解析文档场景下多模态大模型的应用与研究前沿
- 一、TextIn 文档解析技术
- 1. 现有大模型文档解析问题
- 2. 文档解析技术背景
- 3. TextIn 文档解析技术架构
- 4. 版面分析关键技术 Layout-engine
- 二、TextIn 文本向量化技术
- 三、TextIn.com Text Intelligence
一、TextIn 文档解析技术
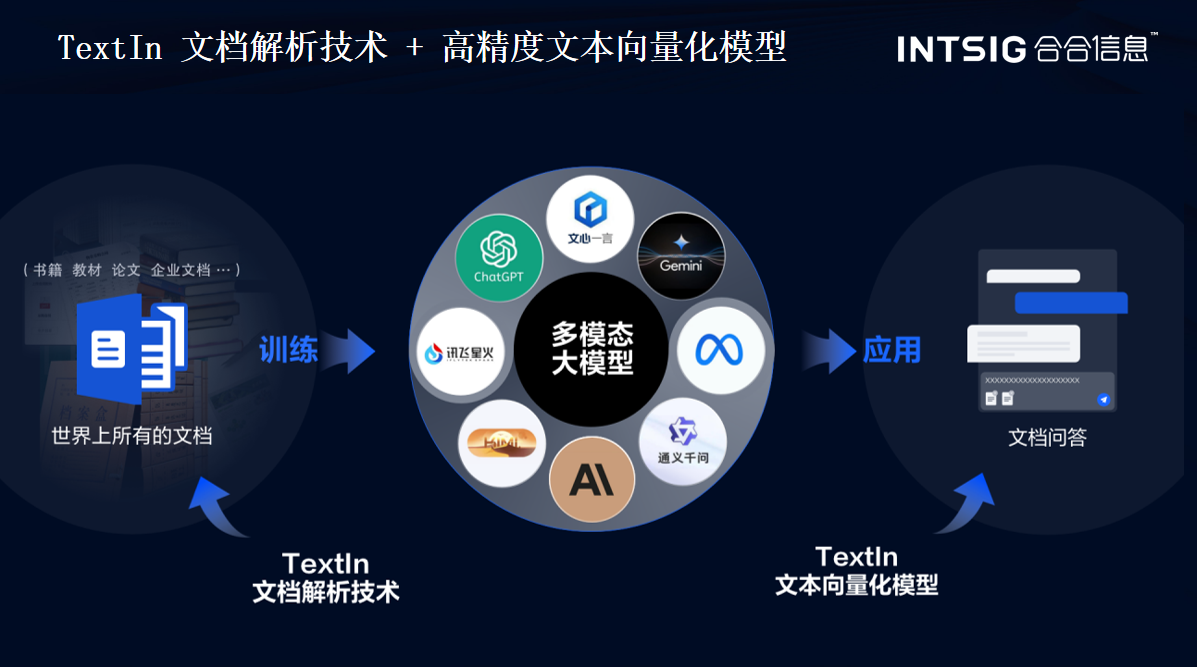
hello,大家好我是恒川,今天我来给大家安利一个非常好用的网站TextIn,它的第一个核心技术是这个文档解析,现存的文档解析存在一些问题,比如表格、无线表无法解析以及阅读顺序的解析错乱的问题,包括扫描版文档以及文档编码的问题等。下面我给大家举几个例子。
1. 现有大模型文档解析问题
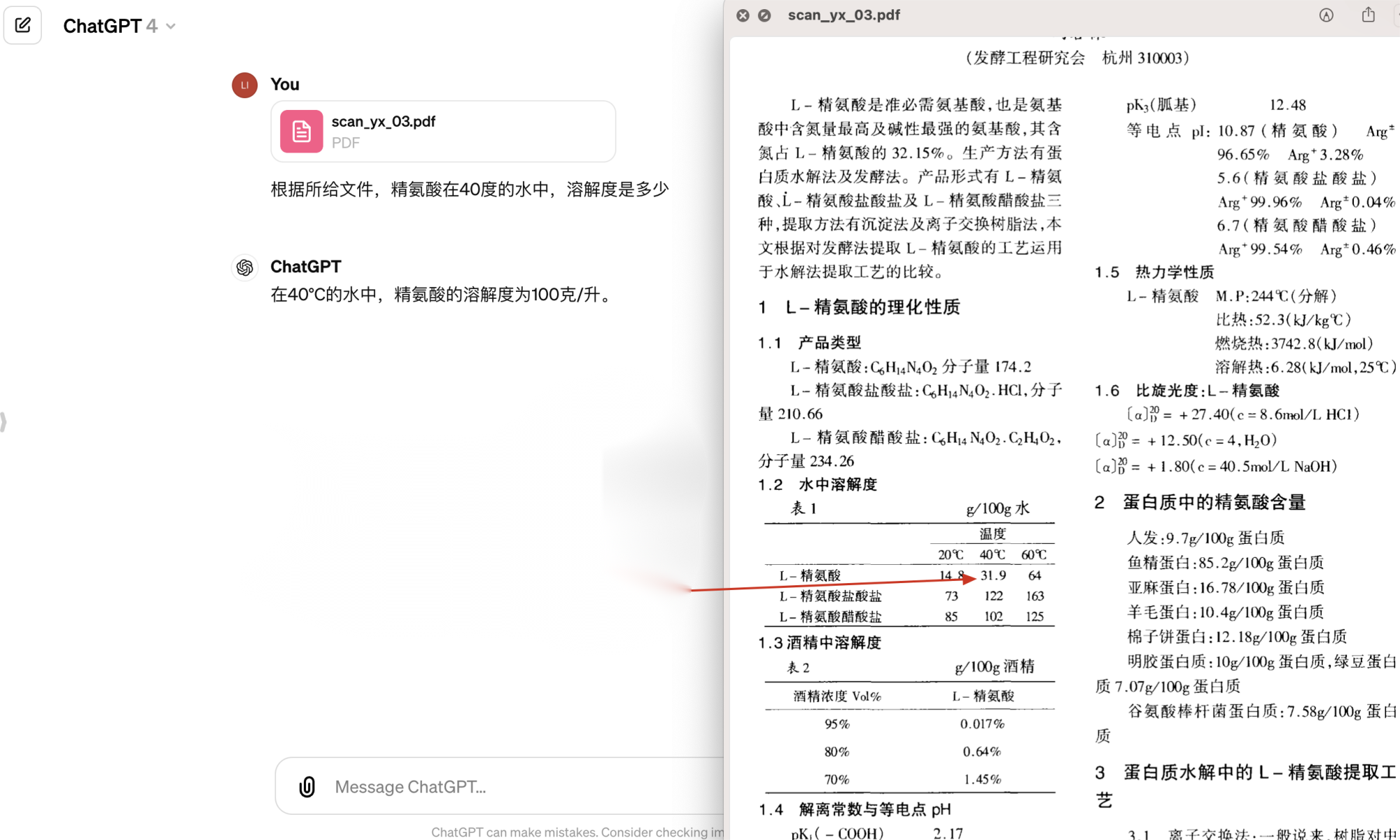
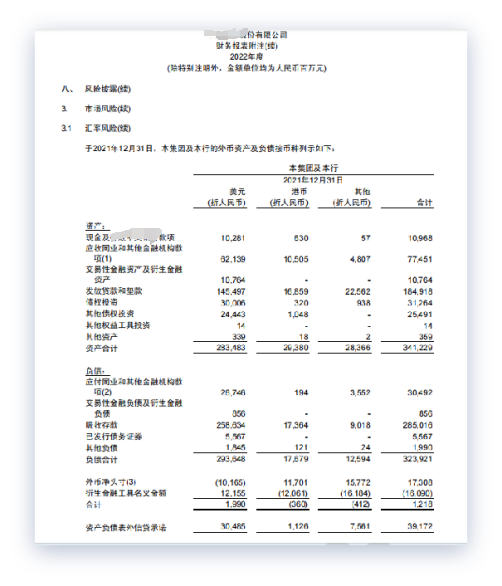
我们将ChatGPT里面输入了一个PDF,这个PDF显示精氨酸在40度的温度下,它的溶解度是31.9,但ChatGPT并没有将这个PDF进行准确的解析,所以他的回答是错误的。
我们再举一个例子。
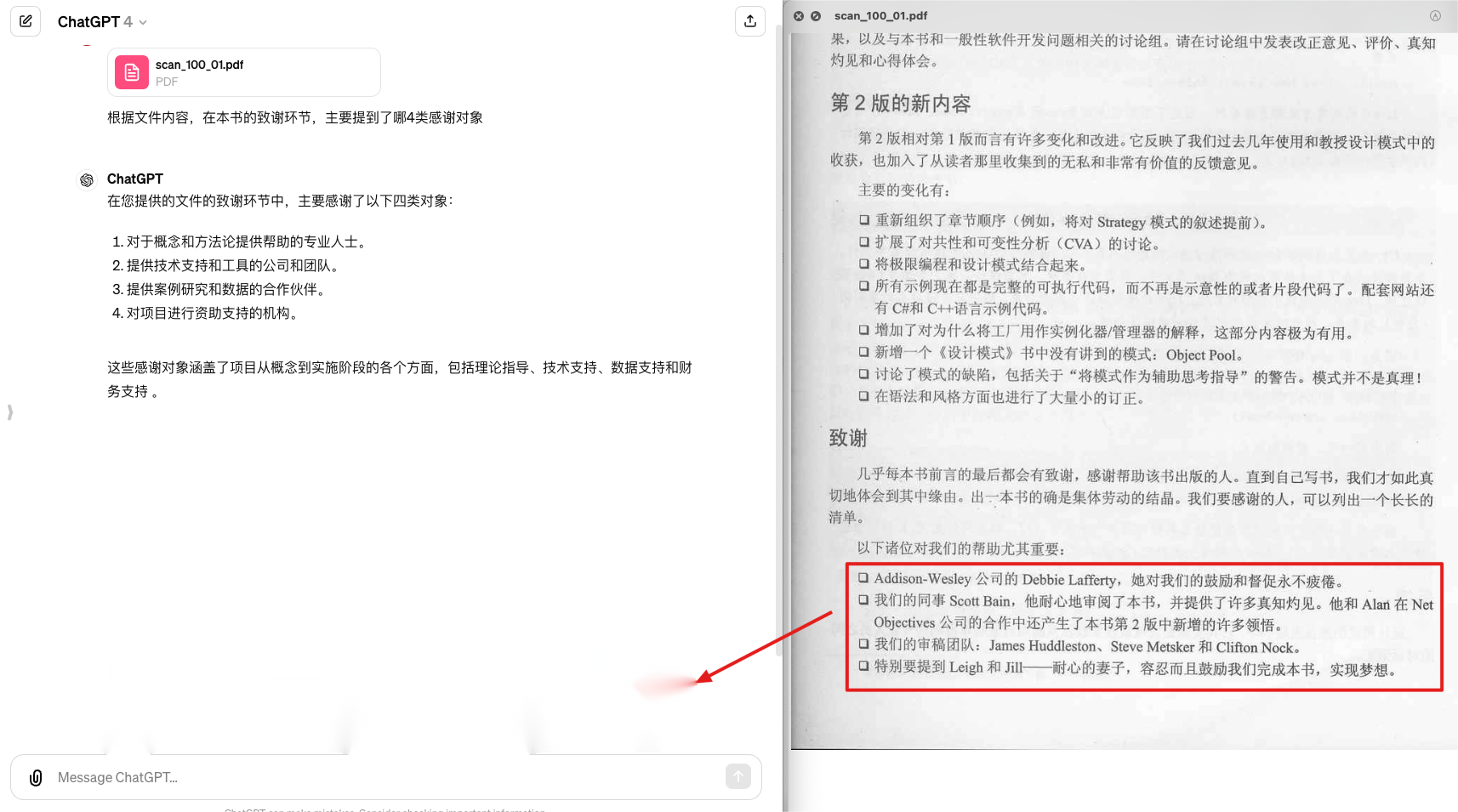
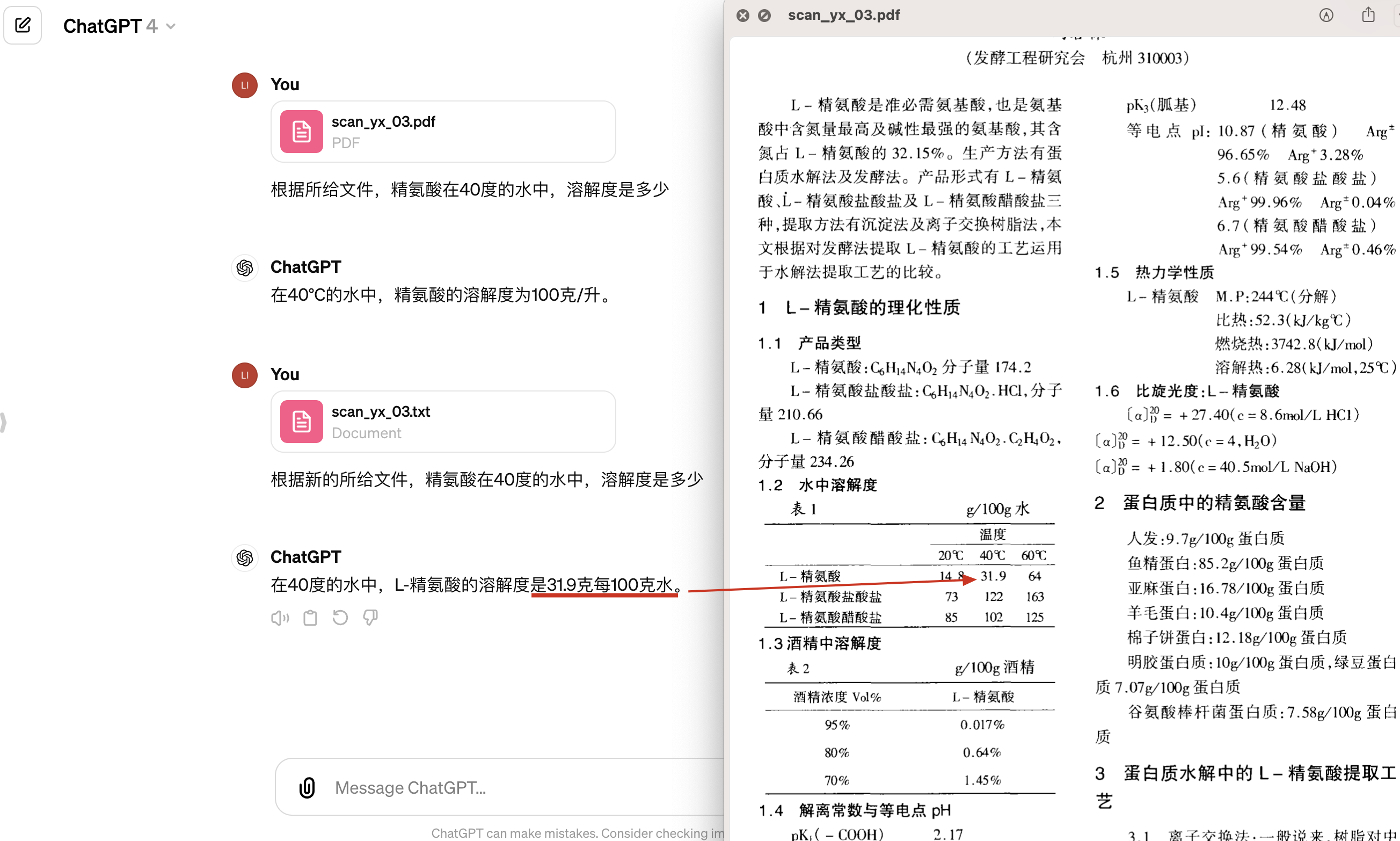
在这个文档的致谢的过程中,我们来问他文中的致谢提到了哪四类感谢对象,实际上他的感谢对象也是错误的,那这个的原因都是在于本身这个文档的解析,阅读顺序错误导致的一些问题,那像这样的一个编码问题依然是存在这个大模型的,无论是训练还是应用的过程之中。
2. 文档解析技术背景
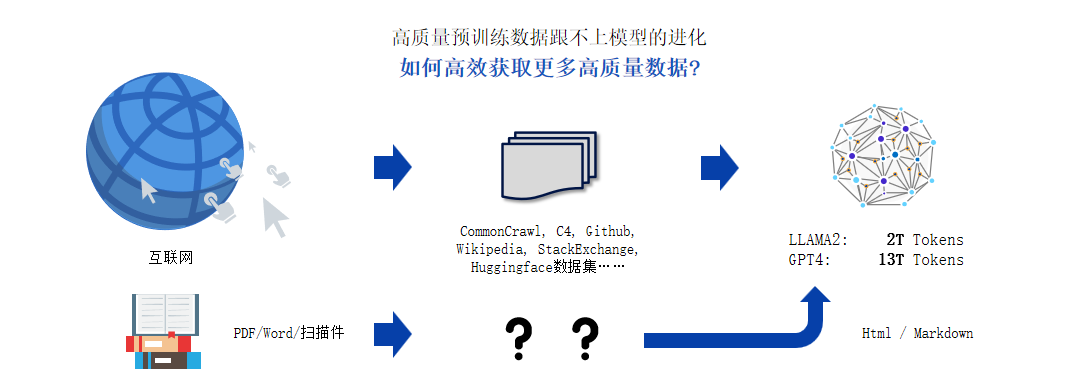
在我们的日常生活中,那我们有什么样的一个诉求呢?在探索多模态大模型在不同应用领域的应用中,如文档智能分析、智能搜索、阅读顺序还原准确、支持论文和多种排版文档等。
接下来我要通过具体案例来展示这些模型在实际应用中的效果和潜力。PDF word在扫描文件时,我们希望在训练和应用的部分可以将这个整体的一个阅读顺序进行还原,包括他的表格、段落、公式和标题相关的一些元素识别准确。以及识别的速度和多样的排版的支持,那我们来看一下在多模态大模型的预训练中,我们需要处理哪些文档?
文档示例

比如这个书籍,或像论文以及产品说明书。
文档解析Pipeline
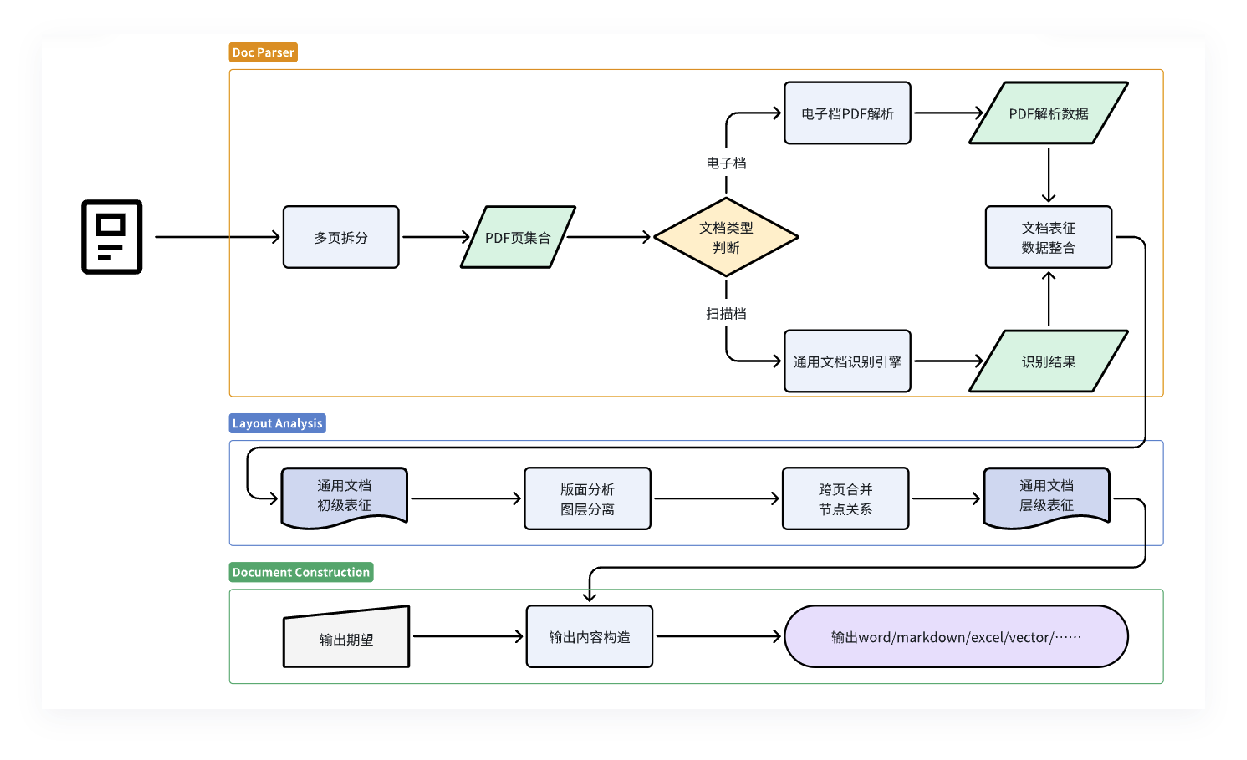
这是一整套的文档解析。分为三个部分,那第一个部分呢,就是将一个多页的文档进行了拆分,并且将其中的电子文档扫描到经过不同的解析引擎,最终形成的一个文档基础的一个特征。第二部分,要将基础文档表中的表格、眉页、目录、文字、图形等等,来做文档的一个绑定分析。以及跨越合并和它几点关系之间的处理,最终的目的是将一个多元异构的不同格式的文档输出成一个有顺序的文档(称之为大模型),那最后一部分就是文档的重建会输出成一个markdown,那简单来说就是他们将一个多种格式,多种版面的PDF最终输出成了一个大模型,能够理解为一个顺序的markdown形式。
接下来给大家举些例子,就是它的技术难点在哪里?

第一个部分是可以看到有元素的印章的遮盖和遮盖文字本身的一个呈现(如上图),那包括页面也有不同的形式以及双栏,三栏和跨页相关的内容。
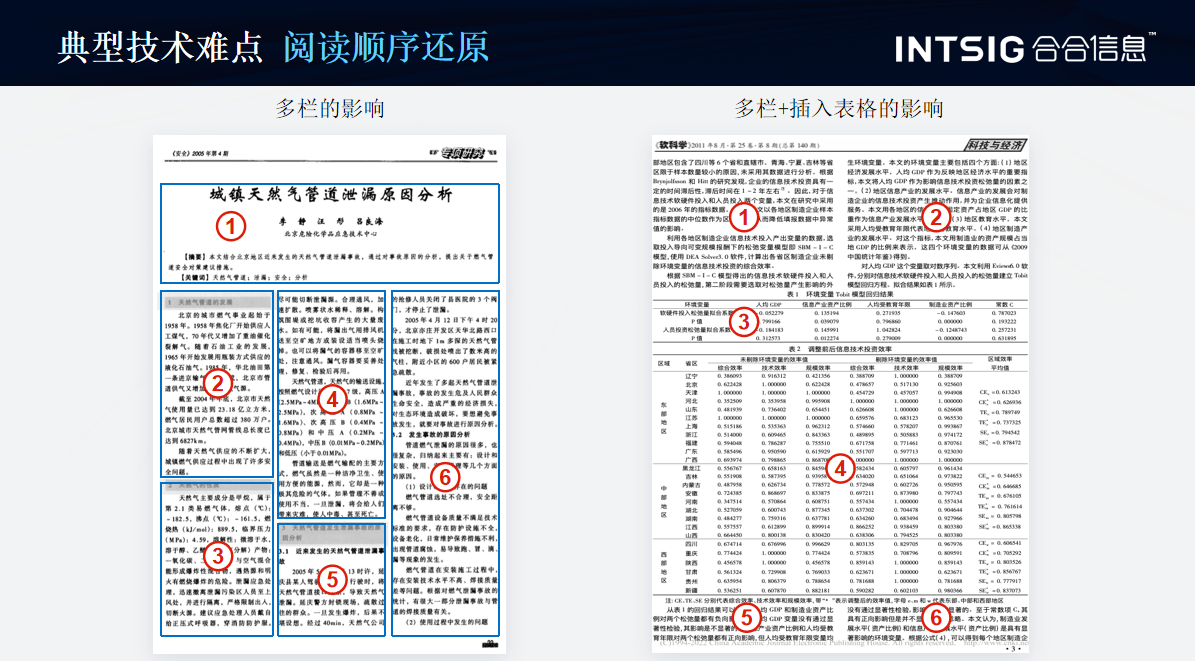
还有一些文档,它的阅读顺序是需要一个准确的排序的,比如像左边(如上图)的这张图,它的顺序先是上面的全栏,在三栏下的每一个是上下的顺序的阅读。那我们来看右边多栏和插入表格的影响,它的顺序是要先将上半部分的双栏进行一和二的阅读,再进行三和四无线表的阅读,最终五和六的双栏。
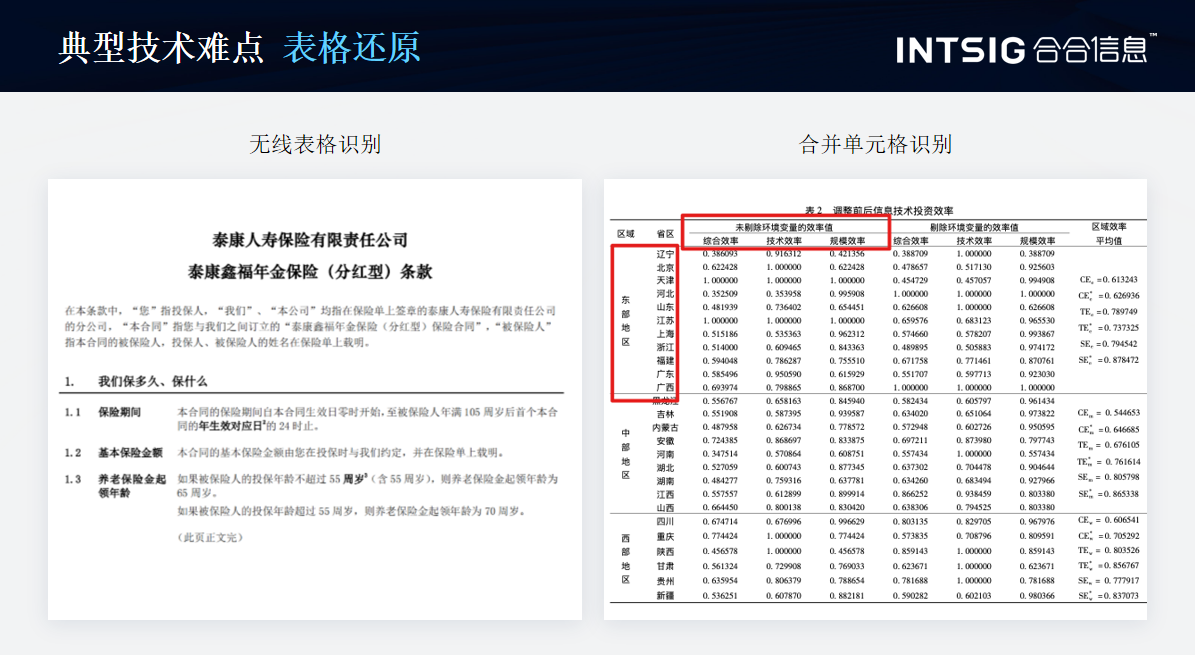
在表格的部分,其实在有线表已经解决不错的情况下,在无线表格的一个解决,包括无线表中我们的三线表合并单元格的一个情况,那这个部分在论文或在报告中都是经常会出现的。

也包括在公式的整体识别和表格内的这个公式的一个识别。
3. TextIn 文档解析技术架构
那整体我们的技术架构是怎么样的?
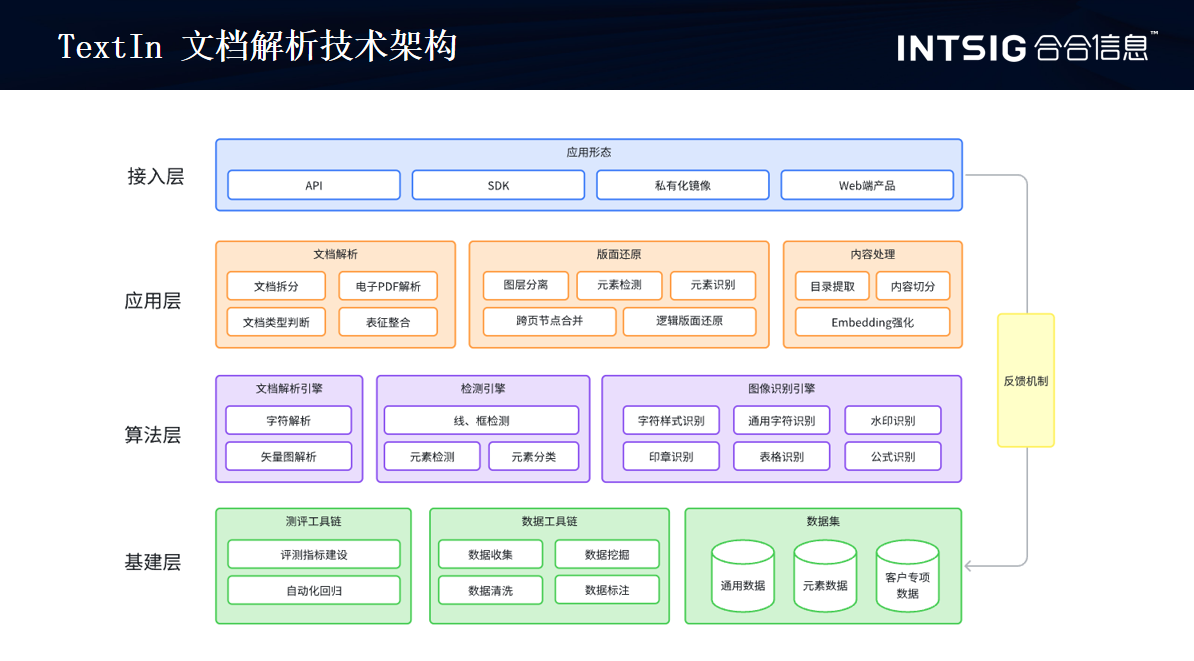
为了解决这些问题,将一个基于数据和基于测评的一个基建,在上方的算法层,是将一个文档的多页拆成单页。同时,将其中的每一个独立的元素进行文档解析,检测以及图像文字的识别。完成了元素的基础表中识别之后,会进行整个文档的一个解析,它包含这个文档类型的判断,包括表当中的一个整合以及整个的版面相关的一个还原,最终还原成了一个完整的阅读顺序。
4. 版面分析关键技术 Layout-engine
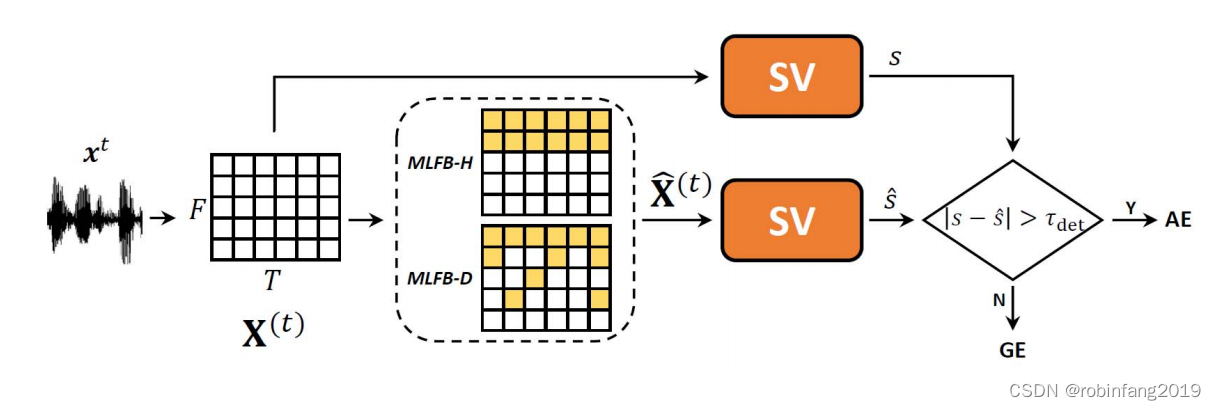
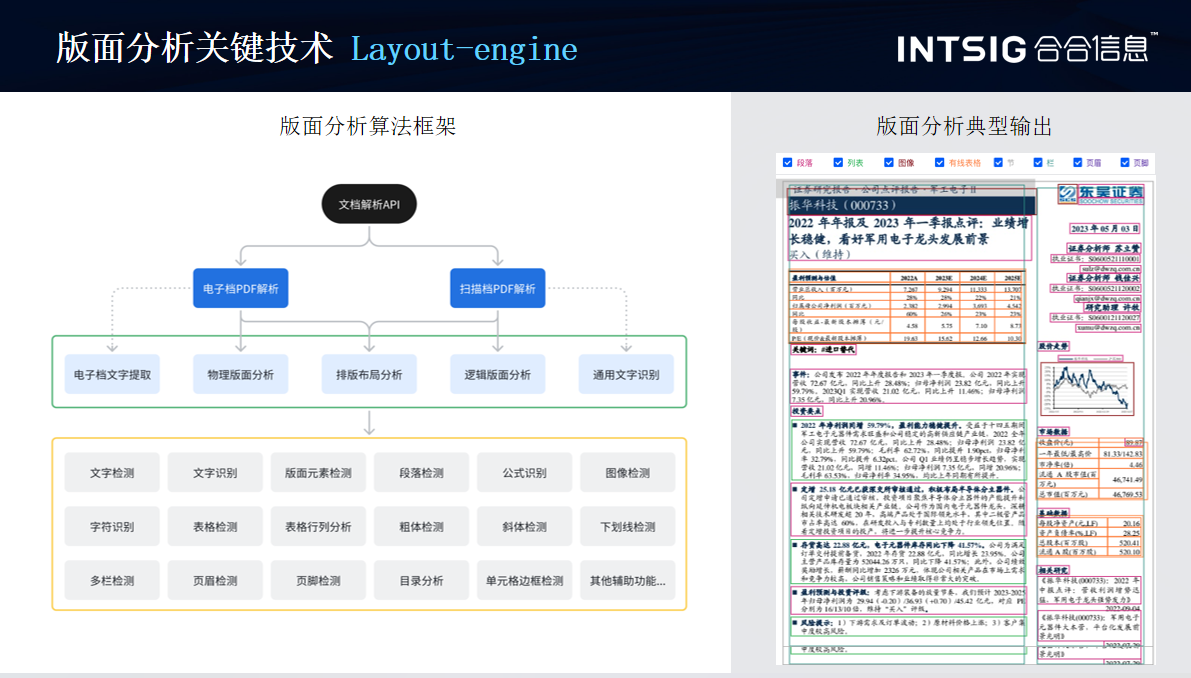
其中的关键技术,我在这里展示两个部分,第一部分是将一个电子档和扫描档经过不同的物理和逻辑版面的分析,最终拿到所有的这个元素,比如有段落、有公式、有图像以及有相关的页眉、页脚、目录,然后再整合成一个可以被大模型顺利阅读的顺序,这一块内容(如下图)右边就是一个典型的一个输出,里面每个内容都有它的类型。
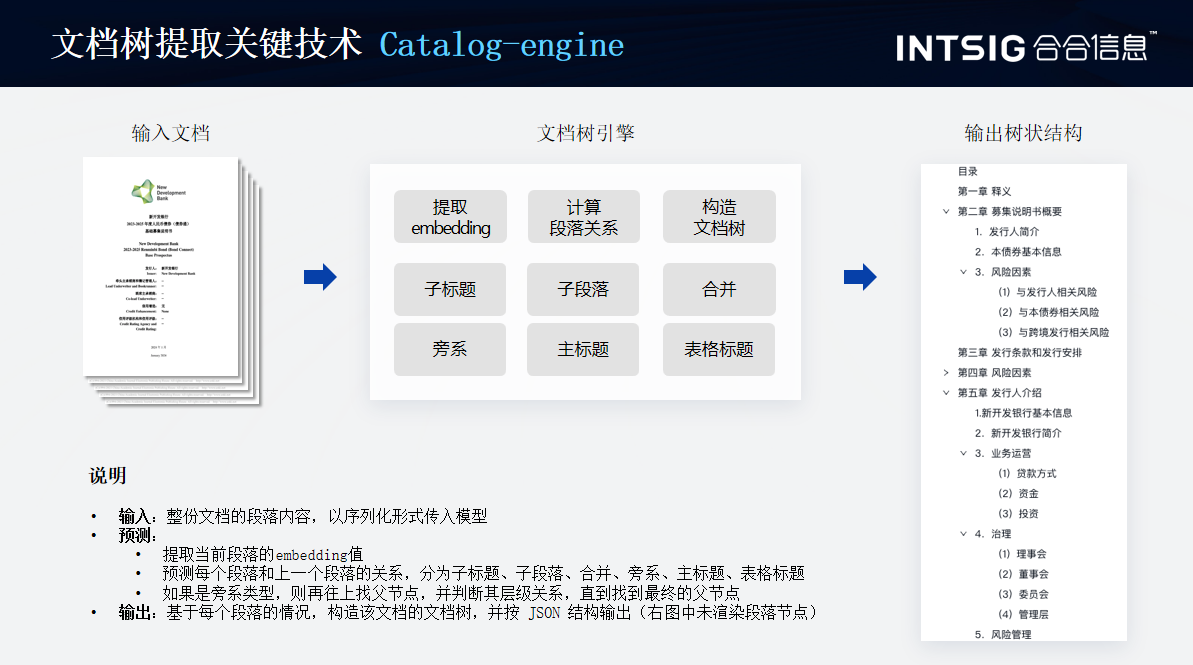
那第二部分呢,其实是大家现在大模型训练中一个重要的部分,它是一个目录树的梳理,因为目录树是一个文档中它结构化的第一层,也是最重要的一层,他们设计了一个文档处理引擎来准确的区分它的子标题、子段落以及主标题和表格的标题。
那我们可以看见这样技术的一个展示(如下图),像这样的一个双栏,它是可以比较准确从左边到右边的一个顺序输出。
我们将这样的一个横栏,再加两双栏进行了一个准确的输出(如下图)。

那第三部分我们可以看非对称的双栏,大概左边占三分之二,右边是占三分之一,而且有图有表,也是进行了一套左边的三分之二的顺序输出,然后进行右边的一个输出,可以看到表格是在这个下方的区域(如下图)。
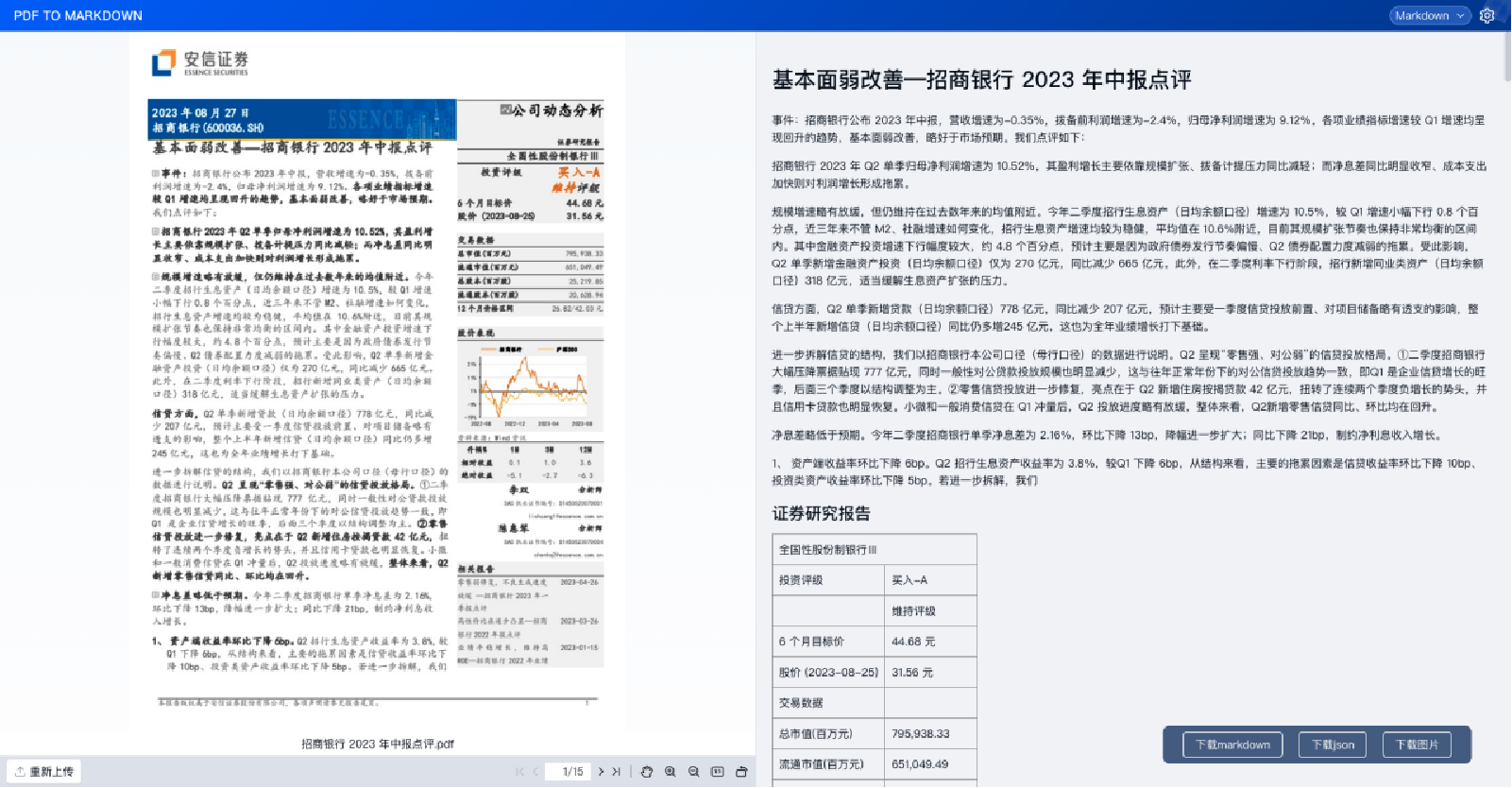
双栏和表格也是比较顺畅的进行了一个准确的输出(如下图)。
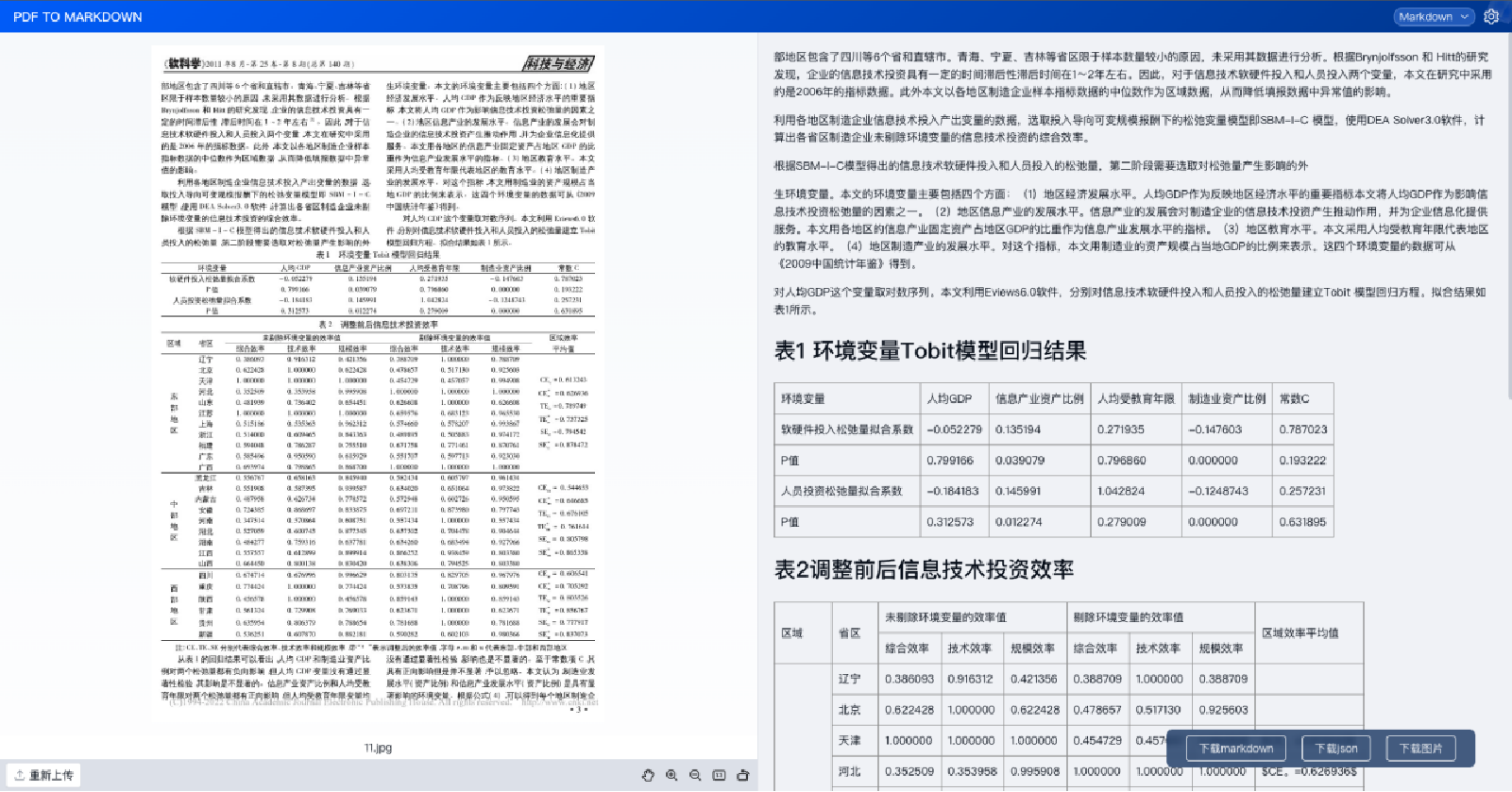
也包括无线表格(如下图)以及单元格的合并(如下图)。
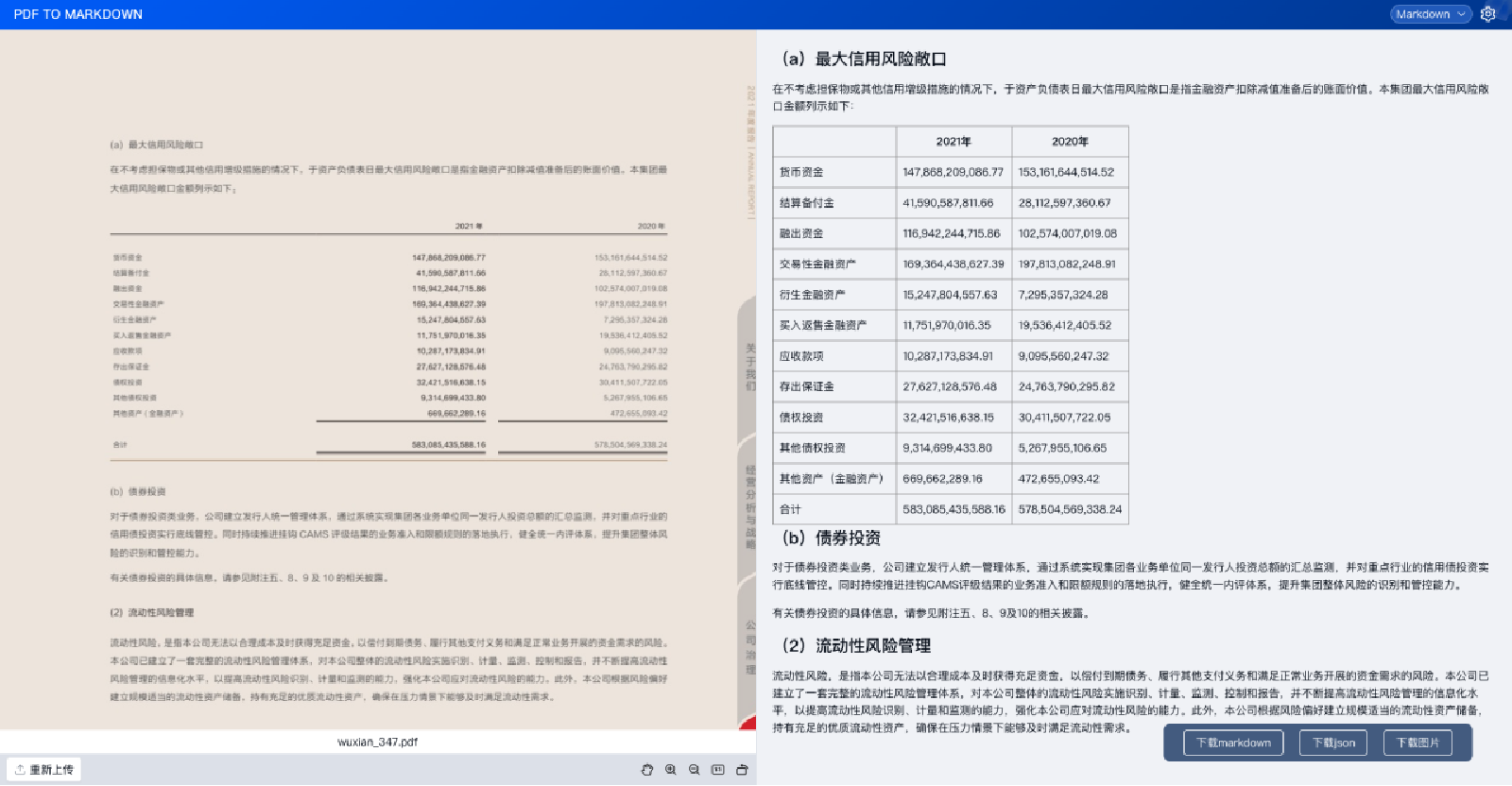
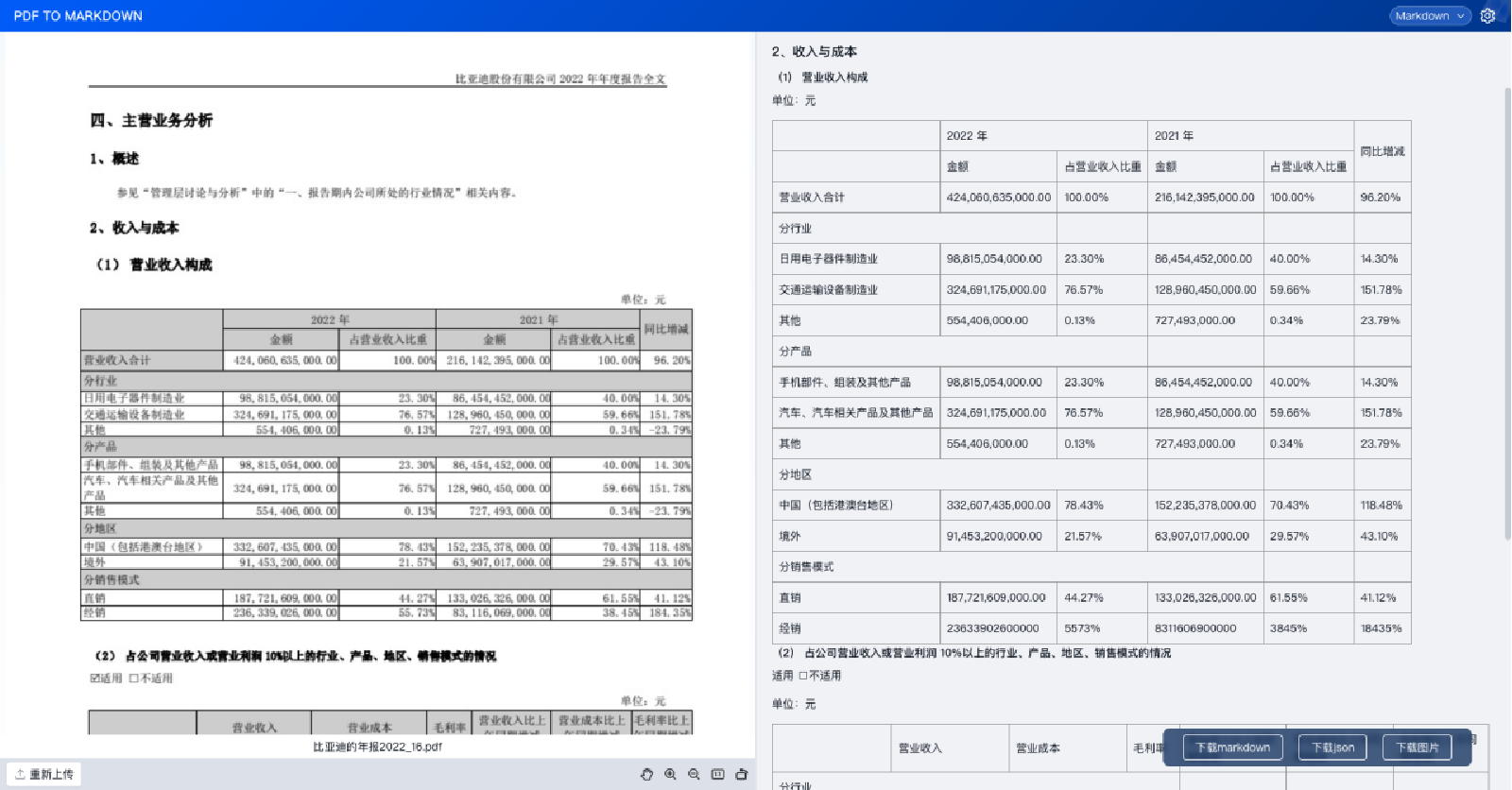
最终的输出形式是在markdown形式之下,所以整个的大模型也是可以来进行一个训练和应用。
那我们可以看到层级目录已经进行了准确的一个识别(如下图)。
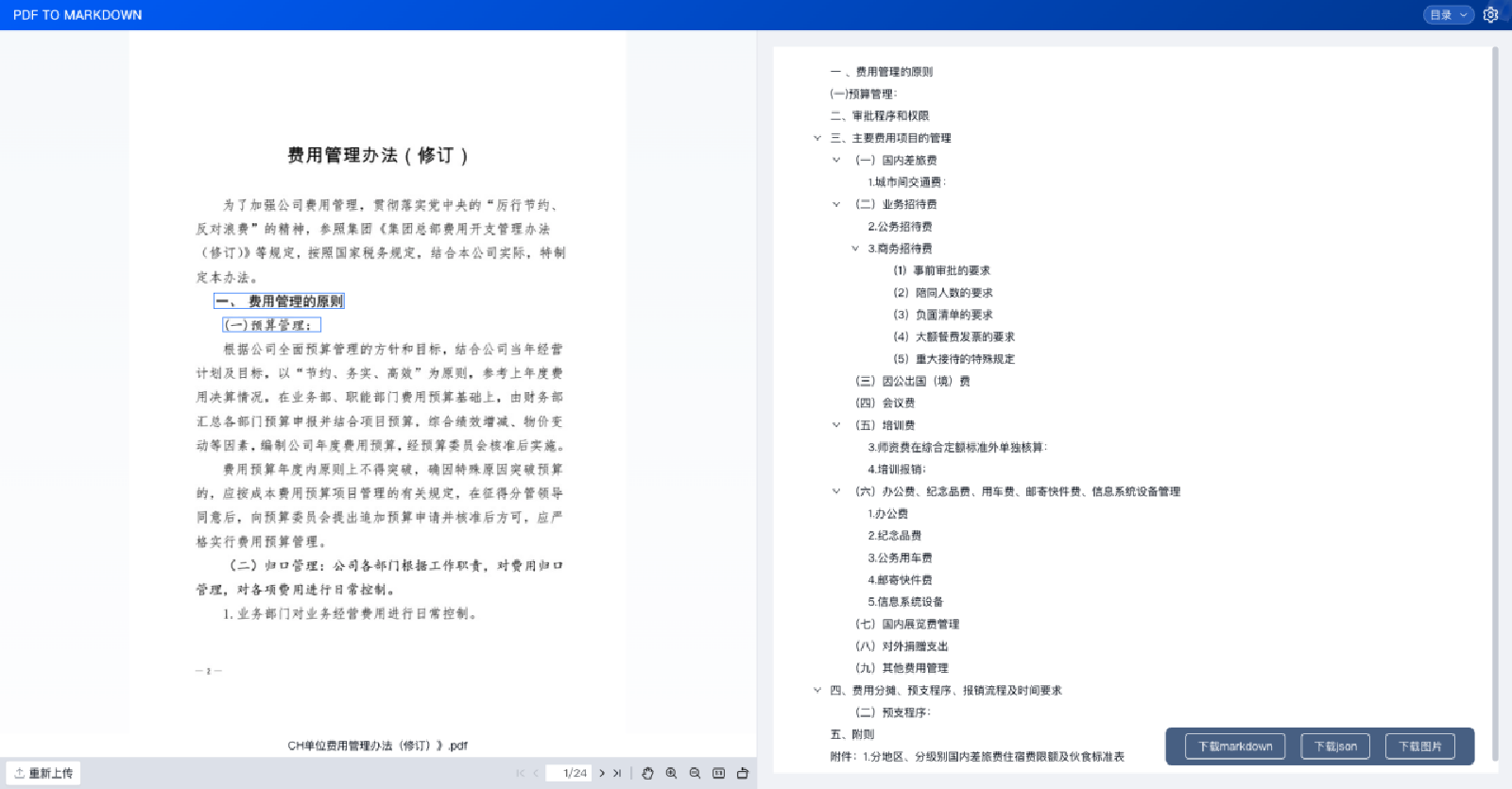
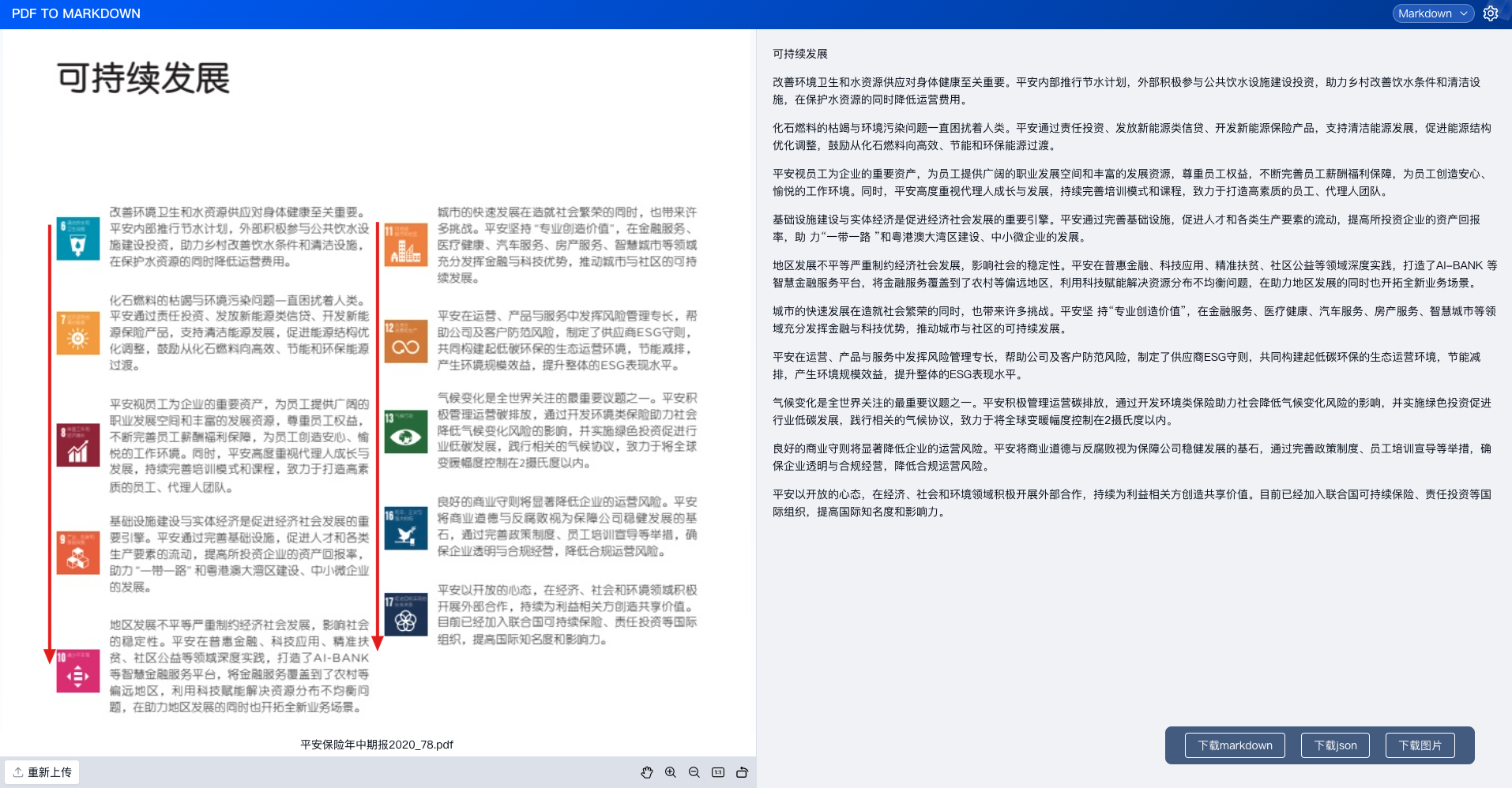
从这里我们可以看到(如上图),我在开头举的几个例子,ChatGPT-4在直接解析PDF回答的过程中是回答失败的。但我们将这个PDF转化成markdown的一个内容,并且以TextIn上传到这个ChatGPT-4后,它便回答的非常清楚,就31.9的这个溶解度。
那第二个问题也准确将整个致谢做了一个回答(如下图)。
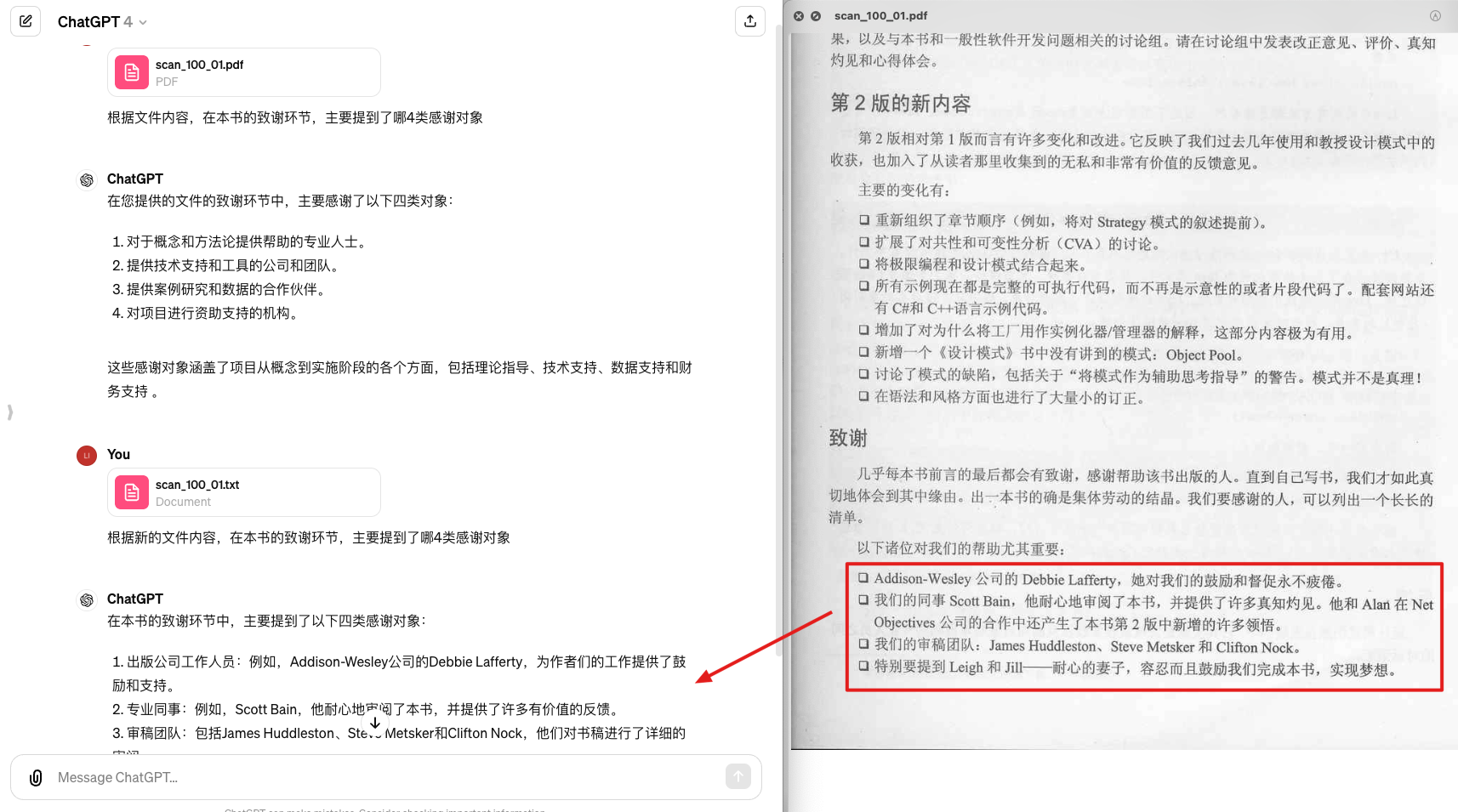
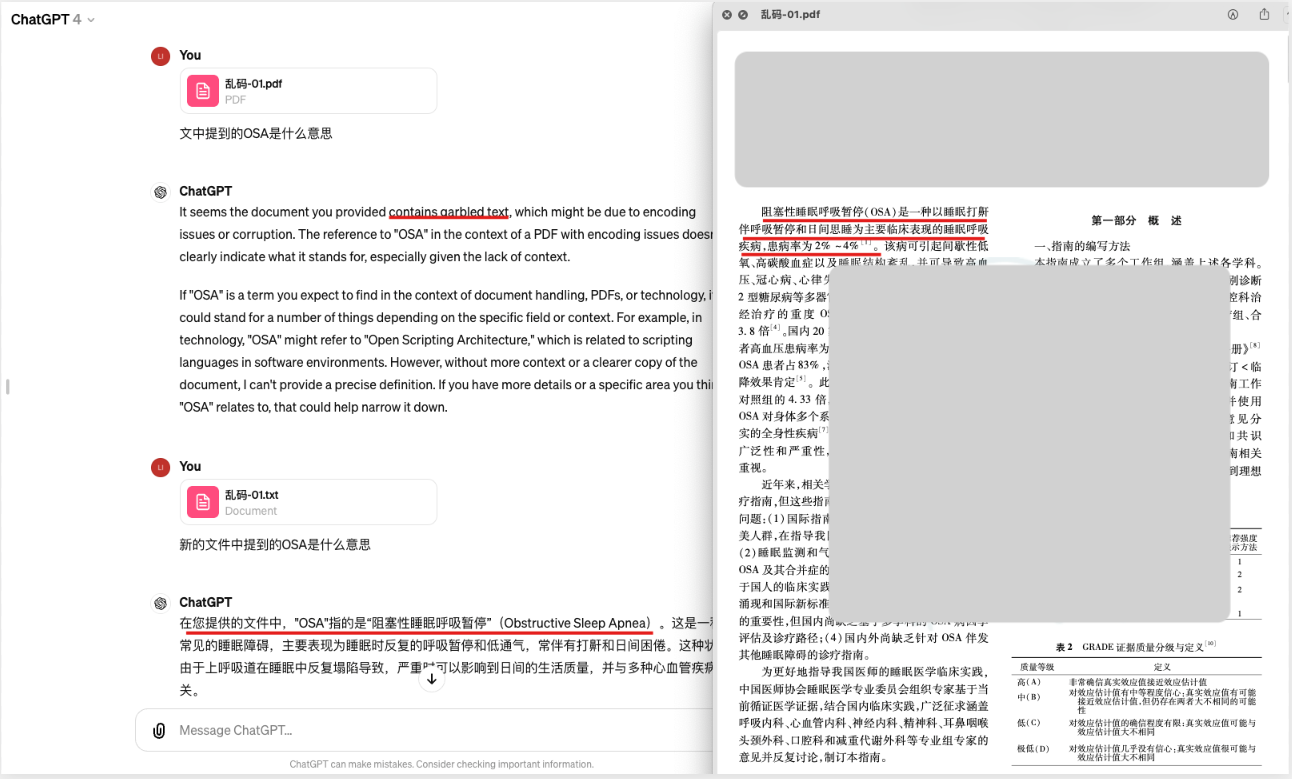
第三部分就是将整个编码错误的PDF也进行了准确的识别和输出。
二、TextIn 文本向量化技术
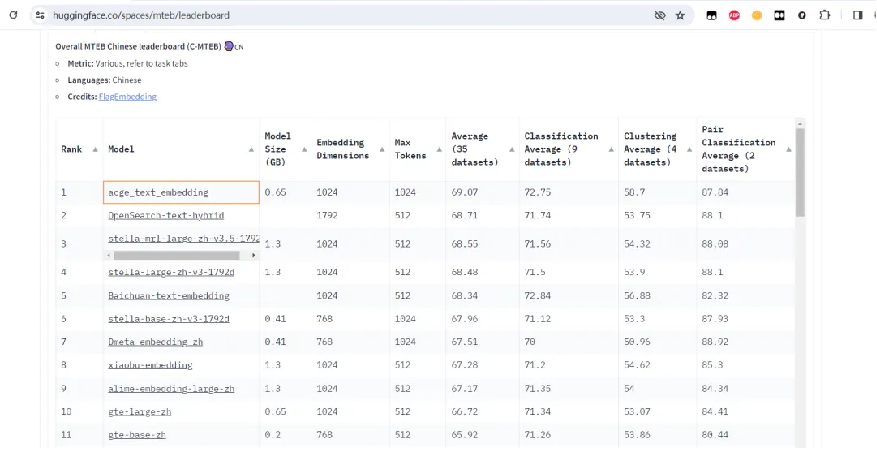
这是TextIn的第二个核心技术,它主要是文本向量化的工作,也是我们在文本应用的部分,这个地方他们做了一个TextIn acge_text_embedding的一个模型(如下图),这块就不详细讲了,如果大家感兴趣,可以在huggingface去看,里面有技术的介绍,以及如何直接引用这个库。
三、TextIn.com Text Intelligence
合合信息目前也做了一个站点,TextIn是一个缩写,就是这个部分,欢迎访问 TextIn.com,加速多模态大模型研究与应用。
大家也可以去免费的体验,如果大家有更多更高量的一个需求。我们可以扫下边的这个二维码,可以给到大家更多的这个版面分析相关的一个讨论,TextIn希望在大模型的训练应用的过程中,能够帮助到大家,将更高信息量、更高质量的一些文档相关信息可以用在我们的这个大模型的训练和应用之中。