提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
前言
因为课题需要,调研了几个快速排序方法,并手写或者改进了若干待测试对象,包括记分板型冒泡排序(这个是别人的)、插入排序(这个是我写的)、双调排序(这个我改了又改,可能还会接着改进)、堆排序(这个是别人的)。以上都在7035开发板上测试了资源。除了堆排序截了时序图之外,其他几个我就直接给代码,外加资源占用情况和延迟(这个延迟是给定例子的延迟)。不介绍原理了,默认都懂!
书写、修改、调试不易,请大家多多惠存~
一、记分板型冒泡排序
以下是.v
// reference: https://mp.weixin.qq.com/s/BesXJzfle_ZvW__C6DBNrA
module sort_bubble #(parameter BITWIDTH = 8, parameter ELEMENTS = 32)(
input clk ,
input rst ,
input [BITWIDTH*ELEMENTS-1:0] data_in ,
input data_in_valid ,
output [BITWIDTH*ELEMENTS-1:0] data_out ,
output data_out_valid
);
reg [ 5:0] data_in_valid_ff;
reg [BITWIDTH*ELEMENTS-1:0] data_in_ff[5:0] ;
reg v[ELEMENTS-1:0][ELEMENTS-1:0] ;
reg [ 1:0] sum_1[31:0][15:0] ;
reg [ 2:0] sum_2[31:0][7:0] ;
reg [ 3:0] sum_3[31:0][3:0] ;
reg [ 4:0] sum_4[31:0][1:0] ;
reg [ 5:0] sum_5[31:0] ;
reg [BITWIDTH-1:0] data_out_temp[ELEMENTS-1:0] ;
reg data_out_valid_temp;
genvar i;
genvar j;
always @(posedge clk ) begin
if(rst == 1'b1)begin
data_in_valid_ff <= 6'b0;
end
else begin
data_in_valid_ff <= {data_in_valid_ff[4:0], data_in_valid};
end
end
always @(posedge clk ) begin
data_in_ff[0] <= data_in;
end
generate
for ( i = 0; i < 5 ; i = i + 1 ) begin : LOOP_DATA_IN
always @(posedge clk ) begin
data_in_ff[i+1] <= data_in_ff[i];
end
end
endgenerate
generate
for ( i = 0 ; i < 32 ; i = i + 1 ) begin : LOOP_V_I
for ( j = i ; j < 32 ; j = j + 1) begin : LOOP_V_J
always @(posedge clk ) begin
if(data_in_valid == 1'b1)begin
v[i][j] <= data_in[i*8 +: 8] >= data_in[j*8 +: 8]; // 2D Parallel
v[j][i] <= data_in[i*8 +: 8] < data_in[j*8 +: 8]; // 2D Parallel
end
end
end
end
endgenerate
generate
for ( i = 0 ; i < 32 ; i = i + 1 ) begin : LOOP_SUM_1_I
for ( j = 0 ; j < 16 ; j = j + 1) begin : LOOP_SUM_1_J
always @(posedge clk ) begin
if(data_in_valid_ff[0] == 1'b1)begin
sum_1[i][j] <= v[i][j*2] + v[i][j*2 + 1];
end
end
end
end
endgenerate
generate
for ( i = 0 ; i < 32 ; i = i + 1 ) begin : LOOP_SUM_2_I
for ( j = 0 ; j < 8 ; j = j + 1) begin : LOOP_SUM_2_J
always @(posedge clk ) begin
if(data_in_valid_ff[1] == 1'b1)begin
sum_2[i][j] <= sum_1[i][j*2] + sum_1[i][j*2 + 1];
end
end
end
end
endgenerate
generate
for ( i = 0 ; i < 32 ; i = i + 1 ) begin : LOOP_SUM_3_I
for ( j = 0 ; j < 4 ; j = j + 1) begin : LOOP_SUM_3_J
always @(posedge clk ) begin
if(data_in_valid_ff[2] == 1'b1)begin
sum_3[i][j] <= sum_2[i][j*2] + sum_2[i][j*2 + 1];
end
end
end
end
endgenerate
generate
for ( i = 0 ; i < 32 ; i = i + 1 ) begin : LOOP_SUM_4_I
for ( j = 0 ; j < 2 ; j = j + 1) begin : LOOP_SUM_4_J
always @(posedge clk ) begin
if(data_in_valid_ff[3] == 1'b1)begin
sum_4[i][j] <= sum_3[i][j*2] + sum_3[i][j*2 + 1];
end
end
end
end
endgenerate
generate
for ( i = 0 ; i < 32 ; i = i + 1 ) begin : LOOP_SUM_5_I
always @(posedge clk ) begin
if(data_in_valid_ff[4] == 1'b1)begin
sum_5[i] <= sum_4[i][0] + sum_4[i][1];
end
end
end
endgenerate
always @(posedge clk ) begin : LOOP_DATA_OUT_TEMP_CLK
integer k;
for ( k = 0; k < 32; k = k + 1) begin : LOOP_DATA_OUT_TEMP
if(data_in_valid_ff[5] == 1'b1)begin
data_out_temp[sum_5[k]] <= data_in_ff[5][k*8 +: 8];
data_out_valid_temp <= 1'b1;
end
else begin
data_out_temp[sum_5[k]] <= 8'd0;
data_out_valid_temp <= 1'b0;
end
end
end
generate
for ( i = 0 ; i < 32 ; i = i + 1) begin : LOOP_DATA_OUT
assign data_out[i*8 +: 8] = data_out_temp[i] ;
assign data_out_valid = data_out_valid_temp;
end
endgenerate
endmodule以下是testbench
`timescale 1ns / 1ps
module tb_bubble(
);
reg clk;
reg rst;
reg [7:0] data_in_0;
reg [7:0] data_in_1;
reg [7:0] data_in_2;
reg [7:0] data_in_3;
reg [7:0] data_in_4;
reg [7:0] data_in_5;
reg [7:0] data_in_6;
reg [7:0] data_in_7;
reg [7:0] data_in_8;
reg [7:0] data_in_9;
reg [7:0] data_in_10;
reg [7:0] data_in_11;
reg [7:0] data_in_12;
reg [7:0] data_in_13;
reg [7:0] data_in_14;
reg [7:0] data_in_15;
reg [7:0] data_in_16;
reg [7:0] data_in_17;
reg [7:0] data_in_18;
reg [7:0] data_in_19;
reg [7:0] data_in_20;
reg [7:0] data_in_21;
reg [7:0] data_in_22;
reg [7:0] data_in_23;
reg [7:0] data_in_24;
reg [7:0] data_in_25;
reg [7:0] data_in_26;
reg [7:0] data_in_27;
reg [7:0] data_in_28;
reg [7:0] data_in_29;
reg [7:0] data_in_30;
reg [7:0] data_in_31;
wire [255:0] data_in;
reg data_in_valid;
wire [255:0] data_out;
wire data_out_valid;
initial begin
clk = 1'b0;
rst = 1'b1;
#50
rst = 1'b0;
end
always #5 clk = !clk;
always @(posedge clk ) begin
if(rst == 1'b1)begin
data_in_0 <= 8'd0;
data_in_1 <= 8'd0;
data_in_2 <= 8'd0;
data_in_3 <= 8'd0;
data_in_4 <= 8'd0;
data_in_5 <= 8'd0;
data_in_6 <= 8'd0;
data_in_7 <= 8'd0;
data_in_8 <= 8'd0;
data_in_9 <= 8'd0;
data_in_10 <= 8'd0;
data_in_11 <= 8'd0;
data_in_12 <= 8'd0;
data_in_13 <= 8'd0;
data_in_14 <= 8'd0;
data_in_15 <= 8'd0;
data_in_16 <= 8'd0;
data_in_17 <= 8'd0;
data_in_18 <= 8'd0;
data_in_19 <= 8'd0;
data_in_20 <= 8'd0;
data_in_21 <= 8'd0;
data_in_22 <= 8'd0;
data_in_23 <= 8'd0;
data_in_24 <= 8'd0;
data_in_25 <= 8'd0;
data_in_26 <= 8'd0;
data_in_27 <= 8'd0;
data_in_28 <= 8'd0;
data_in_29 <= 8'd0;
data_in_30 <= 8'd0;
data_in_31 <= 8'd0;
data_in_valid <= 1'b0;
end
else begin
data_in_0 <= {$random} % 255;
data_in_1 <= {$random} % 255;
data_in_2 <= {$random} % 255;
data_in_3 <= {$random} % 255;
data_in_4 <= {$random} % 255;
data_in_5 <= {$random} % 255;
data_in_6 <= {$random} % 255;
data_in_7 <= {$random} % 255;
data_in_8 <= {$random} % 255;
data_in_9 <= {$random} % 255;
data_in_10 <= {$random} % 255;
data_in_11 <= {$random} % 255;
data_in_12 <= {$random} % 255;
data_in_13 <= {$random} % 255;
data_in_14 <= {$random} % 255;
data_in_15 <= {$random} % 255;
data_in_16 <= {$random} % 255;
data_in_17 <= {$random} % 255;
data_in_18 <= {$random} % 255;
data_in_19 <= {$random} % 255;
data_in_20 <= {$random} % 255;
data_in_21 <= {$random} % 255;
data_in_22 <= {$random} % 255;
data_in_23 <= {$random} % 255;
data_in_24 <= {$random} % 255;
data_in_25 <= {$random} % 255;
data_in_26 <= {$random} % 255;
data_in_27 <= {$random} % 255;
data_in_28 <= {$random} % 255;
data_in_29 <= {$random} % 255;
data_in_30 <= {$random} % 255;
data_in_31 <= {$random} % 255;
data_in_valid <= 1'b1;
end
end
assign data_in = {data_in_0, data_in_1, data_in_2, data_in_3, data_in_4, data_in_5, data_in_6, data_in_7, data_in_8, data_in_9, data_in_10, data_in_11, data_in_12, data_in_13, data_in_14, data_in_15,data_in_16, data_in_17, data_in_18, data_in_19, data_in_20, data_in_21, data_in_22, data_in_23,data_in_24, data_in_25, data_in_26, data_in_27, data_in_28, data_in_29, data_in_30, data_in_31};
sort_bubble sort_bubble_u(
.clk (clk ),
.rst (rst ),
.data_in (data_in ),
.data_in_valid (data_in_valid ),
.data_out (data_out ),
.data_out_valid (data_out_valid)
);
endmodule二、插入排序
以下是.v:
module sort_insertion #(parameter BITWIDTH = 8, parameter ELEMENTS = 32)(
input clk,
input rst_n,
input [BITWIDTH*ELEMENTS-1:0] data_in,
output reg [BITWIDTH*ELEMENTS-1:0] data_out
);
reg [7:0] array [0:31];
reg [5:0] i, j;
reg [7:0] key;
// State machine states
reg [2:0] state_c;
reg [2:0] state_n;
parameter IDLE = 3'b000,
SORT = 3'b001,
BREAK= 3'b010,
DONE = 3'b011;
genvar p;
generate
for (p=0; p<32; p=p+1) begin: ASSIGN_FOR_DATA_OUT
always @(posedge clk or negedge rst_n) begin
data_out[p*8 +: 8] <= array[p];
end
end
endgenerate
// State Transfer - First
always @(posedge clk or negedge rst_n) begin
if (!rst_n) begin
state_c <= IDLE;
end
else begin
state_c <= state_n;
end
end
// State Transfer - Second
always @(*) begin
case (state_c)
IDLE: begin
state_n = BREAK;
end
SORT: begin
if (j == 0 || array[j] <= key) state_n = BREAK;
else state_n = state_c;
end
BREAK: begin
if (i > 0 && i < 31) state_n = SORT;
else if (i == 31) state_n = DONE;
else state_n = state_c;
end
default: state_n = DONE;
endcase
end
// State Transfer - Third
always @(posedge clk or negedge rst_n) begin
if (!rst_n) begin i <= 0; j <= 0; key <= 8'd0; end
else if (state_c == SORT) begin
if (j == 0 || array[j] <= key) begin
i <= i; j <= j - 1; key <= array[i]; // 同时跳转到break
end
else begin
i <= i; j <= j - 1; key <= key; // 接着比较
end
end
else if (state_c == BREAK) begin
if ( i <= 30) begin
i <= i + 1; j <= i; key <= array[i+1];
end
else begin
i <= i + 1; j <= 0; key <= 8'd0;
end
end
else begin i <= 0; j <= 0; key <= 8'd0; end
end
always @(posedge clk or negedge rst_n) begin
if (!rst_n) begin
array[0] <= 0;
array[1] <= 0;
array[2] <= 0;
array[3] <= 0;
array[4] <= 0;
array[5] <= 0;
array[6] <= 0;
array[7] <= 0;
array[8] <= 0;
array[9] <= 0;
array[10] <= 0;
array[11] <= 0;
array[12] <= 0;
array[13] <= 0;
array[14] <= 0;
array[15] <= 0;
array[16] <= 0;
array[17] <= 0;
array[18] <= 0;
array[19] <= 0;
array[20] <= 0;
array[21] <= 0;
array[22] <= 0;
array[23] <= 0;
array[24] <= 0;
array[25] <= 0;
array[26] <= 0;
array[27] <= 0;
array[28] <= 0;
array[29] <= 0;
array[30] <= 0;
array[31] <= 0;
end
else begin
if (state_c == IDLE) begin
array[0] <= data_in[0*8 +: 8];
array[1] <= data_in[1*8 +: 8];
array[2] <= data_in[2*8 +: 8];
array[3] <= data_in[3*8 +: 8];
array[4] <= data_in[4*8 +: 8];
array[5] <= data_in[5*8 +: 8];
array[6] <= data_in[6*8 +: 8];
array[7] <= data_in[7*8 +: 8];
array[8] <= data_in[8*8 +: 8];
array[9] <= data_in[9*8 +: 8];
array[10] <= data_in[10*8 +: 8];
array[11] <= data_in[11*8 +: 8];
array[12] <= data_in[12*8 +: 8];
array[13] <= data_in[13*8 +: 8];
array[14] <= data_in[14*8 +: 8];
array[15] <= data_in[15*8 +: 8];
array[16] <= data_in[16*8 +: 8];
array[17] <= data_in[17*8 +: 8];
array[18] <= data_in[18*8 +: 8];
array[19] <= data_in[19*8 +: 8];
array[20] <= data_in[20*8 +: 8];
array[21] <= data_in[21*8 +: 8];
array[22] <= data_in[22*8 +: 8];
array[23] <= data_in[23*8 +: 8];
array[24] <= data_in[24*8 +: 8];
array[25] <= data_in[25*8 +: 8];
array[26] <= data_in[26*8 +: 8];
array[27] <= data_in[27*8 +: 8];
array[28] <= data_in[28*8 +: 8];
array[29] <= data_in[29*8 +: 8];
array[30] <= data_in[30*8 +: 8];
array[31] <= data_in[31*8 +: 8];
end
else if (state_c == BREAK && i == 1 && array[j] > key) begin
array[j + 1] <= array[j];
array[j] <= key;
end
else if (state_c == SORT && array[j] > key) begin
array[j + 1] <= array[j];
array[j] <= key;
end
end
end
endmodule以下是testbench:
module sort_insertion_tb #(parameter BITWIDTH = 8, parameter ELEMENTS = 32)();
reg clk;
reg rst_n;
reg [BITWIDTH*ELEMENTS-1:0] data_in;
wire [BITWIDTH*ELEMENTS-1:0] data_out;
sort_insertion #(BITWIDTH, ELEMENTS) uut (
.clk(clk),
.rst_n(rst_n),
.data_in(data_in),
.data_out(data_out)
);
// Clock generation
always #5 clk = ~clk;
initial begin
// Initialize inputs
clk = 0;
rst_n = 0;
// Apply reset
#10;
rst_n = 1;
// Load test data
data_in[BITWIDTH*0 +: BITWIDTH] = 8'd12;
data_in[BITWIDTH*1 +: BITWIDTH] = 8'd3;
data_in[BITWIDTH*2 +: BITWIDTH] = 8'd25;
data_in[BITWIDTH*3 +: BITWIDTH] = 8'd8;
data_in[BITWIDTH*4 +: BITWIDTH] = 8'd15;
data_in[BITWIDTH*5 +: BITWIDTH] = 8'd18;
data_in[BITWIDTH*6 +: BITWIDTH] = 8'd7;
data_in[BITWIDTH*7 +: BITWIDTH] = 8'd1;
data_in[BITWIDTH*8 +: BITWIDTH] = 8'd31;
data_in[BITWIDTH*9 +: BITWIDTH] = 8'd14;
data_in[BITWIDTH*10 +: BITWIDTH] = 8'd6;
data_in[BITWIDTH*11 +: BITWIDTH] = 8'd22;
data_in[BITWIDTH*12 +: BITWIDTH] = 8'd27;
data_in[BITWIDTH*13 +: BITWIDTH] = 8'd20;
data_in[BITWIDTH*14 +: BITWIDTH] = 8'd5;
data_in[BITWIDTH*15 +: BITWIDTH] = 8'd9;
data_in[BITWIDTH*16 +: BITWIDTH] = 8'd4;
data_in[BITWIDTH*17 +: BITWIDTH] = 8'd17;
data_in[BITWIDTH*18 +: BITWIDTH] = 8'd2;
data_in[BITWIDTH*19 +: BITWIDTH] = 8'd10;
data_in[BITWIDTH*20 +: BITWIDTH] = 8'd11;
data_in[BITWIDTH*21 +: BITWIDTH] = 8'd13;
data_in[BITWIDTH*22 +: BITWIDTH] = 8'd24;
data_in[BITWIDTH*23 +: BITWIDTH] = 8'd28;
data_in[BITWIDTH*24 +: BITWIDTH] = 8'd19;
data_in[BITWIDTH*25 +: BITWIDTH] = 8'd26;
data_in[BITWIDTH*26 +: BITWIDTH] = 8'd23;
data_in[BITWIDTH*27 +: BITWIDTH] = 8'd30;
data_in[BITWIDTH*28 +: BITWIDTH] = 8'd29;
data_in[BITWIDTH*29 +: BITWIDTH] = 8'd21;
data_in[BITWIDTH*30 +: BITWIDTH] = 8'd16;
data_in[BITWIDTH*31 +: BITWIDTH] = 8'd0;
// Wait for the sorting to complete
#3000;
// Display sorted data
$display("Sorted data:");
$display("data_out[0] = %d", data_out[BITWIDTH*0 +: BITWIDTH]);
$display("data_out[1] = %d", data_out[BITWIDTH*1 +: BITWIDTH]);
$display("data_out[2] = %d", data_out[BITWIDTH*2 +: BITWIDTH]);
$display("data_out[3] = %d", data_out[BITWIDTH*3 +: BITWIDTH]);
$display("data_out[4] = %d", data_out[BITWIDTH*4 +: BITWIDTH]);
$display("data_out[5] = %d", data_out[BITWIDTH*5 +: BITWIDTH]);
$display("data_out[6] = %d", data_out[BITWIDTH*6 +: BITWIDTH]);
$display("data_out[7] = %d", data_out[BITWIDTH*7 +: BITWIDTH]);
$display("data_out[8] = %d", data_out[BITWIDTH*8 +: BITWIDTH]);
$display("data_out[9] = %d", data_out[BITWIDTH*9 +: BITWIDTH]);
$display("data_out[10] = %d", data_out[BITWIDTH*10 +: BITWIDTH]);
$display("data_out[11] = %d", data_out[BITWIDTH*11 +: BITWIDTH]);
$display("data_out[12] = %d", data_out[BITWIDTH*12 +: BITWIDTH]);
$display("data_out[13] = %d", data_out[BITWIDTH*13 +: BITWIDTH]);
$display("data_out[14] = %d", data_out[BITWIDTH*14 +: BITWIDTH]);
$display("data_out[15] = %d", data_out[BITWIDTH*15 +: BITWIDTH]);
$display("data_out[16] = %d", data_out[BITWIDTH*16 +: BITWIDTH]);
$display("data_out[17] = %d", data_out[BITWIDTH*17 +: BITWIDTH]);
$display("data_out[18] = %d", data_out[BITWIDTH*18 +: BITWIDTH]);
$display("data_out[19] = %d", data_out[BITWIDTH*19 +: BITWIDTH]);
$display("data_out[20] = %d", data_out[BITWIDTH*20 +: BITWIDTH]);
$display("data_out[21] = %d", data_out[BITWIDTH*21 +: BITWIDTH]);
$display("data_out[22] = %d", data_out[BITWIDTH*22 +: BITWIDTH]);
$display("data_out[23] = %d", data_out[BITWIDTH*23 +: BITWIDTH]);
$display("data_out[24] = %d", data_out[BITWIDTH*24 +: BITWIDTH]);
$display("data_out[25] = %d", data_out[BITWIDTH*25 +: BITWIDTH]);
$display("data_out[26] = %d", data_out[BITWIDTH*26 +: BITWIDTH]);
$display("data_out[27] = %d", data_out[BITWIDTH*27 +: BITWIDTH]);
$display("data_out[28] = %d", data_out[BITWIDTH*28 +: BITWIDTH]);
$display("data_out[29] = %d", data_out[BITWIDTH*29 +: BITWIDTH]);
$display("data_out[30] = %d", data_out[BITWIDTH*30 +: BITWIDTH]);
$display("data_out[31] = %d", data_out[BITWIDTH*31 +: BITWIDTH]);
$finish;
end
endmodule看一张调了很久的波形:
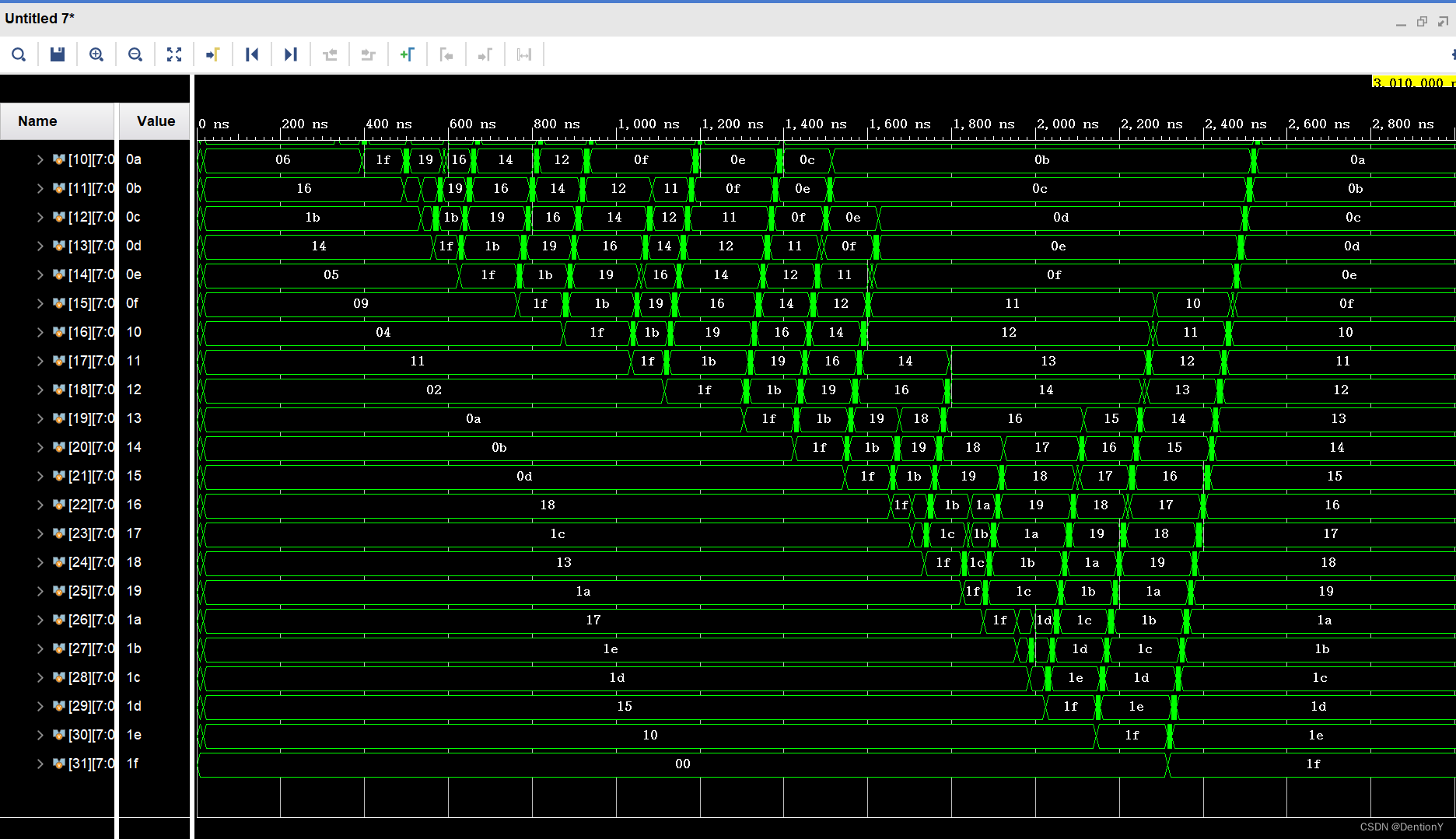
三、双调排序
以下是双调排序.v(目前来看,这段代码还有很大改进空间):
//
//
// Create Date: 22/03/2022
// Author: Bala Dhinesh
// Module Name: BitonicSortScalable
// Project Name: Bitonic Sorting in Verilog
//
//
// This code can work with any number of elements in the powers of 2. There are three primary states in the code, namely SORT, MERGE_SETUP, MERGE.
// **SORT**: Sort the array for every eight elements.
// **MERGE_SETUP**: This will make a bitonic sequence for the entire array.
// **MERGE**: Do the bitonic sort from the bitonic sequence array obtained from MERGE_SETUP.
// This code uses eight elements as a base for hardware and scaled from it.
// reference: https://github.com/BalaDhinesh/Bitonic-Sorting-In-Verilog
// another reference: https://github.com/john9636/SortingNetwork
module sort_bitonic #(parameter BITWIDTH = 8, parameter ELEMENTS = 32)(
input clk,
input rst_n,
input en_i,
input [ELEMENTS*BITWIDTH-1:0] in,
// add signal for max
// 32-max1
input enable_SORT32_max1,
// 16-max1
input enable_SORT16_max1,
// The reason of multipling 8 is 8 group of 4-max1
// 4 group of 8-max1, 2 group of 16-max1, 1 group of 32-max1
output reg [BITWIDTH*8-1:0] sort_max,
output reg done_o,
output reg [ELEMENTS*BITWIDTH-1:0] out
);
// FSM states
localparam START = 3'b000, // 0
SETUP = 3'b001, // 1
SORT = 3'b010, // 2
DONE = 3'b011, // 3
MERGE_SETUP = 3'b100, // 4
MERGE = 3'b101, // 5
IDLE = 3'b111; // 7
reg positive; // sort ascending or descending for intermediate sub-arrays
reg [2:0] state; // state of FSM
reg [$clog2(ELEMENTS)-1:0] stage;
reg [7:0] d[0:7]; // temporary register array
reg [2:0] step;
// Register variables for Bitonic merge
reg [$clog2(ELEMENTS):0] compare;
reg [$clog2(ELEMENTS)-1:0] i_MERGE;
reg [$clog2(ELEMENTS)-1:0] sum;
reg [$clog2(ELEMENTS)-1:0] sum_max;
reg [$clog2(ELEMENTS):0] STAGES = ELEMENTS/16;
reg [$clog2(ELEMENTS):0] STAGES_FIXED = ELEMENTS/16;
always @(posedge clk or negedge rst_n)
if (!rst_n) begin
out <= 0;
step <= 4'd0;
done_o <= 1'd0;
state <= START;
end else begin
case(state)
START:
begin
step <= 0;
done_o <= 1'd0;
compare <= ELEMENTS;
i_MERGE <= 0;
positive <= 1;
sum <= 8;
sum_max <= 8;
out <= in;
if(en_i) begin
state <= SETUP;
stage <= 0;
end
end
SETUP:
begin
if(stage <= (ELEMENTS/8)) begin
d[0] <= in[stage*8*BITWIDTH + 0*BITWIDTH +: 8];
d[1] <= in[stage*8*BITWIDTH + 1*BITWIDTH +: 8];
d[2] <= in[stage*8*BITWIDTH + 2*BITWIDTH +: 8];
d[3] <= in[stage*8*BITWIDTH + 3*BITWIDTH +: 8];
d[4] <= in[stage*8*BITWIDTH + 4*BITWIDTH +: 8];
d[5] <= in[stage*8*BITWIDTH + 5*BITWIDTH +: 8];
d[6] <= in[stage*8*BITWIDTH + 6*BITWIDTH +: 8];
d[7] <= in[stage*8*BITWIDTH + 7*BITWIDTH +: 8];
state <= SORT;
end
else begin
state <= START;
end
end
SORT:
begin
case(step)
0: begin
if(d[0] > d[1]) begin
d[0] <= d[1];
d[1] <= d[0];
end
if(d[2] < d[3]) begin
d[2] <= d[3];
d[3] <= d[2];
end
if(d[4] > d[5]) begin
d[4] <= d[5];
d[5] <= d[4];
end
if(d[6] < d[7]) begin
d[6] <= d[7];
d[7] <= d[6];
end
step <= step + 1;
end
1: begin
if(d[0] > d[2]) begin
d[0] <= d[2];
d[2] <= d[0];
end
if(d[1] > d[3]) begin
d[1] <= d[3];
d[3] <= d[1];
end
if(d[4] < d[6]) begin
d[4] <= d[6];
d[6] <= d[4];
end
if(d[5] < d[7]) begin
d[5] <= d[7];
d[7] <= d[5];
end
step <= step + 1;
end
2: begin
if(d[0] > d[1]) begin
d[0] <= d[1];
d[1] <= d[0];
end
if(d[2] > d[3]) begin
d[2] <= d[3];
d[3] <= d[2];
end
if(d[4] < d[5]) begin
d[4] <= d[5];
d[5] <= d[4];
end
if(d[6] < d[7]) begin
d[6] <= d[7];
d[7] <= d[6];
end
step <= step + 1;
end
3: begin
if(stage%2 ==0) begin
if(d[0] > d[4]) begin
d[0] <= d[4];
d[4] <= d[0];
end
if(d[1] > d[5]) begin
d[1] <= d[5];
d[5] <= d[1];
end
if(d[2] > d[6]) begin
d[2] <= d[6];
d[6] <= d[2];
end
if(d[3] > d[7]) begin
d[3] <= d[7];
d[7] <= d[3];
end
end
else begin
if(d[0] < d[4]) begin
d[0] <= d[4];
d[4] <= d[0];
end
if(d[1] < d[5]) begin
d[1] <= d[5];
d[5] <= d[1];
end
if(d[2] < d[6]) begin
d[2] <= d[6];
d[6] <= d[2];
end
if(d[3] < d[7]) begin
d[3] <= d[7];
d[7] <= d[3];
end
end
step <= step + 1;
end
4: begin
if(stage%2 ==0) begin
if(d[0] > d[2]) begin
d[0] <= d[2];
d[2] <= d[0];
end
if(d[1] > d[3]) begin
d[1] <= d[3];
d[3] <= d[1];
end
if(d[4] > d[6]) begin
d[4] <= d[6];
d[6] <= d[4];
end
if(d[5] > d[7]) begin
d[5] <= d[7];
d[7] <= d[5];
end
end
else begin
if(d[0] < d[2]) begin
d[0] <= d[2];
d[2] <= d[0];
end
if(d[1] < d[3]) begin
d[1] <= d[3];
d[3] <= d[1];
end
if(d[4] < d[6]) begin
d[4] <= d[6];
d[6] <= d[4];
end
if(d[5] < d[7]) begin
d[5] <= d[7];
d[7] <= d[5];
end
end
step <= step + 1;
end
5: begin
if(stage%2 ==0) begin
if(d[0] > d[1]) begin
d[0] <= d[1];
d[1] <= d[0];
end
if(d[2] > d[3]) begin
d[2] <= d[3];
d[3] <= d[2];
end
if(d[4] > d[5]) begin
d[4] <= d[5];
d[5] <= d[4];
end
if(d[6] > d[7]) begin
d[6] <= d[7];
d[7] <= d[6];
end
end
else begin
if(d[0] < d[1]) begin
d[0] <= d[1];
d[1] <= d[0];
end
if(d[2] < d[3]) begin
d[2] <= d[3];
d[3] <= d[2];
end
if(d[4] < d[5]) begin
d[4] <= d[5];
d[5] <= d[4];
end
if(d[6] < d[7]) begin
d[6] <= d[7];
d[7] <= d[6];
end
end
step <= 4'd0;
state <= DONE;
end
default: step <= 4'd0;
endcase
end
DONE: begin
if(stage == (ELEMENTS/8 - 1)) begin
out[stage*8*BITWIDTH + 0*BITWIDTH +: 8] <= d[0];
out[stage*8*BITWIDTH + 1*BITWIDTH +: 8] <= d[1];
out[stage*8*BITWIDTH + 2*BITWIDTH +: 8] <= d[2];
out[stage*8*BITWIDTH + 3*BITWIDTH +: 8] <= d[3];
out[stage*8*BITWIDTH + 4*BITWIDTH +: 8] <= d[4];
out[stage*8*BITWIDTH + 5*BITWIDTH +: 8] <= d[5];
out[stage*8*BITWIDTH + 6*BITWIDTH +: 8] <= d[6];
out[stage*8*BITWIDTH + 7*BITWIDTH +: 8] <= d[7];
if(ELEMENTS == 8) state <= IDLE;
// add code by dention 20240514 start
// add 2 group of 16-max1
else begin
if (enable_SORT16_max1) begin
if (out[0*8*BITWIDTH + 7*BITWIDTH +: 8] > out[1*8*BITWIDTH + 0*BITWIDTH +: 8]) begin
sort_max[BITWIDTH-1:0] <= out[0*8*BITWIDTH + 7*BITWIDTH +: 8]; // 16-max1
end
else begin
sort_max[BITWIDTH-1:0] <= out[1*8*BITWIDTH + 0*BITWIDTH +: 8];
end
if (out[2*8*BITWIDTH + 7*BITWIDTH +: 8] > out[3*8*BITWIDTH + 0*BITWIDTH +: 8]) begin
sort_max[2*BITWIDTH-1:BITWIDTH] <= out[2*8*BITWIDTH + 7*BITWIDTH +: 8]; // 16-max1
end
else begin
sort_max[2*BITWIDTH-1:BITWIDTH] <= out[3*8*BITWIDTH + 0*BITWIDTH +: 8];
end
sort_max[8*BITWIDTH-1:2*BITWIDTH] <= 0;
state <= IDLE;
done_o <= 1;
end
else begin
sort_max[8*BITWIDTH-1:0] <= 0;
state <= MERGE_SETUP;
end
end
stage <= 0;
sum <= 8;
i_MERGE <= 0;
compare <= 16;
end
else if(stage < (ELEMENTS/8)) begin
out[stage*8*BITWIDTH + 0*BITWIDTH +: 8] <= d[0];
out[stage*8*BITWIDTH + 1*BITWIDTH +: 8] <= d[1];
out[stage*8*BITWIDTH + 2*BITWIDTH +: 8] <= d[2];
out[stage*8*BITWIDTH + 3*BITWIDTH +: 8] <= d[3];
out[stage*8*BITWIDTH + 4*BITWIDTH +: 8] <= d[4];
out[stage*8*BITWIDTH + 5*BITWIDTH +: 8] <= d[5];
out[stage*8*BITWIDTH + 6*BITWIDTH +: 8] <= d[6];
out[stage*8*BITWIDTH + 7*BITWIDTH +: 8] <= d[7];
state <= SETUP;
stage <= stage + 1;
end
else begin
out <= 110;
state <= IDLE;
end
end
MERGE_SETUP:
begin
if(STAGES == ELEMENTS | STAGES_FIXED == 1) begin
if(sum == ELEMENTS/2) begin
// add code by dention 20240514 start
// add 32-max1
if (enable_SORT32_max1) begin
// choose double sort bitonic 16 max1 and compare two max1 to gain the max in 32
if (out[1*8*BITWIDTH + 7*BITWIDTH +: 8] > out[2*8*BITWIDTH + 0*BITWIDTH +: 8]) begin
sort_max[BITWIDTH-1:0] <= out[1*8*BITWIDTH + 7*BITWIDTH +: 8]; // 32-max1
end
else begin
sort_max[BITWIDTH-1:0] <= out[2*8*BITWIDTH + 0*BITWIDTH +: 8]; // 32-max1
end
sort_max[BITWIDTH*8-1:BITWIDTH] <= 0;
state <= IDLE;
done_o <= 1;
end
// add code by dention 20240514 end
else begin
sort_max[BITWIDTH*8-1:0] <= 0;
state <= MERGE;
end
end
else begin
sum <= sum_max * 2; //16
sum_max <= sum_max * 2; //16
state <= MERGE_SETUP;
i_MERGE <= 0;
compare <= sum_max*4; //64
positive <= 1;
stage <= 0;
STAGES <= STAGES_FIXED / 2; // 2
STAGES_FIXED <= STAGES_FIXED / 2; // 1
end
end
// across-0 min-max-min-max 1 period
// across-1 min-max-min-max 2 period
// across-3 min-max-min-max 3 period
// across-7 min-max-min-max 4 period
else begin
if((sum + i_MERGE) < compare && (compare <= ELEMENTS) && (stage < STAGES)) begin
if(positive) begin
if(out[i_MERGE*BITWIDTH +: 8] > out[(i_MERGE+sum)*BITWIDTH +: 8]) begin
out[i_MERGE*BITWIDTH +: 8] <= out[(i_MERGE+sum)*BITWIDTH +: 8];
out[(i_MERGE+sum)*BITWIDTH +: 8] <= out[i_MERGE*BITWIDTH +: 8];
end
end
else begin
if(out[i_MERGE*BITWIDTH +: 8] < out[(i_MERGE+sum)*BITWIDTH +: 8]) begin
out[i_MERGE*BITWIDTH +: 8] <= out[(i_MERGE+sum)*BITWIDTH +: 8];
out[(i_MERGE+sum)*BITWIDTH +: 8] <= out[i_MERGE*BITWIDTH +: 8];
end
end
if ((sum + i_MERGE) >= (compare - 1)) begin
i_MERGE <= compare;
compare <= compare + 2*sum;
stage = stage + 1;
if(STAGES == 2) begin
if(stage == 0) positive <= 1;
else positive <= 0;
end
else begin
if((stage%(STAGES*2/STAGES_FIXED)) < STAGES/STAGES_FIXED) positive <= 1;
else positive <= 0;
end
state <= MERGE_SETUP;
end
else begin
i_MERGE = i_MERGE + 1;
state <= MERGE_SETUP;
end
end
else begin
state <= MERGE_SETUP;
i_MERGE <= 0;
positive <= 1;
sum <= sum / 2;
compare <= sum;
stage <= 0;
STAGES <= STAGES * 2;
end
end
end
MERGE:
begin
if(sum == 1) begin
state <= IDLE;
done_o <= 1;
end
else begin
if((sum + i_MERGE) < ELEMENTS) begin
if(out[i_MERGE*BITWIDTH +: 8] > out[(i_MERGE+sum)*BITWIDTH +: 8]) begin
out[i_MERGE*BITWIDTH +: 8] <= out[(i_MERGE+sum)*BITWIDTH +: 8];
out[(i_MERGE+sum)*BITWIDTH +: 8] <= out[i_MERGE*BITWIDTH +: 8];
end
if ((sum + i_MERGE) >= (compare - 1)) begin
i_MERGE <= compare;
compare <= compare * 2;
end
else begin
i_MERGE = i_MERGE + 1;
state <= MERGE;
end
end
else begin
state <= MERGE;
i_MERGE <= 0;
sum <= sum / 2;
compare <= sum;
end
end
end
IDLE: state <= IDLE;
default: state <= START;
endcase
end
endmodule以下是testbench:
`timescale 1ns/1ps
`define clk_period 20
module BitonicSortScalable_tb #(
parameter BITWIDTH = 8, // Bitwidth of each element
parameter ELEMENTS = 32 // Number of elements to be sorted. This value must be a powers of two
)
();
reg clk, rst_n, en_i;
reg [ELEMENTS*BITWIDTH-1:0] in;
wire done_o;
wire [ELEMENTS*BITWIDTH-1:0] out;
reg enable_SORT32_max1;
reg enable_SORT16_max1;
wire [BITWIDTH*8-1:0] sort_max;
sort_bitonic bitonic_SORT_u(
clk,
rst_n,
en_i,
in,
enable_SORT32_max1,
enable_SORT16_max1,
sort_max,
done_o,
out
);
integer i;
initial begin
clk = 1'b1;
end
always #(`clk_period/2) begin
clk = ~clk;
end
initial begin
rst_n = 0;
en_i = 0;
in = 0;
enable_SORT16_max1 = 0;
enable_SORT32_max1 = 0;
#(`clk_period);
rst_n = 1;
en_i = 1;
enable_SORT16_max1 = 1;
// Input array vector to sort.
// Increase the number of elements based on ELEMENTS parameter
in ={ 8'd28, 8'd23, 8'd24, 8'd16, 8'd11, 8'd25, 8'd29, 8'd1,
8'd10, 8'd32, 8'd21, 8'd2, 8'd27, 8'd31, 8'd3, 8'd30,
8'd15, 8'd13, 8'd0, 8'd8, 8'd5, 8'd18, 8'd22, 8'd26,
8'd4, 8'd6, 8'd9, 8'd19, 8'd20, 8'd7, 8'd14, 8'd17
};
#(`clk_period);
en_i = 0;
#(`clk_period*10000);
$display("Input array:");
for(i=0;i<ELEMENTS;i=i+1)
$write(in[i*BITWIDTH +: 8]);
$display("\nOutput sorted array:");
for(i=0;i<ELEMENTS;i=i+1)
$write(out[i*BITWIDTH +: 8]);
$display("\ndone %d", done_o);
$finish;
end
endmodule四、堆排序
以下是堆排序的.v代码:
// reference: https://zhuanlan.zhihu.com/p/32166363
`timescale 1ns / 1ps
module sort_heap
#(
parameter addr_width = 5,
parameter data_width = 8
)
(
input clk,
input rst_n,
input en,
input clr,
output reg done,
input [addr_width - 1:0] parent,
input [addr_width - 1:0] length,
output reg wea,
output reg [ addr_width - 1:0 ] addra,
output reg [ data_width - 1:0 ] data_we,
input [ data_width - 1:0 ] data_re
);
reg [data_width - 1:0] temp;
reg [addr_width :0] parent_r;//attention: For recognize the parent, we must expand data width of it
reg [addr_width :0] child_r;
reg [addr_width :0] length_r;
parameter IDLE = 6'b000001;
parameter BEGINA = 6'b000010;
parameter GET = 6'b000100;
parameter COMPARE = 6'b001000;
parameter WRITE = 6'b010000;
parameter COMPLETE= 6'b100000;
reg [5:0] state;
reg [5:0] next_state;
reg [7:0] cnt;
reg [data_width - 1:0] child_compare;
always@(posedge clk or negedge rst_n)
begin
if(!rst_n) begin state <= IDLE; end
else begin state <= next_state; end
end
always@(*)
begin
case(state)
IDLE: begin
if(en) begin next_state = BEGINA; end
else begin next_state = IDLE; end
end
BEGINA:begin
if(cnt == 8'd2) begin next_state = GET; end
else begin next_state = BEGINA; end
end
GET: begin
if(child_r >= length_r) begin next_state = COMPLETE; end
else if(cnt == 8'd4) begin next_state = COMPARE; end
else begin next_state = GET; end
end
COMPARE: begin
if(temp >= child_compare) begin next_state = COMPLETE; end
else begin next_state = WRITE; end
end
WRITE: begin
if(cnt == 8'd1) begin next_state = GET; end
else begin next_state = WRITE; end
end
COMPLETE:begin
if(clr) begin next_state = IDLE; end
else begin next_state = COMPLETE; end
end
endcase
end
reg [data_width - 1:0] child_R;
reg [data_width - 1:0] child_L;
always@(posedge clk or negedge rst_n)
begin
if(!rst_n) begin done <= 1'b0; end
else
begin
case(state)
IDLE: begin
parent_r <= {1'b0, parent};
length_r <= {1'b0, length};
child_r <= 2*parent + 1'b1;
cnt <= 8'd0; child_R <= 0; child_L <= 0;
done <= 1'b0;
end
BEGINA:begin
if(cnt == 8'd0) begin addra <= parent_r; cnt <= cnt + 1'b1; end
else if(cnt == 8'd2) begin temp <= data_re; cnt <= 1'b0; end
else begin cnt <= cnt + 1'b1; end
end
GET: begin
if(child_r >= length_r) begin addra <= addra; end
else
begin
if(cnt == 8'd0) begin addra <= child_r; cnt <= cnt + 1'b1; end
else if(cnt == 8'd1) begin addra <= child_r + 1'b1; cnt <= cnt + 1'b1; end
else if(cnt == 8'd2) begin child_L <= data_re; cnt <= cnt + 1'b1; end
else if(cnt == 8'd3) begin child_R <= data_re; cnt <= cnt + 1'b1; end
else if(cnt == 8'd4)
begin
if( (child_r + 1'b1 < length_r) && (child_R > child_L) )
begin
child_r <= child_r + 1'b1;
child_compare <= child_R;
end
else
begin
child_r <= child_r;
child_compare <= child_L;
end
cnt <= 8'd0;
end
else begin cnt <= cnt + 1'b1; end
end
end
COMPARE: begin end
WRITE: begin
if(cnt == 8'd0) begin
addra <= parent_r; wea <= 1'b1;
data_we <= child_compare; cnt <= cnt + 1'b1;
end
else if(cnt == 8'd1) begin
wea <= 1'b0; cnt <= 8'd0;
parent_r <= child_r;
child_r <= child_r*2 + 1'b1;
end
else begin cnt <= cnt; end
end
COMPLETE: begin
if(cnt == 8'd0) begin
wea <= 1'b1; addra <= parent_r;
data_we <= temp; cnt <= cnt + 1'b1;
end
else if(cnt == 8'd1)
begin
wea <= 1'b0;
cnt <= cnt + 1'b1;
done <= 1'b1;
end
else if(cnt == 8'd2)
begin
done <= 1'b0;
cnt <= 8'd2;
end
end
endcase
end
end
endmodule以下是堆排序的top文件(注意事先在vivado的库内例化ROM,并载入coe,网上有大量关于coe的语法,我这边也贴上)
`timescale 1ns / 1ps
module sort_heap_top
#(
parameter addr_width = 5, //stack address width
parameter data_width = 8, //stack data width
parameter stack_deepth = 31 //stack deepth
)
(
input clk,
input rst_n
);
reg en; //initial module input: Enable initial process
reg clr; //initial module input: Reset initial process
wire done; //initial module output: One initial process have done
reg [addr_width - 1:0] parent; //initial module input: Parent
reg [addr_width - 1:0] length; //initial module input: Length of list
wire wea; //RAM module input: write enable
wire [addr_width - 1:0] addra; //RAM module input: write/read address
wire [data_width - 1:0] data_we; //RAM module input: write data
wire [data_width - 1:0] data_re; //RAM module output: read data
parameter BEGINA = 9'b0_0000_0001;//stage 1: stack initial
parameter RANK = 9'b0_0000_0010;
parameter FINISH = 9'b0_0000_0100;
parameter DONE = 9'b0_0000_1000;
parameter READ = 9'b0_0001_0000;//stage 2: rank of stack
parameter WRITE = 9'b0_0010_0000;
parameter RANK_2 = 9'b0_0100_0000;
parameter FINISH_2= 9'b0_1000_0000;
parameter DONE_2 = 9'b1_0000_0000;
reg [addr_width - 1:0] cnt; //counter in FSM stage 1/2
reg [addr_width - 1:0] cnt2; //counter in FSM stage 2
reg [8:0] state; //FSM state
reg [8:0] next_state; //FSM next state
reg [addr_width - 1:0] addr; //stack inital process read RAM address
reg initial_done; //stack initial done
reg [data_width - 1:0] list_i; //RANK process reg
reg [data_width - 1:0] list_0; //RANK process reg
reg wea_FSM; //wea signal from FSM
reg [data_width - 1:0] data_we_FSM; //write data form FSM
//FSM stage 1: state transform
always@(posedge clk or negedge rst_n)
begin
if(!rst_n) begin state <= BEGINA; end
else begin state <= next_state; end
end
//FSM stage 2: state change
always@(*)
begin
case(state)
BEGINA: begin next_state = RANK; end //stack initial process begin
RANK: begin
if(done) begin next_state = FINISH; end
else begin next_state = RANK; end
end
FINISH:begin
if(addr == stack_deepth - 1 & cnt != {addr_width{1'b1}}) begin next_state = BEGINA; end
else if(addr == stack_deepth - 1 & cnt == {addr_width{1'b1}} ) begin next_state = DONE; end
else begin next_state = FINISH; end
end
DONE: begin next_state = READ; end //stack initial process have done
READ: begin //stack rank process begin
if(cnt == 3) begin next_state = WRITE; end
else begin next_state = READ; end
end
WRITE:begin
if(cnt == 2) begin next_state = RANK_2; end
else begin next_state = WRITE; end
end
RANK_2:begin
if(done) begin next_state = FINISH_2; end
else begin next_state = RANK_2; end
end
FINISH_2:begin
if(addr == stack_deepth - 1 & cnt2 != 0) begin next_state = READ; end
else if(addr == stack_deepth - 1 & cnt2 == 0) begin next_state = DONE_2; end
else begin next_state = FINISH_2; end
end
DONE_2:begin next_state = DONE_2; end//stack rank process done
endcase
end
//FSM stage 3: state output
always@(posedge clk or negedge rst_n)
begin
if(!rst_n) begin cnt <= stack_deepth/2; addr <= {addr_width{1'b1}}; initial_done <= 1'b0; wea_FSM <= 1'b0; end
else
begin
case(state)
BEGINA: begin //stack initial begin
en <= 1'b1;
clr <= 1'b0;
parent <= cnt;
length <= stack_deepth;
end
RANK: begin
clr <= 1'b0;
if(done) begin cnt <= cnt - 1'b1; clr <= 1'b1; en <= 1'b0; addr <= 4'd0; end
end
FINISH:begin clr <= 1'b0; addr <= addr + 1'b1; end
DONE: begin
initial_done <= 1'b1; //stack initial have done
cnt2 <= stack_deepth - 1;
cnt <= 0;
end
READ: begin //stack rank process begin
if(cnt == 0) begin addr <= 0; cnt <= cnt + 1'b1; end
else if(cnt == 1) begin addr <= cnt2; cnt <= cnt + 1'b1; end
else if(cnt == 2) begin list_0 <= data_re; cnt <= cnt + 1'b1; end
else if(cnt == 3) begin list_i <= data_re; cnt <= 0; end
else begin cnt <= cnt; end
end
WRITE:begin
if(cnt == 0) begin
wea_FSM <= 1'b1;
addr <= 0; data_we_FSM <= list_i;
cnt <= cnt + 1'b1;
end
else if(cnt == 1) begin
wea_FSM <= 1'b1;
addr <= cnt2; data_we_FSM <= list_0;
cnt <= cnt + 1'b1;
end
else if(cnt == 2) begin wea_FSM <= 1'b0; cnt <= 0; parent <= 0; length <= cnt2; en <= 1'b1; end
else begin cnt <= cnt; end
end
RANK_2:begin
if(done) begin cnt2 <= cnt2 - 1'b1; clr <= 1'b1; en <= 1'b0; addr <= 0; end
end
FINISH_2:begin
clr <= 1'b0; addr <= addr + 1'b1;
end
endcase
end
end
wire wea_initial;
wire [data_width - 1:0] data_we_initial;
//stack initial process
sort_heap U1
(
.clk(clk),
.rst_n(rst_n),
.en(en),
.clr(clr),
.done(done),
.parent(parent),
.length(length),
.wea(wea_initial),
.addra(addra),
.data_we(data_we_initial),
.data_re(data_re)
);
wire [addr_width - 1:0] RAM_addr;
assign wea = (state == WRITE) ? wea_FSM:wea_initial;
assign RAM_addr = (state == FINISH || state == READ || state == WRITE || state == FINISH_2) ? addr:addra;
assign data_we = (state == WRITE) ? data_we_FSM:data_we_initial;
//RAM module
blk_mem_gen_0 RAM1
(
.clka(clk),
.wea(wea),
.addra(RAM_addr),
.dina(data_we),
.douta(data_re)
);
endmodule对应的coe文件如下:
;分号后的代码都被认为是注释内容
memory_initialization_radix=10;
memory_initialization_vector=
1,
3,
4,
5,
2,
6,
9,
7,
8,
0,
11,
15,
13,
19,
20,
16,
12,
10,
14,
11,
25,
21,
23,
22,
18,
27,
36,
29,
17,
24,
26,
30;以下为对应的testbench:
`define clk_period 20
module sort_hep_top_tb
();
reg clk;
reg rst_n;
initial begin
clk = 1'b1;
end
always #(`clk_period/2) begin
clk = ~clk;
end
initial begin
rst_n = 0;
#(`clk_period);
rst_n = 1;
#(`clk_period*100000);
$finish;
end
sort_heap_top sort_heap_top_u(
clk,
rst_n
);
endmodule
五、资源占用和延时对比
直接贴图表示,不多废话!


![[ROS 系列学习教程] 建模与仿真 - URDF 建模实践](https://img-blog.csdnimg.cn/direct/bc0104b3ddfd45309df5c295080cb9c0.png#pic_center)



![BUUCTF靶场[MISC]wireshark、被嗅探的流量、神秘龙卷风、另一个世界](https://img-blog.csdnimg.cn/direct/25715a70b4ee4f5d86a2660a4d1c27ee.png)