随着机器学习理论和方法的发展, 出现了用于模仿特定说话人语音的深度伪造、针对语音识别和声纹识别的对抗样本, 它们都为破坏语音载体的可信性和安全性提供了具体手段, 进而对各自应用场景的信息安全构成了挑战。
深度伪造是利用生成式对抗网络等方法, 通过构建特定的模型, 产生听起来像目标说话人的语音样本。之所以称之为伪造, 是因为目标说话人根本没有说过这些话。深度伪造的欺骗对象主要是人耳听觉, 也可以用于导致声纹识别系统出错。与深度伪造不同, 语音对抗样本旨在通过对载体信号引入微小的扰动, 使语音识别或声纹识别系统出现。特定的差错, 但并不影响人耳对该语音样本的听觉感知。相对于深度伪造, 利用声纹识别系统自身的脆弱性,声纹系统对抗样本的攻击具有很强的隐蔽性。
1、声纹识别的对抗样本攻击
1.1 研究现状
白盒攻击中, 攻击者完全了解被攻击模型的结构、参数、损失函数和梯度等信息, 利用被攻击白盒模型的结构和参数信息构建对抗样本生成算法,从而有指导性地修改原始样本, 以生成对抗样本。在黑盒攻击中, 攻击者不掌握被攻击模型的结构、参数等内部信息, 只能通过利用白盒模型对抗样本的迁移性, 或利用黑盒模型的输出结果训练替代模型等方式来生成对抗样本。在现实场景中, 攻击者难以获取被攻击模型的内部信息, 因此黑盒攻击相对于白盒攻击难度更高, 但也更符合实际。
| 方法 | 对抗知识 | 优点 | 缺点 |
| 基于梯度/迭代优化 | 白盒 | 攻击成功率高、信噪比高 | 需要访问模型结构,迭代计算对抗扰动,生成 对抗样本的时间长,容易被检测 |
| 基于生成网络 | 白盒 | 生成对抗样本的时间短 | 攻击成功率和信噪比难以平衡 |
| 基于查询 | 黑盒 | 不需访问梯度,仅靠置信度或决策就可以实现攻击 | 攻击成功率较低;查询过多时容易被检测到 |
| 基于迁移性 | 黑盒 | 不需要访问目标模型结构 | 对抗样本迁移性弱,黑盒攻击成功率低 |
1.2 关键技术路线
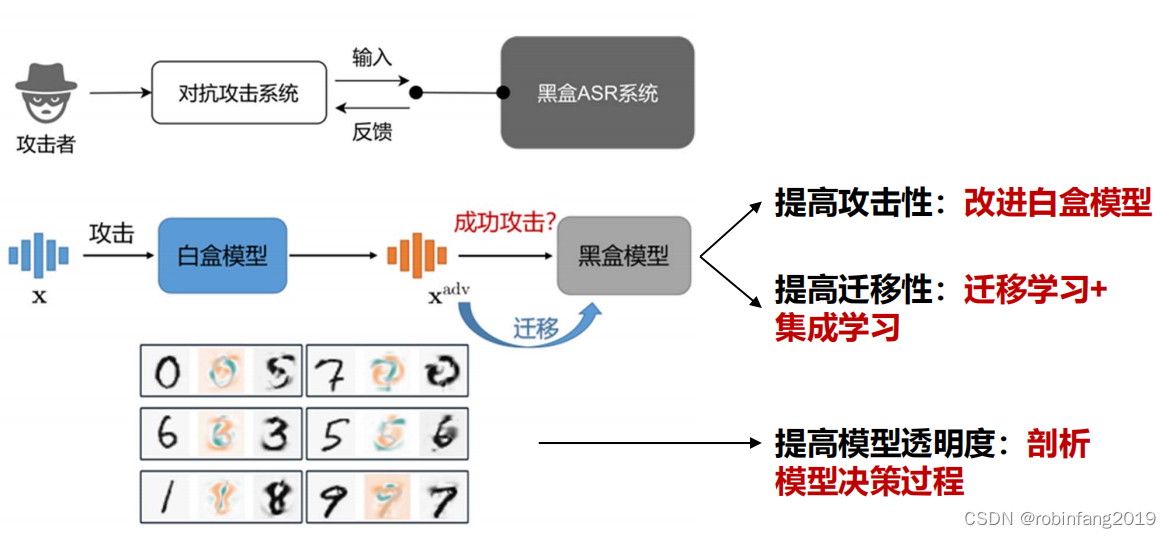
1.3 白盒攻击
下图展示Symmetric Saliency-based Adversarial Attack to Speaker Identification 是一种针对说话人识别系统的对抗性攻击方法:
- 模型逆向工程:攻击者首先需要了解目标说话人识别系统的内部结构和参数。由于是对抗性攻击,攻击者可能需要访问模型的权重和架构,以便更好地设计攻击。
- 确定攻击目标:攻击者确定他们想要系统误解的具体说话人,例如,他们可能希望系统将说话人A误认为说话人B。
- 构建对称显著性模块:在SSED中,显著性模块用于突出显示语音信号中对说话人识别最重要的部分。在对抗性攻击中,这个模块可以被用来识别那些对模型预测影响最大的特征,从而在这些特征上引入扰动。
- 优化过程:通过梯度下降或其他优化算法,攻击者在保持语音变化不可察觉的同时,寻找能够最小化损失函数的对抗性扰动。损失函数通常包括两部分:一部分是针对说话人识别任务的错误分类损失,另一部分是针对语音变化的感知损失,以确保扰动对人类听众来说是不可察觉的。
- 生成对抗性样本:一旦找到最佳扰动,攻击者将其添加到原始语音中,生成对抗性样本。
- 攻击评估:最后,攻击者评估生成的对抗性样本是否能够成功地欺骗说话人识别系统,使其做出错误的预测。
-
1.4 黑盒攻击
下图展示Interpretable Spectrum Transformation Attacks to Speaker Recognition 是一种针对说话人识别系统的对抗性攻击方法。说话人识别系统通常基于语音信号中的频谱特征来识别不同的说话人。
- 选择目标说话人:攻击者首先确定他们想要系统误解的具体说话人,例如,他们可能希望系统将说话人A误认为说话人B。
- 构建频谱转换模型:攻击者构建一个频谱转换模型,该模型能够将目标说话人的语音频谱转换为攻击目标说话人的频谱。这个模型可以是基于深度学习的,如神经网络或卷积神经网络。
- 优化过程:通过梯度下降或其他优化算法,攻击者在保持语音内容不变的同时,寻找能够最小化损失函数的频谱转换。损失函数通常包括两部分:一部分是针对说话人识别任务的错误分类损失,另一部分是针对语音内容的损失,以确保语音内容的不变性。
- 生成对抗性样本:一旦找到最佳频谱转换,攻击者将其应用于原始语音,生成对抗性样本。
- 攻击评估:攻击者评估生成的对抗性样本是否能够成功地欺骗说话人识别系统,使其做出错误的预测。
2、声纹识别的对抗样本防御
2.1 研究现状
声纹识别的对抗样本防御是指采取一系列措施来增强声纹识别系统对对抗性攻击的鲁棒性。防御策略可以单独使用,也可以组合使用,以提高声纹识别系统对对抗性攻击的鲁棒性。
| 方法 | 研究方向 | 优点 | 缺点 |
| 纯化 | 提高语音纯化质量 | 对任何样本都 可以进行有效声纹判定 | 对任意样本都进行语音纯化,可能造成声纹识别系统性能下降, |
| 检测 | 改进检测模型 | 不改变样本 | 被误判的纯净样本会被丢弃 |
| 混合训练 | 改进训练数据的合成方法 | 声纹识别模型,自带防御功能 | 模型训练规模大,对抗样本造成声纹识别模型精度下降 |
2.2 纯化防御
声纹识别的对抗样本防御中,扩散(Diffusion)模型纯化利用了扩散模型在生成高质量语音方面的能力,以净化对抗性扰动,从而提高声纹识别系统的鲁棒性。
扩散模型是一种深度学习模型,它通过迭代去噪的过程来生成数据。在声纹识别的背景下,扩散模型首先将干净的声纹信号逐渐添加噪声,直到信号变成随机噪声,然后将这些噪声逐渐去噪,恢复出原始的声纹信号。这个过程可以看作是对声纹信号的纯化,因为它可以去除声纹信号中的噪声和扰动。
Diffusion模型纯化
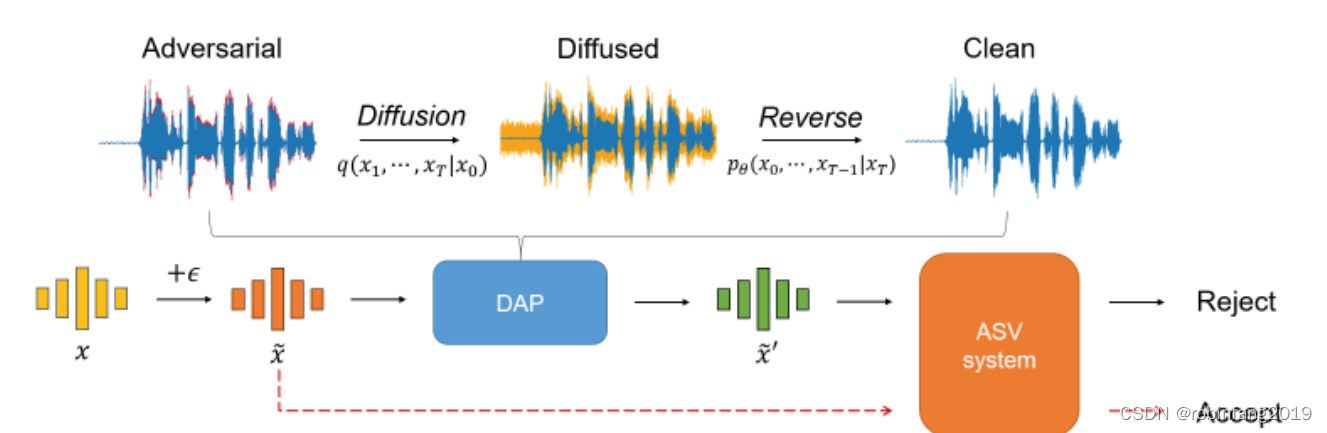
两阶段 diffusion模型纯化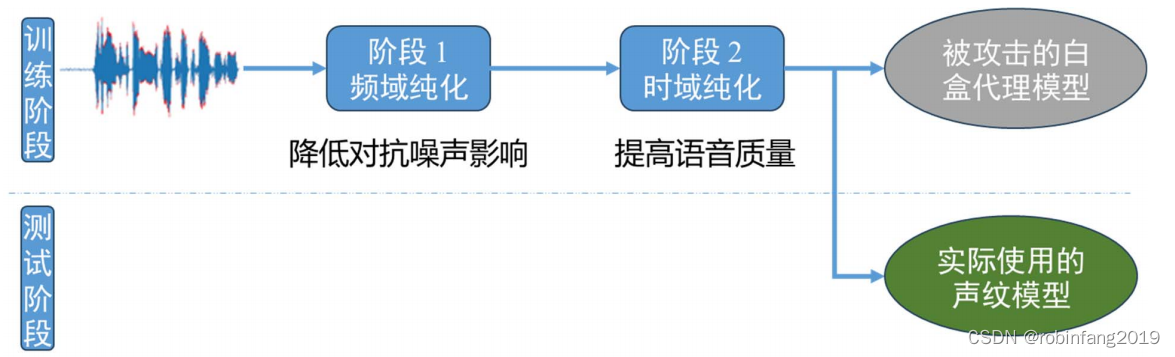
大语言模型驱动的diffusion模型纯化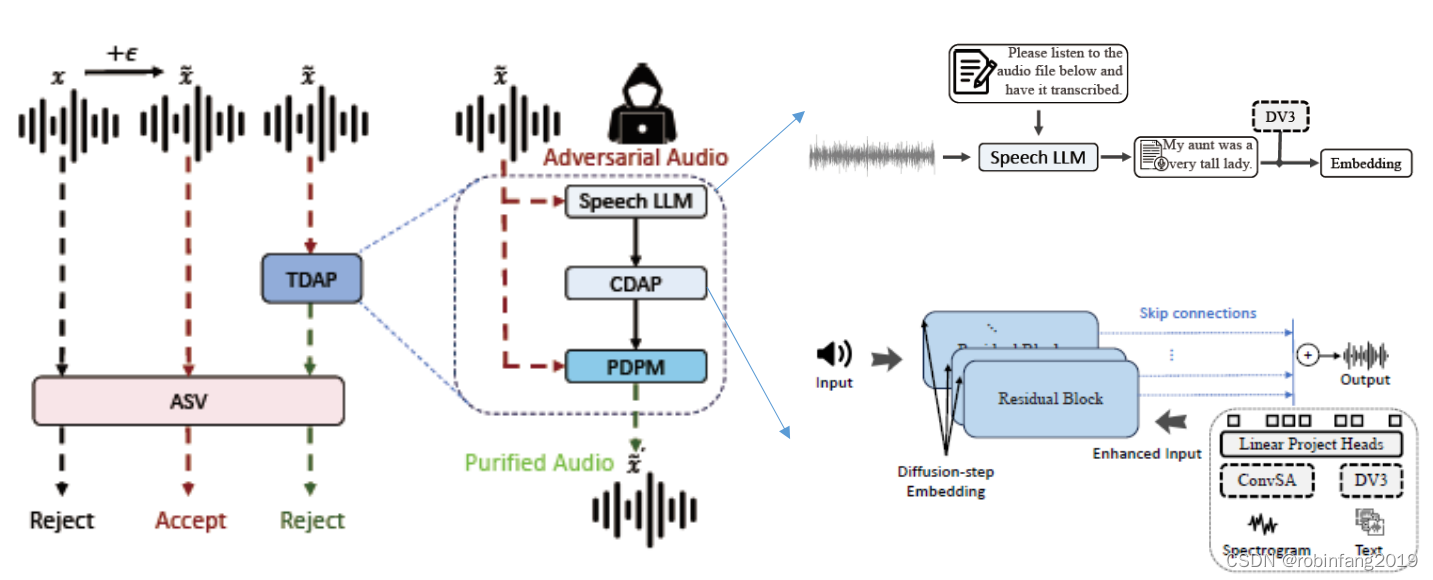
- 对抗样本生成:首先,使用特定的对抗攻击方法生成对抗性声纹样本。这些样本在人类听起来与原始语音几乎相同,但能够导致声纹识别模型错误地识别说话人。
- 扩散过程:将生成的对抗性声纹样本输入到扩散模型中,通过迭代添加噪声,将样本逐渐转换为随机噪声。
- 去噪过程:在去噪过程中,扩散模型将噪声逐渐去除,尝试恢复出原始的声纹信号。由于扩散模型在生成声纹信号时已经学习了声纹信号的本质特征,因此它可以在去噪过程中识别并去除对抗性扰动。
- 声纹识别:将去噪后的声纹样本输入到声纹识别模型中,进行说话人识别。
2.3 检测防御
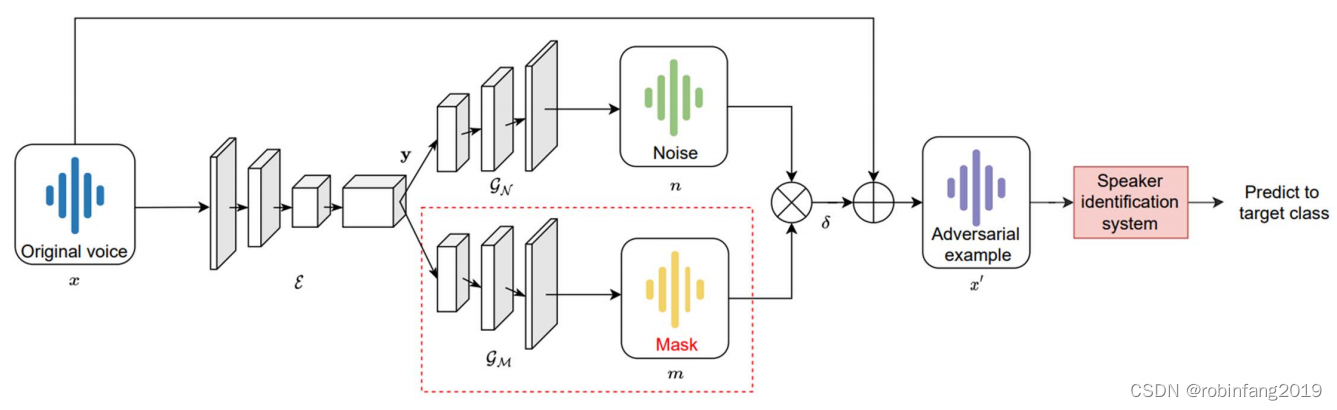
基于可学习Mask的对抗样本检测方法的核心思想是利用可学习的Mask来识别和去除声纹信号中的对抗性扰动,从而保护声纹识别系统不受攻击。
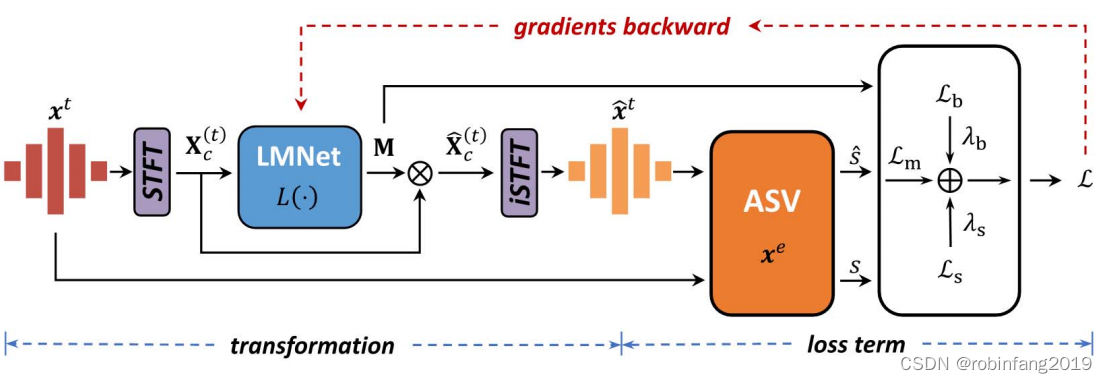
- 训练可学习Mask:首先,需要训练一个可学习的Mask。这个Mask是一个神经网络,它能够学习如何识别声纹信号中的对抗性扰动。训练数据包括正常的声纹信号和被对抗性攻击污染的声纹信号。通过训练,Mask学会了识别和去除对抗性扰动。
- 声纹信号输入:当一个新的声纹信号输入到系统时,首先通过可学习Mask进行处理。Mask会识别并去除信号中的对抗性扰动,从而净化声纹信号。
- 声纹识别:将净化后的声纹信号输入到声纹识别模型中,进行说话人识别。
基于规则Mask的对抗样本检测方法的核心思想是利用预先定义的规则来生成Mask,这个Mask用于识别和去除声纹信号中的对抗性扰动,从而保护声纹识别系统不受攻击。
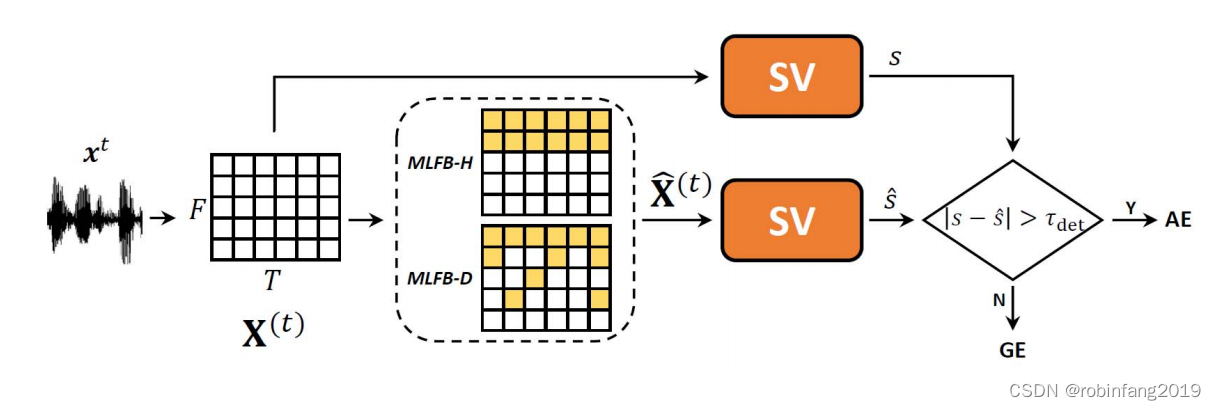
- 定义规则:首先,需要定义一组规则,这些规则用于确定哪些部分的声纹信号可能是对抗性扰动。这些规则可以是基于声学特征的,例如音高、能量、频谱特性等,或者是基于信号处理的技术,例如滤波、傅里叶变换等。
- 生成规则Mask:根据定义的规则,生成一个规则Mask。这个Mask是一个矩阵,它将声纹信号中的每个部分标记为正常或异常。规则Mask可以通过编程实现,也可以通过机器学习算法学习得到。
- 声纹信号输入:当一个新的声纹信号输入到系统时,首先通过规则Mask进行处理。规则Mask会识别并去除信号中可能是对抗性扰动的部分,从而净化声纹信号。
- 声纹识别:将净化后的声纹信号输入到声纹识别模型中,进行说话人识别。