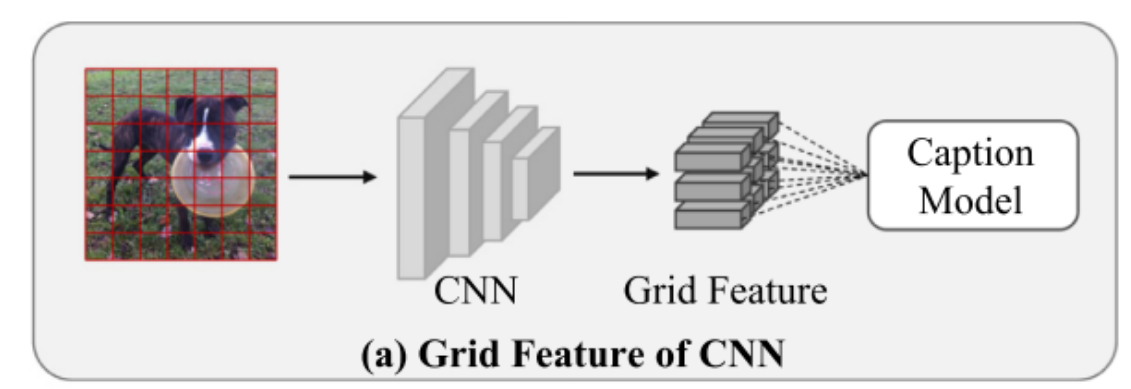
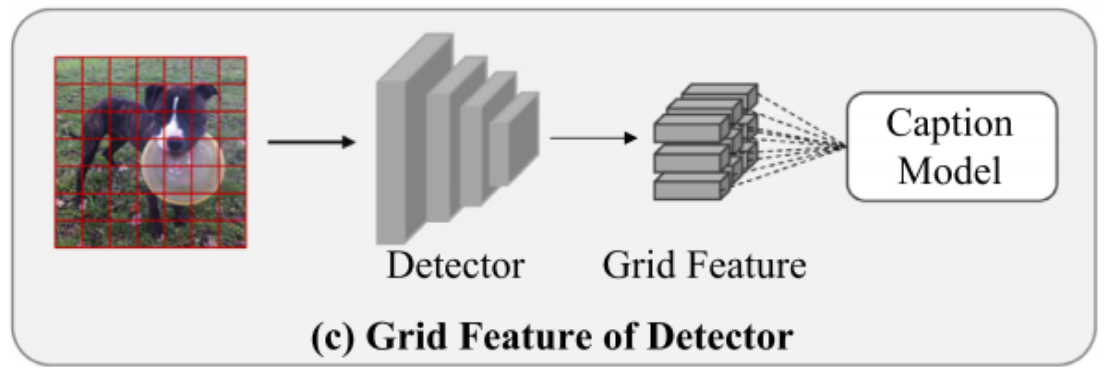
【Image captioning】基于检测模型网格特征提取——以Sydeny为例
今天,我们将重点探讨如何利用Faster R-CNN检测模型来提取Sydeny数据集的网格特征。具体而言,这一过程涉及通过Faster R-CNN模型对图像进行分析,进而抽取出关键区域的特征信息,这些特征在网格结构中被系统地组织和表示。下面,我将引导大家深入了解这一特征提取流程。
1. 数据的预处理
为了适应In Defense of Grid Features for Visual Question Answering论文提供的官方代码,需要将自定义图像数据集的标注和元数据调整成符合COCO数据集格式。COCO(Common Objects in Context)数据集是一种广泛使用的视觉理解数据集,它不仅包含了丰富的图像资源,还提供了详尽的注解信息,包括图像中的物体类别、边界框等。
原始Sydeny遥感图像字幕包含的有图片imgs和对应的字幕信息dataset.json。
1.1 划分数据集
根据dataset.json的中的信息,将图片文件从一个源目

![[数据集][目标检测]纸箱子检测数据集VOC+YOLO格式8375张1类别](https://img-blog.csdnimg.cn/direct/4283cc21363b4ee6a66a143e40c4bc2f.png)


![NSSCTF | [SWPUCTF 2021 新生赛]easyupload2.0](https://img-blog.csdnimg.cn/direct/e7365ddaee994c438241ceeb7eab363d.png)