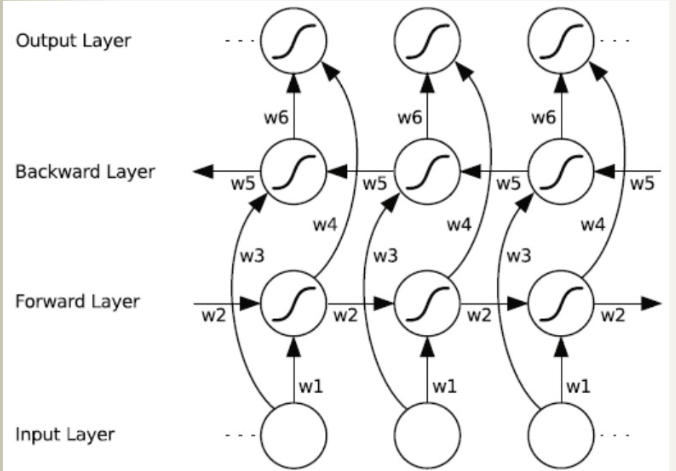
双向RNN和双向LSTM
一、双向循环神经网络BiRNN
1、为什么要用BiRNN
双向RNN,即可以从过去的时间点获取记忆,又可以从未来的时间点获取信息,也就是说具有以下两个特点:
捕捉前后文信息:传统的单向 RNN 只能利用先前的上下文信息,而 BiRNN 同时利用了输入序列的前后文信息。在很多任务中,如自然语言处理中的命名实体识别、机器翻译等,理解一个词的前后文语境至关重要。
例如:
判断句子中Teddy是否是人名,如果只从前面两个词是无法得知Teddy是否是人名,如果能有后面的信息就很好判断了,这就需要用的双向循环神经网络。
提高精度:在处理某些序列数据时,单向 RNN 可能无法充分捕捉整个序列中的重要信息,导致性能欠佳。BiRNN 能够通过双向处理,提高模型的表达能力和准确度。
2、BiRNN的架构
双向循环神经网络(BRNN)的基本思想是提出每一个训练序列向前和向后分别是两个循环神经网络(RNN),而且这两个都连接着一个输出层。这个结构提供给输出层输入序列中每一个点的完整的过去和未来的上下文信息。下图展示的是一个沿着时间展开的双向循环神经网络。六个独特的权值在每一个时步被重复的利用,六个权值分别对应:输入到向前和向后隐含层(w1, w3),隐含层到隐含层自己(w2, w5),向前和向后隐含层到输出层(w4, w6)。值得注意的是:向前和向后隐含层之间没有信息流,这保证了展开图是非循环的。每一个输出都是综合考虑两个方向获得的结果再输出,如下图所示:
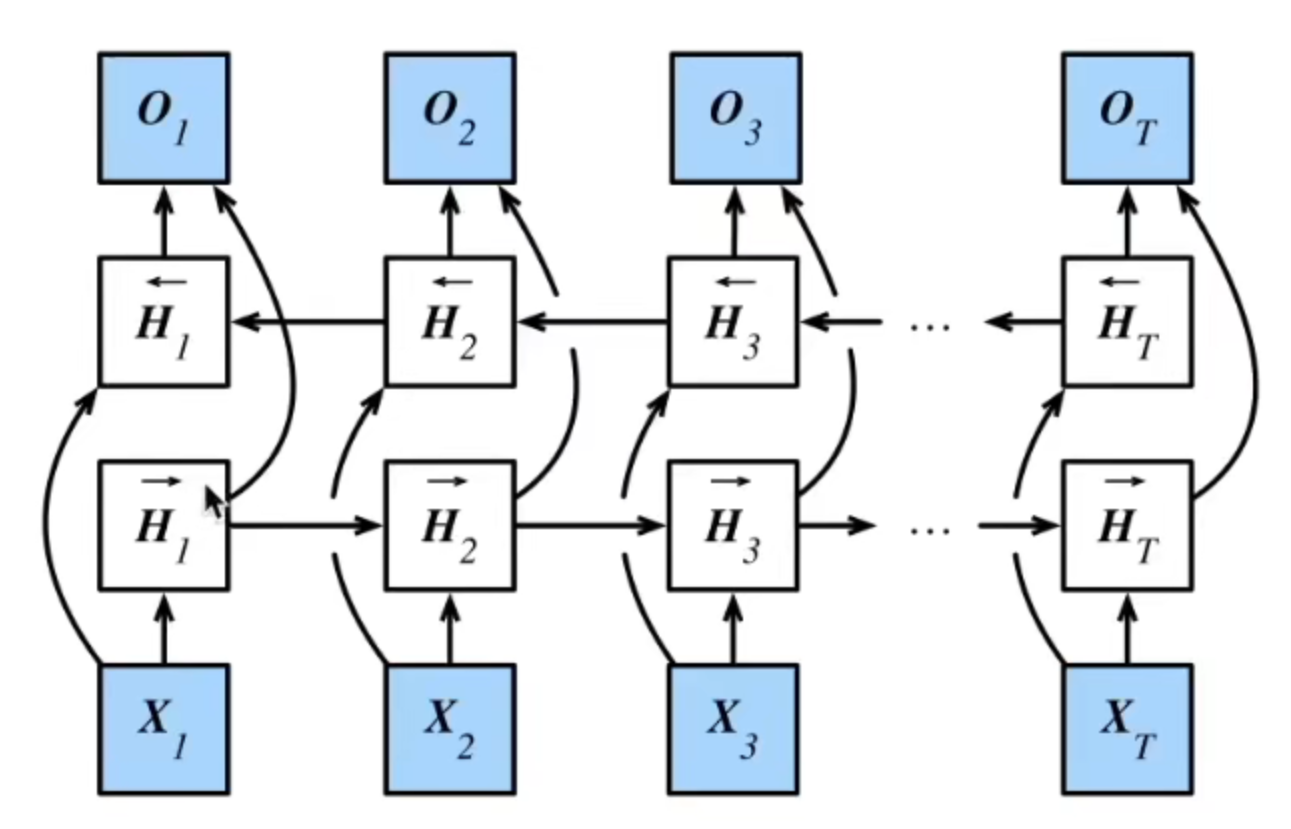
H
→
t
=
ϕ
(
X
t
W
x
h
(
f
)
+
H
→
t
−
1
W
h
h
(
f
)
+
b
h
(
f
)
)
,
H
←
t
=
ϕ
(
X
t
W
x
h
(
b
)
+
H
←
t
+
1
W
h
h
(
b
)
+
b
h
(
b
)
)
,
\begin{array}{l} \overrightarrow{\mathbf{H}}_{t}=\phi\left(\mathbf{X}_{t} \mathbf{W}_{x h}^{(f)}+\overrightarrow{\mathbf{H}}_{t-1} \mathbf{W}_{h h}^{(f)}+\mathbf{b}_{h}^{(f)}\right), \\ \overleftarrow{\mathbf{H}}_{t}=\phi\left(\mathbf{X}_{t} \mathbf{W}_{x h}^{(b)}+\overleftarrow{\mathbf{H}}_{t+1} \mathbf{W}_{h h}^{(b)}+\mathbf{b}_{h}^{(b)}\right), \end{array}
Ht=ϕ(XtWxh(f)+Ht−1Whh(f)+bh(f)),Ht=ϕ(XtWxh(b)+Ht+1Whh(b)+bh(b)),
拼接得到结果:
H
t
=
[
H
→
t
H
←
t
]
\mathbf{H}_{t}=\left[\overrightarrow{\mathbf{H}}_{t} \overleftarrow{\mathbf{H}}_{t}\right]
Ht=[HtHt]
至于网络单元到底是标准的RNN还是GRU或者是LSTM是没有关系的
(GRU:把遗忘门和输入门合并成一个更新门(Update Gate),并且把Cell State和Hidden State也合并成一个Hidden State,它的计算如下图所示)
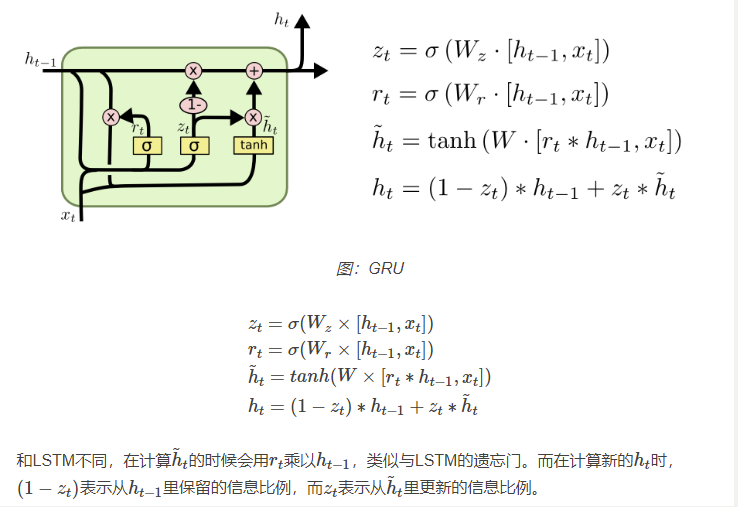
对于整个双向循环神经网络(BRNN)的计算过程如下:
向前推算(Forward pass):
对于双向循环神经网络(BRNN)的隐含层,向前推算跟单向的循环神经网络(RNN)一样,除了输入序列对于两个隐含层是相反方向的,输出层直到两个隐含层处理完所有的全部输入序列才更新:

向后推算(Backward pass):
双向循环神经网络(BRNN)的向后推算与标准的循环神经网络(RNN)通过时间反向传播相似,除了所有的输出层δ项首先被计算,然后返回给两个不同方向的隐含层:

3、代码(用IMDB进行情感分析)
import pandas as pd
import torch
import torch.nn as nn
import torch.optim as optim
from sklearn.model_selection import train_test_split
from torch.utils.data import Dataset, DataLoader
import spacy
from torchtext.vocab import GloVe
# 加载数据集
base_csv = r'E:\kaggle\情感分析\archive (1)\IMDB Dataset.csv'
df = pd.read_csv(base_csv)
# 分割数据集
train_data, test_data = train_test_split(df, test_size=0.2, random_state=42)
# 保存为CSV文件
train_data.to_csv('train.csv', index=False)
test_data.to_csv('test.csv', index=False)
# 加载Spacy分词器
spacy_en = spacy.load('en_core_web_sm')
tokenizer = spacy_en.tokenizer
class TextDataset(Dataset):
def __init__(self, dataframe, text_field, label_field, vocab):
self.dataframe = dataframe
self.text_field = text_field
self.label_field = label_field
self.vocab = vocab
def __len__(self):
return len(self.dataframe)
def __getitem__(self, idx):
text = self.dataframe.iloc[idx][self.text_field]
label = self.dataframe.iloc[idx][self.label_field]
tokens = tokenizer(text)
token_ids = [self.vocab.get(token.text, self.vocab['<unk>']) for token in tokens]
label = 1 if label == "positive" else 0
return torch.tensor(token_ids, dtype=torch.long), torch.tensor(label, dtype=torch.long)
# 加载预训练词向量
glove_embeddings = GloVe(name='6B', dim=100)
vocab = glove_embeddings.stoi
vocab['<unk>'] = len(vocab) # 添加 <unk> 标记
glove_embeddings.vectors = torch.cat((glove_embeddings.vectors, torch.zeros(1, glove_embeddings.dim)), 0)
# 创建数据集
train_dataset = TextDataset(train_data, 'review', 'sentiment', vocab)
test_dataset = TextDataset(test_data, 'review', 'sentiment', vocab)
# 创建数据加载器
batch_size = 32
def collate_fn(batch):
texts, labels = zip(*batch)
text_lengths = [len(text) for text in texts]
padded_texts = nn.utils.rnn.pad_sequence(texts, batch_first=True, padding_value=0)
return padded_texts, torch.tensor(labels, dtype=torch.long)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, collate_fn=collate_fn)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False, collate_fn=collate_fn)
# 定义模型
class BiRNN(nn.Module):
def __init__(self, vocab_size, embed_size, hidden_size, num_layers, num_classes, pad_idx):
super(BiRNN, self).__init__()
self.hidden_size = hidden_size
self.num_layers = num_layers
self.num_directions = 2
self.embedding = nn.Embedding(vocab_size, embed_size, padding_idx=pad_idx)
self.rnn = nn.GRU(embed_size, hidden_size, num_layers, batch_first=True, bidirectional=True)
self.fc = nn.Linear(hidden_size * self.num_directions, num_classes)
def forward(self, x):
h0 = torch.zeros(self.num_layers * self.num_directions, x.size(0), self.hidden_size).to(x.device)
x = self.embedding(x)
out, _ = self.rnn(x, h0)
out = self.fc(out[:, -1, :])
return out
# 设置参数
vocab_size = len(vocab)
embed_size = 100
hidden_size = 256
num_layers = 2
num_classes = 2
pad_idx = 0
model = BiRNN(vocab_size, embed_size, hidden_size, num_layers, num_classes, pad_idx)
model.embedding.weight.data.copy_(glove_embeddings.vectors)
model.embedding.weight.data[pad_idx] = torch.zeros(embed_size)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = model.to(device)
criterion = criterion.to(device)
# 训练模型
num_epochs = 5
for epoch in range(num_epochs):
model.train()
epoch_loss = 0
for texts, labels in train_loader:
texts = texts.to(device)
labels = labels.to(device)
optimizer.zero_grad()
outputs = model(texts)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
epoch_loss += loss.item()
print(f'Epoch {epoch + 1}/{num_epochs}, Loss: {epoch_loss / len(train_loader):.4f}')
# 评估模型
model.eval()
with torch.no_grad():
correct = 0
total = 0
for texts, labels in test_loader:
texts = texts.to(device)
labels = labels.to(device)
outputs = model(texts)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
accuracy = correct / total
print(f'Accuracy: {accuracy * 100:.2f}%')
# 保存模型
torch.save(model.state_dict(), 'model.ckpt')
# 预测函数
def predict(text, model, vocab, device):
model.eval()
tokens = tokenizer(text)
token_ids = [vocab.get(token.text, vocab['<unk>']) for token in tokens]
token_tensor = torch.tensor(token_ids, dtype=torch.long).unsqueeze(0).to(device)
with torch.no_grad():
output = model(token_tensor)
_, predicted = torch.max(output.data, 1)
return 'positive' if predicted.item() == 1 else 'negative'
# 示例使用
sample_text = "This movie was fantastic! I really enjoyed it."
prediction = predict(sample_text, model, vocab, device)
print(f'Prediction: {prediction}')
4、多层RNN
将许多RNN层堆叠,构成一个多层RNN网络。RNN每读取一个新的
x
t
\mathrm{x}_{\mathrm{t}}
xt输就会生成状态向量
h
t
\mathrm{h}_{\mathrm{t}}
ht作为当前时刻的输出和下一时刻的输入状态。 将T 个输入
x
0
∼
x
T
\mathrm{x}_{0} \sim \mathrm{x}_{\mathrm{T}}
x0∼xT 依次输入RNN,相应地会产生个输出。第一层RNN输出的T TT个状态向量可以作为第二层RNN的输入,第二层RNN拥有独立的参数,依次读取T个来自第一层RNN的状态向量,产生T个新的输出。第二层RNN输出的T个状态向量可以作为第三层RNN的输入,依此类推,构成一个多层RNN网络。
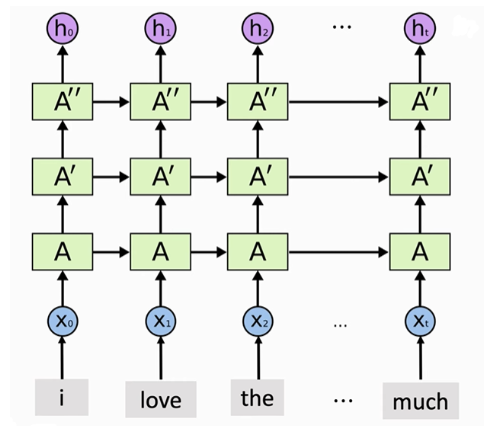
RNN自带层数和是否双向,只要把层数设置成你想要的层数就可以
class RNN(nn.Module):
def __init__(self,vocab_size, embedding_dim, hidden_size, num_classes, num_layers,bidirectional):
super(RNN, self).__init__()
self.vocab_size = vocab_size
self.embedding_dim = embedding_dim
self.hidden_size = hidden_size
self.num_classes = num_classes
self.num_layers = num_layers
self.embedding = nn.Embedding(self.vocab_size, embedding_dim, padding_idx=word2idx['<PAD>'])
# 这里用了torch的embeding函数
self.rnn = nn.RNN(input_size=self.embedding_dim, hidden_size=self.hidden_size,batch_first=True,num_layers=self.num_layers)
# input_size:表示输入 xt 的特征维度,从embeding层的size
# hidden_size:表示输出的特征维度
# num_layers:表示网络的层数
# nonlinearity:表示选用的非线性激活函数,默认是 ‘tanh’
# bias:表示是否使用偏置,默认使用
# batch_first:表示输入数据的形式,默认是 False,就是这样形式,(seq, batch, feature),也就是将序列长度放在第一位,batch 放在第二位
# dropout:表示是否在输出层应用(随机丢掉一些特征,重要的调参)
# bidirectional:表示是否使用双向的 rnn,默认是 False。
def forward(self, x):
batch_size, seq_len = x.shape
h0 = torch.randn(self.num_layers, batch_size, self.hidden_size).to(device)
#初始化一个h0,也即c0,在RNN中一个Cell输出的ht和Ct是相同的,而LSTM的一个cell输出的ht和Ct是不同的
#维度[layers, batch, hidden_len]
x = self.embedding(x) # 这里用的是nn的embeding
out,_ = self.rnn(x, h0) # 输入x,h0是初始化的特征,
output = self.fc(out[:,-1,:]).squeeze(0) #因为有max_seq_len个时态,所以取最后一个时态即-1层
return output
二、双向LSTM----Bi-LSTM
BiLSTM无非就是把cell变成了LSTM的基本单元,其他同理如上所示
需要修改的内容:
- 替换RNN层为LSTM层:将
nn.RNN替换为nn.LSTM。 - 设置双向LSTM:将LSTM层的
bidirectional参数设置为True。 - 修改隐藏状态的初始化:LSTM的隐藏状态包含两个张量(隐藏状态和细胞状态),因此需要初始化这两个张量。
- 处理双向LSTM的输出:双向LSTM的输出维度会加倍(因为有两个方向)
class RNN(nn.Module):
def __init__(self, vocab_size, embedding_dim, hidden_size, num_classes, num_layers, bidirectional):
super(RNN, self).__init__()
self.vocab_size = vocab_size
self.embedding_dim = embedding_dim
self.hidden_size = hidden_size
self.num_classes = num_classes
self.num_layers = num_layers
self.bidirectional = bidirectional
self.num_directions = 2 if bidirectional else 1
self.embedding = nn.Embedding(self.vocab_size, embedding_dim, padding_idx=word2idx['<PAD>'])
self.lstm = nn.LSTM(input_size=self.embedding_dim,
hidden_size=self.hidden_size,
num_layers=self.num_layers,
bidirectional=self.bidirectional,
batch_first=True)#替换了原来的nn.RNN层,使其变为LSTM,并添加了双向参数
# 全连接层的输入大小需要考虑双向LSTM的输出维度
self.fc = nn.Linear(self.hidden_size * self.num_directions, self.num_classes)
def forward(self, x):
batch_size, seq_len = x.shape
# 初始化隐藏状态和细胞状态,双向LSTM需要初始化2*num_layers的hidden states
h0 = torch.zeros(self.num_layers * self.num_directions, batch_size, self.hidden_size).to(device)
c0 = torch.zeros(self.num_layers * self.num_directions, batch_size, self.hidden_size).to(device)
x = self.embedding(x) # Embedding layer
# LSTM layer
out, (hn, cn) = self.lstm(x, (h0, c0))
# 取最后一个时间步的输出,双向LSTM会拼接两个方向的输出
output = self.fc(out[:, -1, :])
return output
三、两者异同
双向RNN(Bidirectional Recurrent Neural Network)和双向LSTM(Bidirectional Long Short-Term Memory)都是用于处理序列数据的神经网络模型。它们在处理时间序列、自然语言处理等任务中非常有用,因为它们能够考虑到序列中的前后信息。尽管它们有一些相似之处,但也有一些关键的不同点。
1、相同点
-
双向结构:无论是双向RNN还是双向LSTM,它们都有双向结构,这意味着它们有两个隐藏层,一个从前向后处理序列,另一个从后向前处理序列。这种结构允许模型在每个时间步上同时考虑前面和后面的信息,从而提高预测性能。
-
序列处理:两者都是为序列数据设计的,适用于自然语言处理、时间序列预测等任务。
-
隐层状态的结合:在每个时间步,它们都会结合来自两个方向的隐藏状态(通常是通过连接或求和)来产生输出。
2、不同点
-
基本单元:
- 双向RNN:基本单元是RNN,即简单的循环神经网络。它们依赖于隐藏状态将信息从一个时间步传播到下一个时间步。然而,RNN在处理长序列时容易遇到梯度消失和梯度爆炸问题,这限制了它们捕捉长距离依赖的能力。
- 双向LSTM:基本单元是LSTM,即长短期记忆网络。LSTM通过引入遗忘门、输入门和输出门来控制信息的流动,从而更好地解决了梯度消失和梯度爆炸问题。因此,LSTM在处理长序列时比普通RNN更有效。
-
记忆能力:
- 双向RNN:由于其结构的限制,普通RNN在处理长期依赖关系时表现不佳。它们更适合短期依赖任务。
- 双向LSTM:LSTM单元通过其门控机制能够有效地捕捉和保持长期依赖信息,因此在需要长时间记忆的任务中表现更优。
-
复杂性和计算成本:
- 双向RNN:结构相对简单,计算成本较低。但由于其局限性,可能需要更多层次的堆叠或者更复杂的架构来提升性能。
- 双向LSTM:由于引入了门机制,LSTM单元比RNN单元复杂,计算成本也更高。但其增强的记忆能力通常能带来更好的性能。
参考https://zhuanlan.zhihu.com/p/519965073
https://fancyerii.github.io/books/rnn-intro/
https://www.cnblogs.com/Lee-yl/p/10066531.html