爬虫之scrapy框架--爬取电影天堂——解释多页爬取函数编写逻辑
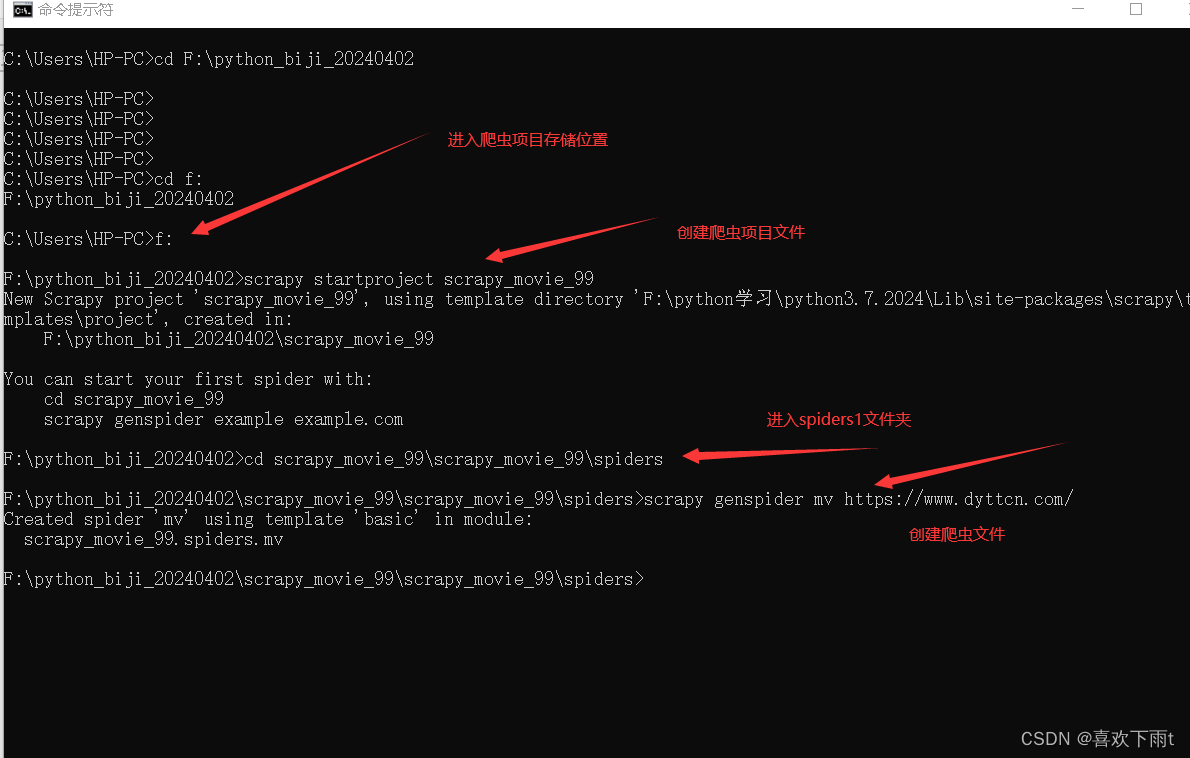
- (1)爬虫文件创建
- (2)检查网址是否正确
- (3)检查反爬
- (3.1) 简写输出语句,检查是否反爬
- (3.2) 检查结果
- (4)函数编写和需求分析
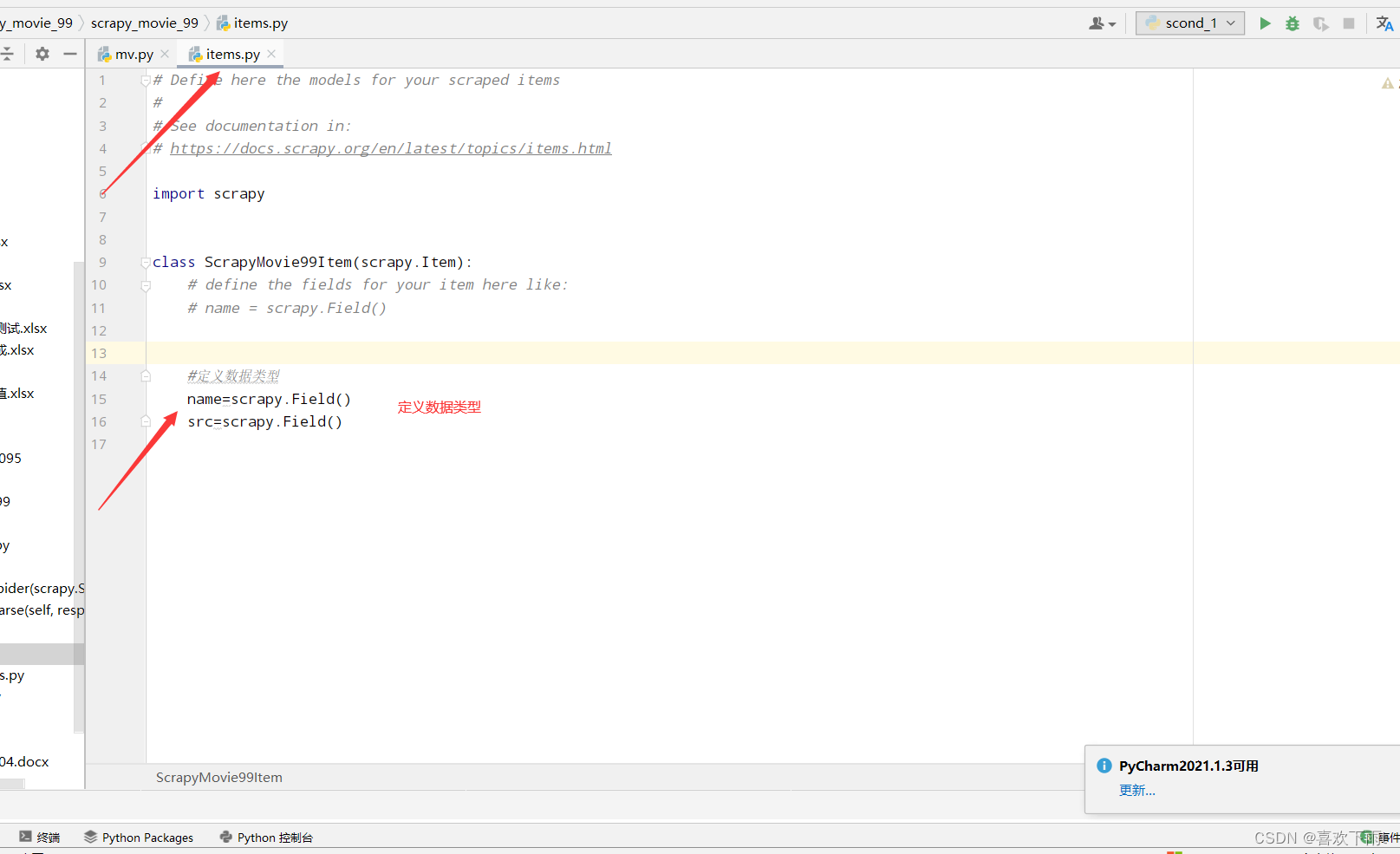
- (4.1)在items中定义数据类型
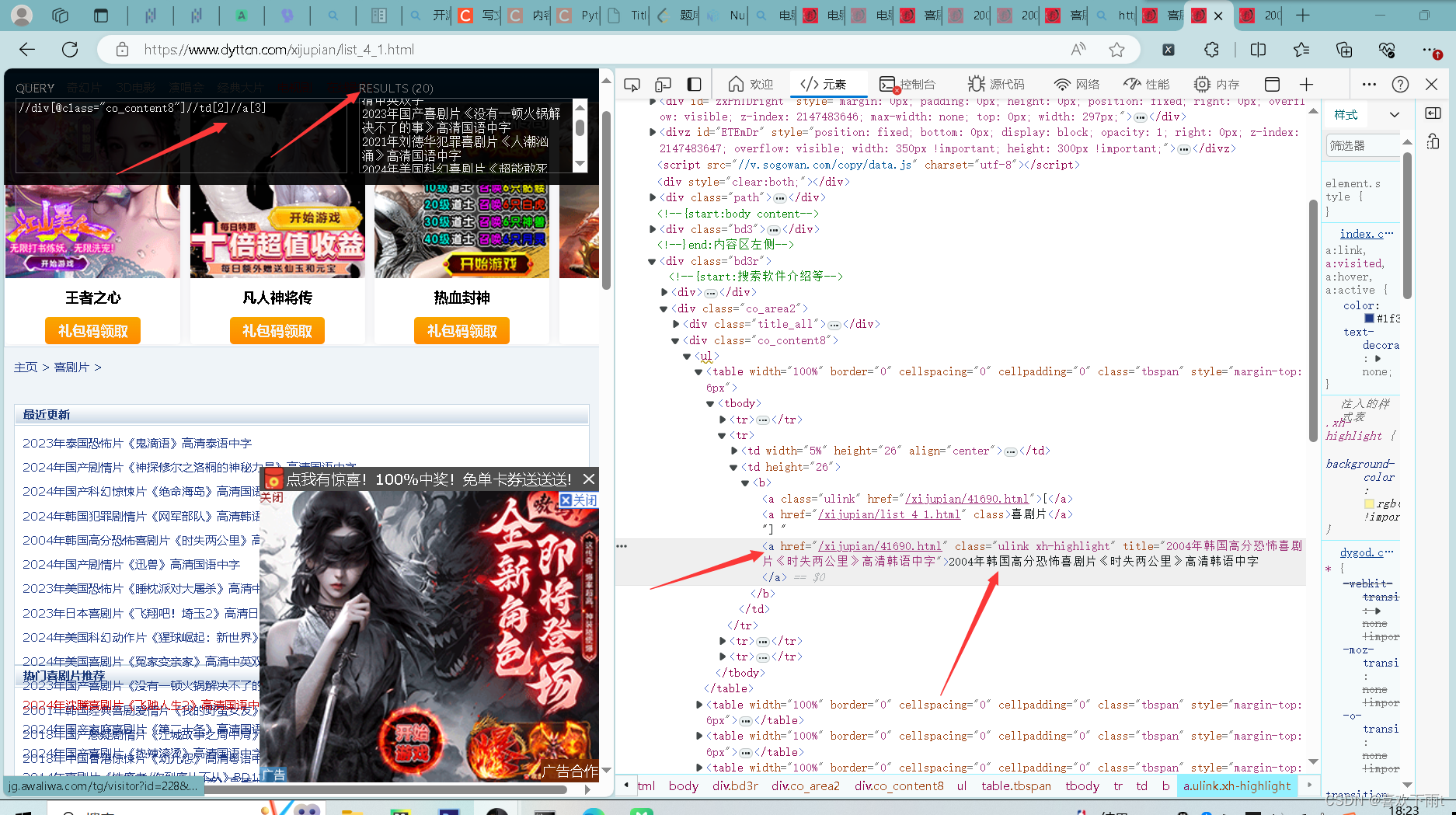
- (4.2)分析网站xpath结构
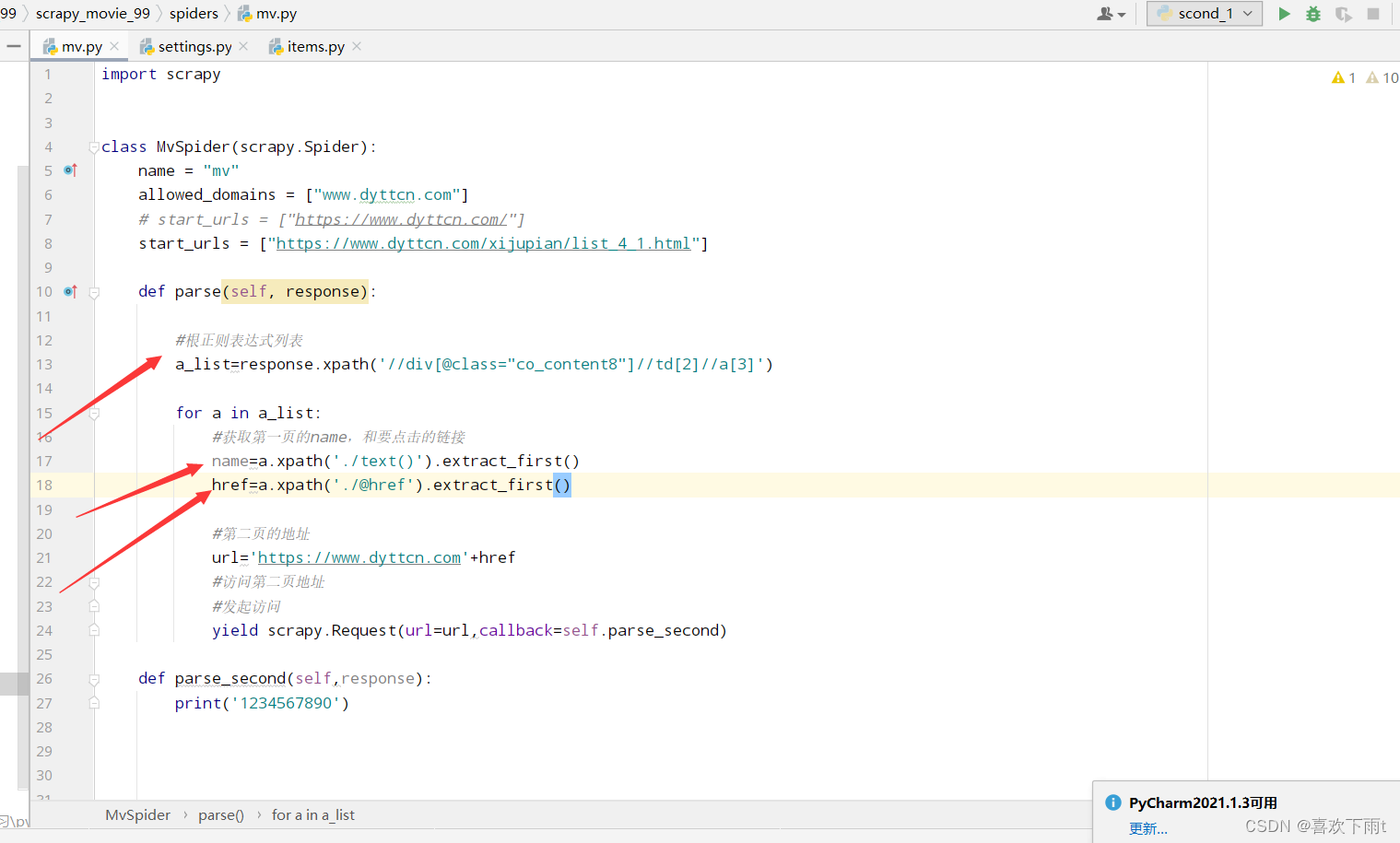
- (4.2.1)拿到第一页的名字和第二页要请求访问的网址
- (4.2.2)完整第二页的网址和请求函数编写
- (4.2.3)完整代码:
- (5)开启管道
- (6)管道封装(写入数据)
- (6)运行爬虫
- (6.1) 运行结果(ctrl+alt+L----可将数据排版一下)
- (7)总结:(该案例的作用)
(1)爬虫文件创建
(2)检查网址是否正确
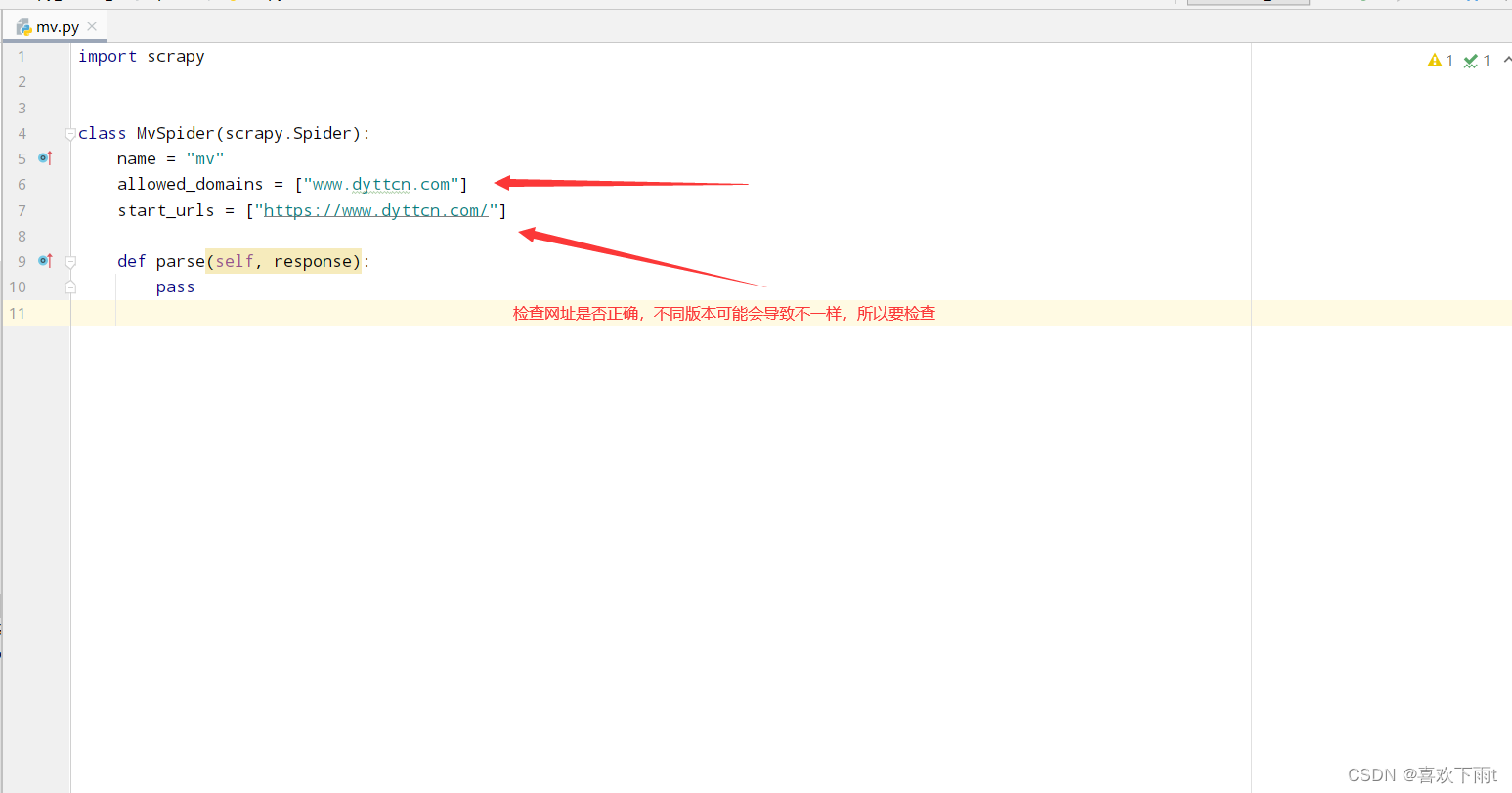
(3)检查反爬
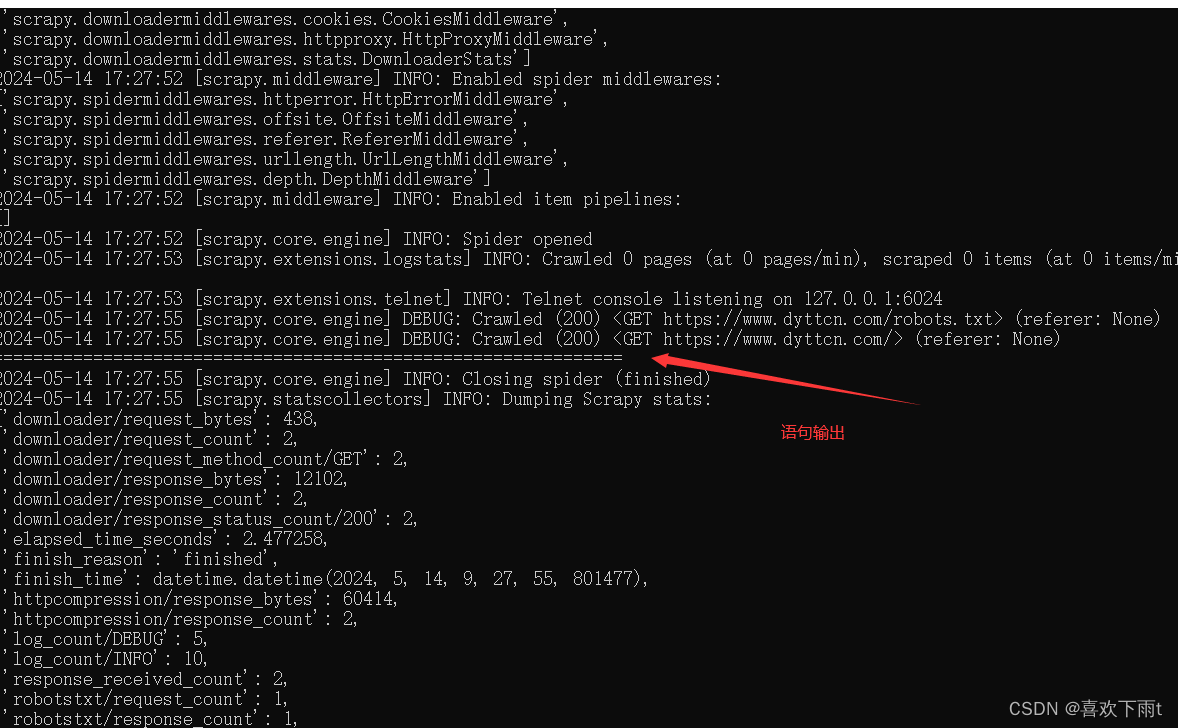
(3.1) 简写输出语句,检查是否反爬
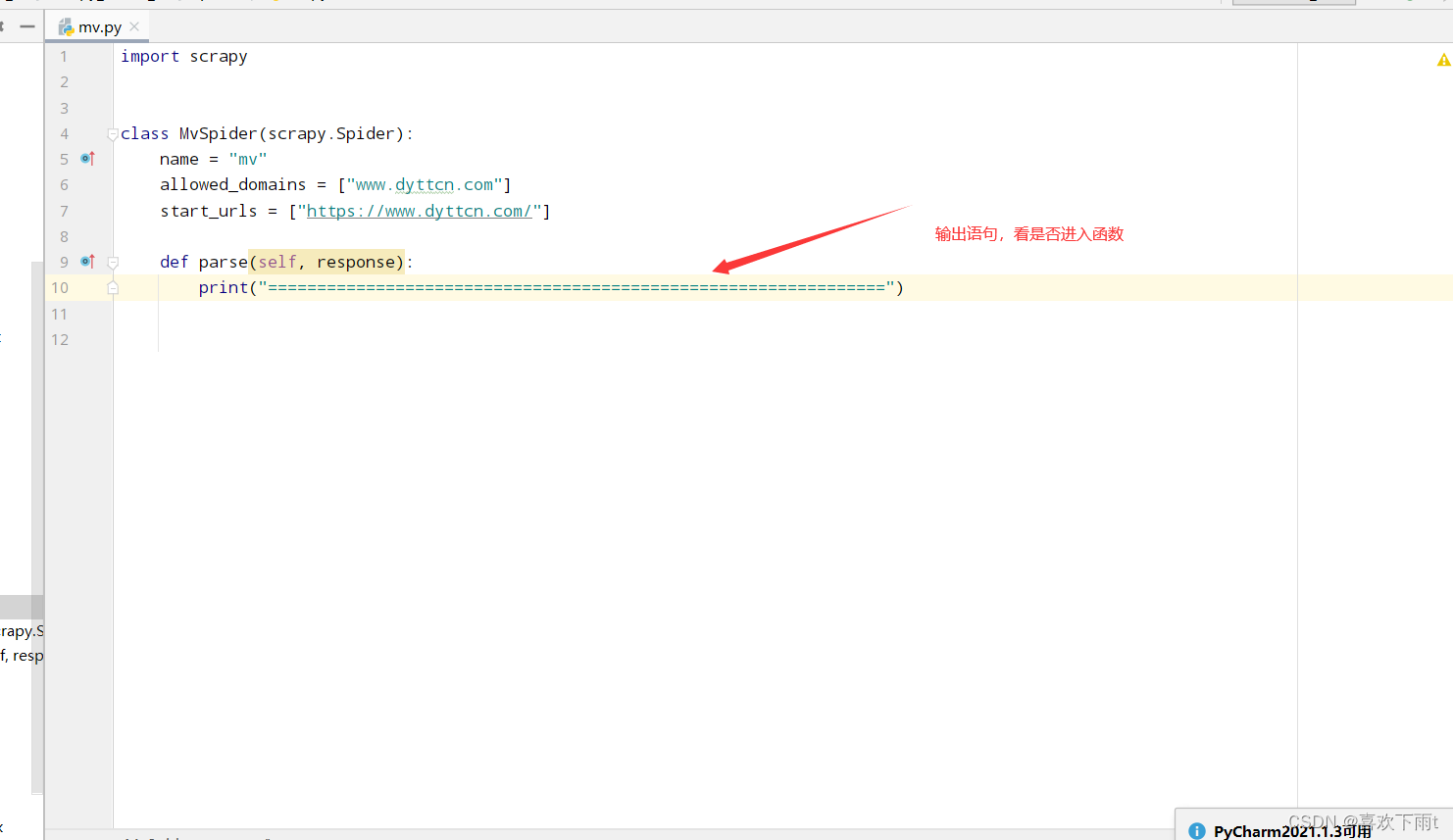
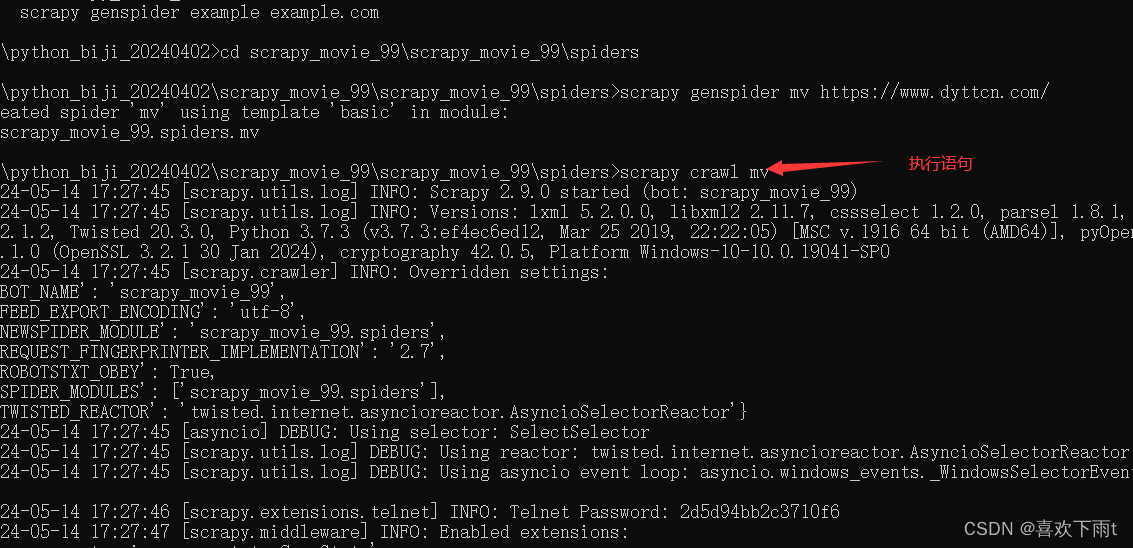
(3.2) 检查结果
scrapy crawl mv
(4)函数编写和需求分析
- 拿去名字
- 拿去图片
(4.1)在items中定义数据类型
(4.2)分析网站xpath结构
mv.py中编写函数:
(4.2.1)拿到第一页的名字和第二页要请求访问的网址
(4.2.2)完整第二页的网址和请求函数编写
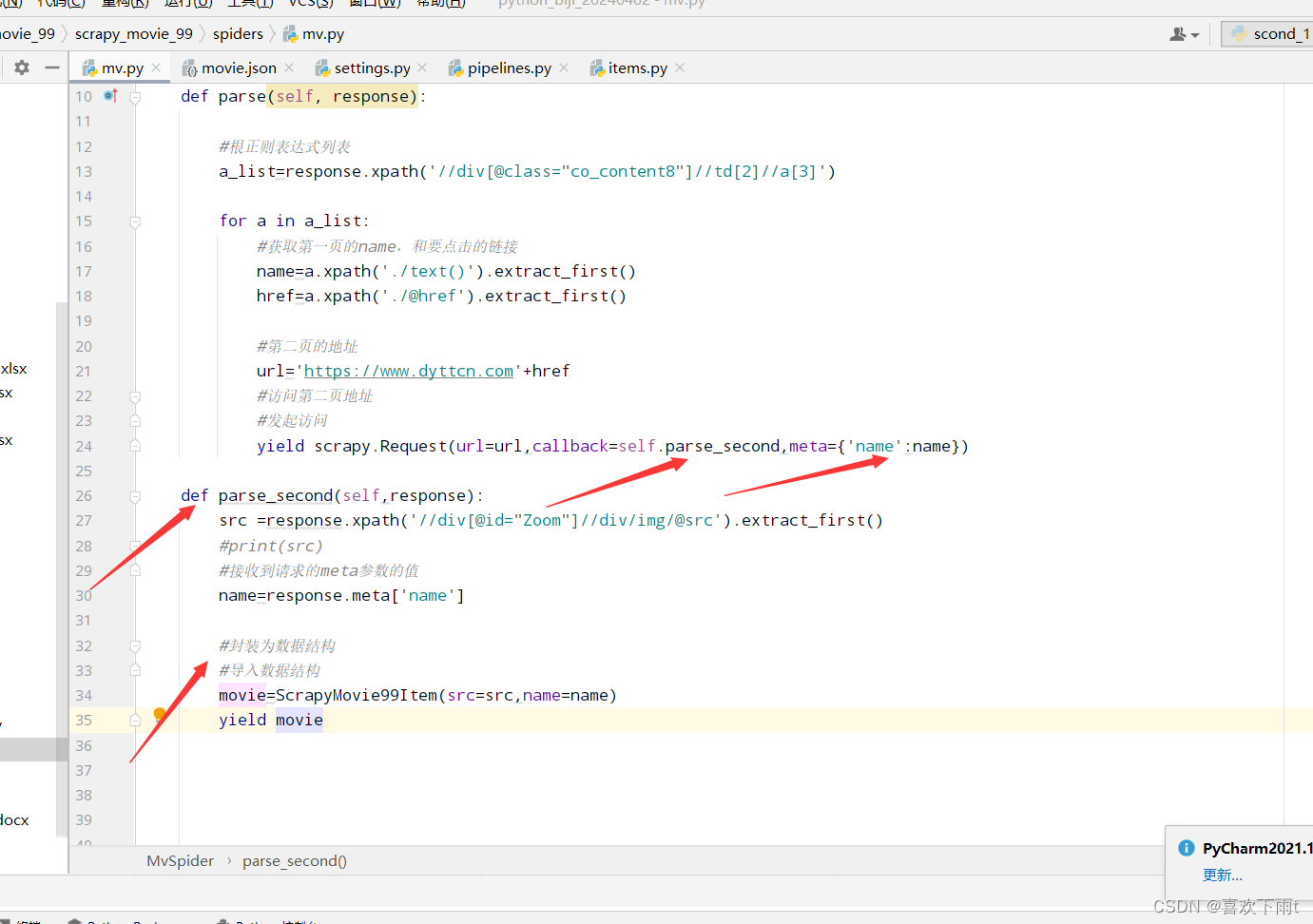
(4.2.3)完整代码:
import scrapy
from scrapy_movie_99.items import ScrapyMovie99Item
class MvSpider(scrapy.Spider):
name = "mv"
allowed_domains = ["www.dyttcn.com"]
# start_urls = ["https://www.dyttcn.com/"]
start_urls = ["https://www.dyttcn.com/xijupian/list_4_1.html"]
def parse(self, response):
#根正则表达式列表
a_list=response.xpath('//div[@class="co_content8"]//td[2]//a[3]')
for a in a_list:
#获取第一页的name,和要点击的链接
name=a.xpath('./text()').extract_first()
href=a.xpath('./@href').extract_first()
#第二页的地址
url='https://www.dyttcn.com'+href
#访问第二页地址
#发起访问
yield scrapy.Request(url=url,callback=self.parse_second,meta={'name':name})
def parse_second(self,response):
src =response.xpath('//div[@id="Zoom"]//div/img/@src').extract_first()
#print(src)
#接收到请求的meta参数的值
name=response.meta['name']
#封装为数据结构
#导入数据结构
movie=ScrapyMovie99Item(src=src,name=name)
yield movie
(5)开启管道
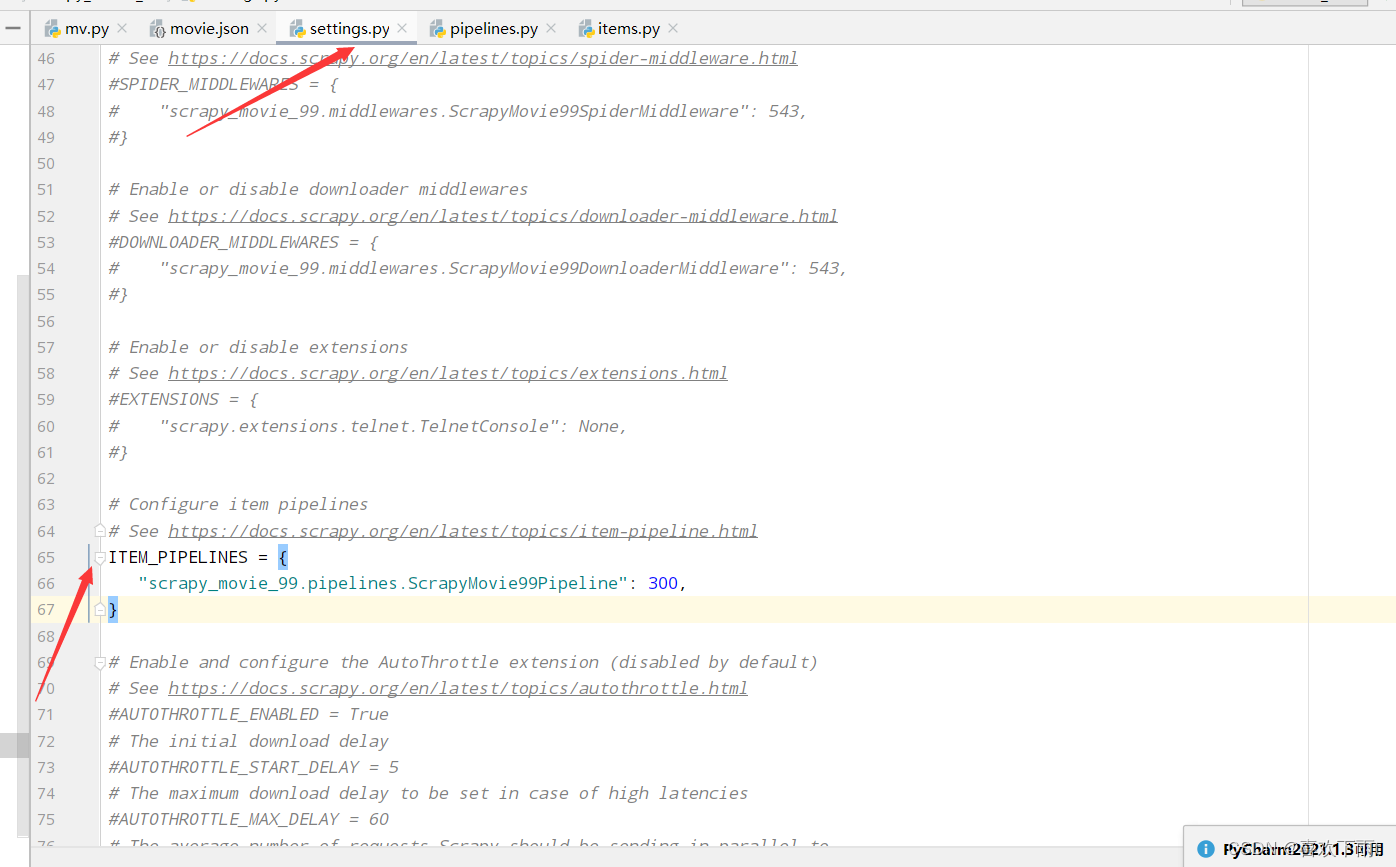
(6)管道封装(写入数据)
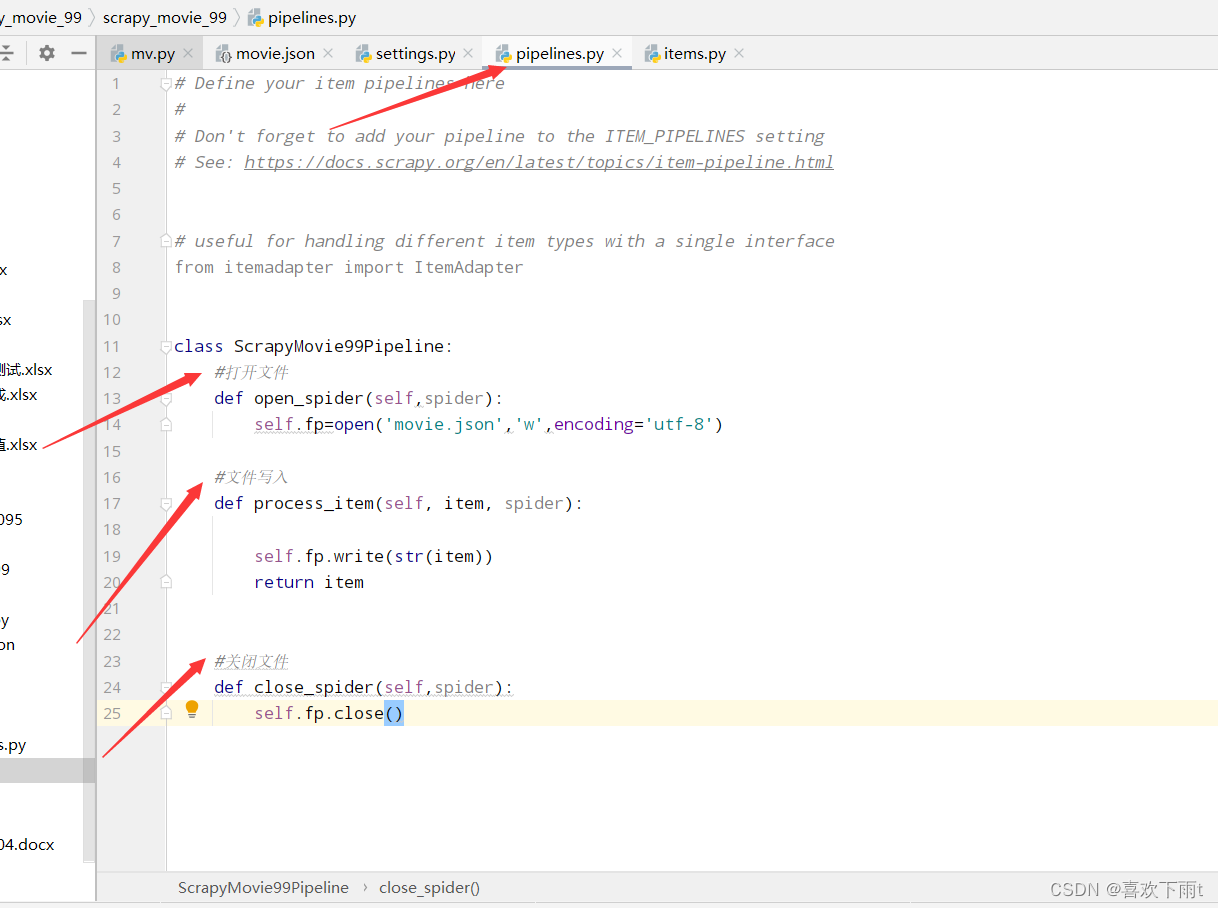
代码如下:
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
class ScrapyMovie99Pipeline:
#打开文件
def open_spider(self,spider):
self.fp=open('movie.json','w',encoding='utf-8')
#文件写入
def process_item(self, item, spider):
self.fp.write(str(item))
return item
#关闭文件
def close_spider(self,spider):
self.fp.close()
(6)运行爬虫
scrapy crawl mv
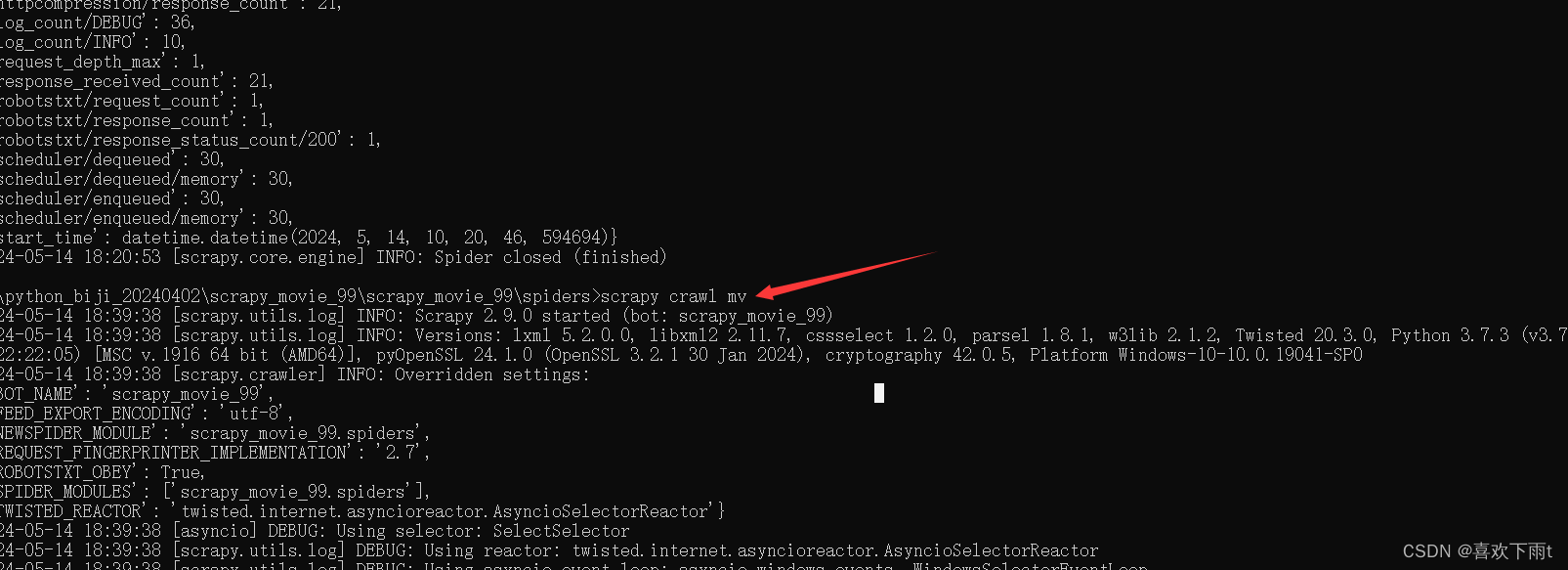
(6.1) 运行结果(ctrl+alt+L----可将数据排版一下)

(7)总结:(该案例的作用)
作用1:解释多页爬取函数编写逻辑
作用2:meta传递数据的使用