SSM(State Space Model)

- SSM是一个针对连续函数的模型,即输入是连续函数,输出也是连续函数。
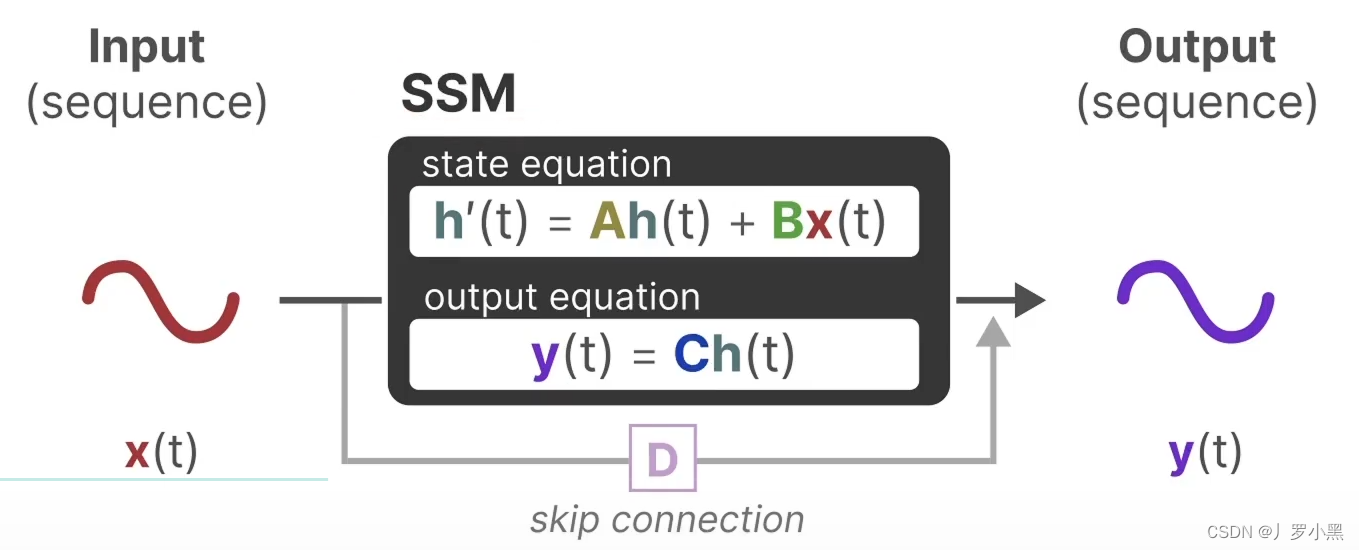
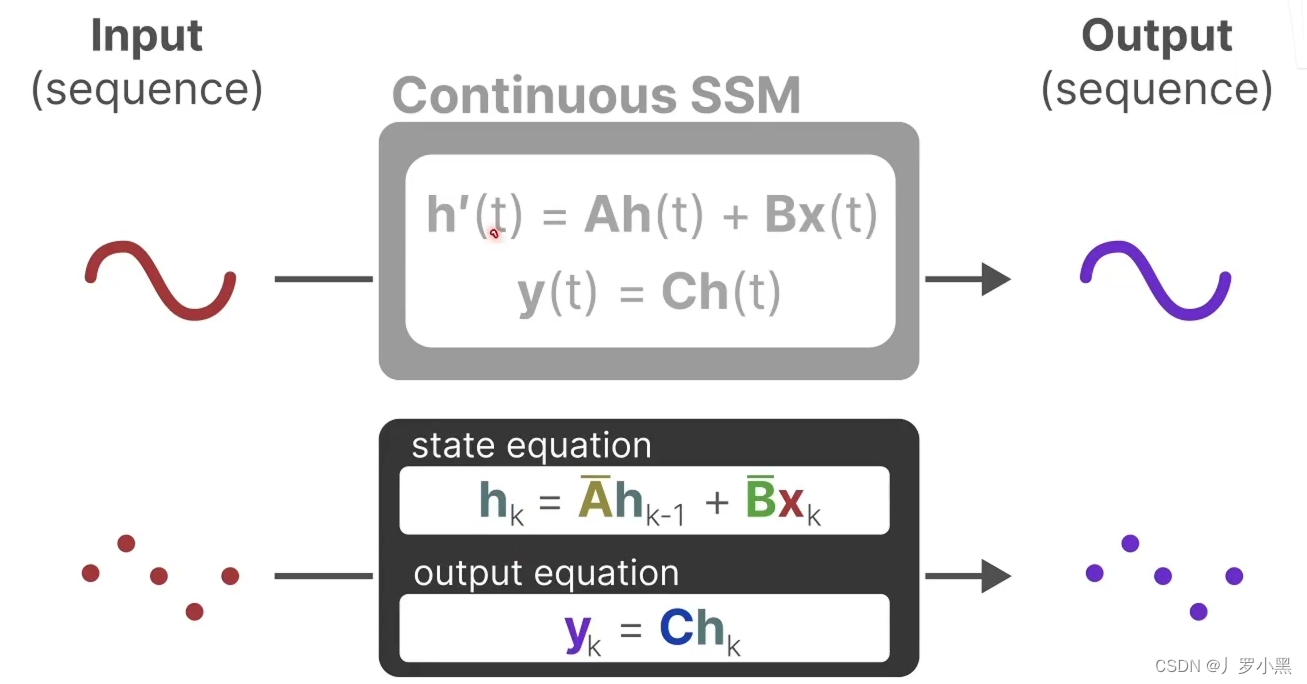
- 上图为状态方程和输出方程,其中h(t)是当前时刻的状态,x(t)是当前时刻的输入,h’(t)是下一个时刻的状态,y(t)是当前时刻的输出。于是上图可以写成下图的形式:
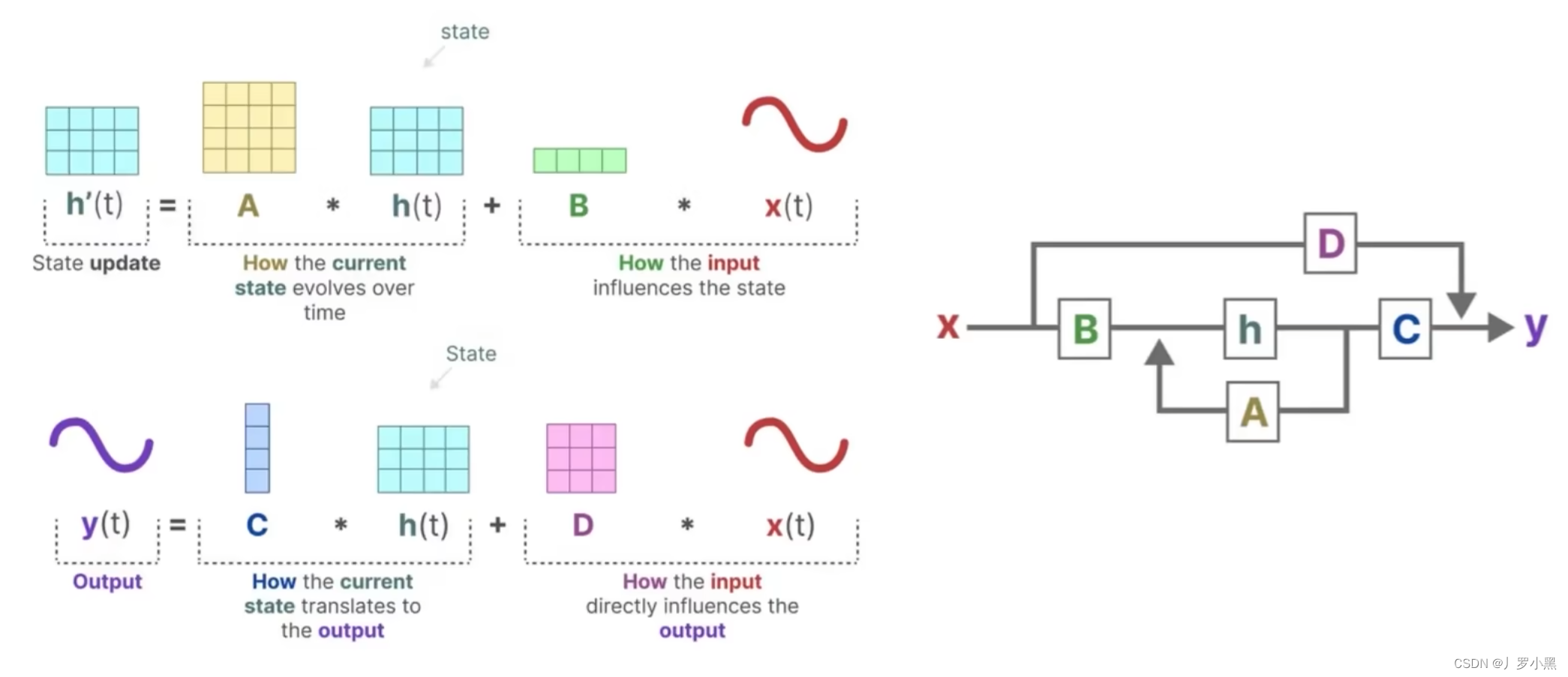
- 下面是详细的流程图,由于D * x(t)为跳跃连接(res连接),所以在论文中一般都省略,灰色部分为通常意义上的SSM模型流程部分
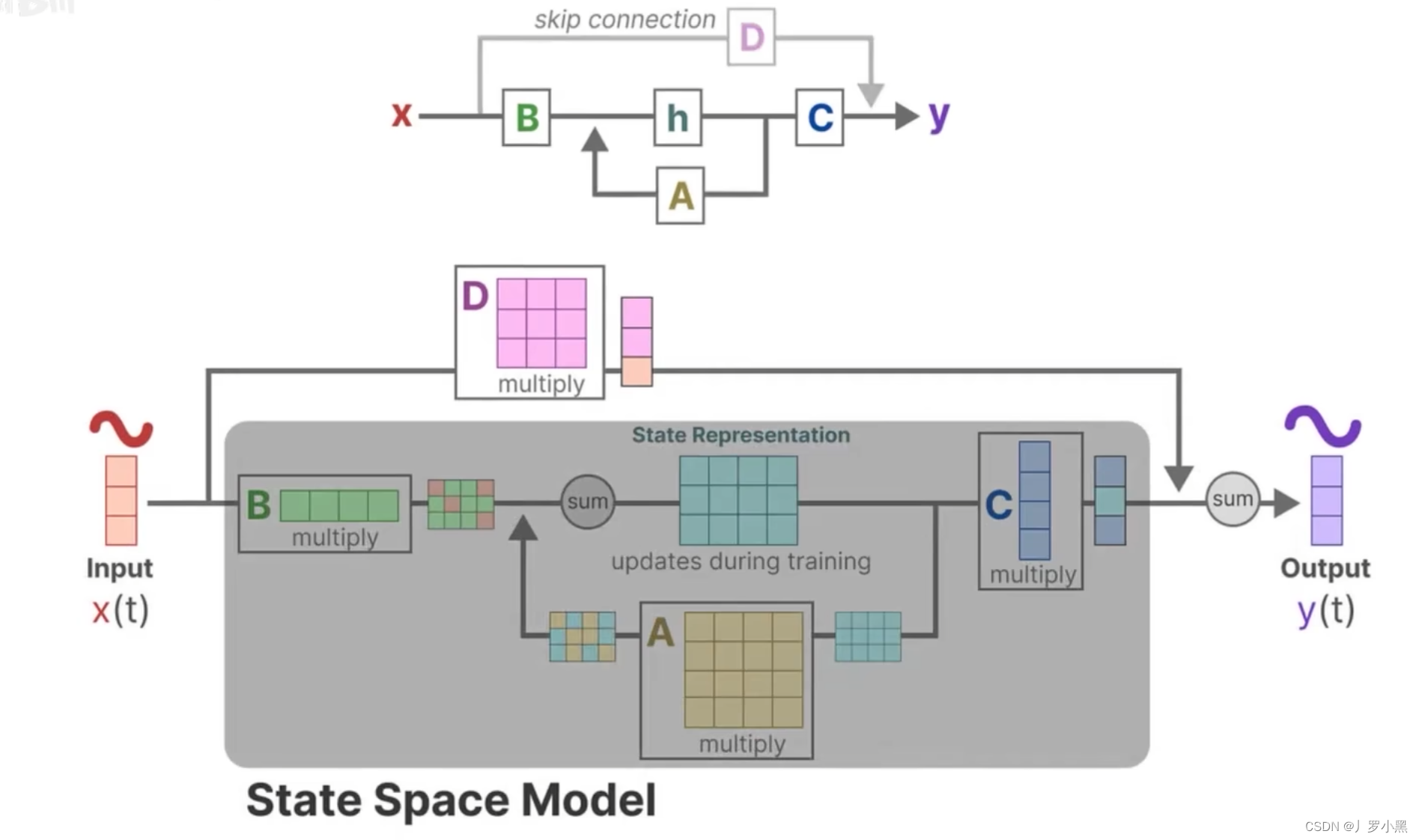
- 综上,SSM的方程可以写成以下的形式:
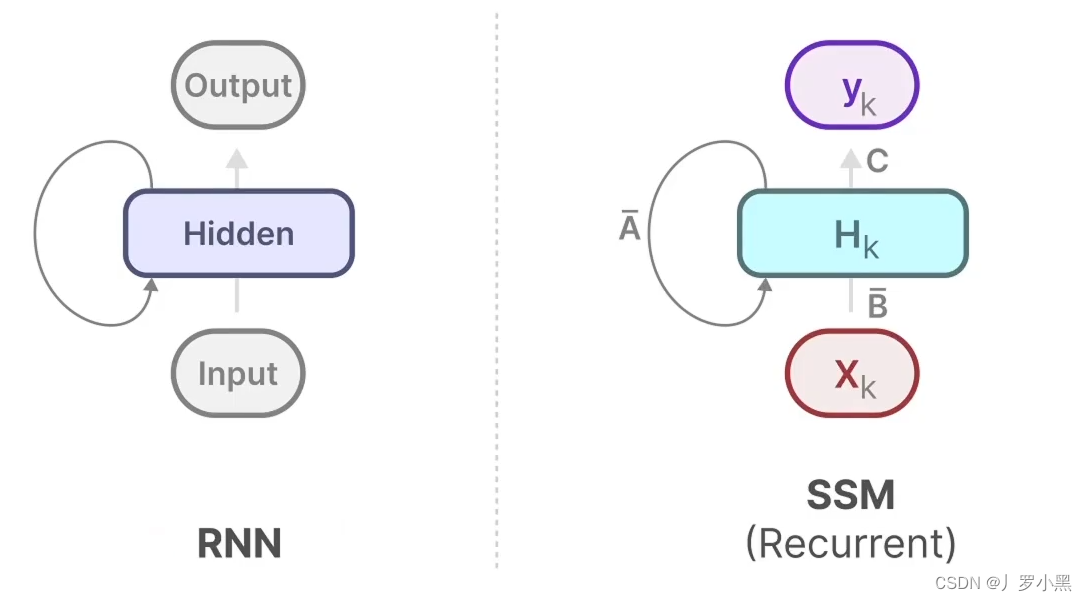
- 由此可以得出SSM跟RNN很类似,一个拥有状态,一个拥有隐藏状态,如下:
S4模型(Structured State Space Model for Sequence Modeling)
- S4模型对SSM的改进有以下三点:
- 采用零阶保持,来进行连续化:由于SSM模型是针对连续函数的,但是在文本、图像等领域,数据都是离散的,所以我们需要将离散的点连续化,才能输入进SSM模型,最后再从连续的输出中采样离散的点来得到真正的输出
- 使用卷积结构表示,从而能够并行训练,加快训练速度
- 使用HIPPO矩阵,解决长距离依赖
- 先看零阶保持,如下:
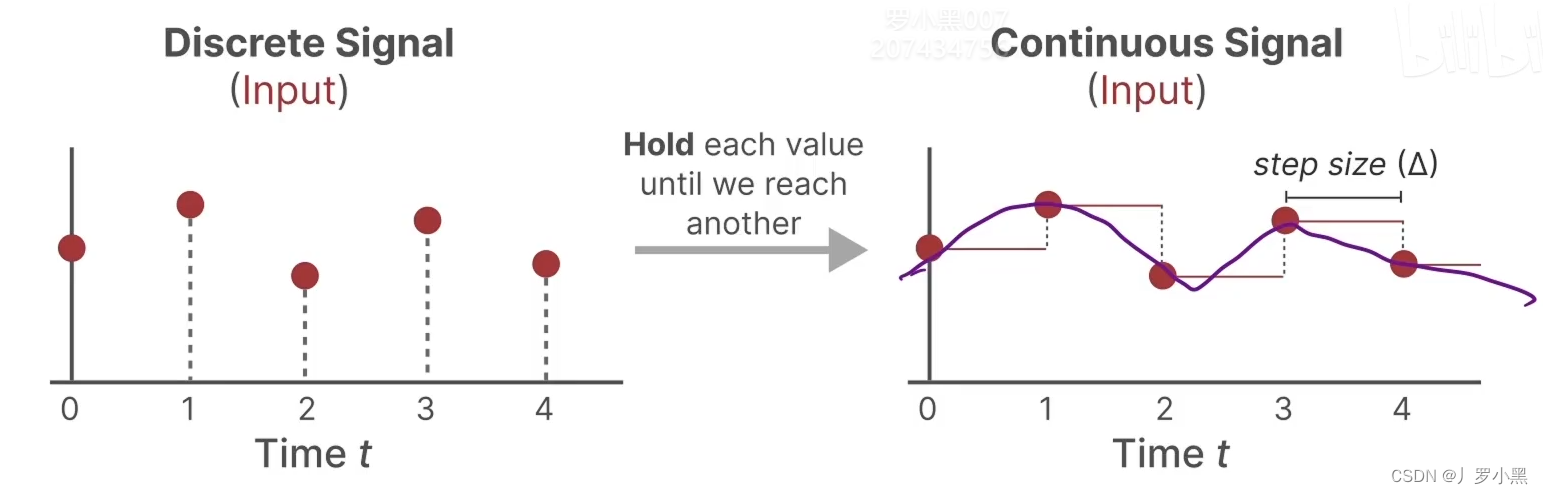
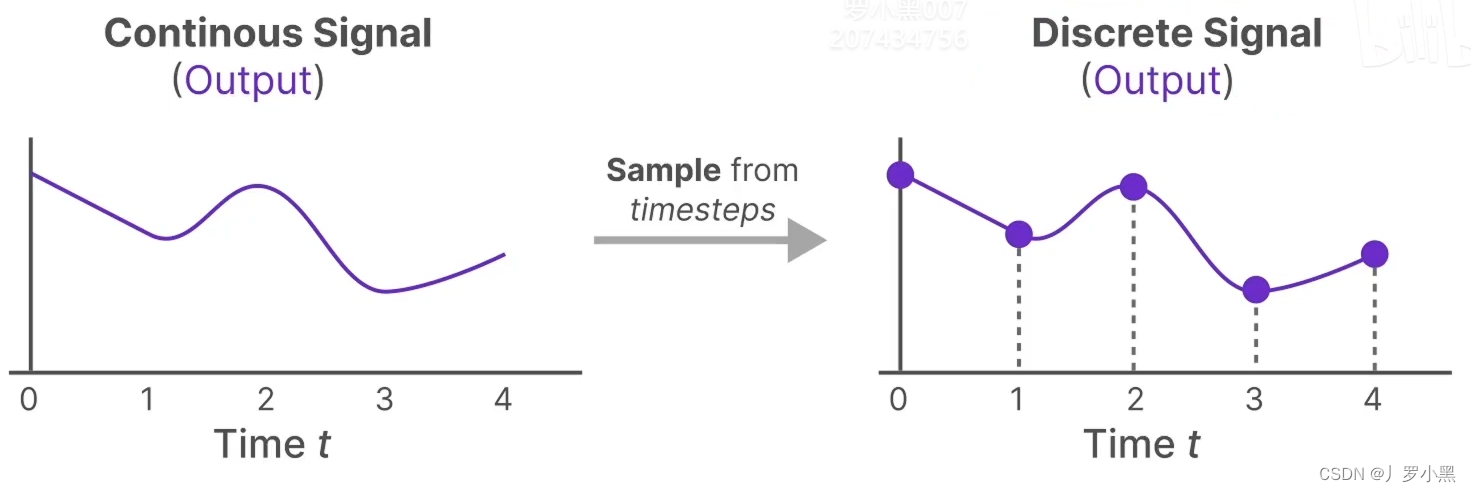
- 对于离散输入,在每个时间步 Δ \Delta Δ中,都保持到一个位置上,从而可以使输入连续
- 对于连续输出,每隔一个时间步 Δ \Delta Δ,都进行一个采样,从而可以得到离散输出
- 由于只有A、B矩阵是反应之前状态、输入是如何影响当前状态的(在连续模型中),而C矩阵是反应状态和输出的映射关系(在连续模型和离散模型中是相同的),所以离散化的重点就是离散化那些描述状态是如何随时间改变的连续模型的矩阵,即A、B矩阵。A、B矩阵是常数。
- 注意:矩阵可以乘函数,但是这个函数得是向量值函数,通常是用来表示系统状态。
- 相对应的离散化A、B矩阵如下:

- 那么状态方程和输出方程就变成如下的形式,为了简化,现在的
h
k
h_k
hk表示当前的状态,
h
(
k
−
1
)
h_(k-1)
h(k−1)表示之前的状态,
y
k
y_k
yk表示当前的输出,
x
k
x_k
xk表示当前的输入
- 再看卷积结构表示,如下:
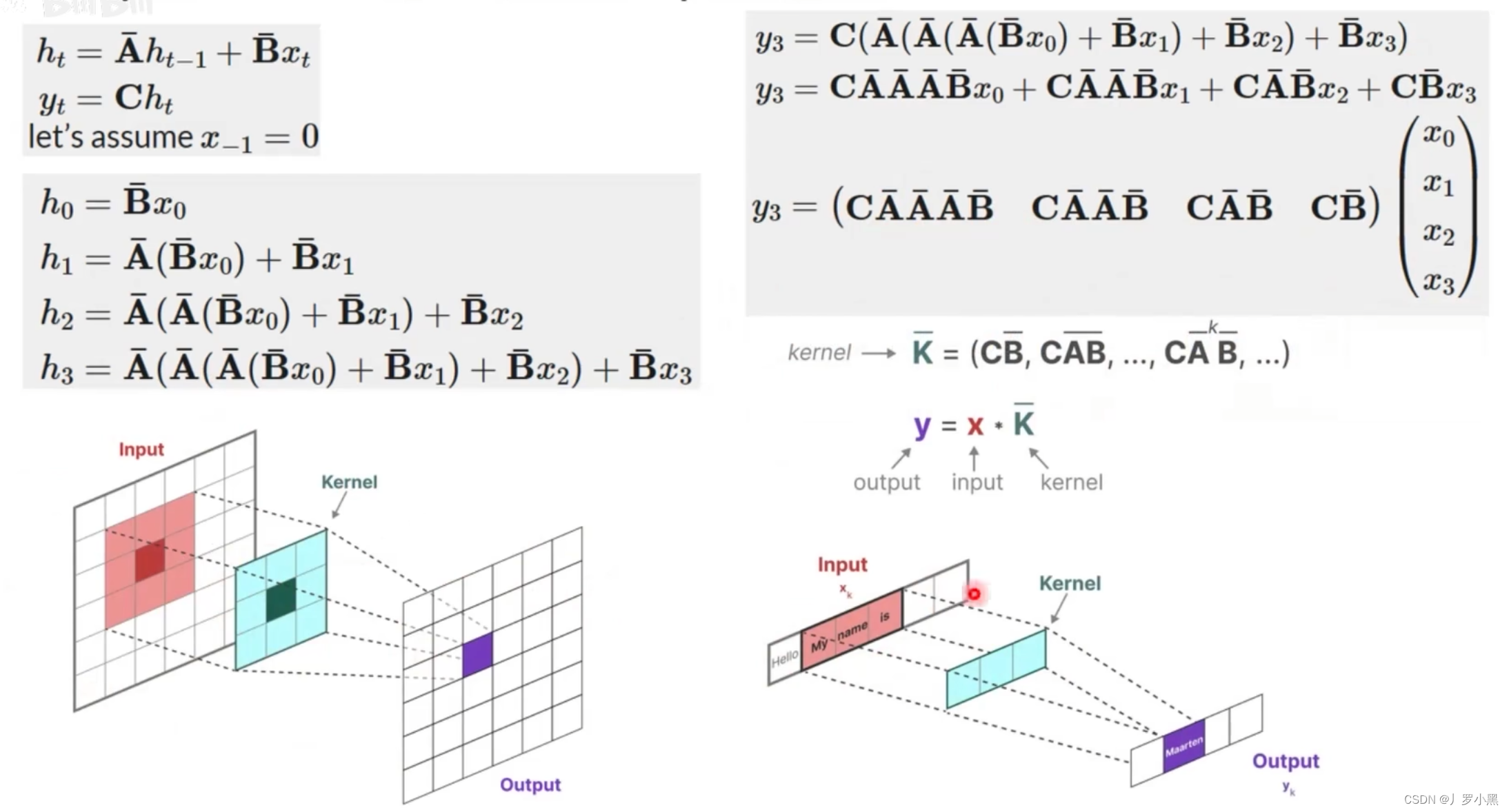
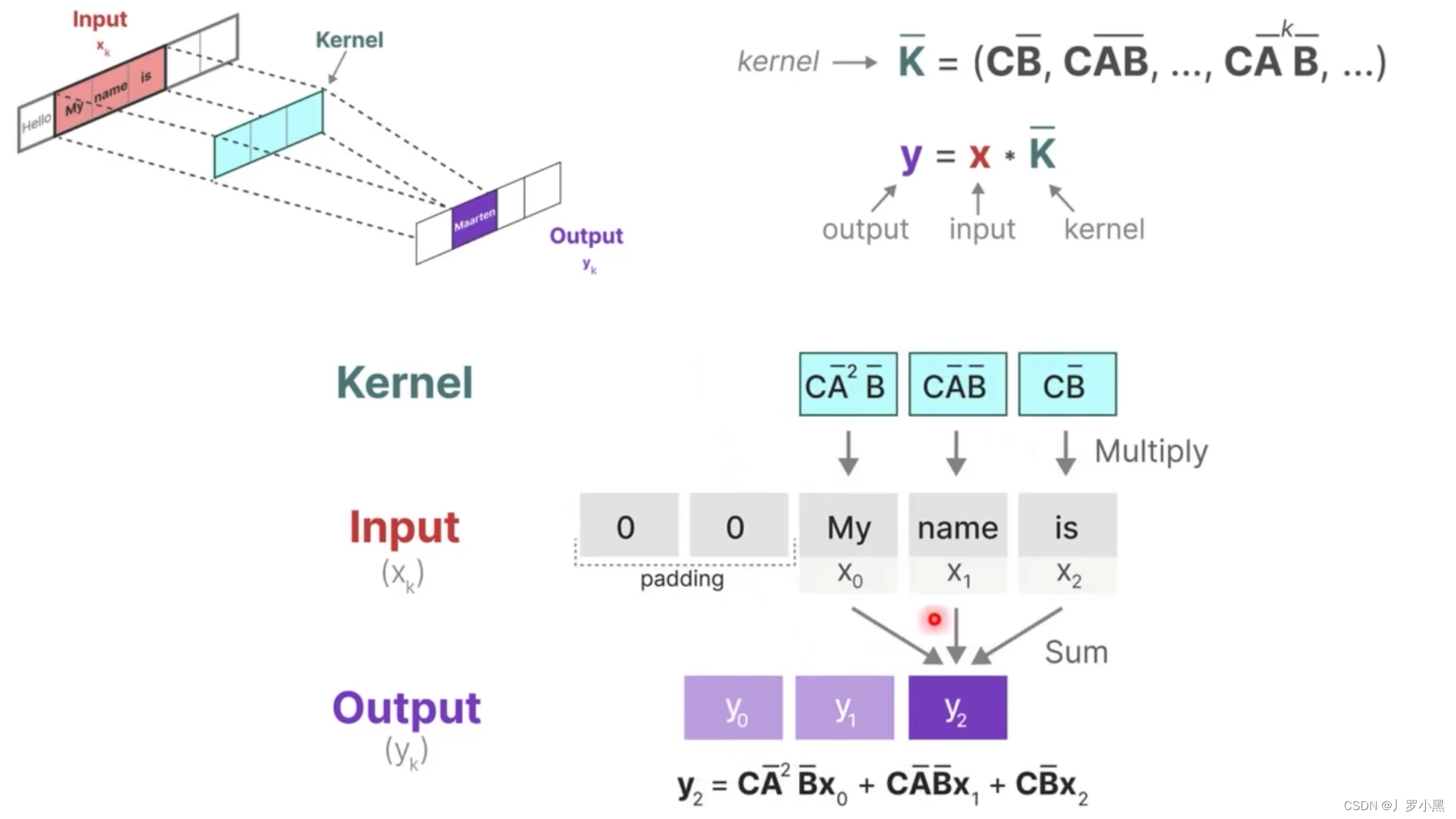
- 如果我们递归的将 h t h_t ht代入,并且展开可以得到一个 h t h_t ht的通用表达式,将这个表达式代回 y t y_t yt可以得到 y t y_t yt的通用表达式,而 y t y_t yt的表达式可以看作两个矩阵相乘,其中一个矩阵为输入矩阵(移动矩阵),另一个矩阵为固定矩阵(由于A、B、C矩阵是固定的,所以 K ‾ \overline{K} K也为固定矩阵),这个形式非常类似CNN中的卷积操作(但是由于mamba是处理文本的,所以只需要一维矩阵),而卷积可以并行,所以它也可以并行执行
- 注意:这里的输入矩阵并不是整个输入,而是对应于卷积上跟卷积核相乘的那个输入矩阵
- 由于我们之前说到SSM跟RNN很类似,于是S4还有一种循环表示形式,使用离散化的A、B矩阵后,如下:
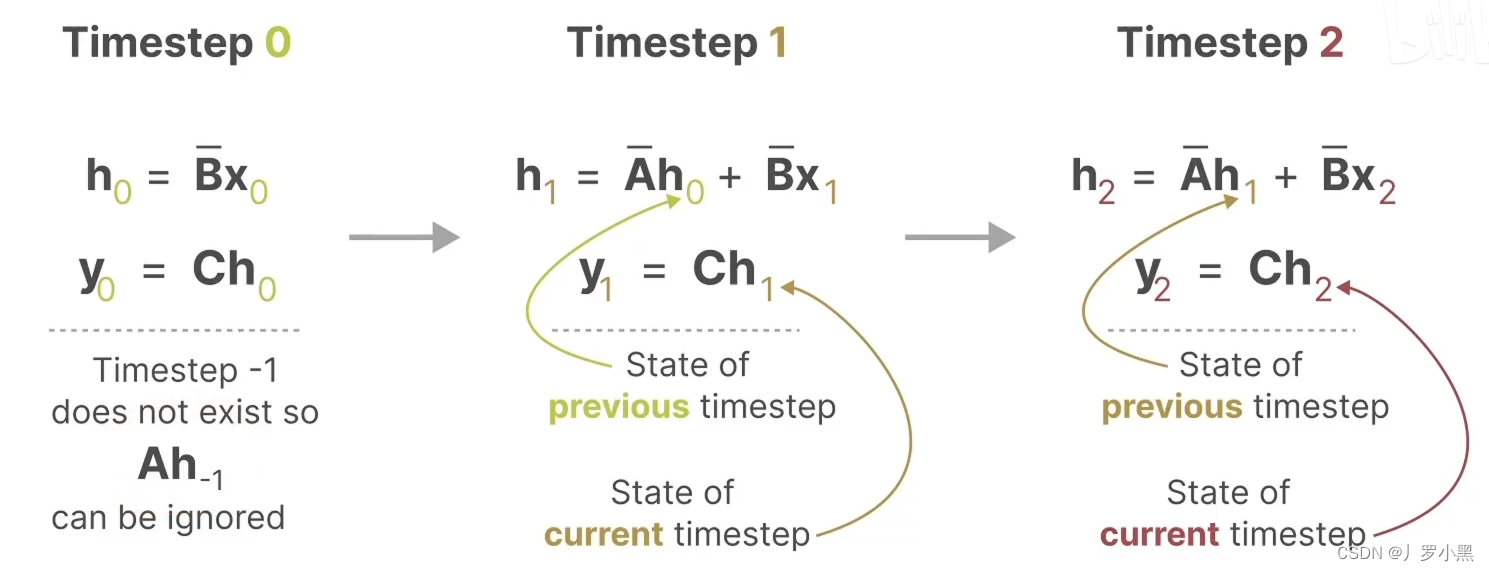
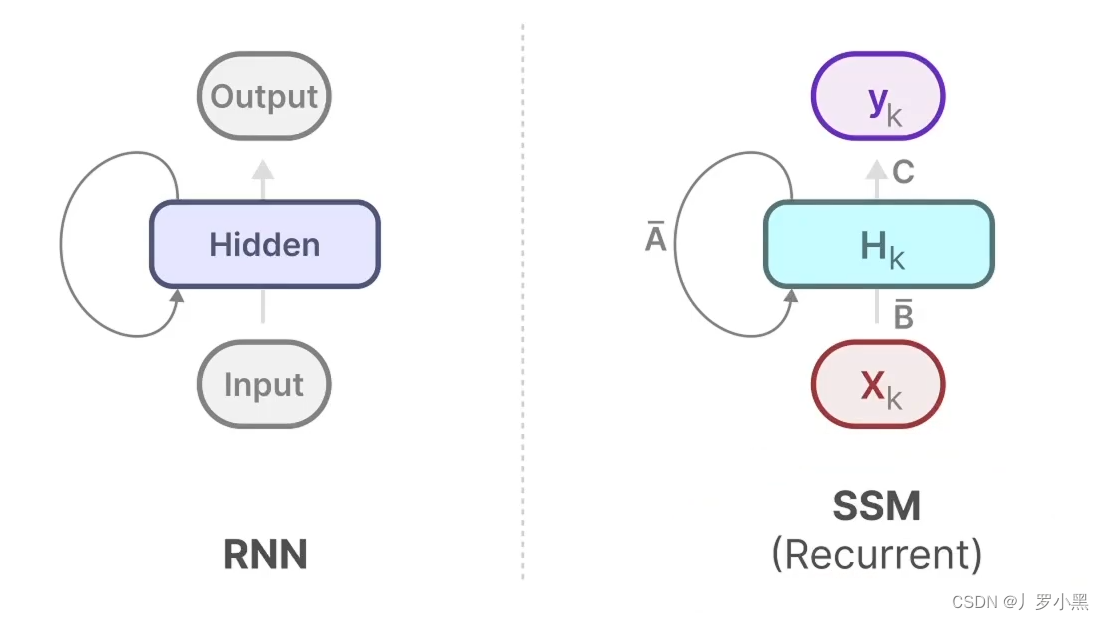
- 综上:S4模型有两种表示形式:循环表示类似RNN、卷积表示类似CNN。
- 那么我们可以在训练时使用CNN来进行并行计算,加快训练。在推理时使用RNN来直接生成预测结果,加快推理。
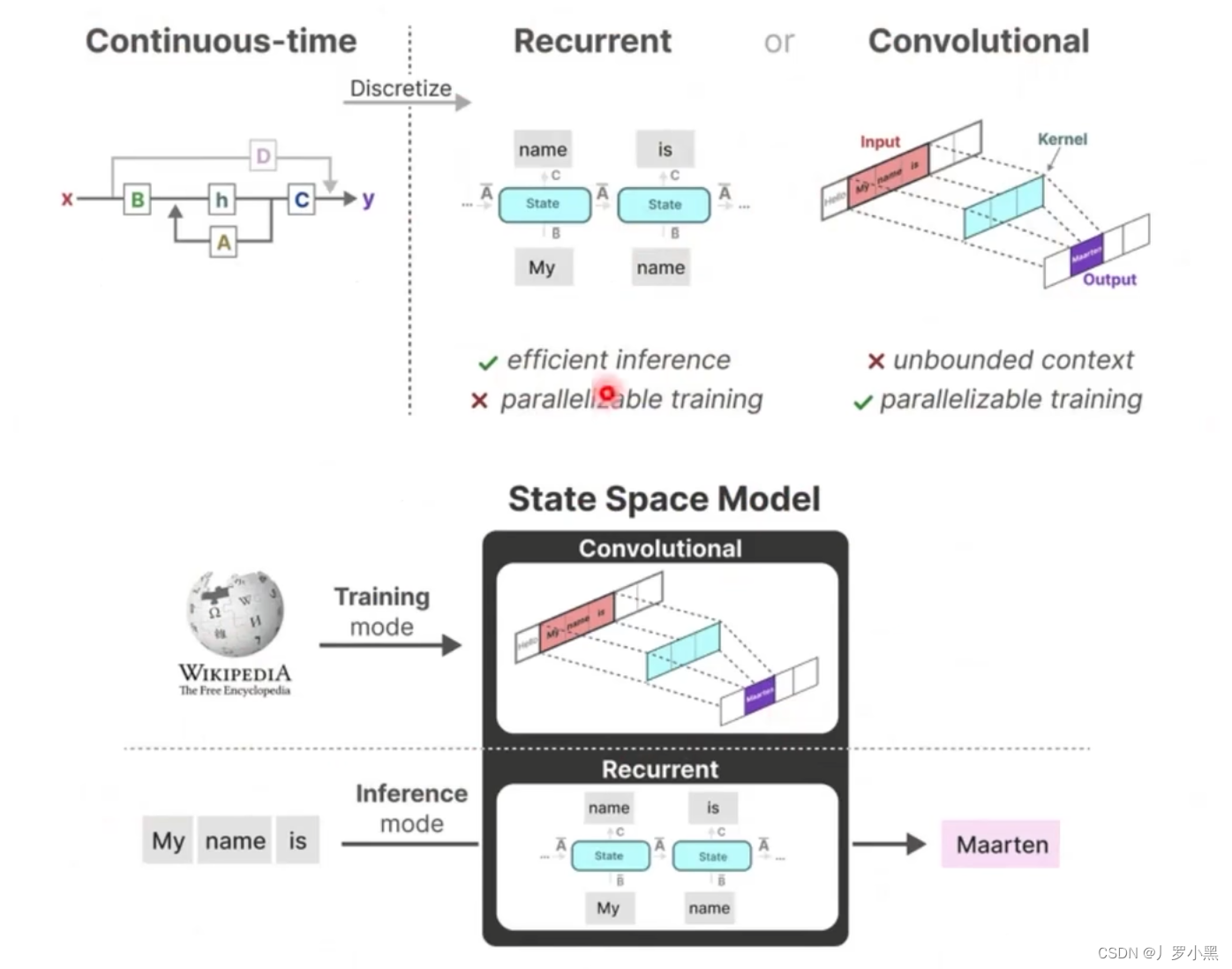
- 最后,我们看HIPPO矩阵,如下:
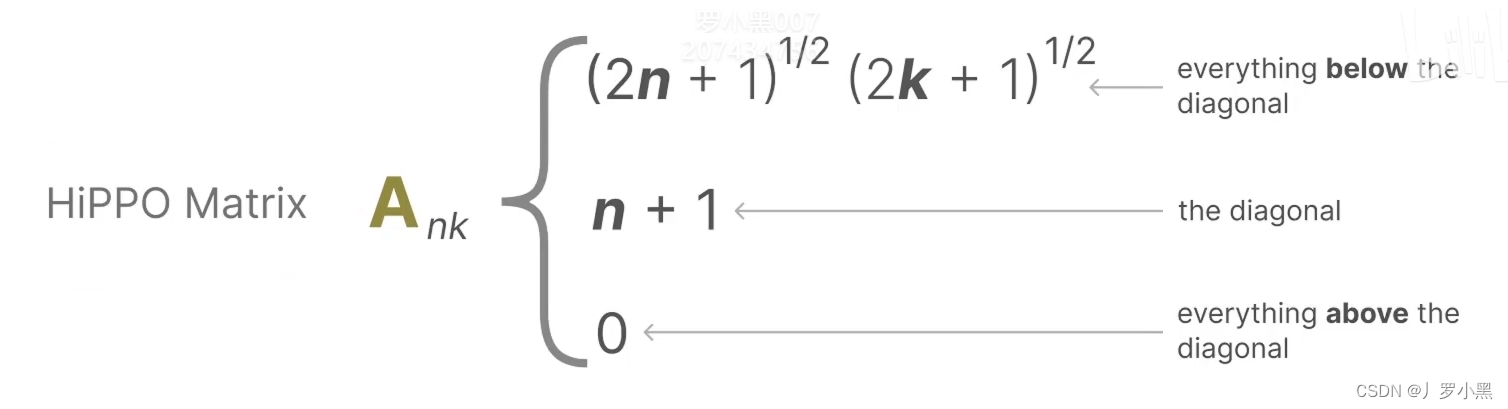
- 由于HIPPO矩阵也是一个二维矩阵,那么相比Transformer的注意力矩阵,并没有减少运算量,那么S4模型使用了低秩分解来表示HIPPO矩阵,从而减少运算量,如下:
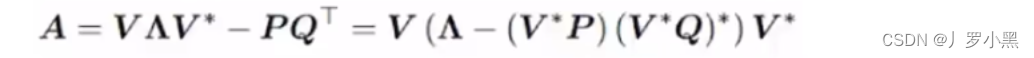
- 由于A矩阵是直接与状态相乘,所以使用HIPPO矩阵来替换掉之前SSM模型中的随机初始化的矩阵
A
‾
\overline{A}
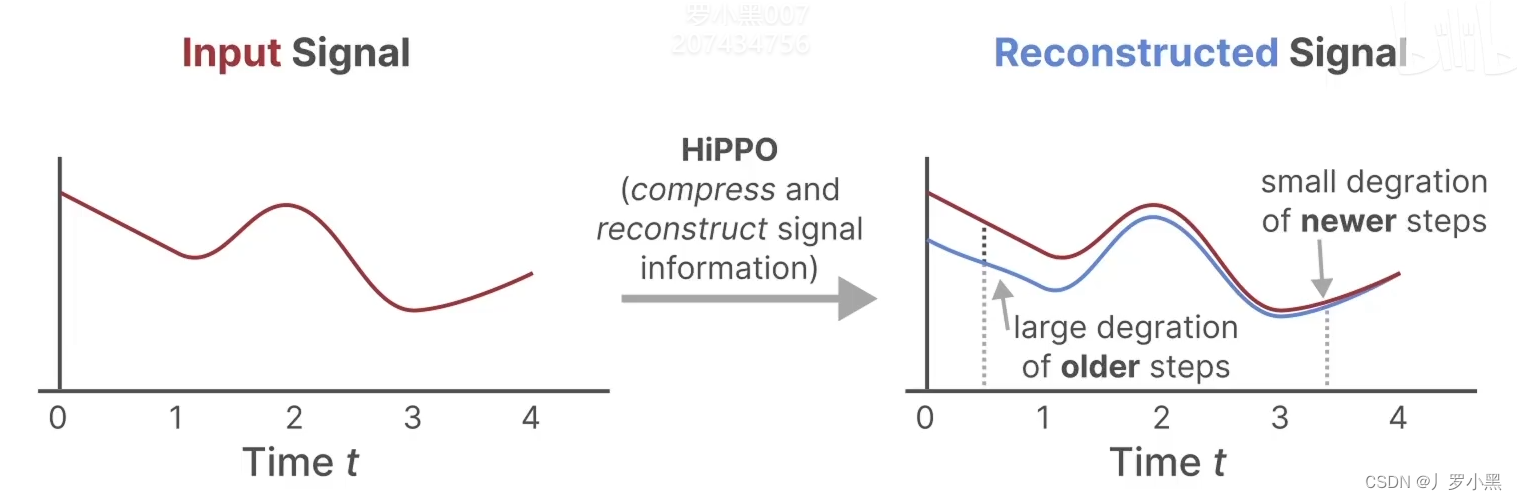
A。因为HIPPO矩阵能够很好的使用最近的token,并逐渐衰减较旧的token,如下:
Mamba(S6)
- Mamba模型对于S4模型的改进有以下三点:
1.