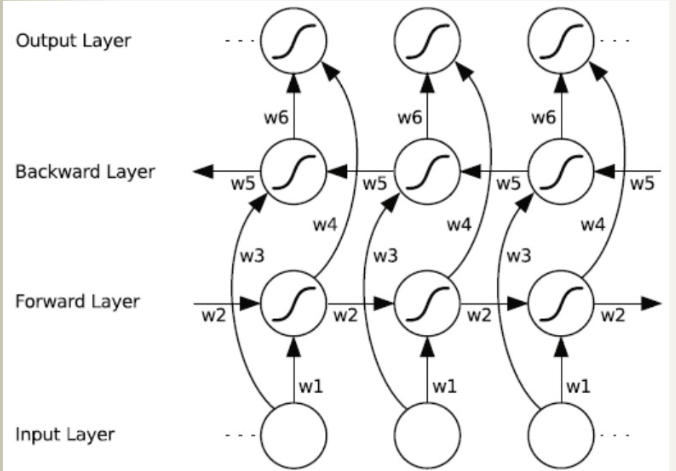
单任务/单领域模型
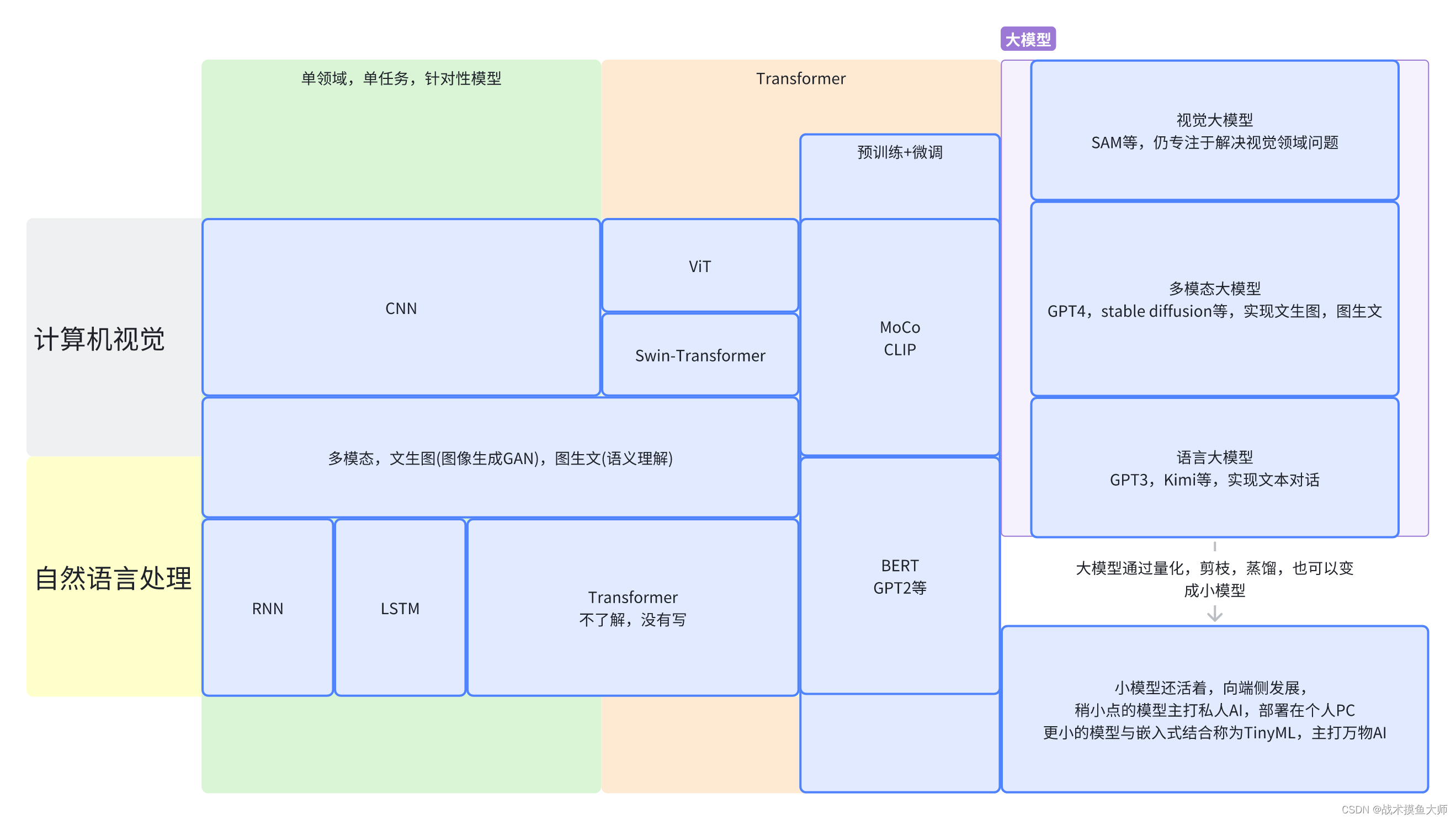
深度学习最早的研究集中在针对单个领域或者单个任务设计相应的模型。
对于CV计算机视觉领域,最常用的模型是CNN卷积模型。其中针对计算机视觉中的不同具体任务例如分类任务,目标检测任务,图像分割任务,以CNN作为骨干backbone,加上不同的前后处理以及一些辅助层,来达到针对不同任务的更好效果。
对于NLP自然语言处理领域,最常用的模型起初是RNN,后续发展有LSTM,Transformer等。这个方向了解不多,具体自行百度。
Transformer:统一架构
Transformer起源于NLP领域,后面人们发现在CV领域Transformer也能用,甚至效果比CNN还要好,使得CV和NLP两个领域的模型架构得到统一,为多模态和大模型打下基础。
Transformer最广为人知的就是它的自注意力机制,要了解为什么创新出了这个机制,还要从RNN谈起。
在NLP领域,第一代模型范式就是RNN,循环神经网络。循环神经网络原理比较简单,RNN中的节点接受两个输入:上个节点的输出以及本次输入对应的词向量:
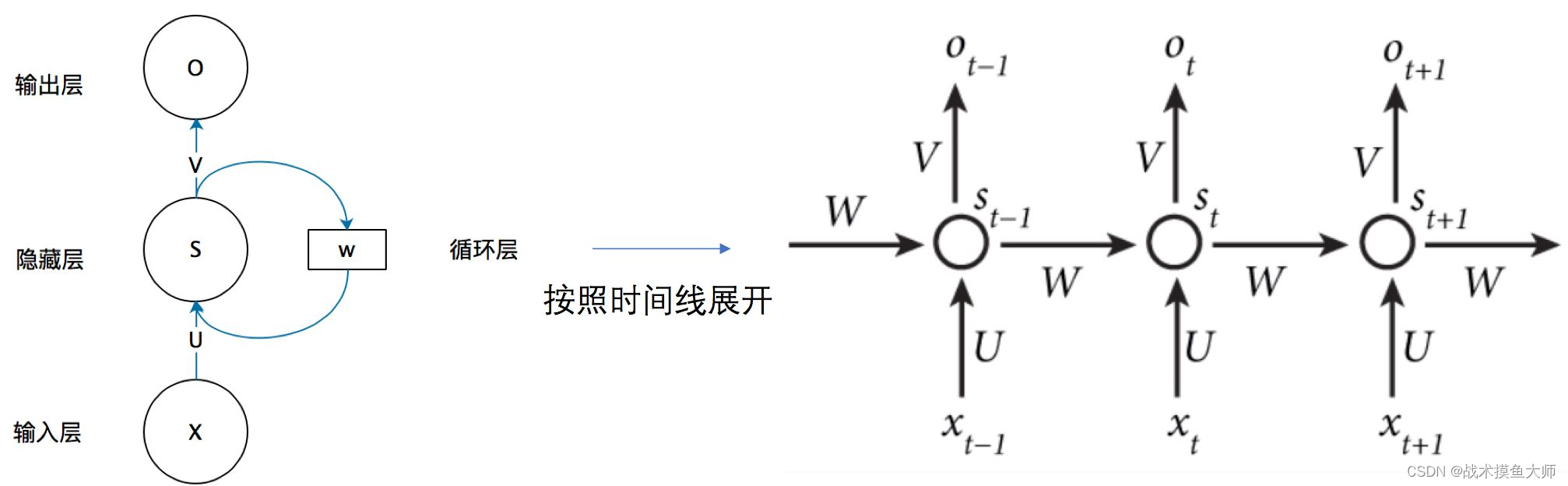
但是RNN缺点也很明显,不断地将输出再次输入,这种方法虽然可以关联到上文所包含的信息,但是只能关联到附近的上文信息,较远的上文信息对当下影响较小,而且容易出现梯度消失的问题。所以RNN在90年以后就很少用了,取而代之的是它的两个改进:LSTM长短时记忆网络和GRU门控循环网络。
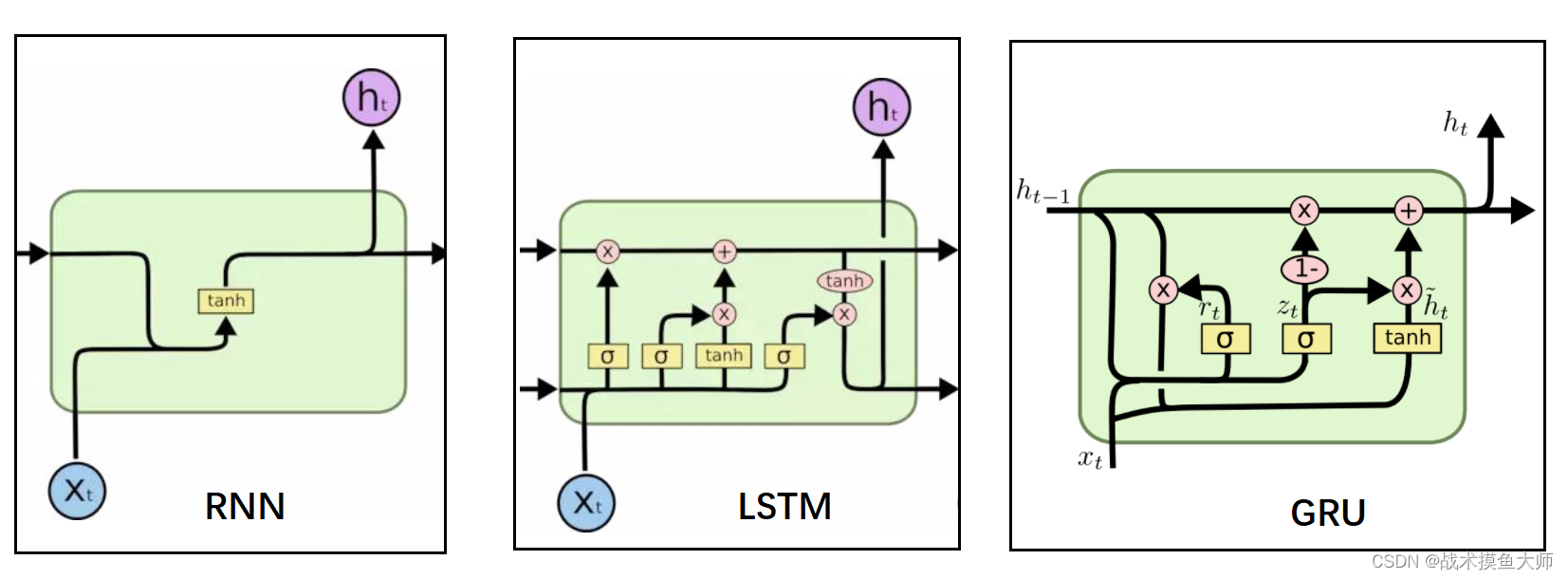
但是二者也只是缓解了RNN的问题,并没有从根本上解决,后面又推出了seq2seq结构,依旧是缝缝补补。再后面计算机视觉中90年代提出的注意力机制,被Google mind团队应用在RNN上来做图像分类后,有学者把注意力机制从CV领域拿到了NLP领域来做机器翻译,Attention-based RNN。在这之后才到transformer的兴起,也就是那句“Attention is all your need”。

transformer简而言之即:将输入向量化,然后通过encoder编码层编码,再经过decoder解码层进行解码得到结果。
encoder的作用是理解和提取输入文本中的相关信息以及上下文的信息。解码器的任务是解码器则根据编码器的输出和先前生成的部分序列来生成输出序列。
注意,由于解码器需要根据先前生成部分的内容来生成输出序列中的下一部分,所以具有自回归的效果,这是encoder没有的,这个特性后面要提到。
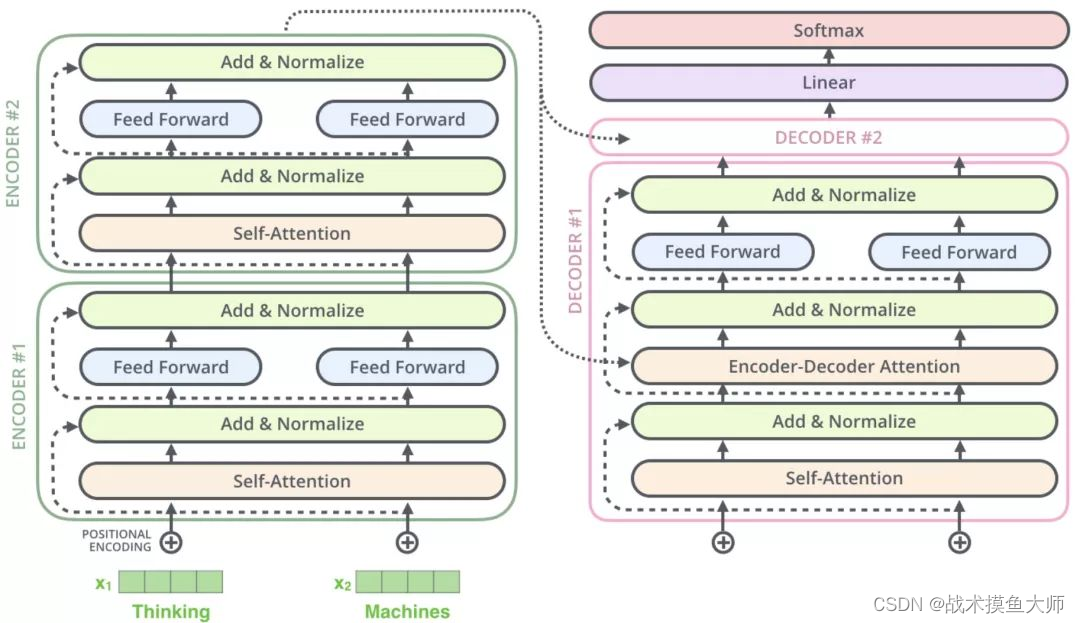
这篇文章写的非常清晰明了,通俗易懂,我就不再班门弄斧了,大家可以直接看这篇文章。
一些细节问题的讲解
ViT:视觉领域的Transformer
Vit李沐大神团队出的讲解非常好:ViT讲解
自注意力和transformer自从提出没多久就有人用在了计算机视觉领域,但是因为如果直接将图像拉长成一个数组,数据复杂度太高,所以提出了stand-alone attention和axial attention等折中方案,分别是将局部窗口输入给transformer和将图像划分为两个维度,分别进行transformer
ViT基本使用了Transformer的原结构,没有什么大的改动。图像数据shape一般都是
C
×
H
×
W
C\times H \times W
C×H×W的,Transformer接受的数据是二维的,所以需要将三维的数据reformat为二维的,原文给出的方法是将图像分为
m
×
n
m\times n
m×n个patch,每个patch的尺寸为
H
m
×
W
n
×
C
\frac{H}{m} \times \frac{W}{n}\times C
mH×nW×C的,将patch拉长为长度为
H
m
×
W
n
×
C
\frac{H}{m} \times \frac{W}{n}\times C
mH×nW×C的一维数组,这样图像就变成了
[
m
×
n
,
H
m
×
W
n
×
C
]
[m \times n,\frac{H}{m} \times \frac{W}{n}\times C]
[m×n,mH×nW×C]的二维数组,原文是将一个224*224的图像分为了
14
×
14
14\times 14
14×14个patch,每个patch的尺寸为
16
×
16
16\times 16
16×16,输入数据为
196
×
768
196\times 768
196×768。从图像到patch的这个过程,可以直接简单分割,也可以使用768个
16
×
16
×
3
16\times 16 \times 3
16×16×3的卷积核提取,得到的结果是是
14
×
14
×
768
14\times 14\times 768
14×14×768的数据,再将其reformat一下得到
196
×
768
196\times 768
196×768。
原文提到Transformer相较于CNN缺少两个归纳偏置,locality和平移等变性
归纳偏置即:从网络结构中就预先存在的偏置,是一种先验知识,所以称为归纳偏置。
locality:潜在的位置信息
平移等变性:f(g(x)) = g(f(x)),先做卷积还是先做平移效果是一样的。
所以要么使用更大的数据集进行训练。
在得到
196
×
768
196\times 768
196×768大小的图像patch序列后,还需要再concat上一个
1
×
768
1\times 768
1×768大小class embedding,用于存储分类结果,形成一个
197
×
768
197\times 768
197×768大小的tensor,再之后还需要添加上一个position embedding,position embedding是一个
197
×
768
197\times 768
197×768的表,直接add到原tensor上,得到最终输入transformer的tensor。
至于ViT的网络结构,跟Transformer是一样的,只不过把Norm层提前到了multi-head attention前面

decoder的作用是进行序列生成,分类的ViT不需要decoder block,只需要encoder即可。
Transformer大模型类型
Transformer的结构是encoder-decoder模式(编码器-解码器)模式,decoder和encoder相比,多了encoder-decoder注意力机制部分,也就是上面transformer架构图中decoder中多的一个环节,将encoder的输出和decoder自注意力输出作为输入的注意力部分。
基于transformer的大模型根据encoder,decoder的搭配不同分为三种技术路线。目前大部分大模型都是decoder-only路线的。
图片来自论文
encoder-only[基本不再使用]
只有encoder的大模型,例子是Bert。
在 Transformer 模型中,编码器负责理解和提取输入文本中的相关信息。这个过程通常涉及到处理文本的序列化形式,例如单词或字符,并且用自注意力机制(Self-Attention)来理解文本中的上下文关系。
encoder-only模型使用MLM(Masked Language Modeling)方法进行训练,即:将语料中的一部分遮住,让模型预测出被遮住的部分,这种训练方式使得encoder-only模型对于文本分类和情感分析这种理解类的任务效果较好。
BERT中还用到了next-sentence prediction task训练方式,该方式主要是训练模型理解上下文语义关系的能力
encoder-decoder[较少使用]
同时有encoder和decoder的大模型,代表作有:T5,清华的GLM(General Language Model Pretraining with Autoregressive Blank Infilling)
因为具有decoderblock部分,所以相较于encoder-only模型,这种模型的文本生成能力要更强一些,比较适合做一些生成序列和输入序列强相关的人物,例如翻译,生成的句子和原句强相关。
encoder-decoder的变体:Prefix-decoder架构
decoder-only[主流]
只有decoder部分的大模型,代表作有:ChatGPT,LLAMA
上文我们提到decoder中有一个部分是编码器-解码器注意力机制部分,那只有decoder,这个部分怎么办呢?
又分为Causal Decoder架构(因果解码器架构)和 Prefix Decoder架构(前缀解码器架构)
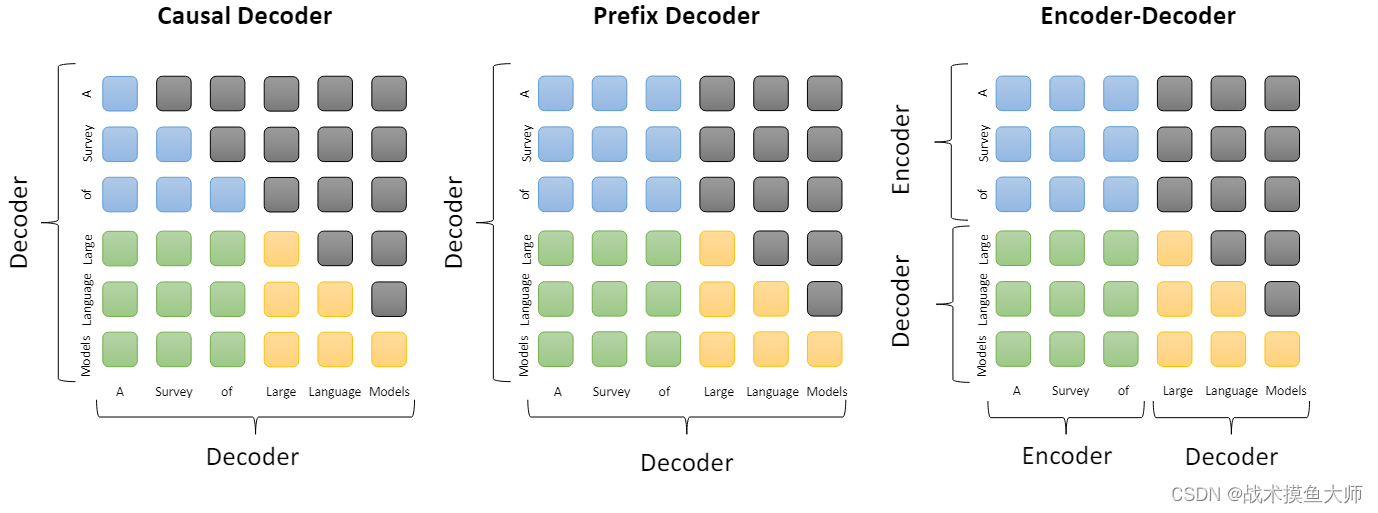
图片来源自论文:A survey of Large Language Models
蓝色是指前缀部分的mask,绿色是前缀和目标token之间的mask,黄色是指目标token之间的mask
简而言之就是表示是否能产生关联,能否读取到该token的信息
不同架构,第一个区别是encoder和decoder组合不同,第二个区别是mask的设计不同。
像对于encoder-decoder架构而言,他的mask可以理解为:encoder的token之间是相互可以关联的,decoder可以关联所有的encoder的token,也可以关联在自己前面的token。
对于causal decoder架构的mask,decoder的token只能关联到前面的token,对于自己后面的token无法产生联系,ChatGPT就是使用这这架构,
Prefix decoder架构跟上面的因果解码器架构相比的特点是将前缀部分的注意力机制改成了双向注意力机制,目标token间还是使用单项token,这就跟encoder很像了,实际上这种架构也是有encoder的,只不过和前缀的decoder是公用一套参数的,所以既可以说是deocder-only,也可以说成是encoder-decoder。代表作是GLM。
为什么大家都用decoder-only路线?
以下答案是依据该问题下的答案总结的
- 对于文本生成类任务效果比较好
- 相较于encoder-decoder路线,计算量小
- decoder-only的泛化性能更好,依据论文原因有很多
- 双向attention[也就是不进行mask,当下token可以接受到所有token的影响]有可能导致低秩问题,反而削弱了模型的表达能力。
- decoder-only模型接受到的信息更少,训练难度更高,在数据充足时,经过训练,可以有更好的表征信息。
- decoder-only的架构相比encoder-decoder在In-Context的学习上会更有优势,因为前者的prompt可以更加直接地作用于decoder每一层的参数,微调信号更强。依据
配套技术
归一化
早期:LayerNorm
为了提高LN的训练速度,提出了RMSNorm
为了稳定深度transformer模型训练,提出了DeepNorm
三种归一化位置方案:post-LN,pre-LN,sandwich-LN
优化器
常用优化器为Adam 优化器和 AdamW 优化器
微调技术
指令微调(instruction tuning)和对齐微调(alignment tuning)。前一种方法旨在增强(或解锁) LLM 的能力,而后一种方法旨在将 LLM 的行为与人类的价 值观或偏好对齐。
上下文学习ICL
为了使大模型能够在不进行梯度更新的情况下完成新的任务。
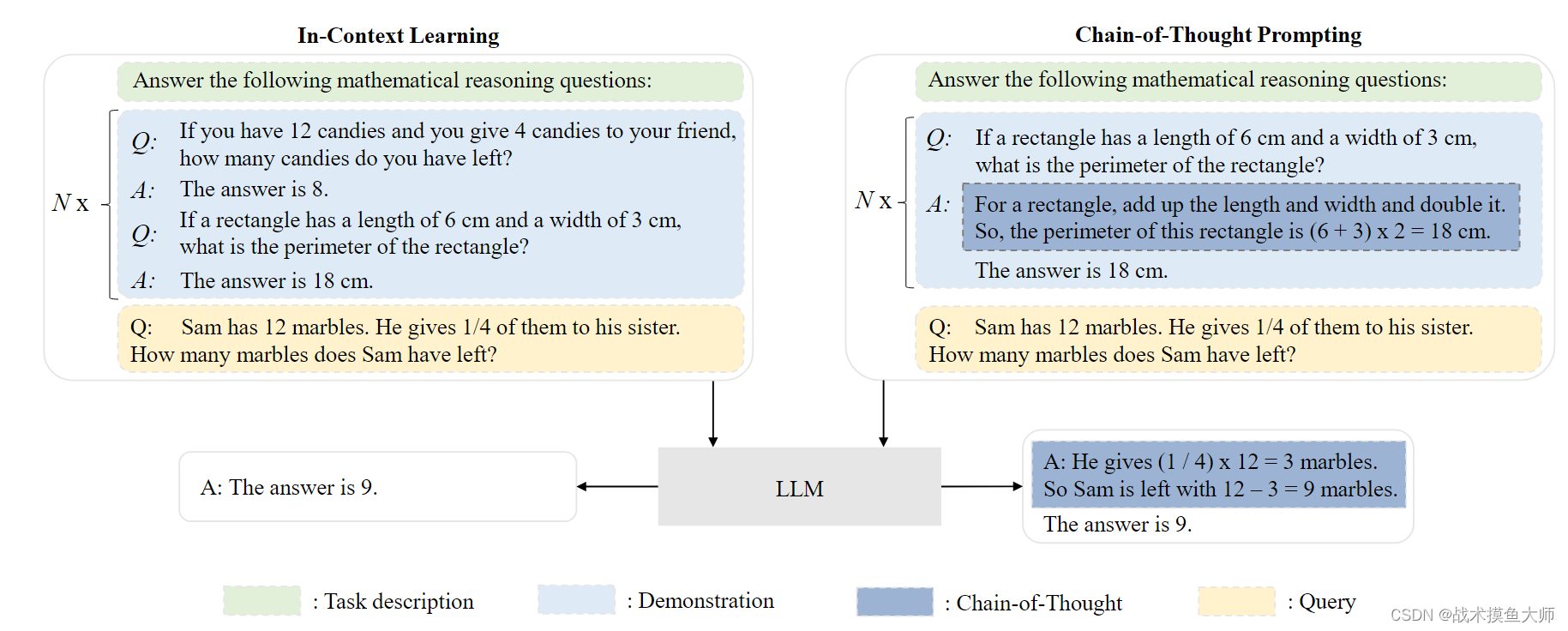
思维链CoT技术
思维链(Chain-of-Thought,CoT)是一种改进的提示策略,旨在提高 LLM 在复杂推理任务中的性能,例如算术推理,常识推理和符号推理。不同于 ICL 中仅使用输入输出对来构造提示,CoT 将可以导出最终输出 的中间推理步骤纳入提示中。通常情况下,CoT 可以在小样本(few-shot)和零样本(zero[1]shot)设置这两种主要设置下与 ICL 一起使用。
参考文献:
[1] A Survey of Large Language Models[J].
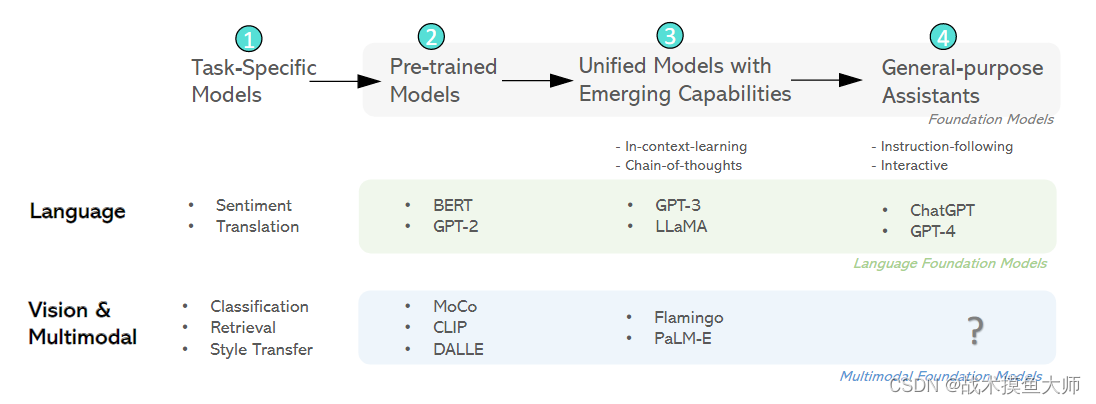
[2] Multimodal Foundation Models: From Specialists to General-Purpose Assistants[J].
[3] https://jalammar.github.io/illustrated-transformer/