尽管Ultralytics 推出了最新版本的 YOLOv8 模型。但YOLOv5作为一个anchor base的目标检测的算法,YOLOv5可能比YOLOv8的效果更好。注意力机制是提高模型性能最热门的方法之一,本文给大家带来的教程是添加Swin-Transformer到backbone中。文章在介绍主要的原理后,将手把手教学如何进行模块的代码添加和修改,并将修改后的完整代码放在文章的最后,方便大家一键运行,小白也可轻松上手实践。以帮助您更好地学习深度学习目标检测YOLO系列的挑战。
专栏地址:YOLOv5改进+入门——持续更新各种有效涨点方法
目录
1.原理
2.Swin-Transformer代码
2.1 添加Swin-Transformer代码
2.2 新增yaml文件
2.3 注册模块
2.4 执行程序
3.总结
1.原理

论文地址:Swin-Transformer点击即可跳转
官方代码:Swin-Transformer官方代码仓库点击即可跳转
Swin-Transformer是MRA的作品,而MRA撑起了深度学习的半边天。
Swin-Transformer是2021年微软研究院发表在ICCV上的一篇文章,并且已经获得ICCV 2021 best paper 的荣誉称号。Swin Transformer网络是Transformer模型在视觉领域的又一次碰撞。该论文一经发表就已在多项视觉任务中霸榜。
Swin Transformer使用了类似卷积神经网络中的层次化构建方法(Hierarchical feature maps),比如特征图尺寸中有对图像下采样4倍的,8倍的以及16倍的,这样的backbone有助于在此基础上构建目标检测,实例分割等任务。而在之前的Vision Transformer中是一开始就直接下采样16倍,后面的特征图也是维持这个下采样率不变。
在Swin Transformer中使用了Windows Multi-Head Self-Attention(W-MSA)的概念,比如在下图的4倍下采样和8倍下采样中,将特征图划分成了多个不相交的区域(Window),并且Multi-Head Self-Attention只在每个窗口(Window)内进行。相对于Vision Transformer中直接对整个特征图进行Multi-Head Self-Attention,这样做的目的是能够减少计算量的,尤其是在浅层特征图很大的时候。这样做虽然减少了计算量但也会隔绝不同窗口之间的信息传递,所以在论文中作者又提出了 Shifted Windows Multi-Head Self-Attention(SW-MSA)的概念,通过此方法能够让信息在相邻的窗口中进行传递。
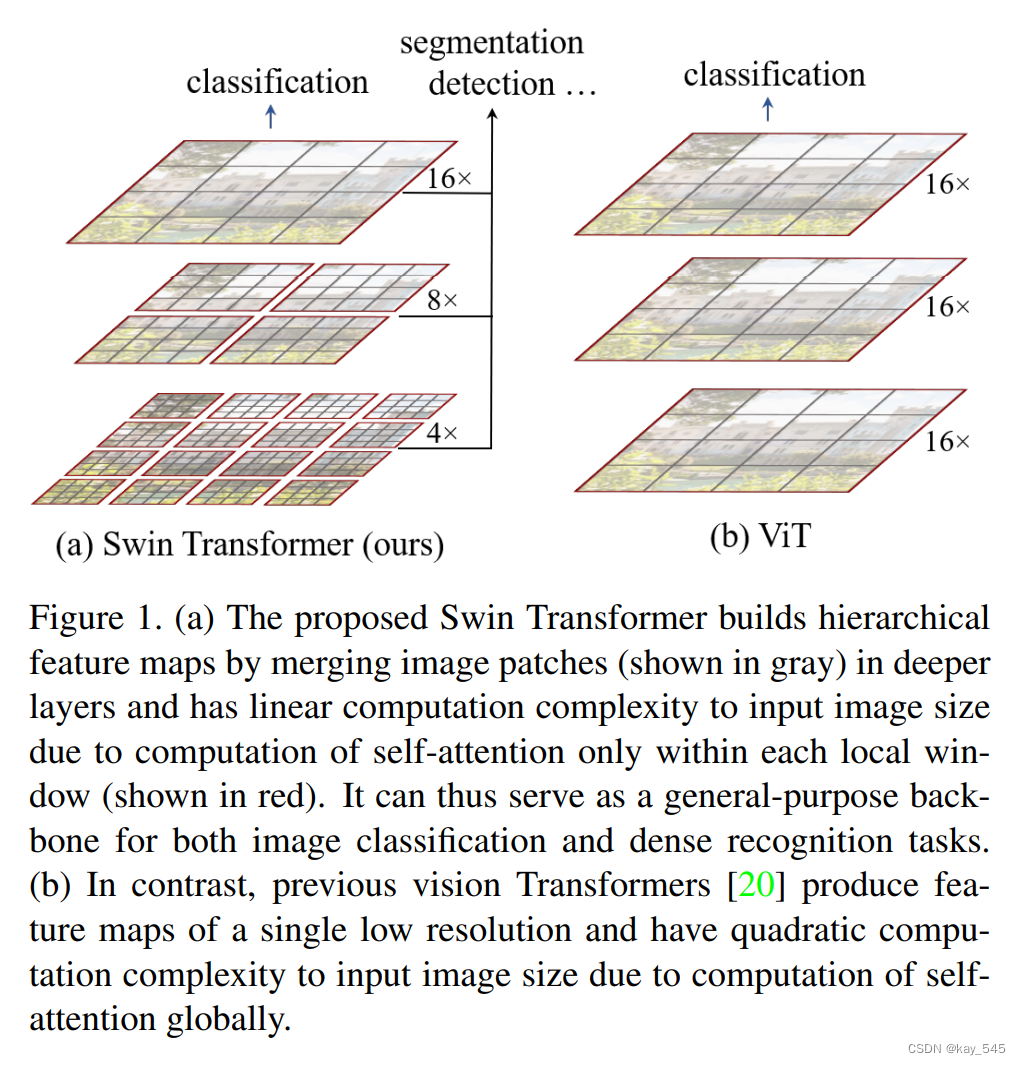
因此,Swin-Transformer在计算效率上相对于传统的 Transformer 架构具有优势。Swin Transformer 是一种高效且性能优越的深度学习模型,适用于图像分类、目标检测等视觉任务,并且在处理大规模图像数据时表现出色。
注意:因为涉及代码较多,比较冗长,因此在此处不在放置完整代码,只放关键代码,完整代码可以查看文章末尾的内容。
2.Swin-Transformer代码
2.1 添加Swin-Transformer代码
关键步骤一:在\yolov5-6.1\models\common.py中添加下面代码
class SwinStage(nn.Module):
def __init__(self, dim, c2, depth, num_heads, window_size,
mlp_ratio=4., qkv_bias=True, drop=0., attn_drop=0.,
drop_path=0., norm_layer=nn.LayerNorm, use_checkpoint=False):
super().__init__()
assert dim==c2, r"no. in/out channel should be same"
self.dim = dim
self.depth = depth
self.window_size = window_size
self.use_checkpoint = use_checkpoint
self.shift_size = window_size // 2
# build blocks
self.blocks = nn.ModuleList([
SwinTransformerBlock(
dim=dim,
num_heads=num_heads,
window_size=window_size,
shift_size=0 if (i % 2 == 0) else self.shift_size,
mlp_ratio=mlp_ratio,
qkv_bias=qkv_bias,
drop=drop,
attn_drop=attn_drop,
drop_path=drop_path[i] if isinstance(drop_path, list) else drop_path,
norm_layer=norm_layer)
for i in range(depth)])
def create_mask(self, x, H, W):
# calculate attention mask for SW-MSA
# 保证Hp和Wp是window_size的整数倍
Hp = int(np.ceil(H / self.window_size)) * self.window_size
Wp = int(np.ceil(W / self.window_size)) * self.window_size
# 拥有和feature map一样的通道排列顺序,方便后续window_partition
img_mask = torch.zeros((1, Hp, Wp, 1), device=x.device) # [1, Hp, Wp, 1]
h_slices = (slice(0, -self.window_size),
slice(-self.window_size, -self.shift_size),
slice(-self.shift_size, None))
w_slices = (slice(0, -self.window_size),
slice(-self.window_size, -self.shift_size),
slice(-self.shift_size, None))
cnt = 0
for h in h_slices:
for w in w_slices:
img_mask[:, h, w, :] = cnt
cnt += 1
mask_windows = window_partition(img_mask, self.window_size) # [nW, Mh, Mw, 1]
mask_windows = mask_windows.view(-1, self.window_size * self.window_size) # [nW, Mh*Mw]
attn_mask = mask_windows.unsqueeze(1) - mask_windows.unsqueeze(2) # [nW, 1, Mh*Mw] - [nW, Mh*Mw, 1]
# [nW, Mh*Mw, Mh*Mw]
attn_mask = attn_mask.masked_fill(attn_mask != 0, float(-100.0)).masked_fill(attn_mask == 0, float(0.0))
return attn_mask
def forward(self, x):
B, C, H, W = x.shape
x = x.permute(0, 2, 3, 1).contiguous().view(B, H*W, C)
attn_mask = self.create_mask(x, H, W) # [nW, Mh*Mw, Mh*Mw]
for blk in self.blocks:
blk.H, blk.W = H, W
if not torch.jit.is_scripting() and self.use_checkpoint:
x = checkpoint.checkpoint(blk, x, attn_mask)
else:
x = blk(x, attn_mask)
x = x.view(B, H, W, C)
x = x.permute(0, 3, 1, 2).contiguous()
return xSwin-Transformer模型处理流程主要包括以下几个步骤:
1. 图像分割和块划分:将输入图像分割成多个块,每个块都会被送入模型进行处理。
2. 块级特征提取:每个块经过块级特征提取阶段,使用局部注意力机制和全局注意力机制提取块级特征。
3. 块级特征整合:整合来自不同块的特征,通过跨块注意力机制实现特征的交互和整合。
4. 多层交叉处理:通过多层的交叉处理,增强模型对图像特征的表示能力。
5. 特征重组:将整合后的特征重新组合成全局特征表示。
6. 分类/回归:利用全局特征表示进行图像分类或其他任务,如对象检测或语义分割。
整个流程利用了局部和全局的位置信息,有效地捕获了图像中的不同位置和层次的信息,从而提高了模型在图像处理任务上的性能。
2.2 新增yaml文件
关键步骤二:在 /yolov5/models/ 下新建文件 yolov5_swin.yaml并将下面代码复制进去
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# Parameters
nc: 1 # number of classes
# ch: 1 # no. input channel
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.25 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
# input [b, 1, 640, 640]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2 [b, 64, 320, 320]
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4 [b, 128, 160, 160]
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8 [b, 256, 80, 80]
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16 [b, 512, 40, 40]
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32 [b, 1024, 20, 20]
[-1, 3, C3, [1024]],
[-1, 1, SwinStage, [1024, 2, 8, 4]], # [outputChannel, blockDepth, numHeaders, windowSize]
[-1, 1, SPPF, [1024, 5]], # 10
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 14
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 18 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 15], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 21 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 11], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 24 (P5/32-large)
[[18, 21, 24], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
温馨提示:因为本文只是对yolov5n基础上添加swin模块,如果要对yolov5n/l/m/x进行添加则只需要修改对应的depth_multiple 和 width_multiple。
yolov5n/l/m/x对应的depth_multiple 和 width_multiple如下:
# YOLOv5n
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.25 # layer channel multiple
# YOLOv5s
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
# YOLOv5l
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple
# YOLOv5m
depth_multiple: 0.67 # model depth multiple
width_multiple: 0.75 # layer channel multiple
# YOLOv5x
depth_multiple: 1.33 # model depth multiple
width_multiple: 1.25 # layer channel multiple2.3 注册模块
关键步骤三:在yolov5/models/yolo.py中注册,大概在250行左右添加 ‘SwinStage’
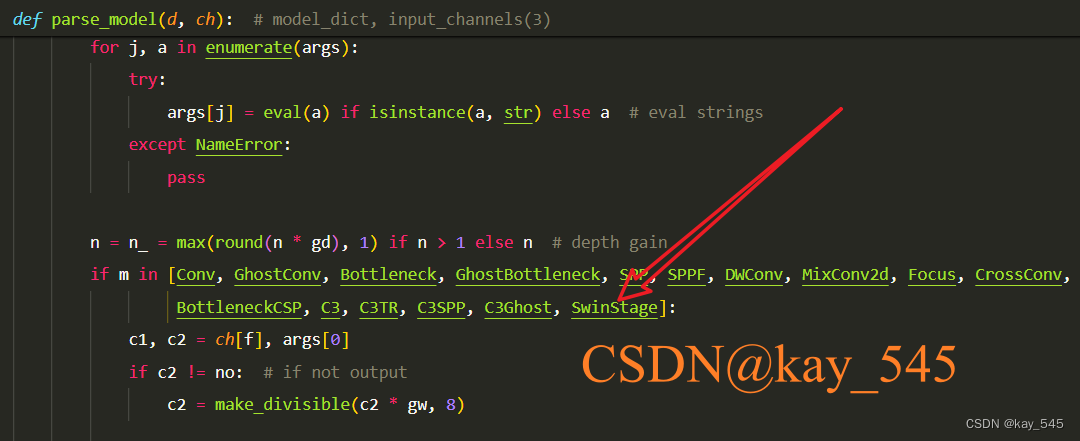
2.4 执行程序
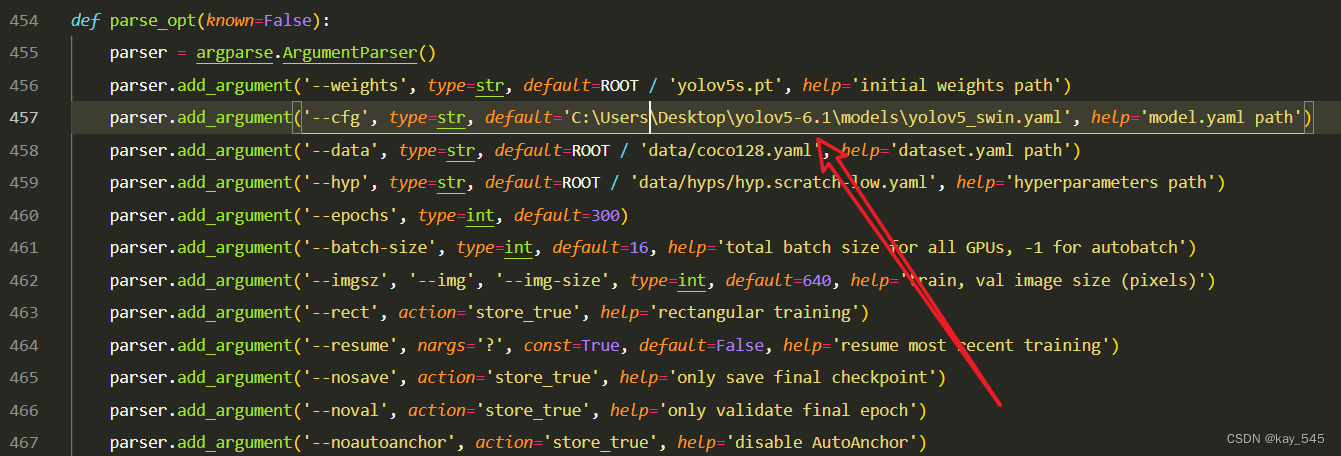
在train.py中,将cfg的参数路径设置为yolov5_swin.yaml的路径,如下图所示
建议大家写绝对路径,确保一定能找到
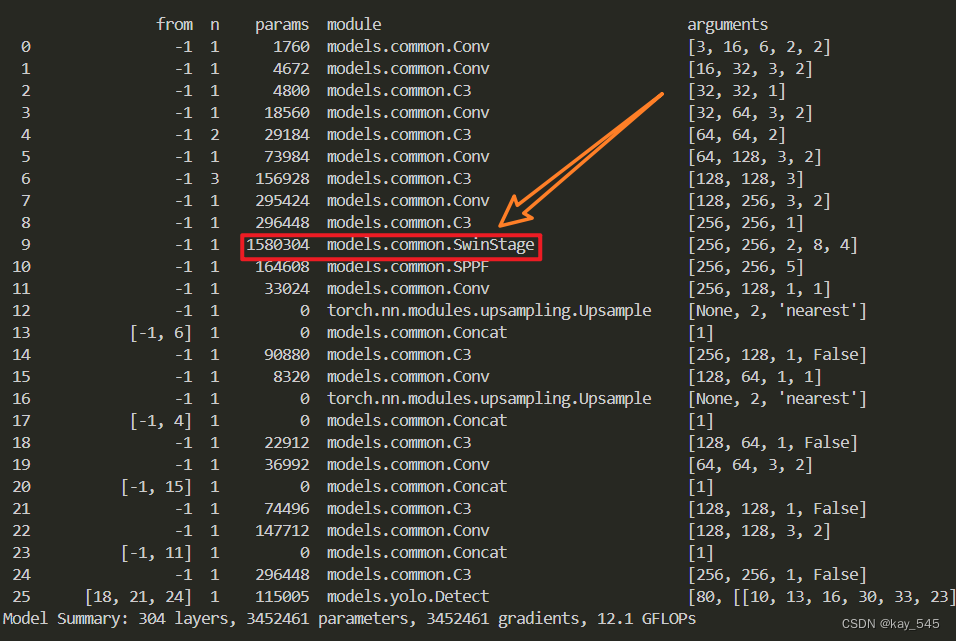
🚀运行程序,如果出现下面的内容则说明添加成功🚀
我修改后的代码:链接: https://pan.baidu.com/s/1SNAxfFWQwPgAk4Vucor_RA?pwd=afsy 提取码: afsy
3.总结
Swin Transformer 是一种基于分区注意力机制和层次化结构的先进深度学习模型,通过在局部区域内进行自注意力计算以及使用窗口式注意力机制,实现了在图像分类和目标检测等任务上优异的性能表现。其Transformer缩放技术提高了模型的可扩展性和效率,使其能够处理大规模图像数据,并在训练和推理过程中保持高效率。综合而言,Swin Transformer以其创新性的设计和卓越的性能,成为处理图像数据的一种领先模型。

![51 单片机[2-1]:点亮一个LED](https://img-blog.csdnimg.cn/img_convert/1c79b1302f7a54cb48809427d581a9be.png)