作者:高玉龙 (元泊)
首先,我们了解一下移动端全链路 Trace 的背景:

从移动端的视角来看,一个 App 产品从概念产生,到最终的成熟稳定,产品研发过程中涉及到的研发人员、工程中的代码行数、工程架构规模、产品发布频率、线上业务问题修复时间等等都会发生比较大的变化。这些变化,给我们在排查问题方面带来不小的困难和挑战,业务问题会往往难以复现和排查定位。比如,在产品初期的时候,工程规模往往比较小,业务流程也比较简单,线上问题往往能很快定位。而等到工程规模比较大的时候,业务流程往往涉及到的模块会比较多,这个时候有些线上问题就会比较难以复现和定位排查。
本文汇集了笔者在 2022 D2 终端技术大会上的相关技术分享,希望能给大家带来一些思考和启发。
端侧问题为什么很难复现和定位?

线上业务问题为什么很难复现和排查定位?经过我们的分析,主要是由 4 个原因导致:
移动端 & 服务端日志采集不统一,没有统一的标准规范来约束数据的采集和处理。
端侧往往涉及的模块非常多,研发框架也各不相同,代码相互隔离,设备碎片化,网络环境复杂,会导致端侧数据采集比较难。
从端视角出发,不同框架、系统之间的数据在分析问题时往往获取比较难,而且数据之间缺少上下文关联信息,数据关联分析不容易。
业务链路涉及到的业务域往往也会比较多,从端的视角去复现和排查问题,往往需要对应域的同学参与排查,人肉运维成本比较高。
这些问题如何来解决? 我们的思路是四步走:
建立统一标准,使用 标准协议 来约束数据的采集和处理。
针对不同的平台和框架,统一数据采集能力。
对多系统、多模块产生的数据进行自动上下文关联分析和处理。
我们也基于机器学习,在自动化经验分析方面做了一些探索。
统一数据采集标准

如何统一标准? 目前行业内也有各种各样的解决方案,但存在的问题也很明显:
不同方案之间,协议/数据类型不统一;
不同方案之间,也比较难以兼容/互通。
标准这里,我们选择了 OTel,OTel 是 OpenTelemetry 的简称,主要原因有两点:
OTel 是由云原生计算基金会(CNCF)主导,它是由 OpenTracing 和 OpenCensus 合并而来,是目前可观测性领域的准标准协议;
OTel 对不同语言和数据模型进行了统一,可以同时兼容 OpenTracing 和 OpenCensus,它还提供了一个厂商无关的 Collectors,用于接收、处理和导出可观测数据。
在我们的解决方案中,所有端的数据采集规范都基于 OTel,数据存储、处理、分析是基于 SLS 提供的 LogHub 能力进行构建。
端侧数据采集的难点

只统一数据协议还不够,还要解决端侧在数据采集方面存在的一些问题。总的来说,端侧采集当前面临 3 个主要的难点:
数据串联难
性能保障难
不丢数据难
端侧研发过程中涉及到的框架、模块往往比较多,业务也有一定的复杂性,存在线程、协程多种异步调用 API,在数据采集过程中,如何解决数据之间的自动串联问题?移动端设备碎片化严重,系统版本分布比较散,机型众多,如何保障多端一致的采集性能?App 使用场景的不确定性也比较大,如何确保采集到的数据不会丢失?
端侧数据串联的难点

我们先来分析一下端侧数据自动串联所面临的主要问题。
在端侧数据采集过程中,不仅会采集业务链路数据,还会采集各种性能&稳定性监控数据,可观测数据源比较多;
如果用到其他的研发框架,如 OkHttp、Fresco 等,可能还会采集三方框架的关键数据用于网络请求,图片加载等问题的分析和定位。对于业务研发同学来说,我们往往不会过多的关注这类三方框架技术能力,涉及到这类框架问题的排查时,过程往往比较困难;
除此之外,端侧几乎完全异步调用,而且异步调用 API 比较多,如线程、协程等,链路打通也存在一定的挑战。
这里会有几个共性问题:
三方框架的数据如何采集?如何串联?
不同可观测数据源之间如何串联?
分布在不同线程、协程之间的数据如何自动串联?
端侧数据自动串联方案
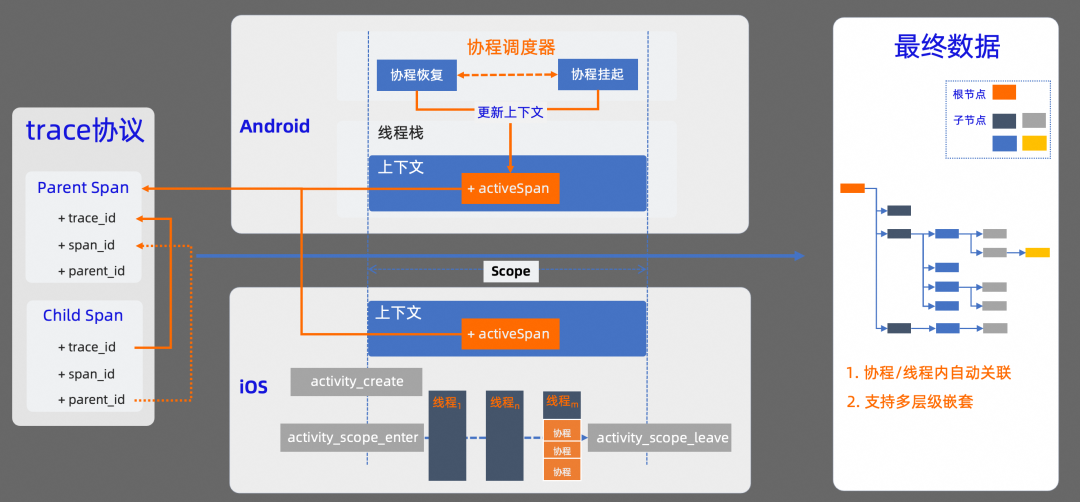
我们先看下端侧数据自动串联的方案。
在 OTel 协议标准中,是通过 trace 协议来约束不同数据之间的串联关系。OTel 定义了 trace 数据链路中每条数据必须要包含的必要字段,我们需要确保同一条链路中数据的一致性。比如,同一条 trace 链路中,trace_id 需要相同;其次,如果数据之间有父子关系,子数据的 parent_id 也需要与父数据的 span_id 相同。
我们知道,不管是 Android 平台,还是 iOS 平台,线程都是操作系统能够调度的最小单元。也就是说,我们所有的代码,最终都会在线程中被执行。在代码被执行过程中,如果我们能把上下文信息和当前线程进行关联,在代码执行时,就能自动获取当前上下文信息,这样就可以解决同一个线程内的 trace 数据自动关联问题。
在 Android 中,可以基于线程变量 ThreadLocal 来存储当前线程栈的上下文信息,这样可以确保在同一线程中采集到的业务数据进行自动关联。如果是在协程中使用,基于线程变量的方案就会存在问题。因为在协程中,协程真实运行的线程是不确定的,可能会在协程执行的生命周期内进行线程切换,我们需要利用协程调度器和协程 Context 来保持当前上下文的正确性。在协程恢复时,让关联的上下文信息在当前线程生效,在协程挂起时,再让上下文信息在当前线程失效。
在 iOS 中,主要基于 activity tracing 机制来保持上下文信息的有效性。通过 activity tracing 机制,在一个业务链路开始时,会自动创建一个 activity,我们把上下文信息与 activity 进行关联。在当前 activity 作用域范围内,所有产生的数据都会与当前上下文自动关联。
基于这两种方案,在产生 Trace 数据时,SDK 会按照 OTel 协议的标准,自动把上下文信息关联到当前数据中。最终产生的数据,会以一棵树的形式进行逻辑关联,树的根节点就是 Trace 链路的起点。这种方式,不仅支持协程/线程内的数据自动关联,还支持多层级嵌套。
三方框架的数据采集和串联

针对三方框架的数据采集,我们先看看业内通行的做法,目前主要有两类:
如果三方库支持拦截器或代理的配置,一般会通过在对应拦截器增加埋点代码的方式来实现;
如果三方库对外暴露的接口比较少,一般会通过 Hook 或其他方式增加埋点代码,或者不支持对应框架的埋点。
这种做法会存在两个主要的问题:
埋点不完全,拿 OkHttp 来举例说明,三方 SDK 内部也可能存在对 OkHttp 的依赖,通过拦截器的方式,可能只支持当前业务代码的埋点采集,三方 SDK 的网络请求信息无法被采集到,会导致埋点信息不完全;
可能需要侵入业务代码,为了实现对应框架的埋点,需要有一个切入时机,这个切入时机往往需要在对应框架初始化时增加代码配置项来实现。
如何解这两个问题?
我们使用的方案是实现一个 Gradle Plugin,在 Plugin 中对字节码进行插桩处理。我们知道,Android App 在打包的过程中,有个流程会把 .class 文件转为 .dex 文件,在这个过程中,可以通过 transform api 对 class 文件进行处理。我们是借助 ASM 的方式来实现 class 文件的插桩处理。在对字节码处理的过程中,需要先找到合适的插桩点,然后注入合适的指令。
这里拿 OkHttp 的字节插桩进行举例:插桩的目标是在 OkHttpClient 调用 newCall 方法时,把当前线程的上下文信息关联到 OkHttp 的 Request 中。在 Transform 过程中,我们先根据 OkHttpClient 的类名过滤出目标 class 文件,然后再根据 newCall 这个方法名过滤要插桩的方法。接下来,需要在 newCall 方法开始的地方把上下文信息插入到 request 的 tags 对象中。经过我们的分析,需要在 newCall 方法调用开始的时候,插入目标代码。为了方便实现和调试,我们在扩展库中实现了一个 OkHttp 的辅助工具,在目标位置插入调用这个工具的字节码,传入 request 对象就可以了。
插入后的字节码会和扩展库进行关联。这样就能解决三方框架数据采集和上下文自动关联的问题。
相对于传统做法,使用字节码插桩的方案,业务代码侵入性会更低,埋点对业务代码和三方框架都能生效,同时结合扩展库也能完成上下文的自动关联。
如何确保性能

在可观测数据采集过程中,会有大量的数据产生,对内存、CPU 占用、I/O 负载都有一定的性能要求。
我们基于 C 对核心部分进行实现,确保多平台的性能一致性,并从三个方面对性能做了优化:
首先,是对协议化处理过程进行优化。数据协议方面选择使用 Protocal Buffer 协议,Protocal Buffer 相对 JSON 来说,不仅速度更快,而且更省内存空间。在协议的序列化上,我们采用了手动封装协议的实现,在序列化的过程中,避免了很多临时内存空间的开辟、复制以及无关函数的调用。
其次,在内存管理方面,我们直接对 SDK 的最大使用内存做了可配置的大小限制。内存的使用,可以根据业务情况按需配置,避免 SDK 内存占用过大对 App 的稳定性造成影响;其次,还引入了动态内存管理机制,内存空间的使用按需增加,不会一直占用 App 的内存空间,避免内存空间的浪费。同时还提升了字符串的处理性能。在字符的处理上,引入了动态字符串机制,它可以记录字符串自身的长度,获取字符长度时,操作复杂度低,而且可以避免缓冲区溢出,同时也可以减少修改字符串时带来的内存重分配次数。
最后,在文件缓存管理方面,我们也限制了文件大小的上限,避免对端设备存储空间的浪费。在缓存文件的落盘处理上,我们引入了 Ring File 机制,把缓存数据存储在多个文件上面,以日志文件组的形式对多个文件进行组装。整个日志文件组以环形数组的形式,从头开始写,写到末尾再回到头重新循环写。通过这种方式写数据,可以减少写文件时的随机 Seek,而且 Ring File 的机制,可以确保单个日志文件不会过大,从而尽可能的降低系统 I/O 的负载。除了 Ring File 的机制外,还把断点保存、缓存清理的逻辑放到了一起聚合执行,减少随机 Seek。checkpoint 的文件大小也做了限制,在超出指定大小后会对 checkpoint 文件进行清理,避免 checkpoint 文件过大影响文件读写效率。
经过上面的这些优化措施之后,最终 SDK 采集数据的吞吐量提升了 2 倍,内存和 CPU 占用都有明显的降低。每秒钟最高可支持 400+条数据的采集。
如何确保日志不丢失?

性能满足要求还不够,还需要确保采集到的数据不能丢失。在 App 的使用过程中,app 经常可能会出现异常崩溃,手机设备异常重启,以及网络质量差,网络延时、抖动大的情况。在这类异常场景下,如何确保采集到数据不会丢失?
在采集数据时,我们使用了预写日志(WAL)机制,并结合自建网络加速通道来优化这个问题。
引入预写日志机制的目的是确保写入到 SDK 的数据,在发送到服务器之前,不会因为异常原因而丢失。这个过程的核心是,在数据成功发送到服务器之前,先把数据缓存在移动设备的磁盘上,数据发送成功之后,再移除磁盘上的缓存数据。如果因为 App 异常原因,或者设备重启导致数据发送失败,因为缓存的数据还在,SDK 会根据记录的断点信息对数据发送进度进行恢复。同时预写日志机制可以确保数据的写入和发送并发执行,不会互相阻塞;
在数据发送之前,还会对多条数据做聚合处理,并通过 lz4 算法进行压缩处理,这种做法可以降低数据发送时的请求次数和网络传输流量的消耗。如果数据发送失败,还会有重试策略,确保数据至少能成功发送一次;
在数据发送时,SDK 支持就近接入加速边缘节点,并通过边缘节点与 SLS 之间的内部网络加速通道传输数据。
经过这三种主要的方式优化之后,数据包的平均大小降低了 2.1 倍,整体的 QPS 平均提升 13 倍,数据整体的发送成功率达到了 99.3%,网络延时平均下降了 50%。
多系统数据关联处理
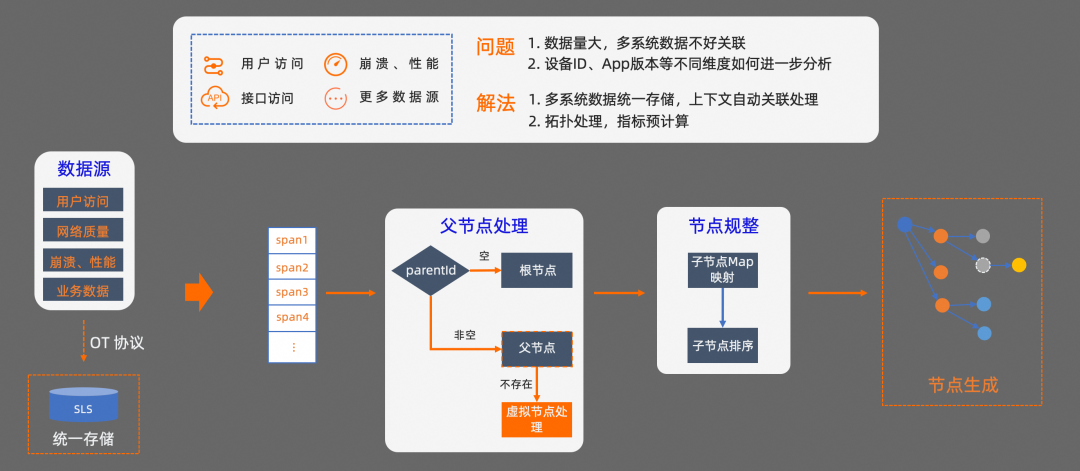
解决了端侧数据的串联和采集性能问题之后,还需要处理多系统之间的数据存储和关联分析问题。
数据存储方面,我们直接基于 SLS LogHub 能力,把相关的数据统一存储,基于 SLS,日均可以承载 PB 级别的流量,这个吞吐量可以支持移动端可观测数据的全量采集。
解决了数据的统一存储问题之后,还需要处理两个主要的问题。
第一个问题,不同系统可观测数据之间的上下文关联如何处理?
根据 OTel 协议的约束,我们可以基于 parent_id 和 span_id 来处理根节点、父节点、子节点之间的映射关系。首先,在查询 Trace 数据链路时,会先从 SLS 拉取一定时间段内的所有 Trace 数据。然后按照 OTel 协议的约束,对每条数据进行节点类型的判定。由于多系统的数据可能存在延时,在查询 Trace 数据链路时,有些数据可能还没有到达。我们还需要对暂时不存在的父节点进行虚拟化处理,确保 Trace 链路的准确性。接下来,还需要对节点进行规整处理,把属于同一个 parent_id 的节点进行聚合,然后再按照每个节点的开始时间进行排序,最终就可以得到一条 trace 链路信息,基于这个链路信息,我们可以还原出系统的调用链路。
第二个问题, 在进行 Trace 分析时,我们往往还需要从系统视角出发,对不同维度的数据进一步分析。比如,如果想从设备 ID、App 版本、服务调用等不同维度,对 Trace 数据进一步分析,该怎么做?我们来看一下怎么解决这个问题。
多系统数据拓扑生成

当我们从系统整体视角对问题进行分析时,所需要的 Trace 数据规模往往会比较大,每分钟可能有数千万条数据,而且对数据的时效性要求也比较高。传统的流处理方式在这种场景下很容易遇到性能瓶颈问题。我们采用的方案是,把流处理问题转换为批处理问题,把传统的链路处理视角转换为系统处理视角。经过视角转化之后,从系统视角来看,解决这个问题最主要的核心,就是如何确定两个节点之间的关系。
我们看一下具体的处理过程。在批处理上,我们使用了 MapReduce 框架。首先,在数据源处理阶段,我们基于 SLS 的定时分析(ScheduledSQL)能力,对数据进行聚合处理,按照分钟级从 Trace 数据源中捞取数据。在 Map 阶段,先按照 traceID 进行分组,对分组之后的数据再按照 spanID、parentID 维度对数据进行聚合。然后计算出相关的统计数据,如成功率、失败率、延时指标等基础统计数据。在实际的业务使用中,往往还会采集一些和具体业务属性相关的数据,这部分数据往往会根据业务的不同,有比较大的差异。针对这部分类型的数据,在聚合处理的过程中,支持按照其他维度对结果进行分组。此时会得到两种中间产物:
包含两个节点关系的聚合数据,我们把这种类型的数据,叫做边信息
以及未匹配到的原始数据
这两种中间产物,在 Combine 阶段还会再进行聚合处理,最终会得到包含基础统计指标,以及其他维度的结果数据。
最终产物会包含几个主要的信息:
边信息,可以体现调用关系。
依赖信息,可以体现服务依赖关系。
还有指标信息,以及其他资源信息等。其中,业务属性相关的数据会体现在资源信息中。
基于这些产物,我们可以通过对资源、服务等信息的多个维度筛选,来统计出对应维度的问题分布和影响链路。
自动化问题根因定位探索
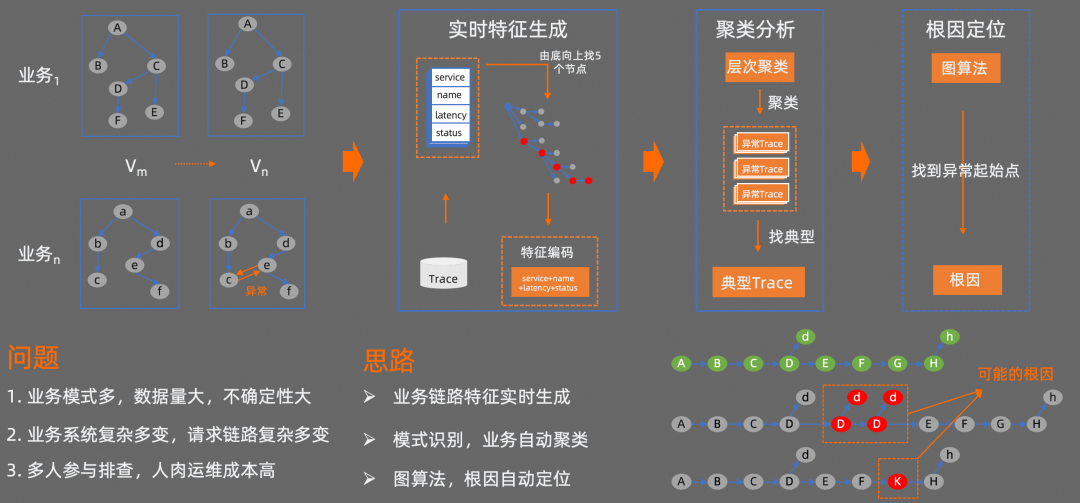
接下来向大家介绍下,我们在自动化问题根因定位方向的一些探索。
我们知道,随着 App 版本的迭代,每次 App 的发版可能会涉及到多个业务的代码变更。这些变更,有的经过充分测试,也有的未经过充分测试,或者常规测试方法没有覆盖到,对线上业务可能会产生一定的潜在影响,导致部分业务不可用。App 规模越大,业务模式越多,对应的业务数据量,请求链路,不确定性就越大。出了问题之后,往往需要多人跨域参与排查,人肉运维成本比较高。
如何在端侧问题排查定位方向,通过技术手段进行研发效能的提速? 我们基于机器学习技术做了一些探索。
我们目前的方法是,先对 Trace 源数据进行特征处理;然后再对特征进行聚类分析,去找到异常 Trace;最后再基于图算法等,对异常 Trace 进行分析,找到异常的起始点。
首先,实时特征处理阶段会读取 Trace 源数据,对每个 Trace 链路按照由底向上找 5 个节点的方式生成一个特征,并对特征进行编码。然后对编码之后的特征通过 HDBSCAN 算法进行层次聚类分析,此时相似的异常会分到同一个组里面,接下来再从每组异常 Trace 中找出一条典型的异常 Trace。最后,通过图算法找到这条异常 Trace 的起点,从而确定当前异常 Trace 可能存在的问题根因。通过这种方式,只要是遵循 OTel 标准协议的数据源都能够进行处理。
案例:多端链路追踪

经过对数据处理之后,我们来看下最终的效果。
这里有一个模拟 Android、iOS、服务端,端到端链路追踪的场景。
我们使用 iOS App 来作为指令的发送端,Android App 来作为指令的响应端,用来模拟远程打开汽车空调的操作。我们从图上可以看到,iOS 端“打开车机空调”这个操作触发后,依次经过了“用户权限校验”、“发送指令”、“调用网络请求”等环节。Android 端收到指令后,依次执行“远程启动空调”、“状态检查”等环节。从这个调用图可以看得到,Android、iOS、服务端,多端链路被串联到了一起。我们可以从 Android、iOS、服务端的任何一个视角,对调用链路进行分析。每个操作的耗时,对应服务的请求数,错误率,以及服务依赖都能体现出来。
整体架构
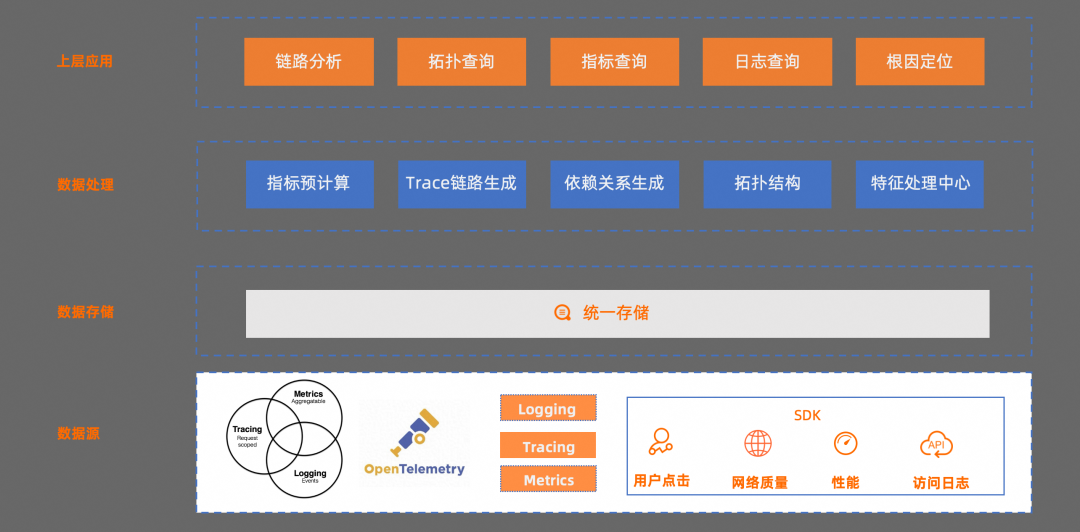
接下来,我们来看下整套解决方案的架构:
最底层是数据源,遵循 OTel 协议,各个端对应的 SDK 按照协议规范统一实现;
数据存储层,是直接依托于 SLS LogHub,所有系统采集到的数据统一存储;
再往上是数据处理层,对关键指标、Trace 链路、依赖关系、拓扑结构、还有特征等进行了预处理。
最后是上层应用,提供链路分析、拓扑查询、指标查询、原始日志查询,以及根因定位等能力
后续规划

最后总结下我们后续的规划:
在采集层,会继续完善插件、注解等方式的支持,降低业务代码的侵入性,提升接入效率
在数据侧,会丰富可观测数据源,后续会支持网络质量、性能等相关数据的采集
在应用侧,会提供用户访问监测、性能分析等能力
最后,我们会把核心技术能力开源,共享社区。


![Python【r e】模块正则表达式[中]实战](https://img-blog.csdnimg.cn/img_convert/98f33575fd1b305db60516c806d8f792.png)