论文题目:Towards Open World Object Detection
1 摘要
人类有一种识别其环境中未知物体实例的自然本能(natural instinct)。当这些未知的实例最终获得相应的知识时,对它们的内在好奇心有助于了解它们。这促使我们提出一种新的计算机视觉问题称为:“开放世界对象检测”,一个模型的任务是: 1)识别对象没有被引入“未知”,没有明确的监督,2)当相应的标签逐渐被接收到时,逐步学习这些被识别出的未知类别,而不忘记之前学习到的类别。我们提出了这个问题,引入了一个强大的评估协议,并提供了一个新的解决方案,ORE:Open World Object Detector,基于对比聚类和基于能量的未知识别。我们的实验评估和消融研究分析了ORE在实现开放世界目标方面的效果。作为一个有趣的副产品,我们发现识别和描述未知实例有助于减少增量对象检测设置中的混淆,在此设置中,我们实现了最先进的性能。
2 理论介绍
2.1 Open World Object Detection
让我们在本节中介绍Open World Object Detection的定义。在任何时间
t
t
t,我们考虑已知对象类的集合为
K
t
=
{
1
,
2
,
.
.
,
C
}
⊂
N
+
K_t =\left\{1,2, .. ,C\right\} \subset N+
Kt={1,2,..,C}⊂N+,其中
N
+
N+
N+表示正整数的集合。为了真实地模拟现实世界的动态,我们还假设它们存在一组未知的类
U
=
{
C
+
1
,
…
}
U = \left\{C + 1,…\right\}
U={C+1,…},在推理过程中可能会遇到。假设已知的对象类
K
t
K_t
Kt在数据集
D
t
Dt
Dt =的
{
X
t
,
X
t
,
Y
t
}
\left\{X_t,X_t,Y_t\right\}
{Xt,Xt,Yt}中被标记,其中
X
X
X和
Y
Y
Y分别表示输入的图像和标签。输入图像集包括
M
M
M个训练图像,
X
t
=
{
I
1
,
…
,
I
M
}
X_t = \left\{I_1,…,I_M\right\}
Xt={I1,…,IM}和每个图像的相关对象标签形成标签集
Y
t
=
{
Y
1
,
…
,
Y
M
}
Y_t = \left\{Y_1,…,Y_M\right\}
Yt={Y1,…,YM}。每个
Y
i
=
{
y
1
,
y
2
,
.
.
,
y
K
}
Y_i = \left\{y_1,y_2,..,y_K\right\}
Yi={y1,y2,..,yK}编码一组
K
K
K个对象实例的类标签和位置,即
y
k
=
[
l
k
,
x
k
,
y
k
,
w
k
,
h
k
]
y_k = [l_k,x_k,y_k,w_k,h_k]
yk=[lk,xk,yk,wk,hk],其中
l
k
∈
K
t
l_k∈K_t
lk∈Kt和
[
x
k
,
y
k
,
w
k
,
h
k
]
[x_k,y_k,w_k,h_k]
[xk,yk,wk,hk]分别表示边界框中心坐标、宽度和高度。
The Open World Object Detection设置考虑了一个对象检测模型
M
C
M_C
MC,该模型被训练用来检测之前遇到的所有
C
C
C对象类。重要的是,模型
M
C
M_C
MC能够识别属于任何已知
C
C
C类的测试实例,并且还可以通过识别一个新的或看不见的类实例,将其分类为一个未知的,用标签
0
0
0表示。然后,可以将未知的实例集
U
t
U_t
Ut转发给人类用户,该用户可以识别
n
n
n个感兴趣的新类别(在潜在的大量未知类别中),并提供它们的训练示例。学习者逐步添加
n
n
n个新类并更新自己以生成更新的模型
M
C
+
M_C+
MC+,而无需对整个数据集从头进行再训练。已知的类集也更新了
K
t
+
1
=
K
t
+
{
C
+
1
,
…
…
,
C
+
n
}
K_{t+1} = K_t + \left\{C + 1,……,C + n\right\}
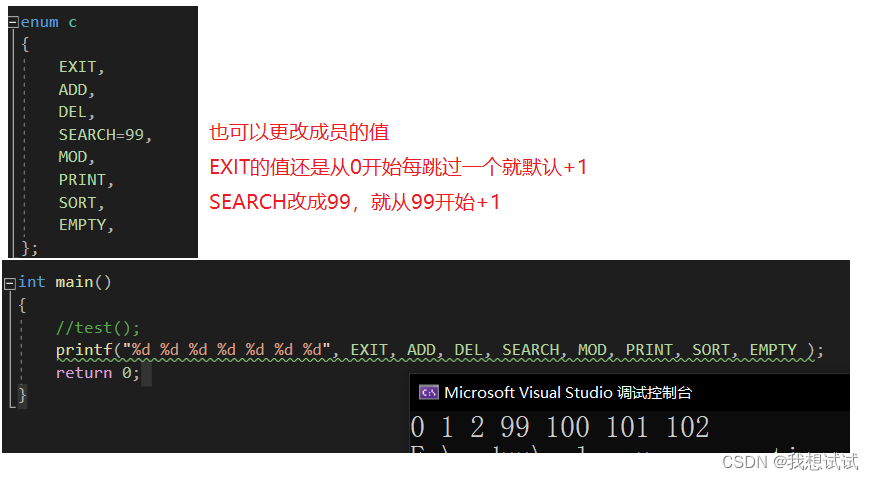
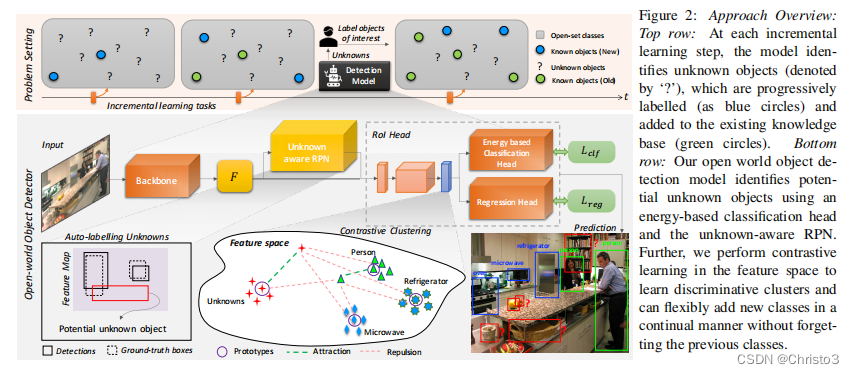
Kt+1=Kt+{C+1,……,C+n}。这个循环在对象检测器的生命周期中持续下去,它用新知识自适应地更新自己。该问题的设置如图2的最上一行所示。
2.2 ORE: Open World Object Detector
一种成功的开放世界对象检测方法应该能够在没有明确监督的情况下识别未知实例,并且在这些识别的新实例的标签呈现给模型进行知识升级(无需从头开始重新训练)时不忘记早期实例。我们提出了一个解决方案,ORE,以统一的方式解决这两个挑战。
图2显示了ORE的高级架构概述。我们选择更快的R-CNN [54]作为基础探测器,因为Dhamija等人[8]发现,与单级视网膜网探测器[31]和基于目标的YOLO探测器[52]相比,它具有更好的开放集性能。更快的R-CNN [54]是一个两阶段的目标检测器。在第一阶段,一个类别不可知的区域建议网络(RPN)提出了一个潜在的区域,这些区域可能具有来自一个共享主干网络的特征图中的一个对象。第二阶段是对每个建议区域的边界框坐标进行分类和调整。由感兴趣区域(RoI)头部中的残差块生成的特征进行对比聚类。RPN和分类头分别适应于自动标记和识别未知数。我们将在下面的小节中解释每个这些相干的组成部分:
2.2.1 Contrastive Clustering
潜在空间中的类分离将是开放世界方法识别未知数的理想特征。实现这一点的一种自然方法是将其建模为一个对比聚类问题,其中同一类的实例将被迫保持近距离,而不同类的实例将被推到很远的距离。
对于每个已知的
i
i
i类
i
∈
K
t
i∈K_t
i∈Kt,我们保持一个原型向量
p
i
p_i
pi。设
f
c
∈
R
d
f_c∈R_d
fc∈Rd是由对象检测器的中间层生成的特征向量,对于类
c
c
c的对象。我们对对比损失的定义如下:
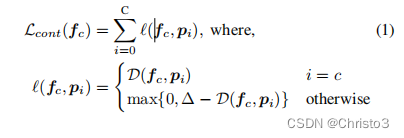
其中
D
D
D是任意距离函数,
∆
∆
∆定义了相似和不同项目的距离。最小化这种损失将确保在潜在空间中实现所期望的类分离。
每个类对应的特征向量的平均值被用来创建类原型集:
P
=
{
p
0
⋅
⋅
⋅
p
C
}
P = \left\{p_0···p_C\right\}
P={p0⋅⋅⋅pC}。维护每个原型向量是ORE的一个关键组成部分。随着整个网络的端到端训练,类原型也应该逐渐演化,因为组成特征的逐渐变化(随着随机梯度下降在每次迭代中通过一个小的步骤更新权值)。我们维护一个固定长度的队列
q
i
q_i
qi,每个类来存储相应的特征。特性存储
F
s
t
o
r
e
=
{
q
0
⋅
⋅
⋅
q
C
}
Fstore = \left\{q0···qC\right\}
Fstore={q0⋅⋅⋅qC},将类特定的特性存储在相应的队列中。这是一种可扩展的方法,用于跟踪特征向量是如何随着训练而演变的,因为存储的特征向量的数量以
C
×
Q
C×Q
C×Q为界,其中
Q
Q
Q是队列的最大大小。

2.2.2 Auto-labelling Unknowns with RPN
同时使用Eqn1计算聚类损失、我们将输入特征向量
f
c
f_c
fc与原型向量进行了对比,其中也包括一个未知对象的原型(
c
∈
{
0
,
1
,
.
.
,
C
}
c∈\left\{0,1,..,C\right\}
c∈{0,1,..,C},其中
0
0
0指未知类)。这将需要将未知的对象实例标记为未知的真实标签类,这在实际上是不可行的,因为需要在已经注释过的大规模数据集中重新注释每个图像的所有实例。
作为替代对象,我们建议自动将图像中的一些对象标记为潜在的未知对象。为此,我们依赖于区域建议网络(RPN)是类不可知论者的事实。给定一个输入图像,RPN为前景和背景实例生成一组边界框预测,以及相应的客观性分数。我们将那些具有高客观性得分,但不与真实标签对象重叠的区域标记为潜在的未知对象。简单地说,我们选择top-k个背景区域建议,按其客观性得分排序,作为未知对象。这个看似简单的启发式实现了良好的性能,如Sec5所示。
2.2.3 Energy Based Unknown Identifier
给定潜在空间
F
F
F中的特征
(
f
∈
F
)
(f∈F)
(f∈F)及其对应的标签
l
∈
L
l∈L
l∈L,我们试图学习一个能量函数
E
(
F
,
L
)
E(F,L)
E(F,L)。我们的公式是基于基于能量的模型(EBMs)[27]学习函数
E
(
⋅
)
E(·)
E(⋅)估计观测变量之间的兼容性
F
F
F和可能的输出变量
L
L
L, 使用一个输出标量,即
E
(
f
)
:
R
d
→
R
E(f):R^d→R
E(f):Rd→R, (EBMs)具有为分布内数据分配低能量值的内在能力,反之亦然,这促使我们使用能量测量方法来描述一个样本是否来自一个未知的类别。
具体地说,我们使用Helmholtz自由能公式,其中L中所有值的能量都被组合起来,
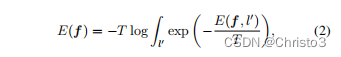
其中,T为温度参数。softmax层后的网络输出与类比能量值[34]的Gibbs分布之间存在着一个简单的关系。这可以被表述为,
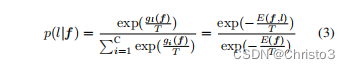
其中
p
(
l
∣
f
)
p(l|f)
p(l∣f)是一个标签
l
l
l的概率密度,
g
l
(
f
)
g_l (f)
gl(f)是分类头
g
(
.
)
g(.)
g(.)的第
l
l
l个分类对分数。利用这种对应关系,我们根据其对数来定义分类模型的自由能如下:
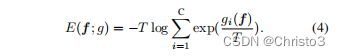
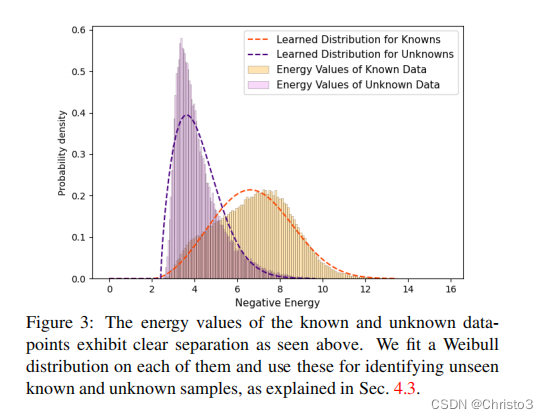
上面的方程为我们提供了一种自然的方法来将标准快速R-CNN [54]的分类头转换为能量函数。由于我们在对比聚类的潜在空间中执行明显的分离,我们在已知类数据点和未知数据点的能级上看到明显的分离,如图3所示。基于这一趋势,我们模拟了已知和未知能量值
ξ
k
n
(
f
)
ξ_kn (f)
ξkn(f)和
ξ
u
n
k
(
f
)
ξ_unk (f)
ξunk(f)的能量分布,并采用了一组移动的威布尔分布。与伽马分布、指数分布和正态分布相比,这些分布可以很好地符合一个小的验证集(包括已知和未知实例)的能量数据。如果
ξ
k
n
(
f
)
<
ξ
u
n
k
(
f
)
ξ_kn (f) < ξ_unk (f)
ξkn(f)<ξunk(f),学习到的分布可以用来将预测标记为未知。
2.2.4 Alleviating Forgetting
略
3 结论
充满活力的对象检测社区已经在很大程度上推动了标准数据集上的性能基准测试。这些数据集和评估协议的封闭集性质阻碍了进一步的进展。我们引入了开放世界目标检测,其中目标检测器能够将未知对象标记为未知对象,并在模型暴露于新的标签时逐渐学习未知对象。我们的关键创新特性包括一个用于未知检测的基于能量的分类器和一个用于开放世界学习的对比聚类方法。我们希望我们的工作将沿着这一重要和开放的方向开展进一步的研究。