Webhooks 是许多 API 的补充。通过设置 webhook 系统,系统 B 可以注册接收有关系统 A 某些更改的通知。当更改发生时,系统 A 推送 更改到系统 B,通常是以发出 HTTP POST 请求的形式。
Webhooks 旨在消除或减少不断轮询数据的需要。但根据我的经验,webhooks 带来了一些挑战。
通常,您不能单靠 webhooks 来保持两个系统的一致性。我参与过的每一个集成项目最终都意识到这一点,并通过轮询增强了 webhooks。这是由于几个问题领域。
首先,当您的系统宕机时存在风险。是的,发送者通常会用某种指数退避重试未送达的 webhooks。但保证往往是宽松或不明确的。而且系统从灾难中恢复后,最不需要的可能就是处理积压的 webhooks 大量任务。
其次,webhooks 是短暂的。它们太容易处理不当或丢失。如果您在部署代码更改后意识到您输入了一个错误的 JSON 字段,并且正在将 null 插入到您的数据库中,那么您无法回放 webhooks。或者,您可能会在 webhook 请求之外处理部分 webhook 处理流程——比如数据库插入。但那样您就冒着失败并丢失 webhook 的风险。
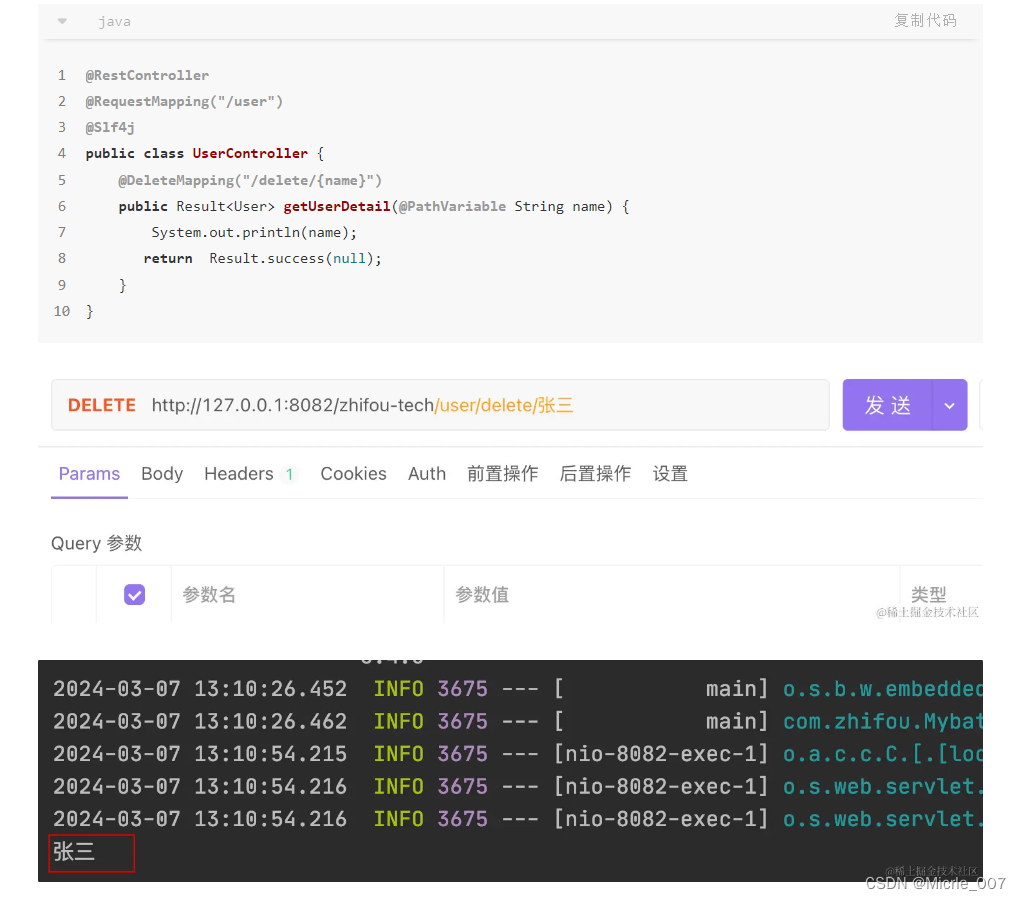
为了缓解这两个问题,许多开发人员最终将 webhooks 缓存在像 Kafka 这样的消息总线系统上,这感觉像是一个笨重的妥协。
考虑两方之间复杂的 webhook 管道结构:
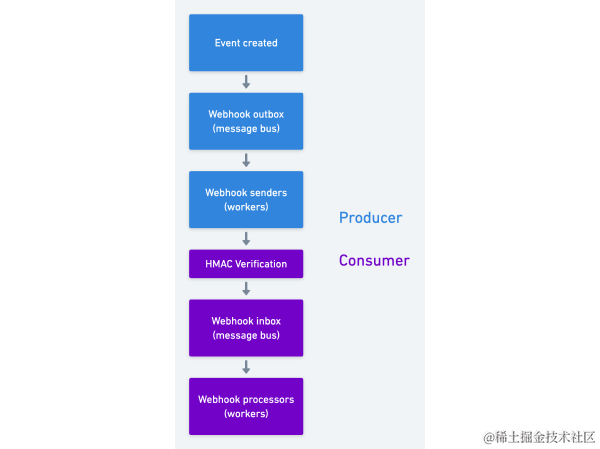
我们在发送端和接收端各有一个消息总线。复杂性显而易见,而且可能出问题的阶段很多。例如:在接收端,即使您的系统运行良好,您仍然可能受到发送者可交付性失败的影响。如果发送者的队列开始经历背压,webhook 事件将被推迟,而您可能很难知道这种滑移正在发生。
增加复杂性的是,两者之间的安全层通常是某种 HTTP 请求签名协议,如 HMAC。这很稳固且减轻了管理秘密的负担。但对于您的普通开发人员来说,这也不太熟悉,因此更容易头疼和出错。(HTTP 请求 签名和验证是那些任务之一,我觉得一个人做得不够频繁,以至于永远不会完全记住。)
因此,不仅仅是 webhooks 使您最终面临不一致,它们对每个人来说也是更多的工作。
那么我们还能用什么来保持两个系统的同步呢?
/events 接口
要寻找保持两个数据集和谐的灵感,我们不妨看看数据库。考虑 Postgres 的复制插槽:您为每个从数据库创建一个复制插槽,从数据库订阅该复制插槽以获取更新。
两个关键组成部分是:
- 主数据库保持最近变更的日志
- 主数据库保持一个游标,跟踪每个从数据库在更改日志中的位置
如果从数据库宕机,当它恢复时,可以自由地翻阅历史记录。没有队列,也没有在每端尝试像接力棒一样传递事件的工人。
API 也可以遵循这种模型。以 Stripe 为例。他们有一个 /events 接口,包含过去 30 天内对 Stripe 帐户进行的所有创建、更新和删除操作。每个事件对象都包含所操作实体的完整有效载荷。这里有一个事件的示例,针对一个 subscription 对象:
{ "id": "evt_1J7rE6DXGuvRIWUJM7m6q5ds", "object": "event", "created": 1625012666, "data": { "object": { "id": "sub_JgFEscIjO0YEHN", "object": "subscription", "canceled_at": 1625012666, "customer": "cus_Jff7uEN4dVIeMQ", "items": { "object": "list", "data": [ // ... ], "url":"/v1/subscription_items?subscription=sub_JgFEscIjO0YEHN" }, "start_date": 1623826800, "status": "canceled", } }, "type": "customer.subscription.deleted" }
一些重要的特质:
- 每个事件有一个
type,告诉我们这个事件是什么。在这个案例中,我们看到一个客户的订阅已被删除。因为包含了完整的订阅有效载荷,我们可以更新我们的数据库以反映字段如canceled_at和它的新status为canceled。 - 每个嵌入对象包含一个
object字段,所以我们可以轻松地提取和解析它们。 - 事件对象大量嵌入子对象,让我们全面了解所有变化,无需轮询 API。
因此,我们可以轮询 /events 来保持事物的最新状态,而不是监听 webhooks。我们只需在本地保持一个游标,我们在请求中使用它来指示给 Stripe 我们已经看到了哪些事件。
优势:
- 如果我们宕机,我们不用担心错过 webhooks。当我们恢复时,我们可以自己的步调赶上。
- 如果我们部署了一个错误地处理事件的错误,不用担心。我们可以部署修复,并为
/events倒带游标,它将回放它们。 - 我们端不需要消息总线。
- 我们不必担心 Stripe 的 webhook 发送者延迟交付。速度掌握在我们手中。我们与最新数据之间的唯一障碍是 Stripe 在 API 层面所做的任何缓存(看起来是没有的)。
- 我们使用简单的基于令牌的身份验证方案。
- 我们拉取和处理事件的方式与我们处理任何其他端点的方式相同。我们可以重用许多相同的 API 请求/处理代码。
在生产者端,为了支持 /events,您需要添加监控创建/更新/删除的同样仪式,就像您会为 webhooks 使用的那样。除了,您不需要构建交付管道,您只需要将记录插入到一个仅追加的数据库表中。
在消费者端,您将需要设置一些轮询基础设施。这比如说,一个处理一切的基本 webhook 处理端点需要更多的基础工作。但是,我敢打赌一个像样的轮询系统构建起来并不比一个健壮的 webhook 处理系统难,例如,一个带有消息总线的系统。而且您得到了更好的一致性保证。
使 /events 更好
在 /events 接口中有一个明显的低效之处:为了尽可能保持实时性,您必须非常频繁地轮询。我们每个帐户每 500 毫秒轮询一次 Stripe /events 端点,并考虑将其减半。
这些请求很轻,因为对于大多数活跃的 Stripe 帐户来说,响应往往是空的。但作为程序员,我们不禁想寻找一种更有效的方式。
对于 Stripe 和其他 API 平台来说,一个创意:支持长轮询!
在长期被遗忘的长轮询艺术中,客户端发出标准的 HTTP 请求。如果服务器没有新的信息需要传递给客户端,服务器将请求保持开放,直到有新的信息要传递。
在我们与 Stripe 的集成中,如果我们可以请求 /events 并指出我们希望进行长轮询,那会很好。根据我们发送的游标,如果有新事件 Stripe 将立即返回这些事件。但如果没有,Stripe 可以保持请求开放,直到创建了新事件。当请求完成时,我们只需重新打开它并重复循环。这不仅意味着我们可以尽快获得事件,还可以减少总体网络流量。
长轮询相对于 websockets 的优势在于代码重用和简单性。大多数集成本来就涉及某种形式的轮询,无论您是在回填数据还是重播错误处理的事件。能够通过单一参数调整从例如回填切换到实时监听新事件的能力是一个巨大的胜利。
我应该使用哪个?
对于 API 消费者来说,如果您幸运地有选择使用轮询 /events 或使用 webhooks 的选择,那么该选择使用哪个主要取决于您的一致性需求。Webhooks 可以更快地开始使用,特别是如果您只关心几个 API 对象。对于某些工作流程,如果 webhooks 被丢弃也没关系,比如您正在向 Slack 频道发布“新订阅者”公告。
但随着集成的重要性增长以及确保不丢失任何东西的需求出现,我们认为轮询 /events 很难被超越。
对于 API 生产者来说,支持 /events 不仅是给您的 API 消费者的一份大礼。/events 可以轻松成为提供 webhooks 的跳板。您的 events 表可以作为您的 webhook 发送者的出站工作的“队列”。事实上,/events 可以解锁急需的 webhook 功能,比如允许您的 webhook 消费者重放或重置其 webhook 订阅的位置。
- 源于:Give me /events, not webhooks