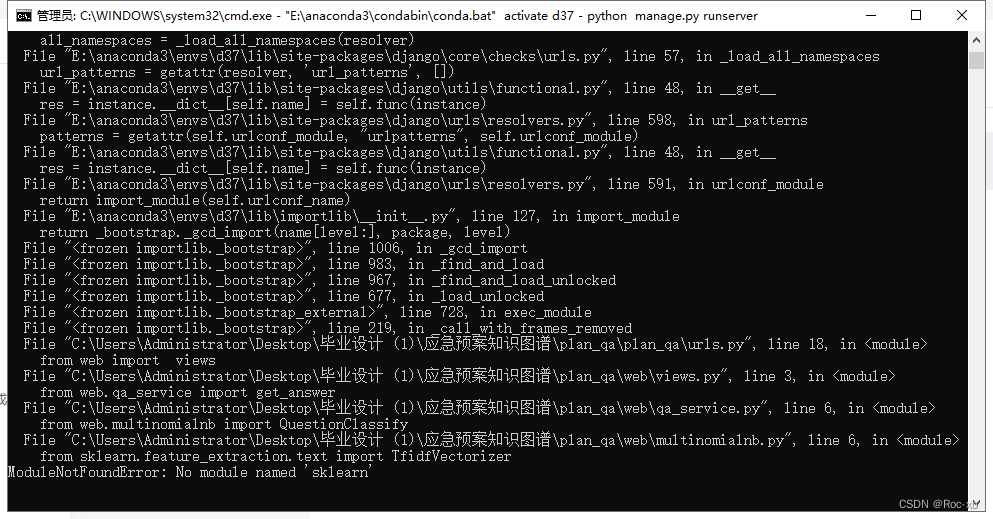
关于max_old_space_size

max_old_space_size参数用于指定V8引擎的老生代内存的最大大小。通过增加max_old_space_size参数的值,我们可以提供更多的内存给V8引擎,从而提高应用程序的性能和稳定性。
既然提到了老生代,就不得不提下什么是垃圾,以及与之密切绑定的垃圾回收机制。
什么是垃圾
程序运行过程中会用到一些数据,这些数据被放在堆栈中,在程序运行结束后,这些不再使用的数据,就是垃圾。
为什么需要GC
GC:Garbage Collection,垃圾回收器。
程序运行需要使用内存,内存的两个分区:栈区和堆区。
● 栈区是线性的队列,随着函数运行结束自动释放。于JS而言,栈用于存放JS中的基本数据类型和引用类型的指针。空间是连续的,增加和删除只需要移动指针,操作速度非常快。同时,栈的空间又是有限的,当栈满了,就会抛出一个内存溢出错误
● 堆区是自由的动态内存空间,堆内存可以手动分配释放,也可以由垃圾回收器自动分配释放。于JS而言,堆用于存放JS中的引用类型
软件开发初期,或者有些语言在处理堆内存的时候,都是手动操作分配和释放,比如C、C++。虽然能精准操作内存,但是开发效率也随之低下,也很容易出现内存操作不当的情况。
随着技术发展,高级语言(Java、Node)都不需要开发者手动操作内存,程序语言会自动分配和释放空间,因此诞生了GC,GC的作用就是帮助程序释放和整理内存。这样就使得开发者大部分情况下不需要关注内存本身,可以更加聚焦业务开发。
堆空间分类
堆区才需要垃圾回收,重点!!!
堆内存的设计与GC的设计是紧密相关的,在NodeJS中,GC采用分代策略,分为新生代和老生代,内存数据大都在这两个区域里。
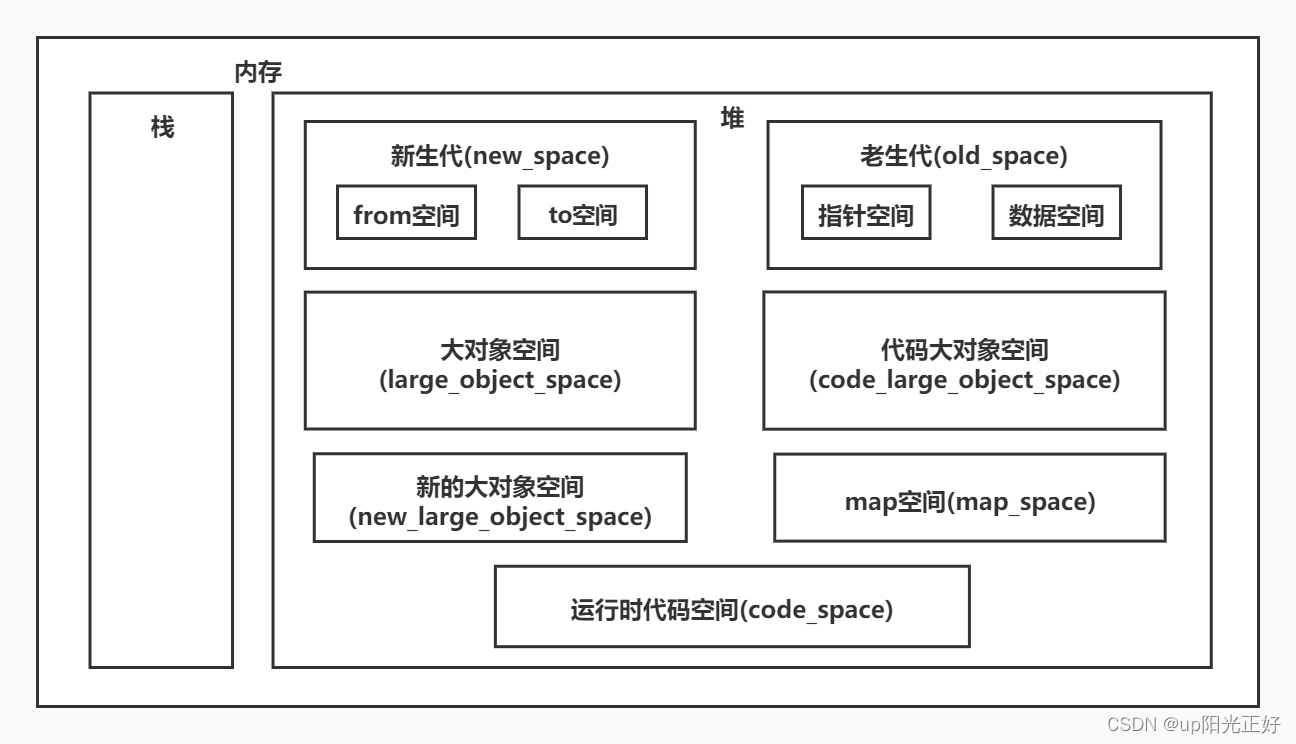
新生代 new space
新生代内存用于存放一些生命周期比较短的对象数据。
老生代 old space
老生代内存存放一些生命周期较长的对象数据。
大对象空间 large object space
默认情况下超过256K的对象会直接在大对象空间创建,并且不会移动到其他空间。
运行时代码空间 code_space
用于存放JIT(即时编译)已编译的代码,这是唯一有执行权限的内存。
map空间 Map space
用于存储用于JavaScript对象的元信息和其他内部数据结构,比如Map和Set对象。
新生代的垃圾回收
新生代内存用于存放一些生命周期比较短的对象数据。新生代分为2个区域,对象区域(from空间)和对象(to空间),两个区域相互切换。
当对象首次创建后它们被分配到from空间,它的年龄就是1,当from空间不足或者超过一定大小数量之后,就会触发Minor GC(采用复制算法),此时,GC 会暂停应用程序的执行(STW,stop-the-world),标记(from空间)中所有活动对象,然后将它们整体移动到另一个空闲空间(to空间)中。最后原本的 from 空间的内存会被全部释放而变成空闲空间,两个空间就完成 from 和 to 的对换,复制算法是牺牲了空间换取时间的算法。
新生代的空间更小,所以此空间会更加频繁地触发GC,同时也是因为扫描的空间小,GC的性能消耗也更小,GC的执行时间也更短。
每当一次Minor GC完成,存活的对象年龄就+1,经历过多次Minor GC还存活的对象(年龄大于N),一般to空间大于75%,将会被移动到老生代内存池中。
老生代的垃圾回收
老生代内存是一个大的内存池,用于存放一些生命周期比较长的对象数据。Old Space 使用**标记清除(Mark-Sweep)和标记压缩算法(Mark-Compact)**的方式进行垃圾回收。它的一次执行叫做Mayor GC。当老生代中的对象占满一定比例时,即存活对象与总对象的比例超过一定的阈值,就会触发一次标记清除和标记压缩。
因为它的空间更大,所以此空间GC执行时间也更长,频率相对新生代更低。如果老生代执行完GC后,空间还是不足,V8就会从系统中申请更多内存。
可以手动执行global.gc()方法,设置不同的参数,主动触发GC。需要注意的是,默认情况下,NodeJS是禁用垃圾回收的,如果要启用垃圾回收,可以通过启动 Node.js 应用程序时添加 --expose-gc 参数来开启,例如:
node --expose-gc xxx.js
默认情况下,执行gc报错:
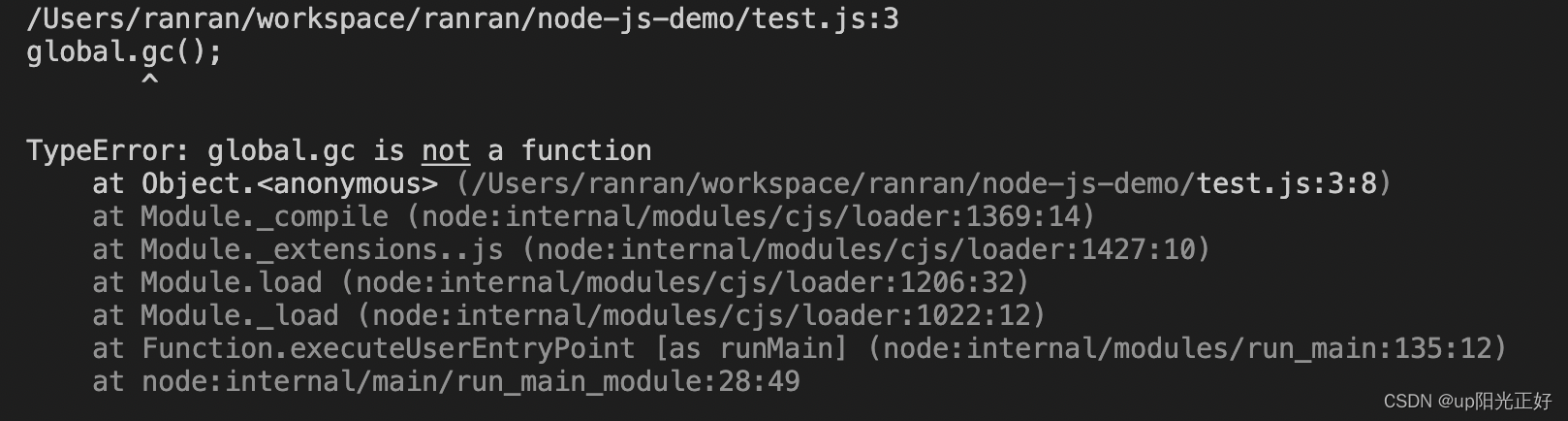
开启GC后,不报错:
Mark-Sweep(标记清除)
Mark-Sweep分为两个阶段:标记和清除。Mark-Sweep在标记阶段遍历(深度优先遍历)堆中的所有对象,并标记活着的对象,然后进入清除阶段。在清除阶段,只清除未被标记的对象。
V8 采取的是黑色和白色来标记数据,垃圾收集之前,会把所有的数据设置为白色,用来标记所有的尚未标记的对象,然后会从 GC 根出发,以深度优先的方式把所有的能访问到的数据都标记为黑色,遍历结束后黑色的就是活的数据,白色的就是可以清理的垃圾数据。
● 由于标记清除只清除死亡对象,而死亡对象在老生代中占用的比例很小,所以效率较高
● 标记清除有一个问题就是进行一次标记清除后,内存空间往往是不连续的,会出现很多的内存碎片。如果后续需要分配一个需要内存空间较多的对象时,如果所有的内存碎片都不够用,就会出现内存溢出的问题

Mark-Compact(标记压缩)
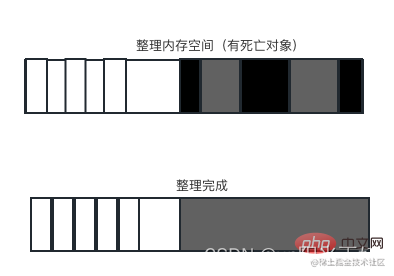
Mark-Compact是为了解决内存碎片的问题,标记压缩是在标记清除的基础上进行修改,将其清除的阶段变为紧缩极端。在整理的过程中,将活着的对象像内存的一端移动,移动完成后,直接清理掉边界外的内存。V8也会根据一定的逻辑,释放一定空闲的内存还给系统。
● 由于在紧缩过程中涉及对象的移动,所以效率并不是太好
● 但是能保证不会生成内存碎片,一般10次标记清除会伴随一次标记压缩
V8新老分区大小
老生代区分
在v12.x之前,为了保证 GC 的执行时间保持在一定范围内,V8 限制了最大内存空间,设置了一个默认老生代内存最大值,64位系统中为大约1.4G,32位为大约700M,超出会导致应用崩溃。
如果想加大内存,可以使用 --max-old-space-size 设置最大内存(单位:MB)
node --max_old_space_size=2048 test.js
如果设置的太小,会触发OOM(out of memory)
在Node版本v12.x之后,V8 将根据可用内存分配老生代大小,也可以说是堆内存大小,所以并没有限制堆内存大小。以前的限制逻辑,其实不合理,限制了 V8 的能力,总不能因为 GC 过程消耗的时间更长,就不让我继续运行程序吧,后续的版本也对 GC 做了更多优化,内存越来越大也是发展需要。
如果想要做限制,依然可以使用 --max-old-space-size 配置, v12 以后它的默认值是0,代表不限制。
新生代区分
新生代中的一个 semi-space 大小 64位系统的默认值是16M,32位系统是8M,因为有2个 semi-space,所以总大小是32M、16M。
可以使用–max-semi-space-size 设置新生代 semi-space 最大值,单位为MB。
此空间不是越大越好,空间越大扫描的时间就越长。这个分区大部分情况下是不需要做修改的,除非针对具体的业务场景做优化,谨慎使用。
查看使用的V8引擎版本
n可以管理多个node版本,可以使用指定的node版本执行代码
n use 11.10.0 test.js
n use 20.12.1 test.js

内存指标
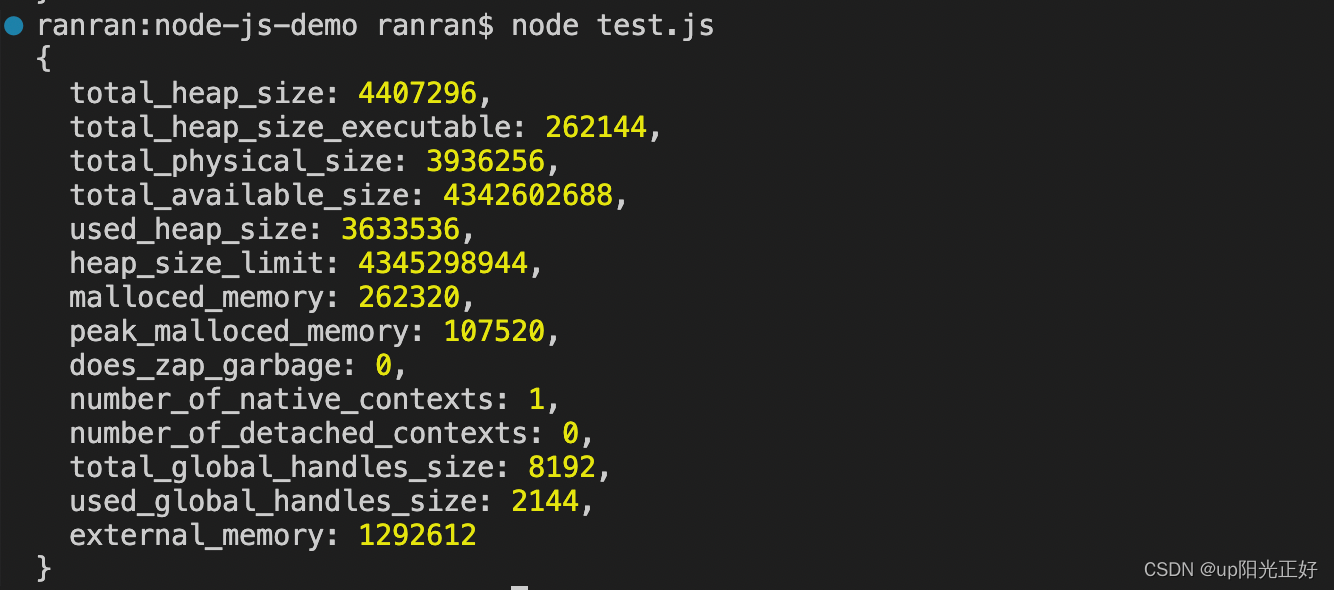
v8.getHeapStatistics()
查看 v8 堆内存信息,查询最大堆内存 heap_size_limit
// 查看堆空间的统计信息,单位是B字节
const v8 = require('v8');
function printHeapSpaceStats() {
const heapStats = v8.getHeapStatistics();
console.log(heapStats);
}
printHeapSpaceStats();
● total_heap_size:V8 引擎可以为堆内存分配的总大小。
● total_heap_size_executable:V8 引擎可以为堆内存分配的可执行代码的大小。
● total_physical_size:当前堆内存的物理占用大小(包括空闲区域)。
● total_available_size:V8 引擎能够分配的内存大小。
● used_heap_size:V8 引擎当前使用的堆内存大小。
● heap_size_limit:V8 引擎能够分配的最大内存大小。
不同版本node下,堆内存大小不同:
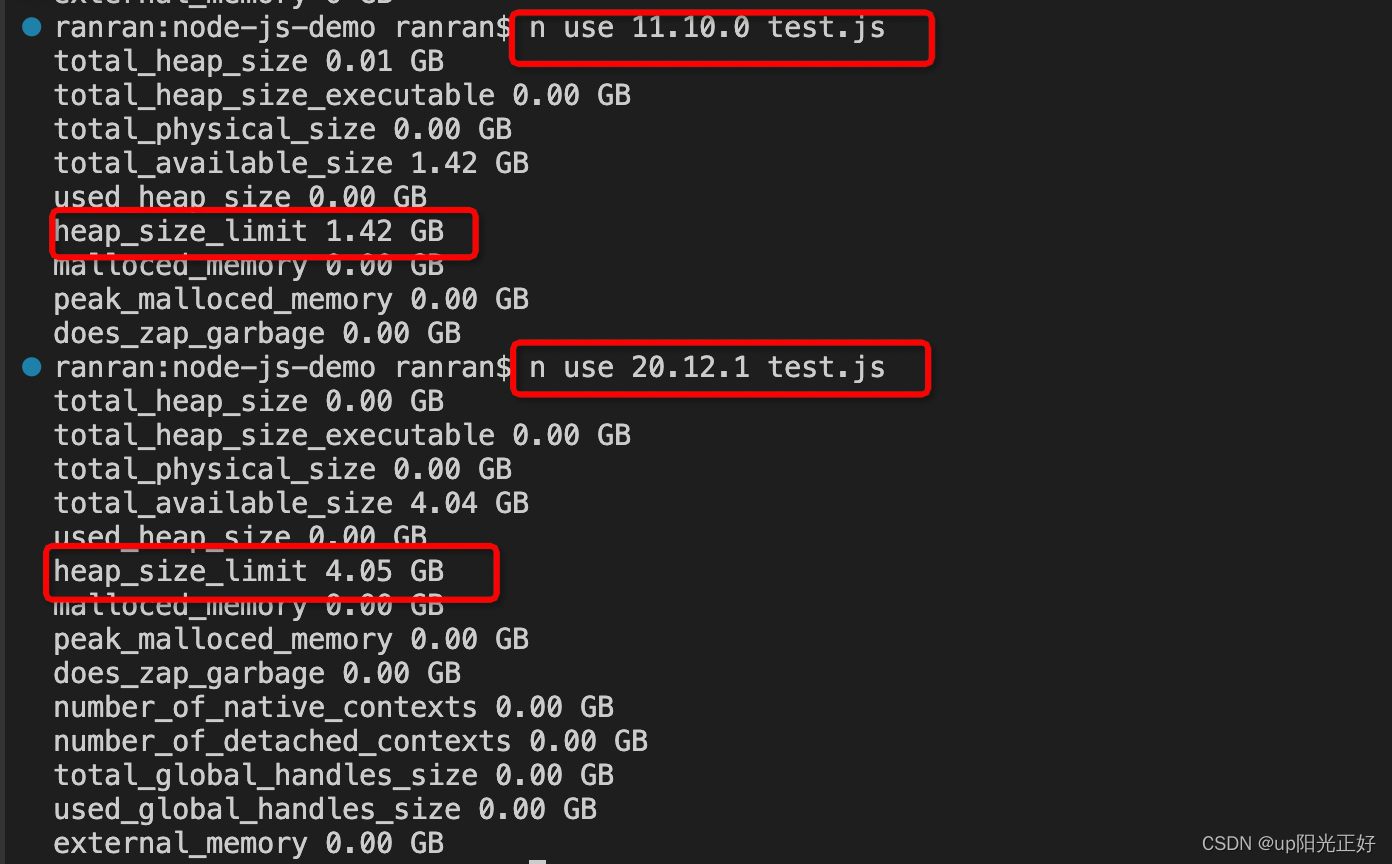
大部分情况下 heap_size_limit 的默认值是系统内存的一半。但是如果超过这个值且系统空间足够,V8 还是会申请更多空间。
process.memoryUsage()
可以查看内存使用情况。除此之外,os模块中的totalmem()和freemem()方法也可以查看内存使用情况。
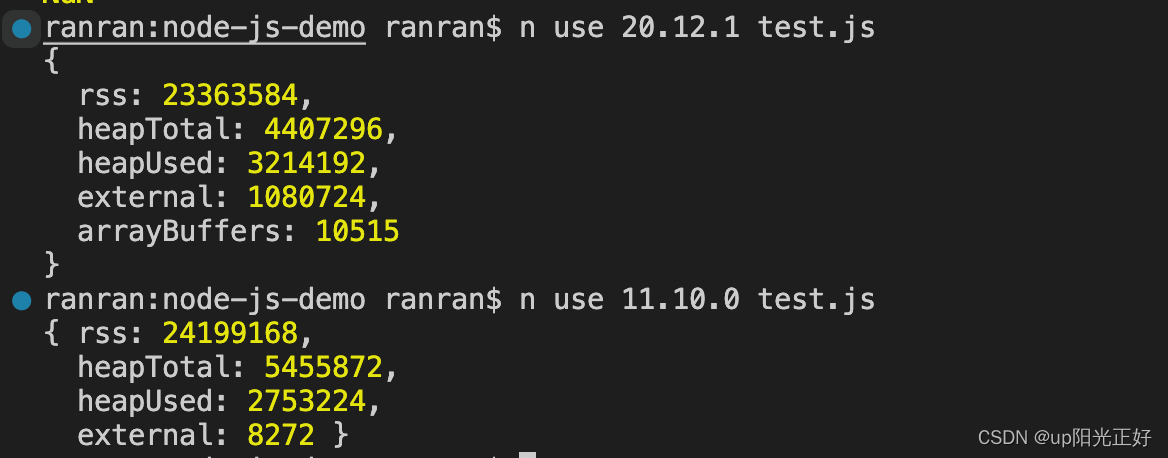
rss是resident set size的缩写,即进程的常驻内存部分。进程的内存总共有几部分,一部分是rss,其余部分在交换区(swap)或者文件系统(filesystem)中。
heapTotal和heapUsed对应的是v8的堆内存信息,heapTotal是堆中总共申请的内存量,heapUsed表示目前堆中使用中的内存量,单位都是字节。
开启打印GC事件
import os from 'node:os';
let len = 1_000_000;
const entries = new Set();
function addEntry() {
const entry = {
timestamp: Date.now(),
memory: os.freemem(),
totalMemory: os.totalmem(),
uptime: os.uptime()
};
entries.add(entry);
}
function summary() {
console.log(`Total: ${entries.size} entries`);
}
// execution
(() => {
while (len > 0) {
addEntry();
process.stdout.write(`~~> ${len} entries to record\r`);
len--;
}
summary();
})();
开启打印GC事件:
node --expose-gc script.mjs
打印堆空间的详细情况:
node --trace_gc_verbose script.mjs
每次GC事件的详细信息,GC类型,各种时间消耗,内存变化等
node --trace_gc_nvp script.mjs
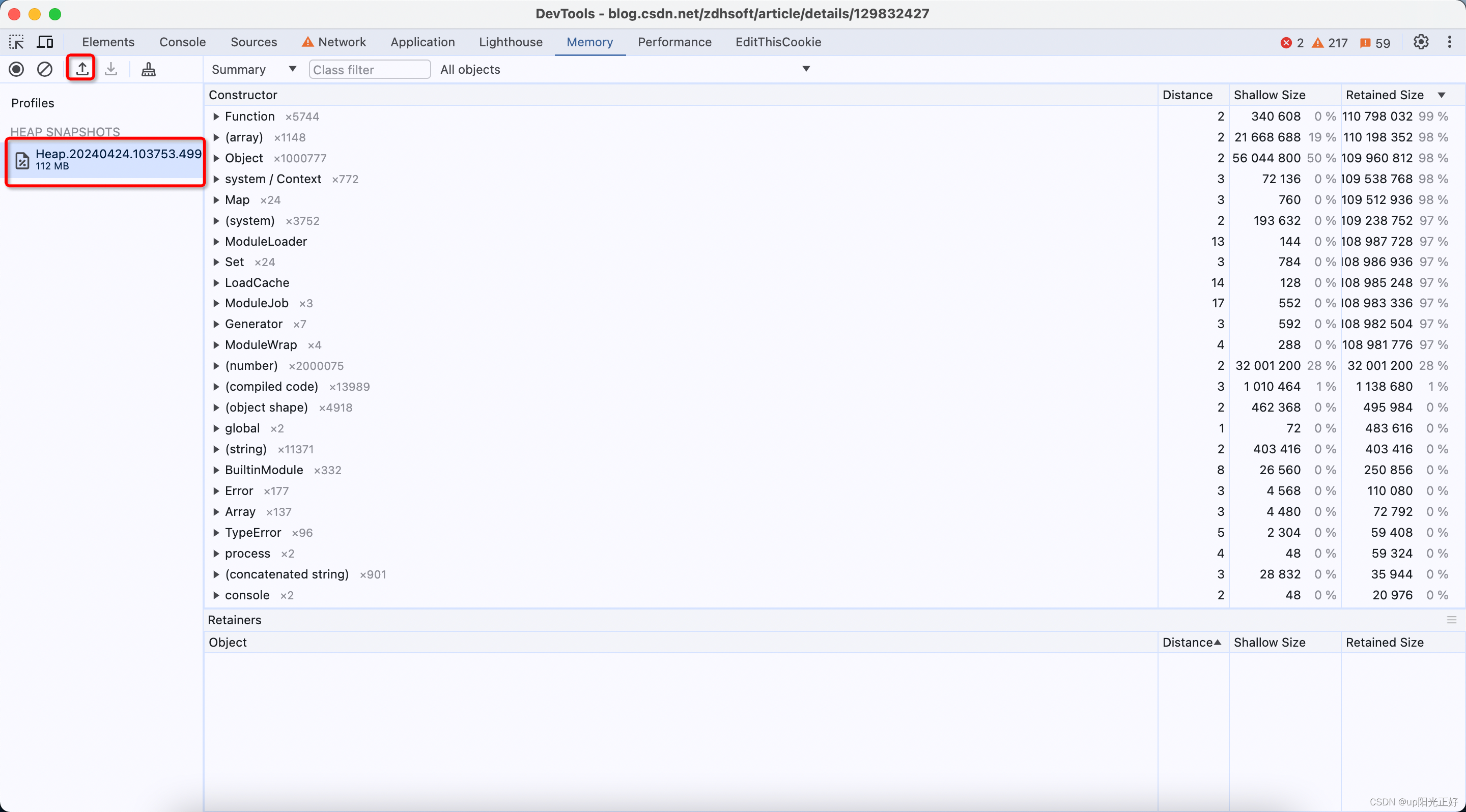
内存快照
const { writeHeapSnapshot } = require('node:v8');
v8.writeHeapSnapshot()
打印快照,将会STW,服务停止响应,内存占用越大,时间越长。此方法本身就比较费时间,所以生成的过程预期不要太高,耐心等待。
此 API 会生成一个 .heapsnapshot 后缀快照文件,可以使用 Chrome 调试器的“内存”功能,导入快照文件,查看堆内存具体的对象数和大小,以及到GC根结点的距离等。也可以对比两个不同时间快照文件的区别,可以看到它们之间的数据量变化。
JS编译
JS是一种解释型的语言,可以在很多地方进行编辑。
浏览器中编译
最初JS在浏览器中运行时,是由JS引擎逐行进行解析和执行的。由于JS代码的普及,浏览器厂商开始将编译作为提高JS性能的手段。许多现代浏览器都将JS代码编译为二进制代码,并进行缓存,以便下次再次使用,这样可以减少解析和编译过程需要的时间,从而加快JS代码的运行速度。
Node.js中编译
Node.js是一种基于Chrome V8引擎的JS运行环境,可以在服务器端运行JS应用程序。Node.js采用与浏览器类似的方式运行JavaScript代码,即JavaScript代码进入Node.js运行时,首先被解析为抽象语法树,然后转换为字节码,最后被编译为机器代码。由于Node.js不像浏览器一样面对浏览器不同的环境,因此它可以开放更多的提高JavaScript性能的方式。
JIT(即时编译)
JIT(即时编译)是一种将字节码或解释的代码直接编译成机器代码的技术。在阅读JavaScript代码时,JIT编译器可能会发现代码中的热点,然后对这些热点进行编译,以使其更快地执行。由于JIT编译器可以在运行时不断改进编译过程,因此,它的性能甚至可以超过一些事先编译的语言。
预编译
预编译会在生产环境之前将JS代码静态地编译到一种与JavaScript本身不同的语言中。这样做的优点是可以减少应用程序再次运行时所需的解析和编译时间,但是缺点是它需要额外的步骤,因此可能会增加开发时间和复杂性。