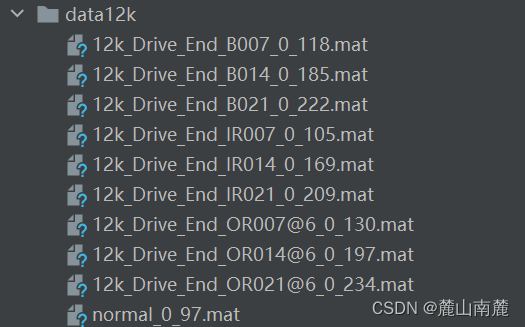
CRWU凯斯西储大学轴承数据,12k频率,十分类。
from torch.utils.data import Dataset, DataLoader
from scipy.io import loadmat
import numpy as np
import os
from sklearn import preprocessing # 0-1编码
from sklearn.model_selection import StratifiedShuffleSplit # 随机划分,保证每一类比例相同
import torch
from torch import nn
from sklearn.metrics import accuracy_score, precision_recall_fscore_support
import torch.optim as optim
def prepro(d_path, length=0, number=0, normal=True, rate=[0, 0, 0], enc=False, enc_step=28):
# 获得该文件夹下所有.mat文件名
filenames = os.listdir(d_path)
def capture(original_path):
files = {}
for i in filenames:
# 文件路径
file_path = os.path.join(d_path, i)
file = loadmat(file_path)
file_keys = file.keys()
for key in file_keys:
if 'DE' in key:
files[i] = file[key].ravel()
return files
def slice_enc(data, slice_rate= rate[1]):
keys = data.keys()
Train_Samples = {}
Test_Samples = {}
for i in keys:
slice_data = data[i]
all_lenght = len(slice_data)
# end_index = int(all_lenght * (1 - slice_rate))
samp_train = int(number * (1 - slice_rate)) # 1000(1-0.3)
Train_sample = []
Test_Sample = []
for j in range(samp_train):
sample = slice_data[j * 150: j * 150 + length]
Train_sample.append(sample)
# 抓取测试数据
for h in range(number - samp_train):
sample = slice_data[samp_train * 150 + length + h * 150: samp_train * 150 + length + h * 150 + length]
Test_Sample.append(sample)
Train_Samples[i] = Train_sample
Test_Samples[i] = Test_Sample
return Train_Samples, Test_Samples
# 仅抽样完成,打标签
def add_labels(train_test):
X = []
Y = []
label = 0
for i in filenames:
x = train_test[i]
X += x
lenx = len(x)
Y += [label] * lenx
label += 1
return X, Y
def scalar_stand(Train_X, Test_X):
# 用训练集标准差标准化训练集以及测试集
data_all = np.vstack((Train_X, Test_X))
scalar = preprocessing.StandardScaler().fit(data_all)
Train_X = scalar.transform(Train_X)
Test_X = scalar.transform(Test_X)
return Train_X, Test_X
def valid_test_slice(Test_X, Test_Y):
test_size = rate[2] / (rate[1] + rate[2])
ss = StratifiedShuffleSplit(n_splits=1, test_size=test_size)
Test_Y = np.asarray(Test_Y, dtype=np.int32)
for train_index, test_index in ss.split(Test_X, Test_Y):
X_valid, X_test = Test_X[train_index], Test_X[test_index]
Y_valid, Y_test = Test_Y[train_index], Test_Y[test_index]
return X_valid, Y_valid, X_test, Y_test
# 从所有.mat文件中读取出数据的字典
data = capture(original_path=d_path)
# 将数据切分为训练集、测试集
train, test = slice_enc(data)
# 为训练集制作标签,返回X,Y
Train_X, Train_Y = add_labels(train)
# 为测试集制作标签,返回X,Y
Test_X, Test_Y = add_labels(test)
# for i in Test_X:
# print(i.shape)
# for i in Train_X:
# print(i.shape)
# Train_X = np.stack(Train_X,axis=0)
# Test_X = np.stack(Test_X,axis=0)
# print(Train_X.shape,Test_X.shape)
# 训练数据/测试数据 是否标准化.
if normal:
Train_X, Test_X = scalar_stand(Train_X, Test_X)
# 将测试集切分为验证集和测试集.
# Valid_X, Valid_Y, Test_X, Test_Y = valid_test_slice(Test_X, Test_Y)
return Train_X, Train_Y, Test_X, Test_Y
num_classes = 10 # 样本类别
length = 224*224 # 样本长度
number = 140 # 每类样本的数量
normal = True # 是否标准化
rate = [0.5, 0.25, 0.25] # 测试集验证集划分比例
class BearingDataset(Dataset):
def __init__(self, data, labels):
self.data = torch.tensor(data, dtype=torch.float32)
self.labels = torch.tensor(labels, dtype=torch.long)
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
return self.data[idx], self.labels[idx]
def create_dataloader(data, labels, batch_size=32, shuffle=True, num_workers=0):
dataset = BearingDataset(data, labels)
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=shuffle, num_workers=num_workers)
return dataloader
# 使用前面定义的函数处理数据
path = './data12k' # 注意路径格式可能需要根据您的操作系统调整
x_train, y_train, x_test, y_test = prepro(
d_path=path,
length=112*112, # 样本长度
number=250, # 每类样本的数量
normal=True, # 是否标准化
rate=[0.8, 0.2] # 测试集验证集划分比例
)
# 创建 DataLoader
train_loader = create_dataloader(x_train, y_train, batch_size=32, shuffle=True, num_workers=0)
test_loader = create_dataloader(x_test, y_test, batch_size=32, shuffle=False, num_workers=0)
class AlexNet(nn.Module):
def __init__(self):
super(AlexNet, self).__init__()
self.Conv1 = nn.Conv2d(1, 24, 15, 3, 2) # [1, 48, 107, 107]
self.relu1 = nn.ReLU()
self.maxpool1 = nn.MaxPool2d(2) # [1, 24, 35, 35]
self.Conv2 = nn.Conv2d(24, 64, 5, 1, 2) # [1, 64, 37, 37]
self.relu2 = nn.ReLU()
self.maxpool2 = nn.MaxPool2d(2) # [1, 64, 18, 18]
self.Conv3 = nn.Conv2d(64, 96, 2, 1, 1) # [1, 96, 19, 19]
self.relu3 = nn.ReLU()
self.Conv4 = nn.Conv2d(96, 96, 2, 1, 1) # [1, 96, 20, 20]
self.relu4 = nn.ReLU()
self.Conv5 = nn.Conv2d(96, 64, 2, 1, 1) # [1, 64, 21, 21]
self.relu5 = nn.ReLU()
self.maxpool3 = nn.MaxPool2d(3) # [1, 64, 7, 7]
self.Dro1 = nn.Dropout(p=0.5)
self.flatten = nn.Flatten()
self.line1 = nn.Linear(64 * 3 * 3, 1000)
self.relu6 = nn.ReLU()
self.Dro2 = nn.Dropout(p=0.5)
self.line2 = nn.Linear(1000, 1000)
self.relu7 = nn.ReLU()
self.line3 = nn.Linear(1000, 500)
self.line4 = nn.Linear(500, 10)
def forward(self, x):
x = self.Conv1(x)
x = self.relu1(x)
x = self.maxpool1(x)
x = self.Conv2(x)
x = self.relu2(x)
x = self.maxpool2(x)
x = self.Conv3(x)
x = self.relu3(x)
x = self.Conv4(x)
x = self.relu4(x)
x = self.Conv5(x)
x = self.relu5(x)
x = self.maxpool3(x)
x = self.Dro1(x)
x = self.flatten(x)
x = self.line1(x)
x = self.relu6(x)
x = self.Dro2(x)
x = self.line2(x)
x = self.relu7(x)
x = self.line3(x)
x = self.line4(x)
return x
def train_model(model, train_loader, criterion, optimizer, device):
model.train()
running_loss = 0.0
for inputs, labels in train_loader:
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(inputs.view(-1,1,112,112))
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
return running_loss / len(train_loader)
def evaluate_model(model, data_loader, device):
model.eval()
all_preds = []
all_labels = []
with torch.no_grad():
for inputs, labels in data_loader:
inputs, labels = inputs.to(device), labels.to(device)
outputs = model(inputs.view(-1,1,112,112))
_, predicted = torch.max(outputs, 1)
all_preds.extend(predicted.cpu().numpy())
all_labels.extend(labels.cpu().numpy())
accuracy = accuracy_score(all_labels, all_preds)
precision, recall, f1_score, _ = precision_recall_fscore_support(all_labels, all_preds, average='weighted')
return accuracy, precision, recall, f1_score
def main():
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = AlexNet().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
num_epochs = 50
# 假设 train_loader 和 test_loader 已经被创建
best_acc=0
for epoch in range(num_epochs):
train_loss = train_model(model, train_loader, criterion, optimizer, device)
print(f'Epoch {epoch+1}, Loss: {train_loss:.4f}')
accuracy, precision, recall, f1_score = evaluate_model(model, test_loader, device)
print(f'Accuracy: {accuracy:.4f}, Precision: {precision:.4f}, Recall: {recall:.4f}, F1-Score: {f1_score:.4f}')
if best_acc<accuracy:
best_acc = accuracy
torch.save(model.state_dict(), 'best_alexnet.pth')
if __name__ == "__main__":
main()






![[AI]-(第1期):OpenAI-API调用](https://img-blog.csdnimg.cn/direct/ac5b636ff9aa442890bd935cb754330a.jpeg#pic_center)