2.4.1 事务排序规则
表2-40定义了PCI Express事务的排序要求。此表中定义的规则适用于PCI Express上的所有事务类型,包括内存、I/O、配置和消息事务。在单个流量类别(Traffic Class,TC)内,这些排序规则适用。不同TC标签之间的事务没有排序要求。请注意,这也意味着通过不同虚拟通道传输的流量之间也没有排序要求,因为具有相同TC标签的事务不允许被映射到任何PCI Express链路上的多个虚拟通道上。
对于表2-40,列代表首次发出的事务,行代表随后发出的事务。表中的条目指示两个事务之间的排序关系。表项定义如下:
Yes 第二个事务(行)必须被允许通过第一个(列),以避免死锁。(当发生阻塞时,第二个事务需要通过第一个事务。必须理解公平性以防止饥饿。)
Y/N 没有要求。第二个事务可以选择性地通过第一个事务,或者被它阻塞。
No 第二个事务不得被允许通过第一个事务。这是为了支持生产者/消费者强排序模型所必需的。
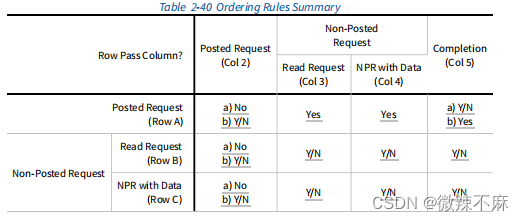
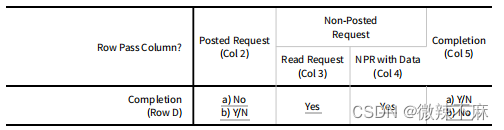
表2-40中行列标题的解释:
- A Posted Request(转发请求)是指内存写请求或消息请求。
- A Read Request(读请求)是指配置读取请求、I/O读取请求或内存读取请求。
- An NPR (Non-Posted Request) with Data(带有数据的非转发请求)是指配置写请求、I/O写请求或原子操作请求。
- A Non-Posted Request(非转发请求)是指读取请求或带有数据的非转发请求。
表2-40中条目的说明:
- A2a:转发请求不得通过另一个转发请求,除非A2b适用。
- A2b:如果设置了RO,则允许转发请求通过另一个转发请求。如果设置了IDO,并且两个请求者的ID不同,或者两个请求都包含PASID TLP前缀且两个PASID值不同,则允许转发请求通过另一个转发请求。
- A3, A4:为了避免死锁,转发请求必须能够通过非转发请求。
- A5a:转发请求被允许通过完成事务,但除非A5b适用,否则不必能够通过完成事务。
- A5b:在PCI Express到PCI/PCI-X桥接器中,如果PCI/PCI-X总线段以传统PCI模式运行,对于PCI Express到PCI方向的事务,为了避免死锁,转发请求必须能够通过完成事务。
- B2a:除非B2b适用,读取请求不得通过转发请求。
- B2b:如果设置了IDO,并且两个请求者的ID不同,或者两个请求都包含PASID TLP前缀且两个PSID值不同,则允许读取请求通过转发请求。
- C2a:除非C2b适用,带有数据的非转发请求不得通过转发请求。
-
C2b:设置了“RO”的带有数据的非转发请求(NPR)被允许通过转发请求。如果设置了“IDO”,并且两个请求者的ID不同,或者两个请求都包含PASID TLP前缀且两个PASID值不同,则允许通过转发请求。
-
B3, B4, C3, C4:非转发请求被允许通过另一个非转发请求。
-
B5, C5:非转发请求被允许通过完成事务。
-
D2a:除非D2b适用,完成事务不得通过已转发请求。
-
D2b:允许I/O或配置写入完成事务通过转发请求。如果设置了RO,则允许完成事务通过转发请求。如果设置了IDO,并且完成事务的完成者ID与转发请求的请求者ID不同,则允许完成事务通过转发请求。
-
D3, D4:为了避免死锁,完成事务必须能够通过非转发请求。
-
D5a:具有不同事务ID的完成事务被允许相互通过。
-
D5b:具有相同事务ID的完成事务不得相互通过。这确保了与单个内存读取请求关联的多个完成事务将保持地址升序排列。
-
附加规则:
- 允许PCI Express Switch去允许设置了宽松排序位的内存写入或消息请求通过任何之前转发的、在同一方向前进的内存写入或消息请求。Switch必须不修改转发宽松排序属性。也允许根复合体去允许请求中的数据字节以任何顺序写入系统内存(字节必须写入正确的系统内存位置。只有写入它们的顺序是未指定的)。
- 对于根复合体和Switch,禁止内存写入合并(如[PCI]中定义)。
- 请注意:这是必要的,以便设备可以优化其接收缓冲区和控制逻辑,以匹配它们自然预期的内存写入大小,而不是必须支持最大可能的内存写入负载大小。
- 禁止合并内存读取请求和/或不同请求的完成事务。
- 不监听位不影响所需的排序行为。
- 对于根端口和Switch下游端口,接受转发请求或完成事务不得依赖于同一流量类别内非转发请求的传输。
- 对于Switch上游端口,接受转发请求或完成事务不得依赖于下游端口内同一流量类别的非转发请求的传输。
-
对于端点(Endpoint)、桥接器(Bridge)和交换机上游端口(Switch Upstream Ports),接受转发请求(Posted Request)不得依赖于同一上游端口(Upstream Port)内同一流量类别(Traffic Class)中传输的任何事务层包(TLP)。
-
对于端点、桥接器和交换机上游端口,接受非转发请求(Non-posted Request)不得依赖于同一上游端口内同一流量类别中传输的非转发请求。
-
对于端点、桥接器和交换机上游端口,接受完成事务(Completion)不得依赖于同一上游端口内同一流量类别中传输的任何TLP。
-
请注意,端点(Endpoints)永远不允许阻止接受完成事务。
-
针对非转发请求发出的完成事务必须返回与相应非转发请求相同的流量类别。
-
支持点对点操作的根复合体(Root Complexes)和交换机必须对所有转发的流量强制执行这些事务排序规则。
-
为确保无死锁操作,设备不应将流量从一个虚拟通道(Virtual Channel)转发到另一个虚拟通道。在设备转发或转换虚拟通道之间的事务时避免死锁的约束规范不在本文档范围内(有关相关议题的讨论,请参阅附录D)。
-
2.4.2 读取事务观察到的更新排序和粒度
如果请求者(Requester)使用单个事务从完成者(Completer)读取数据块,而完成者的数据缓冲区同时正在被更新,那么在读取返回的数据中反映的多个更新的排序和每个更新的粒度不在本规范的范围之内。这既适用于通过PCI Express写入事务执行的更新,也适用于通过其他机制(如主机CPU更新主机内存)执行的更新。
如果请求者使用单个事务从完成者读取数据块,而完成者的数据缓冲区同时正在被一个或多个不在PCI Express结构上的实体更新,那么在读取返回的数据中反映的多个更新的排序和每个更新的粒度也不在本规范的范围之内。
以更新排序为例,假设数据块位于主机内存中,主机CPU首先写入位置A,然后写入不同的位置B。使用单个读取事务读取该数据块的请求者不能保证按顺序观察这些更新。换句话说,请求者可能会观察到位置B的更新值和位置A的旧值,而不管位置A和B在数据块内的排列如何。除非完成者就更新排序作出自己的保证(在本规范之外),否则依赖于更新排序的请求者必须先通过一个读取事务观察位置B的更新,然后再发起对位置A的后续读取以返回其更新值。 以更新粒度为例,如果主机CPU向主机内存写入一个四字(QW),从主机内存读取该四字的请求者可能会观察到四字的一部分被更新,而另一部分包含旧值。
虽然本规范不要求,但强烈建议主机平台保证,当主机CPU向主机内存写入对齐的双字(DW)或对齐的四字(QW)时,PCI Express读取观察到的更新粒度不会小于双字。
2.4.3 写入事务提供的更新排序和粒度
如果完成者接受了包含多个双字(DWs)且清除了宽松排序位(Relaxed Ordering bit)的单个写入事务,那么在完成者的数据缓冲区内对位置的更新观察到的排序必须按递增地址顺序。如果路径上的PCI或PCI-X桥接器将多个写入事务合并为单个事务,这种语义是必需的。然而,对完成者数据缓冲区的更新观察到的粒度不在本规范的范围之内。
虽然本规范不要求,但强烈建议主机平台保证当PCI Express写入更新主机内存时,主机CPU观察到的更新粒度不会小于双字(DW)。
以更新排序和粒度为例,如果请求者向主机内存写入一个四字(QW),在某些情况下,主机CPU从主机内存读取该四字时可能会观察到第一个双字已更新,而第二个双字包含旧值。