一、前期准备
1、代码
参考的博主使用的是2.6版本的
博主的paddleocr代码
下面这个是官方的,可能已经更新了(我用的是官网当前最新版)
paddleocr的源代码
注意:最好把上面两个代码都下载下来,后面都会用到
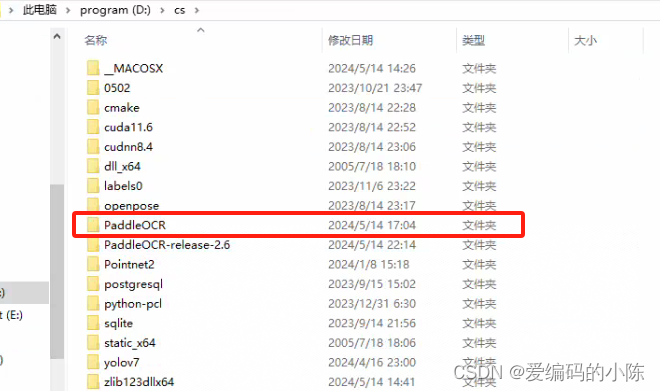
参考博主的:
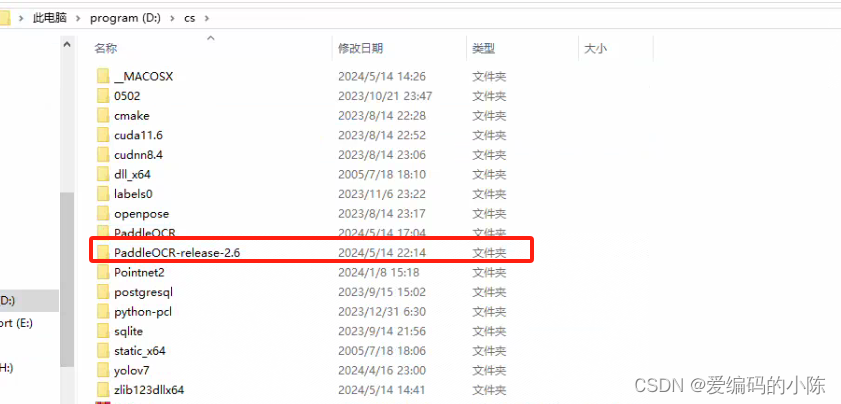
官网源码的:
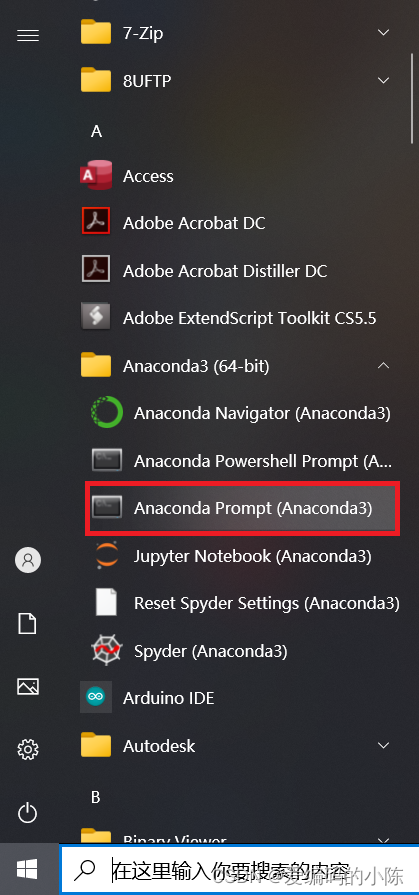
2、创建一个conda虚拟环境
- 打开Anaconda Prompt终端:左下角Windows Start Menu -> Anaconda3 -> Anaconda Prompt启动控制台
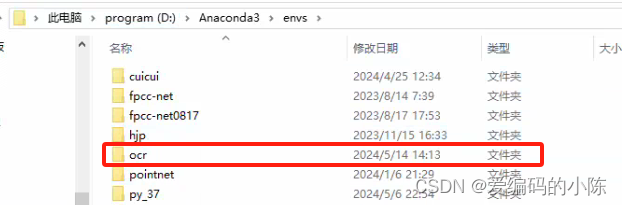
- 创建新的conda环境
# 在命令行输入以下命令,创建名为ocr的环境
# 此处为加速下载,使用清华源
conda create --name ocr python=3.8 --channel https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/ # 这是一行命令该命令会创建1个名为ocr、python版本为3.8的可执行环境,根据网络状态,需要花费一段时间
- 激活虚拟环境测试:
conda activate ocr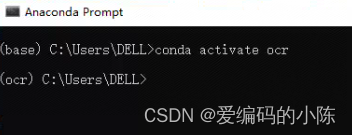
运行环境配置完成
3、安装包
(1)安装PaddlePaddle
# 先激活ocr虚拟环境
activate ocr飞浆官网安装文档链接
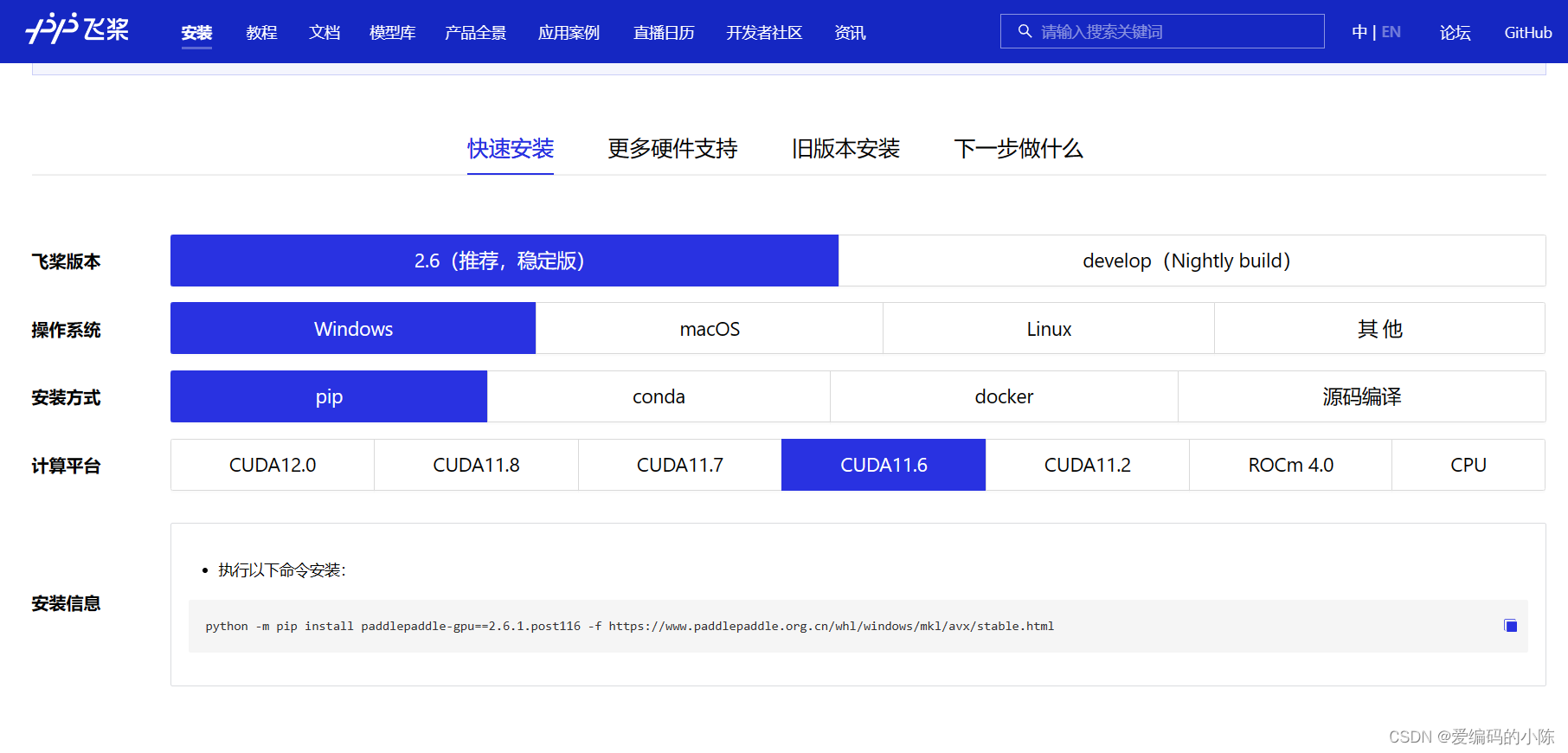
根据自己的CUDA版本来安装,这里我的CUDA版本是11.6的,因此命令为
python -m pip install paddlepaddle-gpu==2.6.1.post116 -f https://www.paddlepaddle.org.cn/whl/windows/mkl/avx/stable.html如果你没有CUDA打算用CPU版本的,命令为
python -m pip install paddlepaddle==2.6.1 -i https://pypi.tuna.tsinghua.edu.cn/simple(2)安装PaddleOCR whl包
pip install "paddleocr>=2.0.1" # 推荐使用2.0.1+版本
- 对于Windows环境用户:直接通过pip安装的shapely库可能出现
[winRrror 126] 找不到指定模块的问题。建议从这里下载shapely安装包完成安装。(我这里直接pip是没问题的,视自己情况)
(3)便捷使用
PaddleOCR提供了一系列测试图片,点击这里下载并解压,放到我们的PaddleOCR根目录文件夹下,然后在终端中切换到相应目录
cd D:/cs/PaddleOCR/ppocr_img
如果不使用提供的测试图片,可以将下方--image_dir参数替换为相应的测试图片路径。
3.1 中英文模型
- 检测+方向分类器+识别全流程:
--use_angle_cls true设置使用方向分类器识别180度旋转文字,--use_gpu false设置不使用GPU
activate ocr
cd D:\cs\PaddleOCR\ppocr_img
paddleocr --image_dir ./imgs/11.jpg --use_angle_cls true --use_gpu false结果是一个list,每个item包含了文本框,文字和识别置信度
[[[28.0, 37.0], [302.0, 39.0], [302.0, 72.0], [27.0, 70.0]], ('纯臻营养护发素', 0.9658738374710083)]
......此外,paddleocr也支持输入pdf文件,并且可以通过指定参数page_num来控制推理前面几页,默认为0,表示推理所有页。
# 这里yolov7.pdf是我自己随便找的一个文件放到该目录下面的
paddleocr --image_dir ./imgs/yolov7.pdf --use_angle_cls true --use_gpu false --page_num 2- 单独使用检测:设置
--rec为false
paddleocr --image_dir ./imgs/11.jpg --rec false结果是一个list,每个item只包含文本框
[[27.0, 459.0], [136.0, 459.0], [136.0, 479.0], [27.0, 479.0]]
[[28.0, 429.0], [372.0, 429.0], [372.0, 445.0], [28.0, 445.0]]
......- 单独使用识别:设置
--det为false
paddleocr --image_dir ./imgs_words/ch/word_1.jpg --det false结果是一个list,每个item只包含识别结果和识别置信度
['韩国小馆', 0.994467]版本说明 paddleocr默认使用PP-OCRv4模型(--ocr_version PP-OCRv4),如需使用其他版本可通过设置参数--ocr_version,具体版本说明如下:
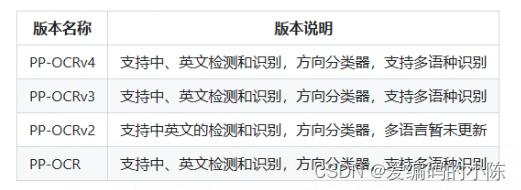
如需新增自己训练的模型,可以在paddleocr中增加模型链接和字段,重新编译即可。
更多whl包使用可参考whl包文档
3.2 多语言模型
PaddleOCR目前支持80个语种,可以通过修改--lang参数进行切换,对于英文模型,指定--lang=en。
paddleocr --image_dir ./imgs_en/254.jpg --lang=en

结果是一个list,每个item包含了文本框,文字和识别置信度
[[[67.0, 51.0], [327.0, 46.0], [327.0, 74.0], [68.0, 80.0]], ('PHOCAPITAL', 0.9944712519645691)]
[[[72.0, 92.0], [453.0, 84.0], [454.0, 114.0], [73.0, 122.0]], ('107 State Street', 0.9744491577148438)]
[[[69.0, 135.0], [501.0, 125.0], [501.0, 156.0], [70.0, 165.0]], ('Montpelier Vermont', 0.9357033967971802)]
......常用的多语言简写包括
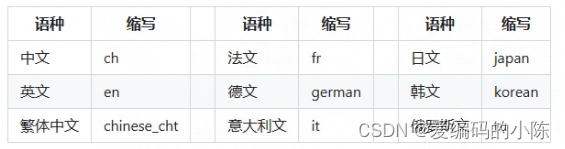
全部语种及其对应的缩写列表可查看多语言模型教程
(4) Python脚本使用
4.1 中英文与多语言使用
通过Python脚本使用PaddleOCR whl包,whl包会自动下载ppocr轻量级模型作为默认模型。
- 检测+方向分类器+识别全流程
from paddleocr import PaddleOCR, draw_ocr
# Paddleocr目前支持的多语言语种可以通过修改lang参数进行切换
# 例如`ch`, `en`, `fr`, `german`, `korean`, `japan`
ocr = PaddleOCR(use_angle_cls=True, lang="ch") # need to run only once to download and load model into memory
img_path = 'ppocr_img/imgs/11.jpg'
result = ocr.ocr(img_path, cls=True)
for idx in range(len(result)):
res = result[idx]
for line in res:
print(line)
# 显示结果
from PIL import Image
result = result[0]
image = Image.open(img_path).convert('RGB')
boxes = [line[0] for line in result]
txts = [line[1][0] for line in result]
scores = [line[1][1] for line in result]
im_show = draw_ocr(image, boxes, txts, scores, font_path='./fonts/simfang.ttf')
im_show = Image.fromarray(im_show)
im_show.save('result.jpg')结果是一个list,每个item包含了文本框,文字和识别置信度
[[[28.0, 37.0], [302.0, 39.0], [302.0, 72.0], [27.0, 70.0]], ('纯臻营养护发素', 0.9658738374710083)]
......结果可视化

如果输入是PDF文件,那么可以参考下面代码进行可视化
from paddleocr import PaddleOCR, draw_ocr
# Paddleocr目前支持的多语言语种可以通过修改lang参数进行切换
# 例如`ch`, `en`, `fr`, `german`, `korean`, `japan`
PAGE_NUM = 10 # 将识别页码前置作为全局,防止后续打开pdf的参数和前文识别参数不一致 / Set the recognition page number
pdf_path = 'ppocr_img/yolov7.pdf'
ocr = PaddleOCR(use_angle_cls=True, lang="ch", page_num=PAGE_NUM) # need to run only once to download and load model into memory
# ocr = PaddleOCR(use_angle_cls=True, lang="ch", page_num=PAGE_NUM,use_gpu=0) # 如果需要使用GPU,请取消此行的注释 并注释上一行 / To Use GPU,uncomment this line and comment the above one.
result = ocr.ocr(pdf_path, cls=True)
for idx in range(len(result)):
res = result[idx]
if res == None: # 识别到空页就跳过,防止程序报错 / Skip when empty result detected to avoid TypeError:NoneType
print(f"[DEBUG] Empty page {idx+1} detected, skip it.")
continue
for line in res:
print(line)
# 显示结果
import fitz
from PIL import Image
import cv2
import numpy as np
imgs = []
with fitz.open(pdf_path) as pdf:
for pg in range(0, PAGE_NUM):
page = pdf[pg]
mat = fitz.Matrix(2, 2)
pm = page.get_pixmap(matrix=mat, alpha=False)
# if width or height > 2000 pixels, don't enlarge the image
if pm.width > 2000 or pm.height > 2000:
pm = page.get_pixmap(matrix=fitz.Matrix(1, 1), alpha=False)
img = Image.frombytes("RGB", [pm.width, pm.height], pm.samples)
img = cv2.cvtColor(np.array(img), cv2.COLOR_RGB2BGR)
imgs.append(img)
for idx in range(len(result)):
res = result[idx]
if res == None:
continue
image = imgs[idx]
boxes = [line[0] for line in res]
txts = [line[1][0] for line in res]
scores = [line[1][1] for line in res]
im_show = draw_ocr(image, boxes, txts, scores, font_path='doc/fonts/simfang.ttf')
im_show = Image.fromarray(im_show)
im_show.save('result_page_{}.jpg'.format(idx))结果可视化

4、标注工具
可以参考ocr标注工具(里面有教程)
或直接安装
pip install PPOCRLabel # 安装
# 选择标签模式来启动
PPOCRLabel --lang ch # 启动【普通模式】,用于打【检测+识别】场景的标签
PPOCRLabel --lang ch --kie True # 启动 【KIE 模式】,用于打【检测+识别+关键字提取】场景的标签5、数据准备
5.1 获取源代码
将PaddleOCR-release-2.6文件夹(即开头介绍的2.6版本的项目文件)里的PPOCRLabel文件夹、Preliminary_training文件夹复制到PaddleOCR文件夹(就是开头介绍的官方项目文件)的根目录里、并在根目录下创建一个名称为inference_model的文件夹
cd 到 PPOCRLabel 目录下
cd D:\cs\PaddleOCR\PPOCRLabel5.2 启动标注工具
终端输入命令
# todo 启动【普通模式】,用于打【检测+识别】场景的标签
PPOCRLabel --lang ch5.3 打开数据集
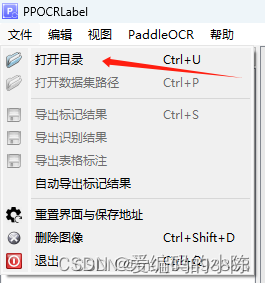
5.4 标注
(1)自动标注
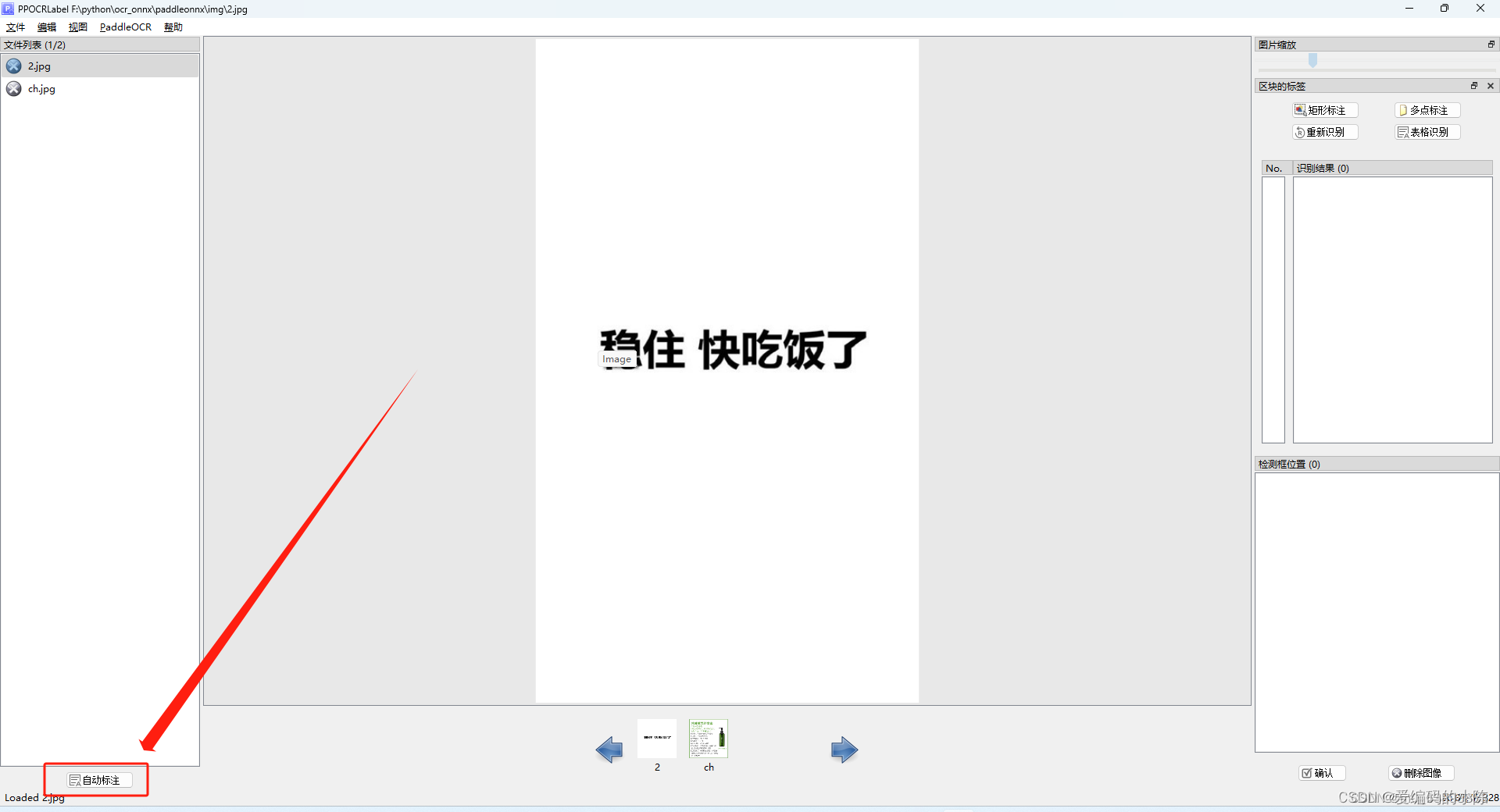
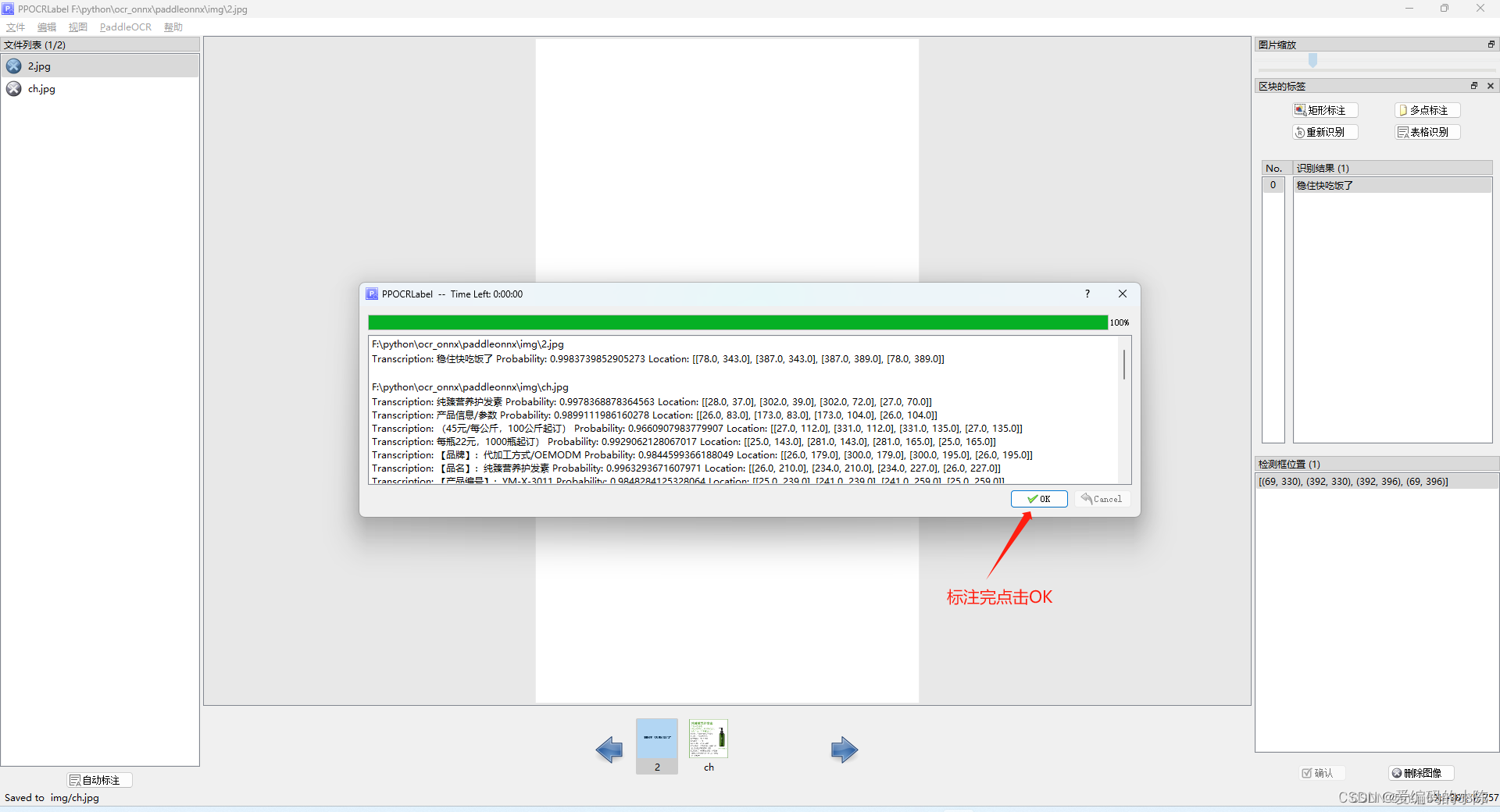

(2)手动标注
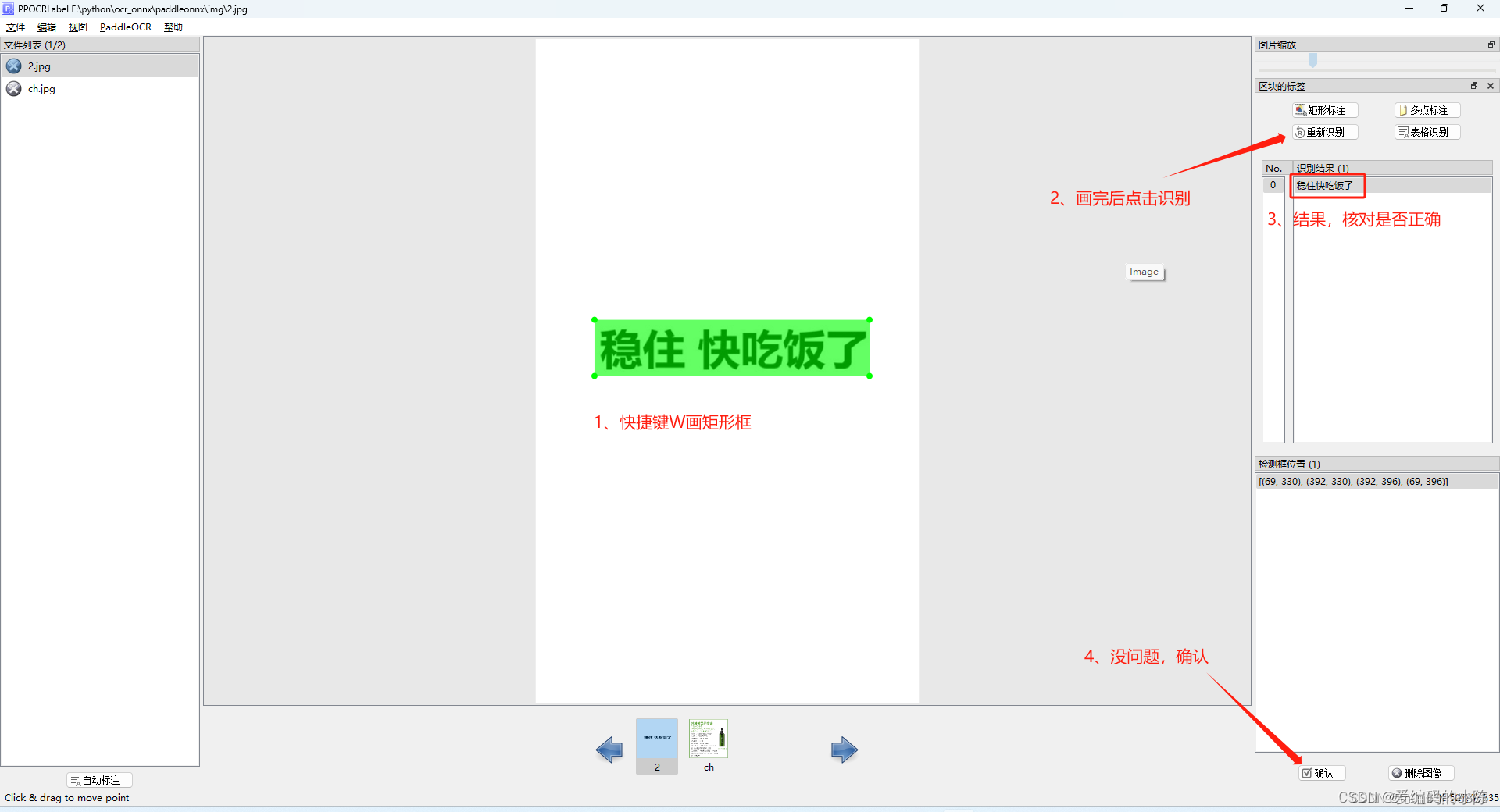
5.5 导出结果
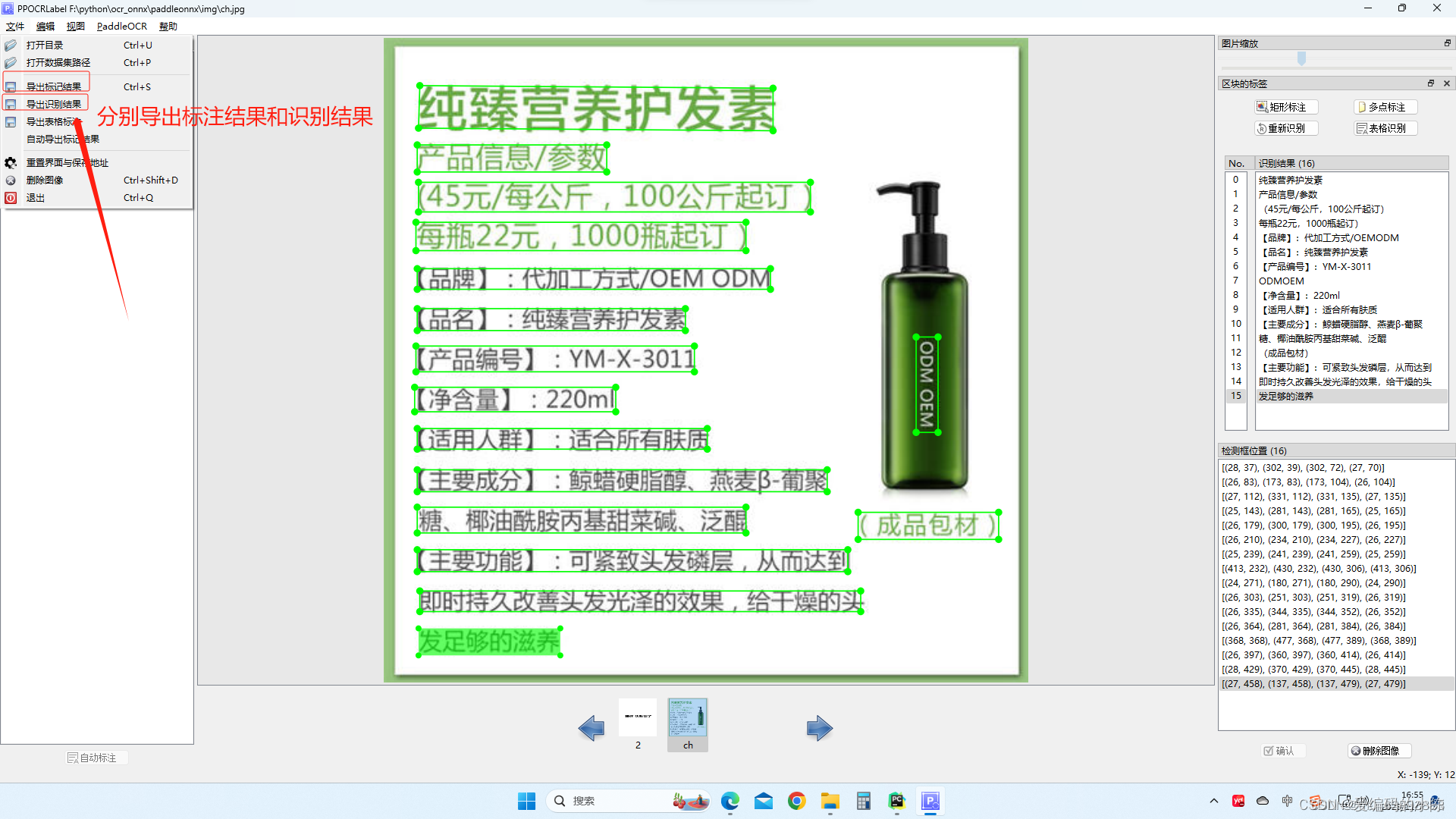

5.6 数据整理
标注完成之后,还是在PPOCRLabel目录下,终端输入命令
python gen_ocr_train_val_test.py --trainValTestRatio 6:2:2 --datasetRootPath ../数据集相对路径,
#我的是在D:\cs\PaddleOCR\ppocr_img\imgs下建立了一个dataset文件夹下,将上面导出的东西和原始图像放在了这个文件夹下
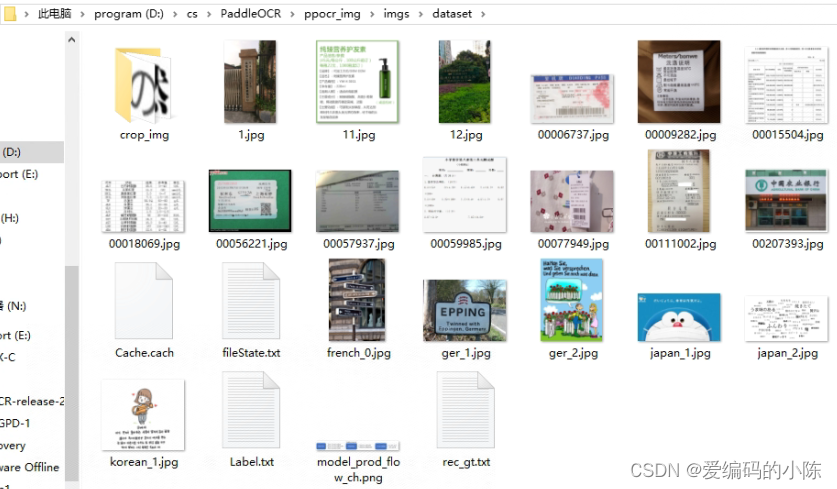
因此命令是
python gen_ocr_train_val_test.py --trainValTestRatio 6:2:2 --datasetRootPath D:\cs\PaddleOCR\ppocr_img\imgs\dataset之后会在根目录下自动创建一个train_data的文件夹
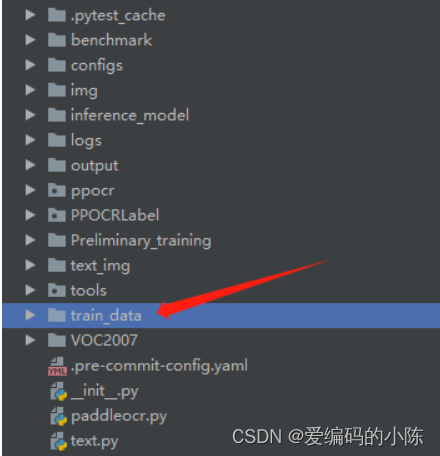
里面就是分好的数据
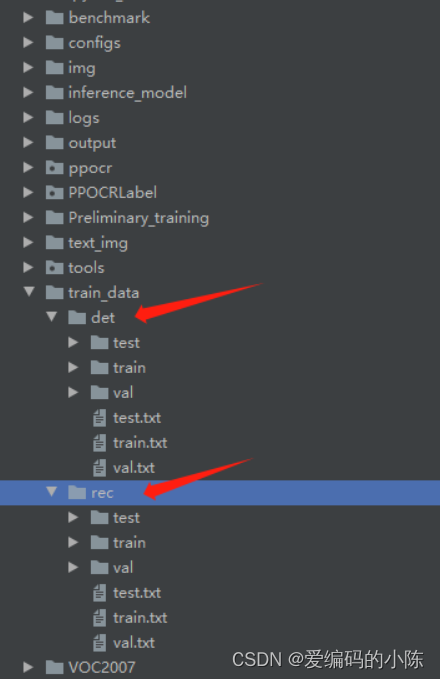
此时文字检测和文字识别的数据集就都制作好了。
二、训练模型
1、训练模型获取
paddleocr之gitcode
github可能下载不了模型,只能用gitcode的
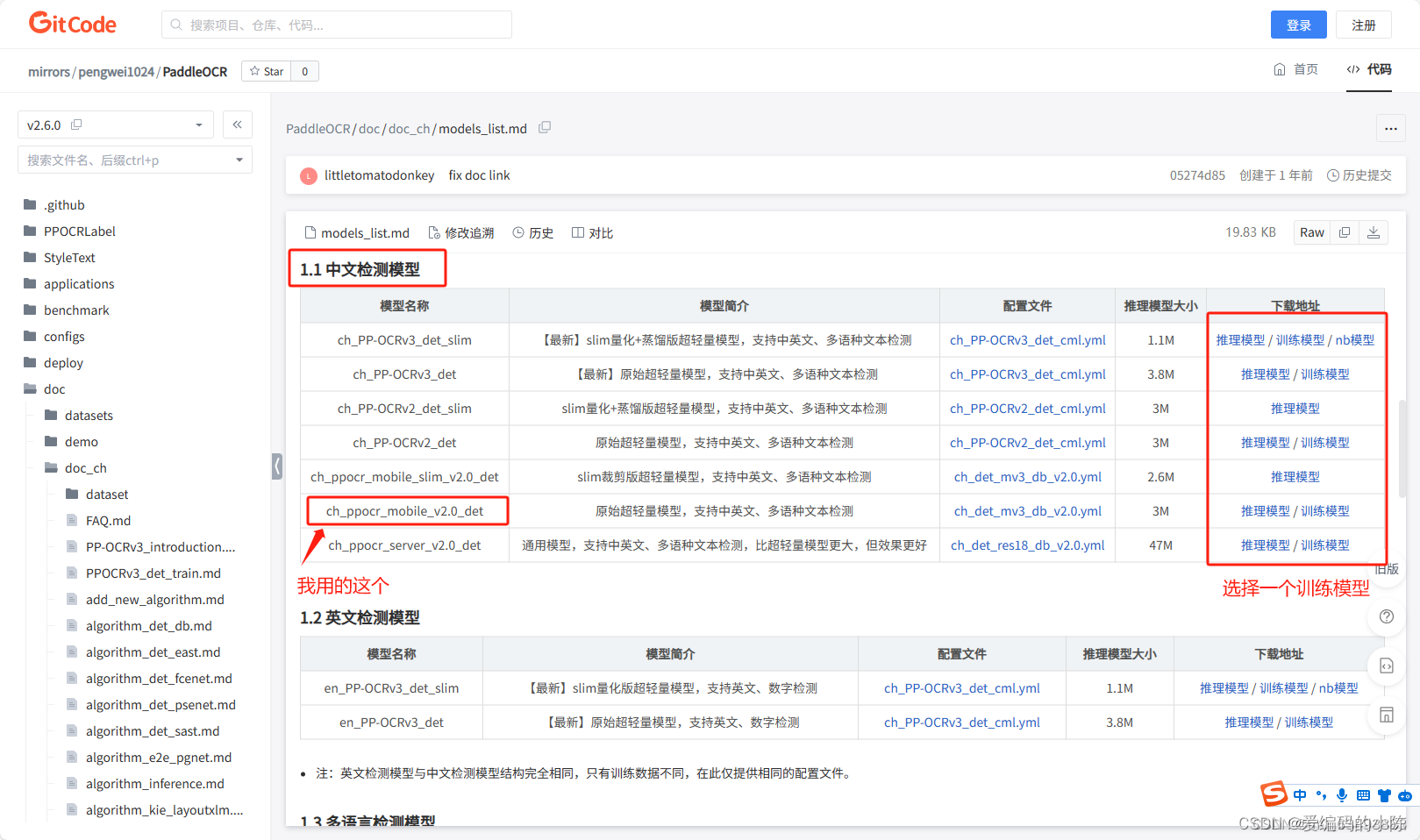
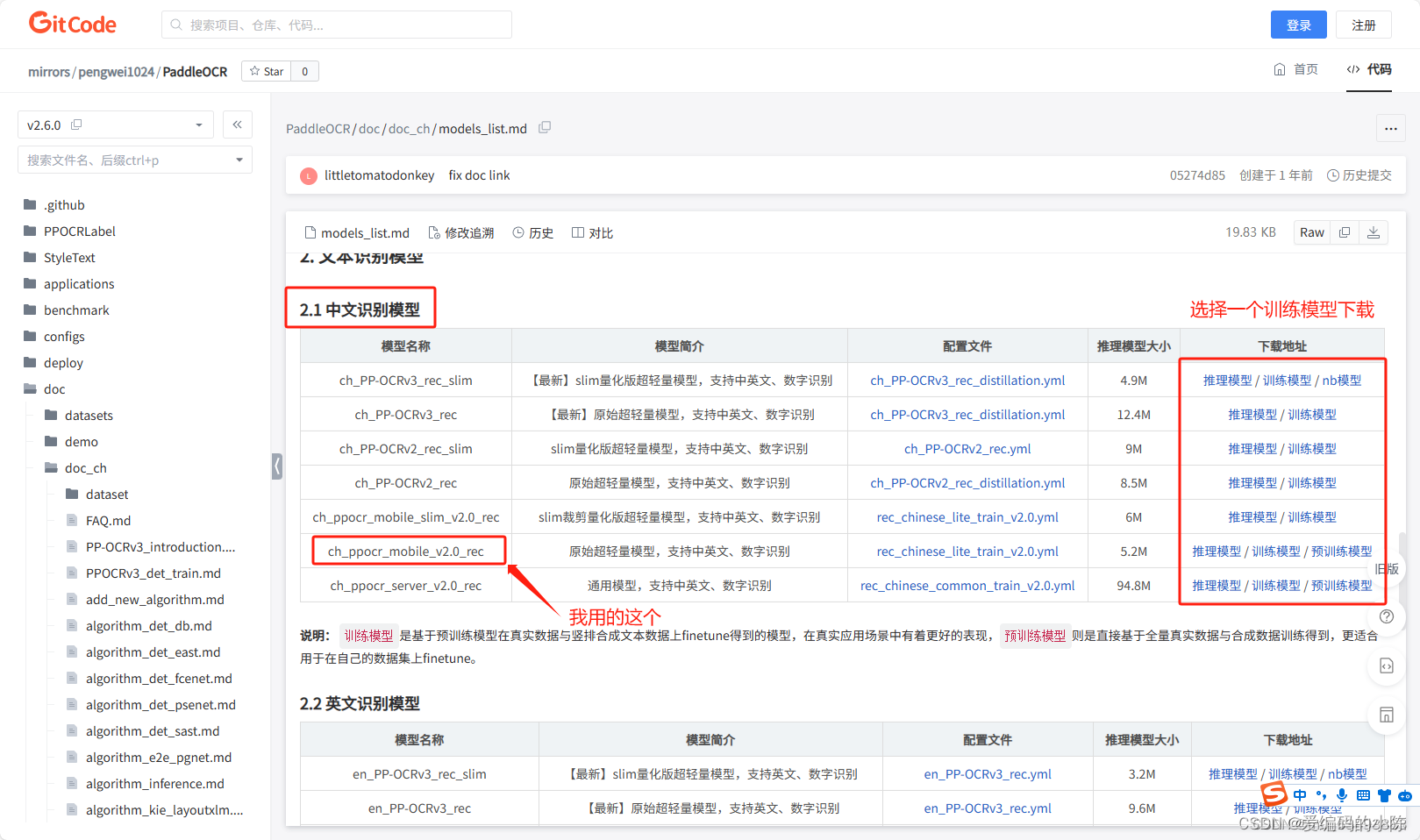
下载之后在PaddleOCR根目录下建立Preliminary_training文件夹(上面已经从PaddleOCR-release-2.6文件夹中复制过来了,包括权重文件,因此不用再新建了),并将训练模型解压至该文件夹下。如下图所示:
2、det模型训练
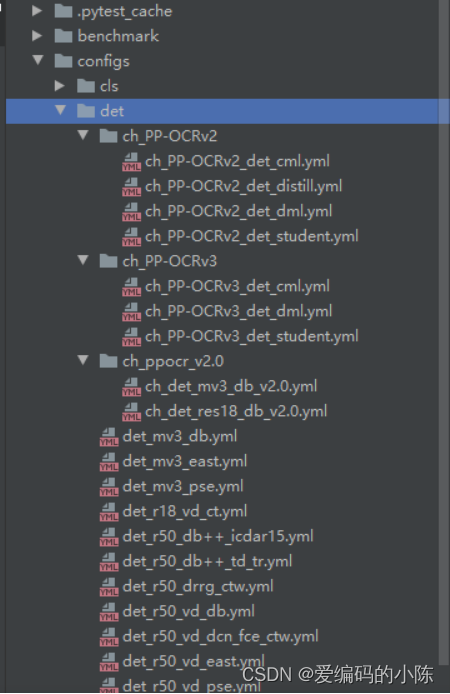
2.1 找到det模型对应的yml文件
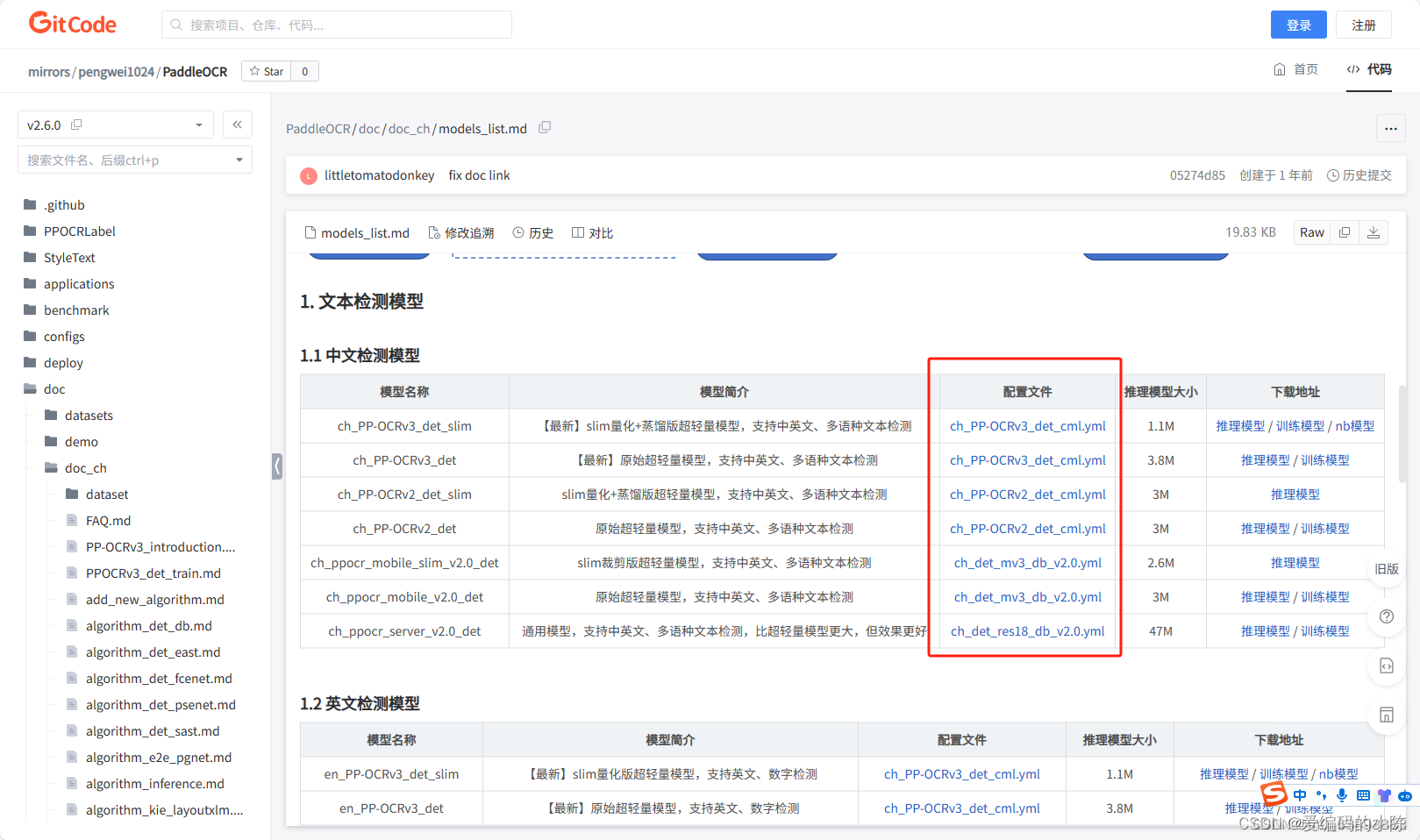
在项目的configs里面找到需要修改的yml文件
2.2 修改配置文件的参数(我这里以det_mv3_db.yml为例,需要修改的参数都差不多)
2.2.1 第一部分
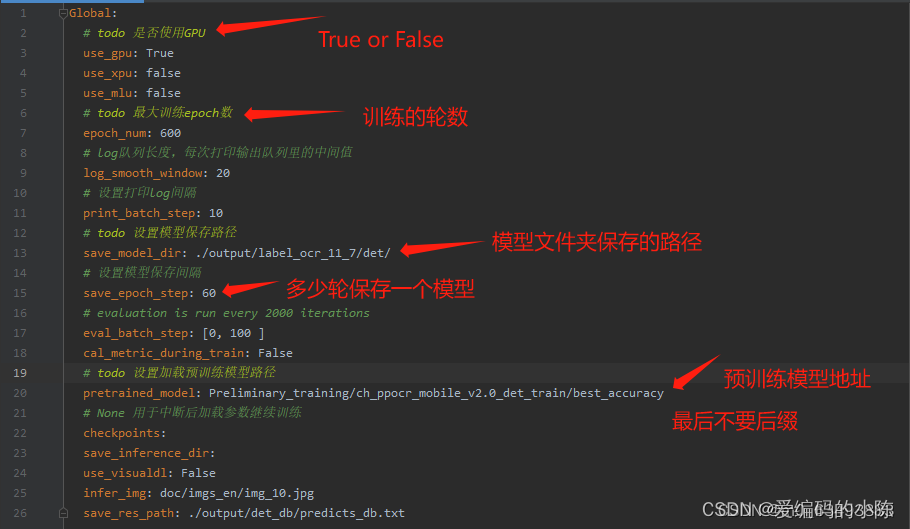
2.2.2 第二部分
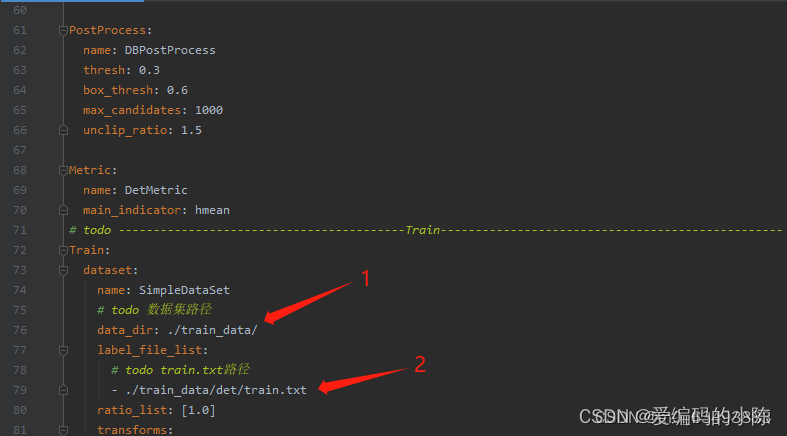
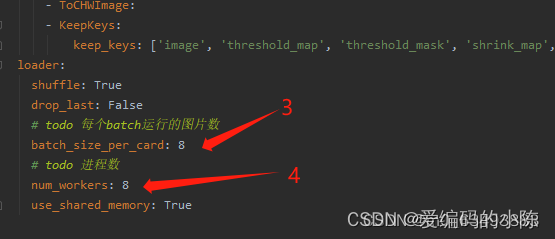
2.2.3 第三部分
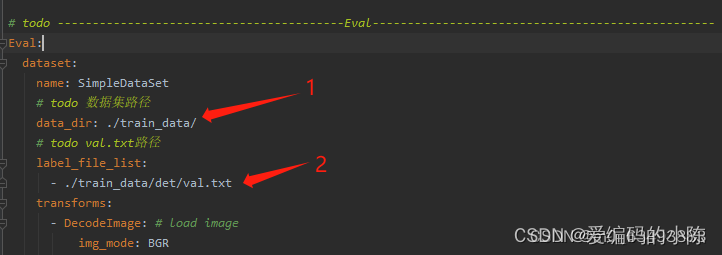
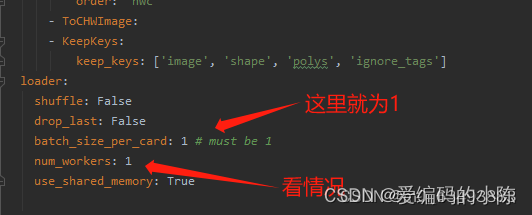
2.3 开始训练
激活环境进入到PaddleOCR根目录下。
activate ocr
cd D:\cs\PaddleOCR输入以下指令开始模型训练
python tools/train.py -c configs/det/"自己选的 det 的yml文件路径"我的是
python tools/train.py -c configs/det/det_mv3_db.yml出现以下画面则代表成功
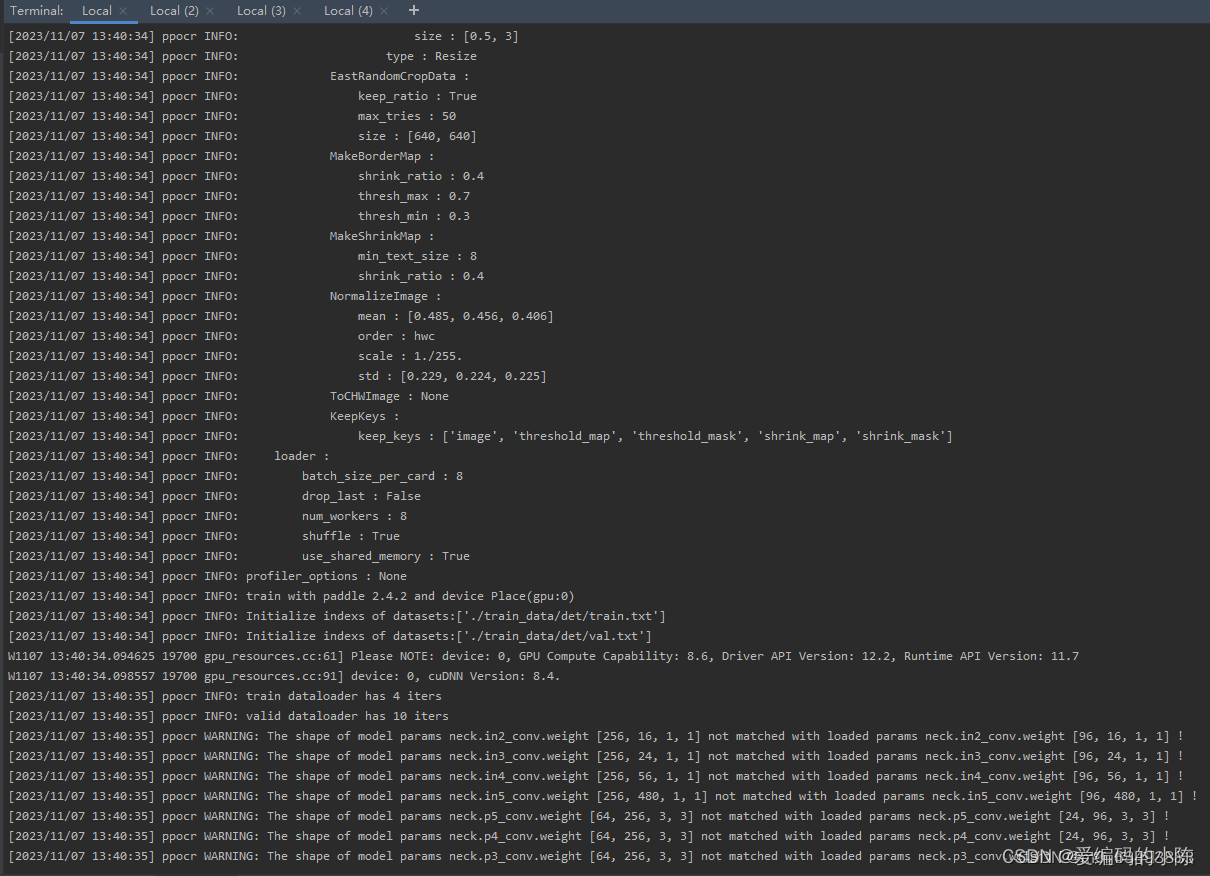
3、rec模型训练
3.1 找到rec模型对应的yml文件
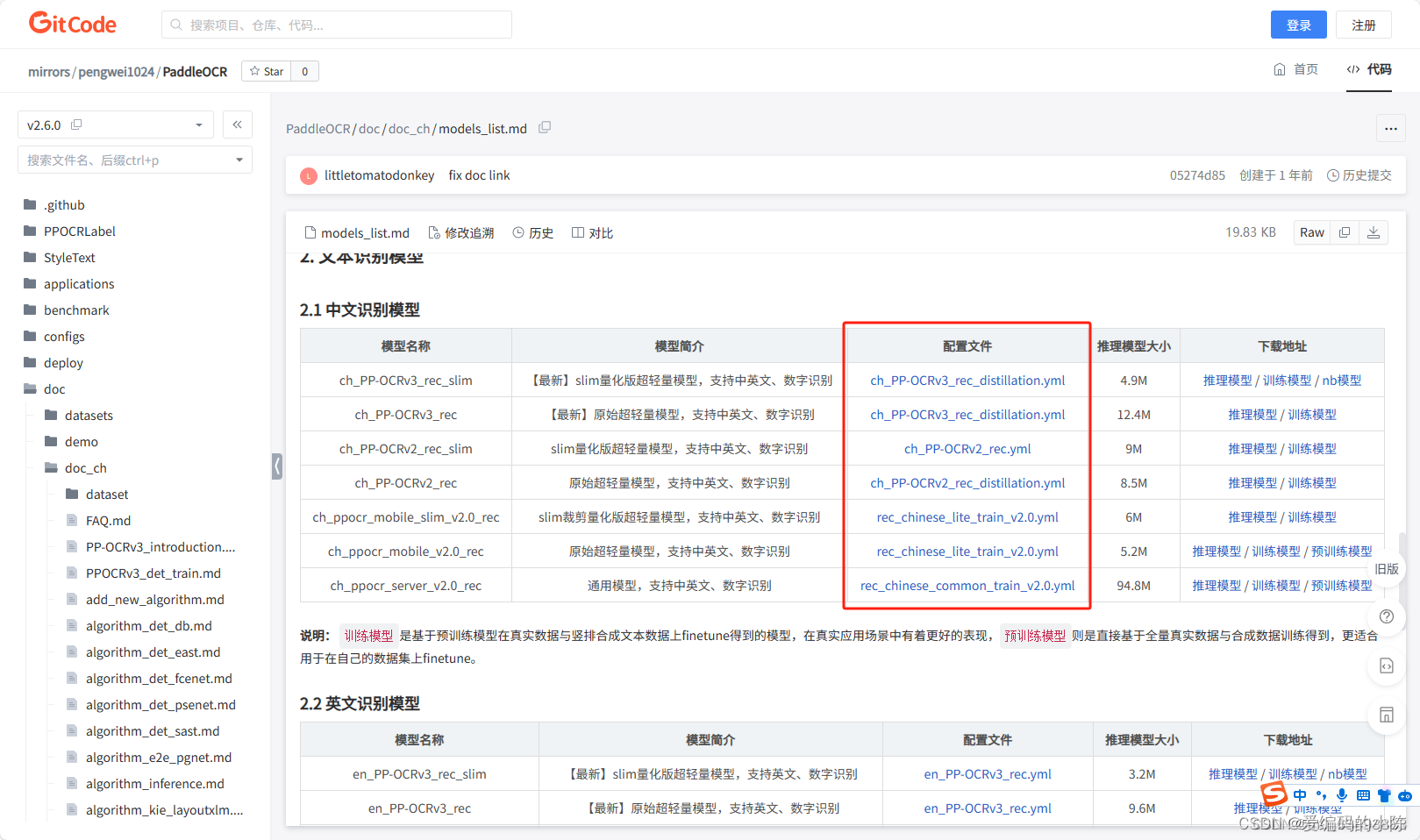
3.2 修改配置文件的参数(我这里以rec_chinese_lite_train_v2.0.yml为例,需要修改的参数都差不多)
3.2.1 第一部分
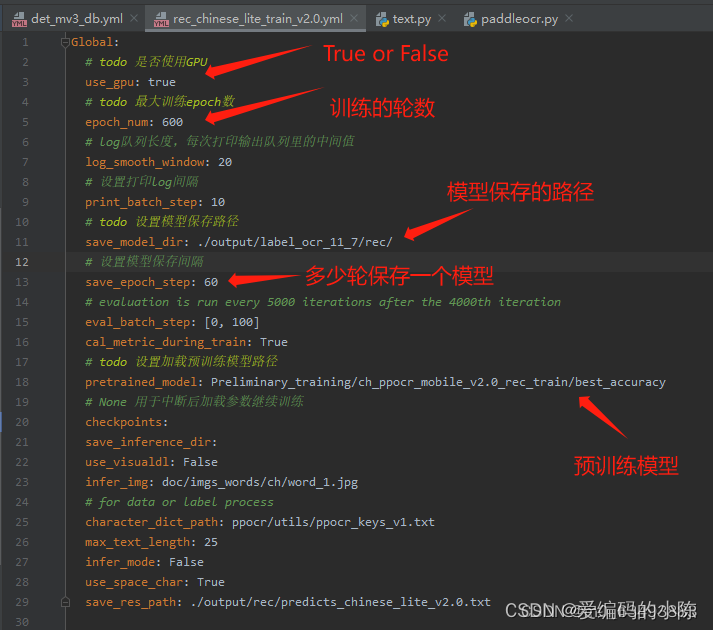
3.2.2 第二部分
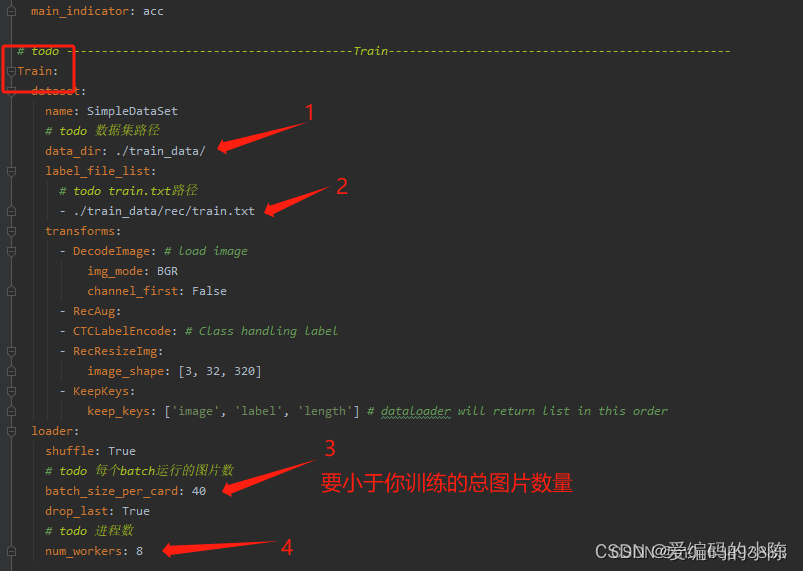
3.2.3 第三部分
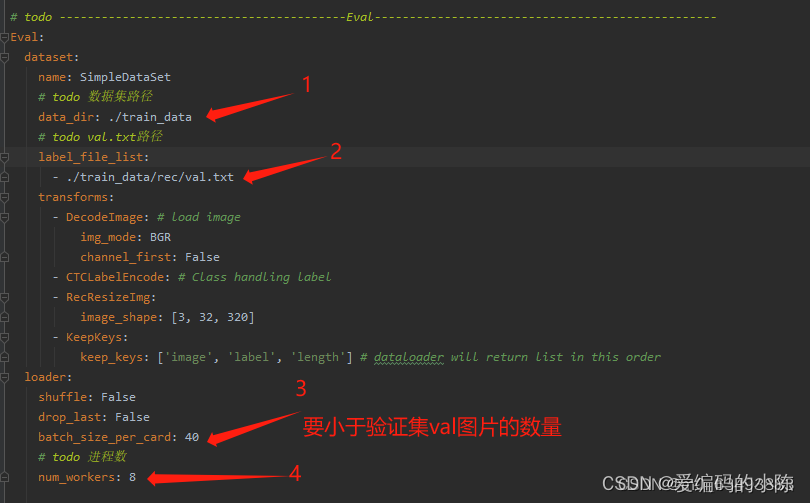
3.3 开始训练
激活环境进入到PaddleOCR根目录下。输入以下指令开始模型训练
python tools/train.py -c configs/rec/"自己选的 rec 的yml文件路径"我的是
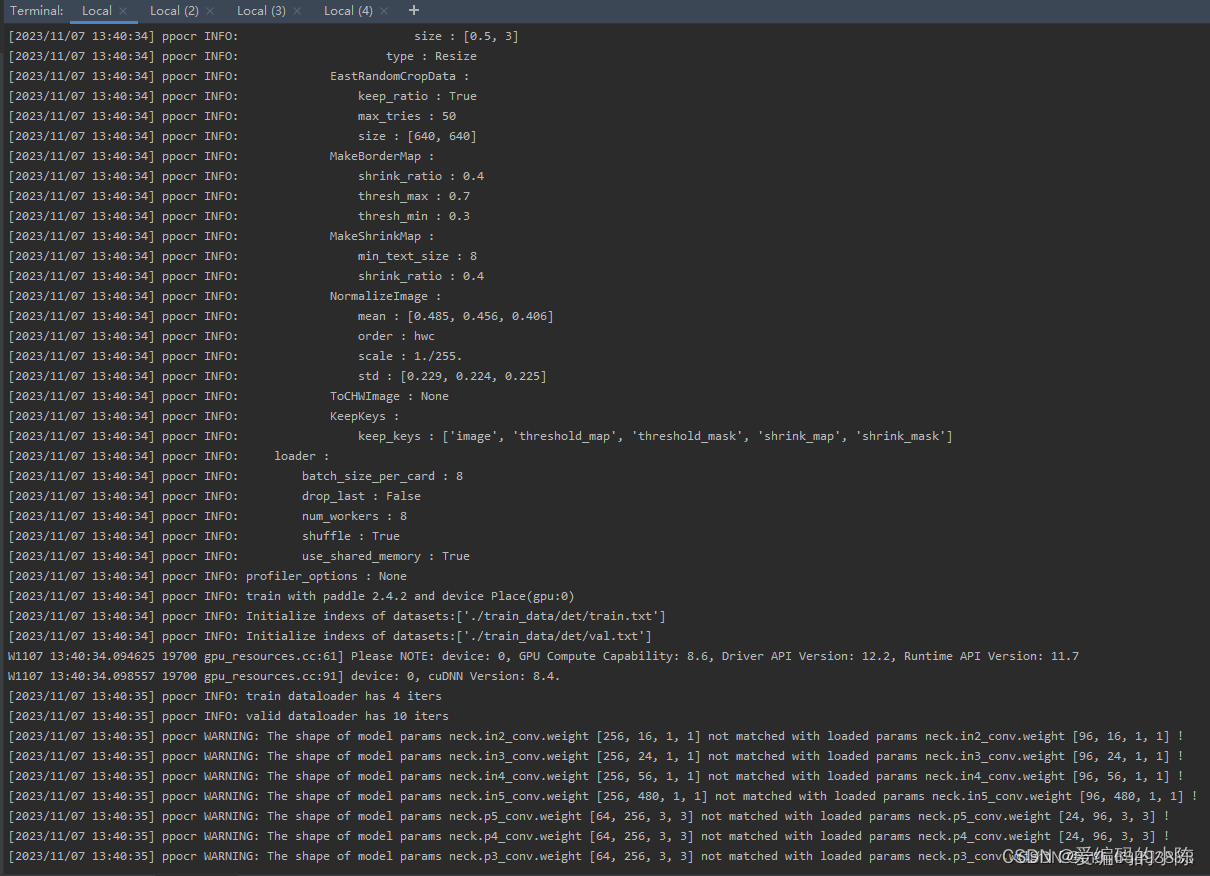
python tools/train.py -c configs/rec/ch_ppocr_v2.0/rec_chinese_lite_train_v2.0.yml出现以下画面则代表成功
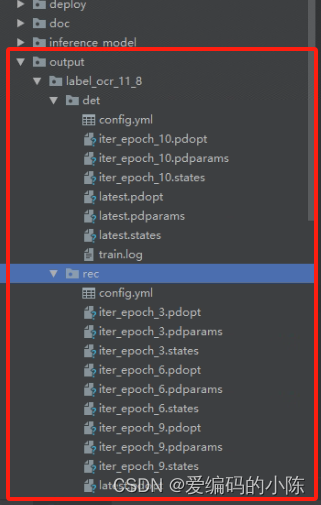
最后训练好可以在./output 下面查看训练后的模型
三、转换成推理模型
需要将生成的转换成为infer文件 命令如下:
需要修改三个地方,改的时候去掉引号
# 将生成的模型转换成 infer 文件 最好的模型轮数 保存的目录地址
python tools/export_model.py -c configs/"det or rec 对应的yml地址" -o Global.checkpoints=./output/"需要转换的模型地址"/best_accuracy Global.save_inference_dir=./"模型保存地址"/例如我的是
det 和 rec
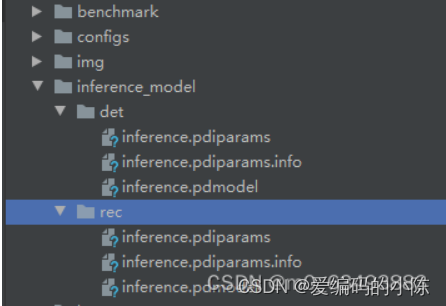
python tools/export_model.py -c configs/det/det_mv3_db.yml -o Global.checkpoints=./output/label_ocr_11_8/det/latest Global.save_inference_dir=./inference_model/det/python tools/export_model.py -c configs/rec/ch_ppocr_v2.0/rec_chinese_lite_train_v2.0.yml -o Global.pretrained_model=./output/label_ocr_11_8/rec/latest Global.save_inference_dir=./inference_model/rec/转换后的模型会保存在你创建的目录下
四、测试
将det和rec模型替换成自己路径下的模型即可
这个代码是预测文件夹的示例
import os
from PIL import Image
def batch_ocr(input_dir, output_dir):
from paddleocr import PaddleOCR, draw_ocr
ocr = PaddleOCR(det_model_dir='inference_model/det', rec_model_dir='inference_model/rec', use_angle_cls=True,
use_gpu=False)
# 遍历输入文件夹下的所有图片文件
for filename in os.listdir(input_dir):
if filename.endswith('.jpg') or filename.endswith('.jpeg') or filename.endswith('.png'):
img_path = os.path.join(input_dir, filename)
# 进行 OCR 识别
result = ocr.ocr(img_path, cls=True)[0]
if result is not None:
# 获取识别结果的坐标、文本和置信度
boxes = [line[0] for line in result]
txts = [line[1][0] for line in result]
scores = [line[1][1] for line in result]
# 读取原始图片
image = Image.open(img_path).convert('RGB')
# 在原始图片上绘制识别结果
im_show = draw_ocr(image, boxes, txts, scores, font_path='doc/fonts/simfang.ttf')
im_show = Image.fromarray(im_show)
# 保存绘制结果的图片
output_path = os.path.join(output_dir, filename)
im_show.save(output_path)
else:
print(f"No result found for image: {img_path}")
continue # 或者其他错误处理逻辑
if __name__ == '__main__':
# Ocr()
input_dir = r'text_img/Eval_img'
output_dir = r'text_img/result_img'
batch_ocr(input_dir, output_dir)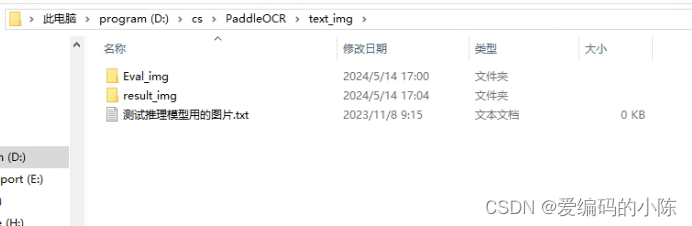
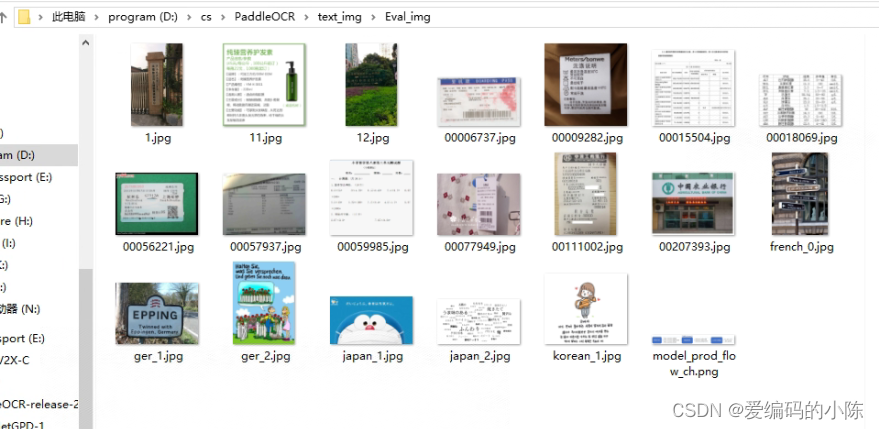
result_img文件夹存放同名预测结果
五、过程中遇到的问题和解决方法
解决问题:Could not locate zlibwapi.dll. Please make sure it is in your library path!
出现问题如下:

这个错误表示找不到zlibwapi.dll这个动态链接库文件。zlibwapi.dll是zlib库的Windows版本,一些Python包在Windows上需要依赖它。
关于zlibwapi.all这个文件可以到NVIDIA官网下载,链接为:添加链接描述
如下图所示:
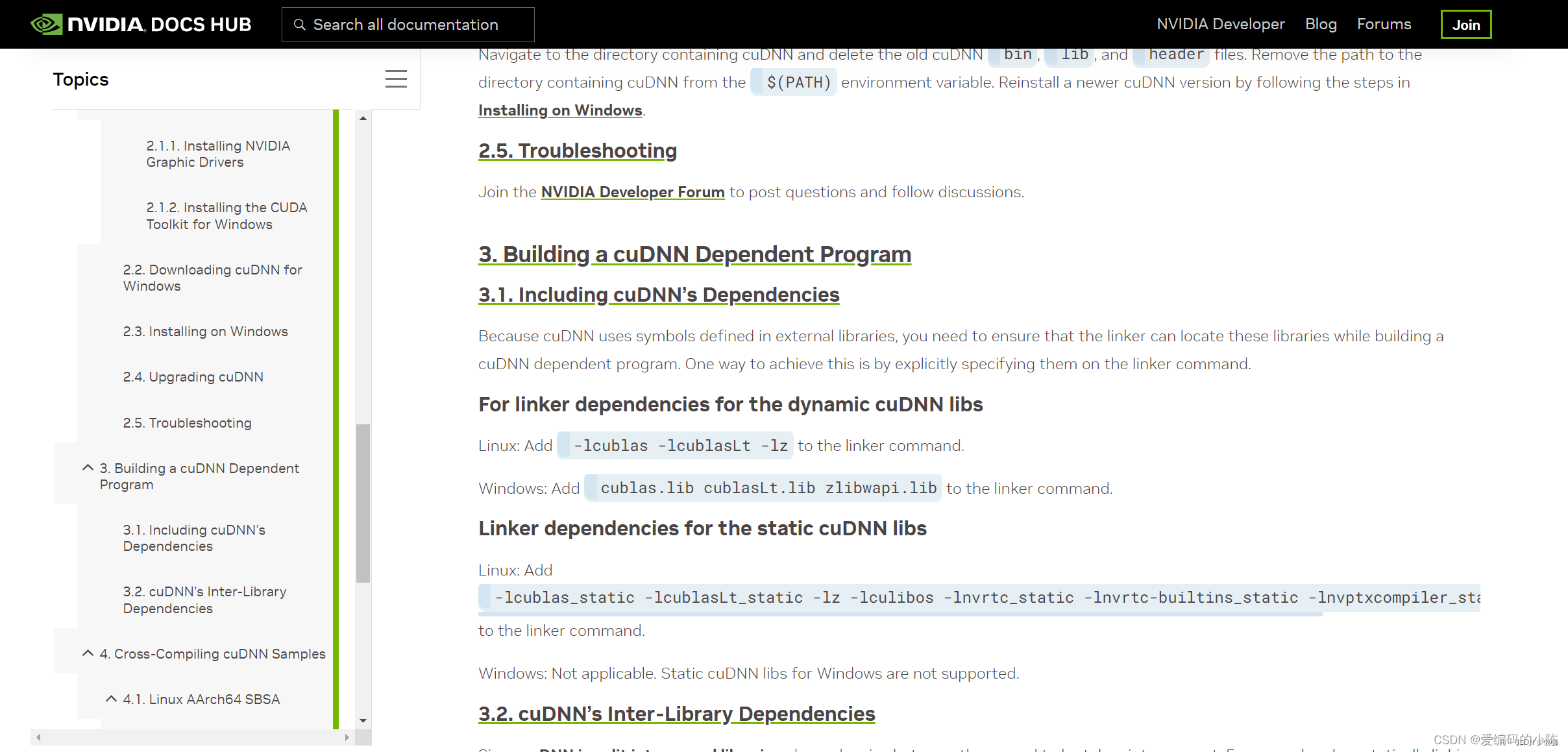
下载的时候点击另存为就行,如果实在下载不了的到我网盘里下载包:链接为:添加链接描述
链接:https://pan.baidu.com/s/1v0E0Q3kpHv6ovZ7ZNIy0wg
提取码:irjk
下载好包后解压,并将各个文件添加到指定路径,如下:
zlibwapi.lib文件放到C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.5\lib
zlibwapi.dll文件放到C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.5\bin
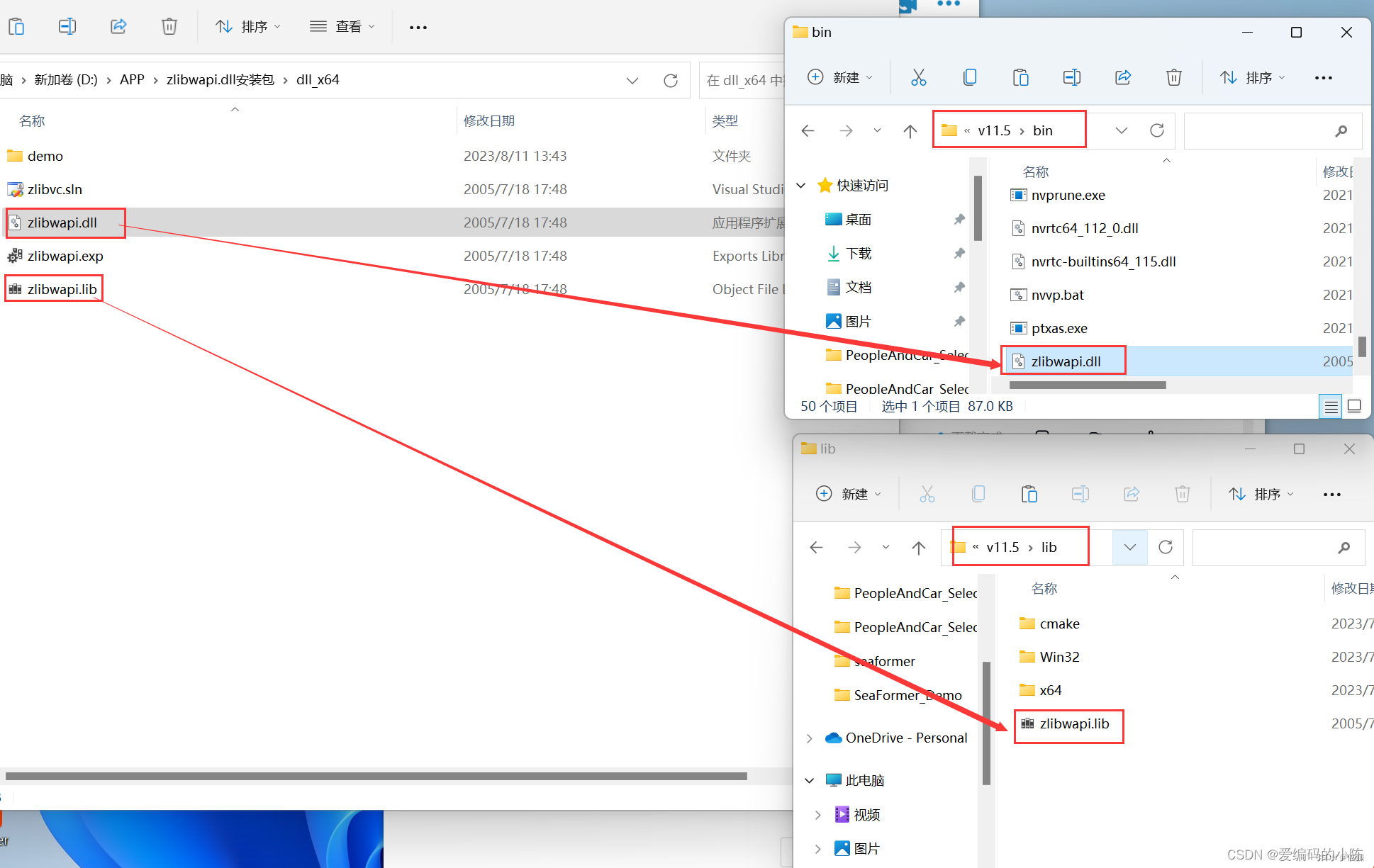
添加好包后再运行代码,就可以解决Could not locate zlibwapi.dll. Please make sure it is in your library path!
参考文献
1.解决问题:Could not locate zlibwapi.dll. Please make sure it is in your library path!
2.PadleOCR训练自己的ocr模型之训练步骤
3.PadleOCR训练自己的ocr模型之数据标注及导出
4.PaddleOCR
5.运行环境准备
6.PPOCRLabelv2
7.PaddleOCR 快速开始
8.PaddlePaddle / PaddleOCR Public训练自己的数据集
9.PaddleOCR训练自己的数据集(已踩坑windows10)
10.PaddleOCR训练自己的数据






![华为昇腾310B1平台视频解码失败[ERROR] Send frame to vdec failed, errorno:507018](https://img-blog.csdnimg.cn/direct/c8c5a3e37c4147c5a9c71afa6622dbcb.png)