01 | 2021-09-07 10:21:59 | 84 |
| 1006 | 9001 | 2021-09-07 10:01:01 | 2021-09-07 10:21:01 | 81 |
| 1002 | 9001 | 2020-09-01 13:01:01 | 2020-09-01 13:41:01 | 81 |
| 1005 | 9001 | 2021-09-01 14:01:01 | (NULL) | (NULL) |
题目练习表 practice_record(uid 用户 ID, question_id 题目 ID, submit_time 提交时间, score 得分):
| uid | question_id | submit_time | score |
|---|---|---|---|
| 1001 | 8001 | 2021-08-02 11:41:01 | 60 |
| 1004 | 8001 | 2021-08-02 19:38:01 | 70 |
| 1004 | 8002 | 2021-08-02 19:48:01 | 90 |
| 1001 | 8002 | 2021-08-02 19:38:01 | 70 |
| 1004 | 8002 | 2021-08-02 19:48:01 | 90 |
| 1006 | 8002 | 2021-08-04 19:58:01 | 94 |
| 1006 | 8003 | 2021-08-03 19:38:01 | 70 |
| 1006 | 8003 | 2021-08-02 19:48:01 | 90 |
| 1006 | 8003 | 2020-08-01 19:38:01 | 80 |
请统计每个 6/7 级用户总活跃月份数、2021 年活跃天数、2021 年试卷作答活跃天数、2021 年答题活跃天数,按照总活跃月份数、2021 年活跃天数降序排序。由示例数据结果输出如下:
| uid | act_month_total | act_days_2021 | act_days_2021_exam |
|---|---|---|---|
| 1006 | 3 | 4 | 1 |
| 1001 | 2 | 2 | 1 |
| 1005 | 1 | 1 | 1 |
| 1002 | 1 | 0 | 0 |
| 1003 | 0 | 0 | 0 |
解释:6/7 级用户共有 5 个,其中 1006 在 202109、202108、202008 共 3 个月活跃过,2021 年活跃的日期有 20210907、20210804、20210803、20210802 共 4 天,2021 年在试卷作答区 20210907 活跃 1 天,在题目练习区活跃了 3 天。
思路:
这题的关键在于CASE WHEN THEN的使用,不然要写很多的left join 因为会产生很多的结果集。
CASE WHEN THEN语句是一种条件表达式,用于在 SQL 中根据条件执行不同的操作或返回不同的结果。
语法结构如下:
CASE
WHEN condition1 THEN result1
WHEN condition2 THEN result2
...
ELSE result
END
在这个结构中,可以根据需要添加多个WHEN子句,每个WHEN子句后面跟着一个条件(condition)和一个结果(result)。条件可以是任何逻辑表达式,如果满足条件,将返回对应的结果。
最后的ELSE子句是可选的,用于指定当所有前面的条件都不满足时的默认返回结果。如果没有提供ELSE子句,则默认返回NULL。
例如:
SELECT score,
CASE
WHEN score >= 90 THEN '优秀'
WHEN score >= 80 THEN '良好'
WHEN score >= 60 THEN '及格'
ELSE '不及格'
END AS grade
FROM student_scores;
在上述示例中,根据学生成绩(score)的不同范围,使用 CASE WHEN THEN 语句返回相应的等级(grade)。如果成绩大于等于 90,则返回"优秀";如果成绩大于等于 80,则返回"良好";如果成绩大于等于 60,则返回"及格";否则返回"不及格"。
那了解到了上述的用法之后,回过头看看该题,要求列出不同的活跃天数。
count(distinct act_month) as act_month_total,
count(distinct case when year(act_time)='2021'then act_day end) as act_days_2021,
count(distinct case when year(act_time)='2021' and tag='exam' then act_day end) as act_days_2021_exam,
count(distinct case when year(act_time)='2021' and tag='question'then act_day end) as act_days_2021_question
这里的 tag 是先给标记,方便对查询进行区分,将考试和答题分开。
找出试卷作答区的用户
SELECT
uid,
exam_id AS ans_id,
start_time AS act_time,
DATE_FORMAT(start_time,'%Y%m') AS act_month,
DATE_FORMAT(start_time,'%Y%m%d') AS act_day,
'exam' AS tag
FROM exam_record
紧接着就是答题作答区的用户
SELECT
uid,
question_id AS ans_id,
submit_time AS act_time,
DATE_FORMAT(submit_time,'%Y%m') AS act_month,
DATE_FORMAT(submit_time,'%Y%m%d') AS act_day,
'question' AS tag
FROM practice_record
最后将两个结果进行UNION 最后别忘了将结果进行排序 (这题有点类似于分治法的思想)
答案:
SELECT user_info.uid,
count(distinct act_month) as act_month_total,
count(distinct case
when year(act_time)='2021'then act_day
end) as act_days_2021,
count(distinct case
when year(act_time)='2021' and tag='exam' then act_day
end) as act_days_2021_exam,
count(distinct case
when year(act_time)='2021' and tag='question'then act_day
end) as act_days_2021_question
FROM (
SELECT
uid,
exam_id AS ans_id,
start_time AS act_time,
DATE_FORMAT(start_time,'%Y%m') AS act_month,
DATE_FORMAT(start_time,'%Y%m%d') AS act_day,
'exam' AS tag
FROM exam_record
UNION ALL
SELECT
uid,
question_id AS ans_id,
submit_time AS act_time,
DATE_FORMAT(submit_time,'%Y%m') AS act_month,
DATE_FORMAT(submit_time,'%Y%m%d') AS act_day,
'question' AS tag
FROM practice_record
) total
RIGHT JOIN user_info ON total.uid = user_info.uid
WHERE user_info.LEVEL IN (6,7)
GROUP BY user_info.uid
ORDER BY act_month_total DESC,
act_days_2021 DESC

好文推荐:
《【SQL】SQL常见面试题总结(1)》
《【SQL】SQL常见面试题总结(2)》