5 特征筛选
学习目标
- 掌握单特征分析的衡量指标
- 知道 IV,PSI等指标含义
- 知道多特征筛选的常用方法
- 掌握Boruta,VIF,RFE,L1等特征筛选的使用方法
1 单特征分析
什么是好特征?从几个角度衡量:覆盖度,区分度,相关性,稳定性
覆盖度
- 采集类,授权类,第三方数据在使用前都会分析覆盖度
- 采集类 :如APP list (Android 手机 90%)
- 授权类:如爬虫数据(20% 30%覆盖度)GPS (有些产品要求必须授权)
- 一般会在两个层面上计算覆盖度(覆盖度 = 有数据的用户数/全体用户数)
- 全体存量客户
- 全体有信贷标签客户
- 覆盖度可以衍生两个指标:缺失率,零值率
- 缺失率:一般就是指在全体有标签用户上的覆盖度
- 零值率:很多信贷类数据在数据缺失时会补零,所以需要统计零值率
- 业务越来越成熟,覆盖度可能会越来愈好,可以通过运营策略提升覆盖度
区分度:是评估一个特征对好坏用户的区分性能的指标
- 可以把单特征当做模型,使用AUC, KS来评估特征区分度
- 在信贷领域,常用Information Value (IV)来评估单特征的区分度
- Information Value刻画了一个特征对好坏用户分布的区分程度
- IV值越大
- IV值越小
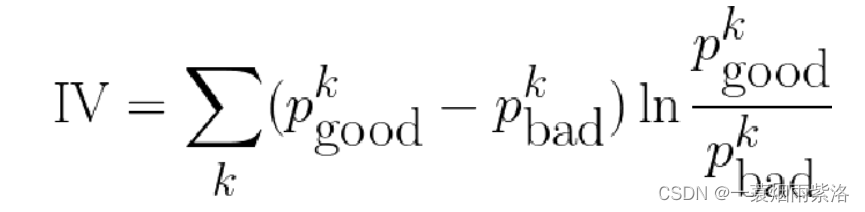
- IV值最后ln的部分跟WOE是一样的
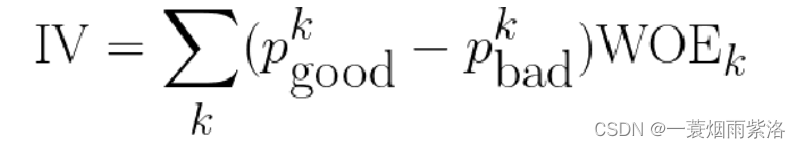
- IV计算举例(数据为了方便计算填充,不代表实际业务)
| 婚配 | good | bad | p_good | p_bad | p_good-p_bad | ln(p_g/p_bad) | IV |
|---|---|---|---|---|---|---|---|
| 未婚 | 40 | 30 | 50% | 37.5% | 0.125 | 0.287 | 0.0358 |
| 已婚 | 30 | 40 | 37.5% | 50% | -0.125 | -0.287 | 0.0358 |
| 其他 | 10 | 10 | 12.5% | 12.5% | 0 | 0 | 0 |
| 总计 | 80 | 80 | 100% | 100% | - | - | 0.0716 |
- IV<0.02 区分度小 建模时不用 (xgboost,lightGMB 对IV值要求不高) IV [0.02,0.5] 区分度大 可以放到模型里 (IV > 0.1 考虑是否有未来信息) IV > 0.5 单独取出作为一条规则使用,不参与模型训练
模型中尽可能使用区分度相对较弱的特征,将多个弱特征组合,得到评分卡模型
- 连续变量的IV值计算,先离散化再求IV,跟分箱结果关联很大(一般分3-5箱)
- 相关性:对线性回归模型,有一条基本假设是自变量x1,x2,…,xp之间不存在严格的线性关系
- 需要对相关系数较大的特征进行筛选,只保留其中对标签区分贡献度最大的特征,即保留IV较大的
- 皮尔逊相关系数,斯皮尔曼相关系数,肯德尔相关系数
- 如何选择:
- 考察两个变量的相关关系,首先得清楚两个变量都是什么类型的
- 连续型数值变量,无序分类变量、有序分类变量
- 连续型数值变量,如果数据具有正态性,此时首选Pearson相关系数,如果数据不服从正态分布,此时可选择Spearman和Kendall系数
- 两个有序分类变量相关关系,可以使用Spearman相关系数
- 一个分类变量和一个连续数值变量,可以使用kendall相关系数
- 总结:就适用性来说,kendall > spearman > pearson
- 如何计算
import pandas as pd
df = pd.DataFrame({'A':[5,91,3],'B':[90,15,66],'C':[93,27,3]})
df.corr() # 皮尔逊
df.corr('spearman')#斯皮尔曼
df.corr('kendall')#肯德尔
- 可以使用toad库来过滤大量的特征,高缺失率、低iv和高度相关的特征一次性过滤掉
import pandas as pd
import toad
data = pd.read_csv('data/germancredit.csv')
data.replace({'good':0,'bad':1},inplace=True)
data.shape
显示结果:
(1000, 21)
#缺失率大于0.5,IV值小于0.05,相关性大于0.7来进行特征筛选
selected_data, drop_list= toad.selection.select(data,target = 'creditability', empty = 0.5, iv = 0.05, corr = 0.7, return_drop=True)
print('保留特征:',selected_data.shape[1],'缺失删除:',len(drop_list['empty']),'低iv删除:',len(drop_list['iv']),'高相关删除:',len(drop_list['corr']))
显示结果:
保留特征: 12 缺失删除: 0 低iv删除: 9 高相关删除: 0
- 稳定性:特征稳定性主要通过计算不同时间段内同一类用户特征的分布的差异来评估
- 常用的特征稳定性的度量有Population Stability Index (PSI)
- 当两个时间段的特征分布差异大,则PSI大
- 当两个时间段的特征分布差异小,则PSI小
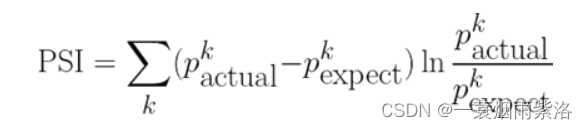
- IV是评估好坏用户分布差异的度量
- PSI是评估两个时间段特征分布差异的度量
- 都是评估分布差异的度量,并且公式其实一模一样,只是符号换了而已
2 多特征筛选
- 当我们构建了大量特征时,接下来的调整就是筛选出合适的特征进行模型训练
- 过多的特征会导致模型训练变慢,学习所需样本增多,计算特征和存储特征成本变高
- 常用的特征筛选方法:
- 星座特征
- Boruta
- 方差膨胀系数
- 后向筛选
- L1惩罚项
- 业务逻辑
星座特征
- 星座是大家公认没用的特征&#x