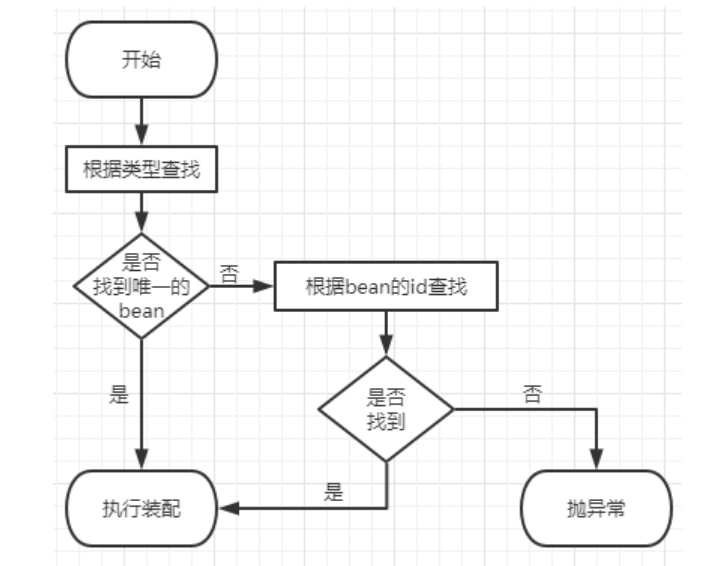
正则表达式相关函数和符号用法:
#正则表达式
"""
.匹配任意某个字符
[.]与转义字符的作用一致,表示匹配.,配合 + ,[.]+,即匹配一次或则多次.
text = . 或则 text = ...
2.从头匹配或者从左往右匹配
re.match()
"""
import re
# text = 'suanliguicai'
# result = re.match('guicai',text)
# print(result.group())
#会报错的 AttributeError:“NoneType”对象没有属性“group”
#正确用法,match函数的作用,从匹配资料开头查看,有没有被match匹配到的内容,如果开头有那就提取出来,否则报错
# text = 'suanliguicai'
# result = re.match('guicai',text)
# print(result.group())
# search()函数:从左往右遍历,如果找到第一个符合要求的数据就会停止,即便有第二个第三个也不会被提取出来
#h很明显’i‘,有好几个
# text = 'suanliguicai'
# result = re.search('i+?',text)
# print(result.group())
#3. ^ 在正则表达式中表示 非,比如 \w在正则表达式中表示大小写字母从a - z,数字,制表符,空格,[^\w],表示除去以上说的那些,比如就可以匹配到符号
# text = "suanlil,ig.uicaicai"
# result = re.search('[^\w]+',text)
# print(result.group())
#4.^ 符号在中括号的外部,表示从那个字符开始匹配
# text = "suanlil,ig.uicaigcai"
#从a b c d ,.....x y z,随意那个字符开始,这里有个问题,就是所指的指定字符并不是真正意义的指定,必须是从左往右,第一个所出现的字符
#比如text中第一个字符是 s,或者是 su 或者suan,不能写成我想从 i 开始所以我在 [] 中写成 [i],这些显然会报错,所以能写成 [s]或者[su]或者[suan],这样是不是和match函数表达的效果一致的
# result = re.search('^[a-z]+',text)
# print(result.group())
#5. * 匹配一个或者多个字符
#问题:出现错误
# text = "suanliguicaiandcaicai"
# result = re.search('[cai]+?',text)
# print(result.group())
# $ 表示以xx为结尾 我想实现从中一个一个提取,拿到符合要求的数据,如果不符合会报错,但是这个小可爱,
# text_list = ['python123@163.com','python@qq.com123']
# for result in text_list:
# print(result)
# result1 = re.match('[\w]?@[a-z0-9]?\.com$',result)
# print(result1.group())
#6. | 或者 [|] 一个一个匹配
# text = 'https://weibo.com/'
# result = re.search('htt|http|https|file',text)
# print(result.group())
# (|)
# text = 'https://weibo.com/'
# result = re.search('(htt|http|https|file)+',text)
# print(result.group())
#[|] 至于 | 和 [|] 是不一样的,|表示在选择项中如果第一个能匹配到文件的开头那就拿出来,第一个不行那就换第二个,第二个不行那就拿第三个直到有效选项匹配完毕
#[|] 应该是单个字符去匹配,如果第一个选项中从第一个字符开始匹配最后一个字符都满足那就拿出来,哪怕有一个字符不满足就会换下一个选项
text = 'htttpts://weibo.com/'
# result = re.match('[t]+',text)
# result2 = re.search('[\w]+',text)
result2 = re.search('[t]+',text)
#正则表达式和字母匹配是有区别的,\w 可以包括任何字母,但是t只能表达t啊,t*应该匹配更多的t啊为啥不是,
# print(result.group())
# print(result2.group())
#经过测试,这个和函数有关系search表示是从数据中去匹配,肯定是从左往右,如果开头没有匹配上可以换一个字母,如果是match函数开头没有匹配的上那就挂了
"""
#贪婪模式中是符合我的要求的
text = 'pythonpythonand'
result = re.match('[python]+',text)
print(result.group())
#本次贪婪模式是不符合我的要求的
text = 'pythonpythonandpythonpythonpython'
result = re.compile('[python]+').findall(text)
print(result) # 为什么会返回n我也不理解
"""
fuck = """
python123@163.com
python@qq.com123
"""
# 可以这样把爬取的邮箱转换成字符串来用正则表达式提取
# print(type(fuck))
p = re.compile('[\w]+@[a-z0-9]+[.]com$').findall(fuck)
# print(type(p))
for result in p:
print(result)
# [\d\D],[\w\W]: 匹配所有的字符
# 转义字符 \ 在正则表达式\符号 返回符号原本的释义
#. 在utf-8符号表示 符号 点的含义,在正则表达式中表示任意字符,如果我们想要在正则表达式式让 . 恢复它原本符号点的释义,就应该在符号. 的前面加上\ ,\.或者[.]
pi = '******suanliguicai****'
result = re.search('\**[a-z]+\*+',pi)
print(result.group())
实战项目:(有注释地方大家可以放开试试,这是我用了两个函数实现同一效果)
我想获取的文字信息是: