【题目描述】
给出一种物质的分子式(不带括号),求分子量。本题中的分子式只包含4种原子,分别为C, H, O, N,原子量分别为12.01, 1.008, 16.00, 14.01(单位:g/mol)。例如,C6H5OH的分子量为6*12.01 + 6*1.008 + 1*16.00=94.108g/mol。
输入第一行表示有T个分子式,后续是T行分子式。字符串的长度为1~79,元素后面的数字范围为2~99。
【样例输入】
4
C
C6H5OH
NH2CH2COOH
C12H22O11
【样例输出】
12.010
94.108
75.070
342.296
【题目来源】
刘汝佳《算法竞赛入门经典 第2版》习题3-2 分子量(Molar Mass, ACM/ICPC Seoul 2007, UVa1586)
【解析】
本题本质上是一个字符计数问题,只不过每种字符的数量是由其后的数字给定的(数量为1时省略)。
一、老金的算法:用switch语句,每遍历1个字符计算1次
因为字符串只有4个字母,其他都是数字,因此老金考虑可以用swich语句,只需要分5种情况分别处理即可。
思路如下:
①设置两个变量:每个原子的分子量weight,每个原子的原子个数n。
②每遍历一个字符,计算一次分子量:wight*n。
代码如下:
#include<stdio.h>
#include<string.h>
char s[85];
int main(){
int T;
scanf("%d", &T);
while(T--){
scanf("%s", s);
int len=strlen(s), n=1;
double weight, sum=0;
for(int i=0; i<len; i++){
switch(s[i]){
case 'C':
weight=12.01;
break;
case 'H':
weight=1.008;
break;
case 'O':
weight=16.00;
break;
case 'N':
weight=14.01;
break;
//字符为数字的情况
default:
n=s[i]-49;
//通过ASCII值判断下个字符是否为数字
if(s[i+1]>=48 && s[i+1]<=57){
n=10*(s[i]-48)+(s[i+1]-48)-1;
i++;
}
}
sum += weight*n;
n=1;
}
printf("%.3f\n", sum);
}
return 0;
}代码说明:
1.字母和数字的区分。根据题意,字符串只有4个字母,其他都是数字。这样就可以通过case来区分4个字母,最后用default处理数字。这样做的好处是不用另外写代码去判断每个字符是字母还是数字了。当然,如果不限制只有4个字母,就要写上N个case,显然再用此语句就有点不合适了。
2.算法的3种情形
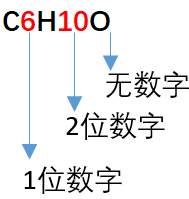
①字母后没数字。方法是设n的默认值为1,这样如果字母后面没有数字,每次计算的结果自然就是正确的分子量。
②字母后有1位数字。因为前面在遍历字母时已经计算了一次分子量,当遍历的数字是1位数字时,需要将个数减1。
③字母后有2位数字。比如C12,可以先将字符转化为对应的数字(字符的ASCII码值-48),然后用1*10+2算出这个两位数字的大小,最后再将1。
那怎么判断数字是两位数呢?也很简单,就是一旦遍历到数字时,就再判断下一个字符是否也是数字。
一旦判断出是两位数,那么遍历到第2位数字时再计算分子量就会出错了,所以要跳过第二位数字。方法很简单,就是加一行i++即可。
3.多位数字情况处理:字符转数
如果不限制数字的位数呢?实质上这是一个多位数字字符转数的问题:
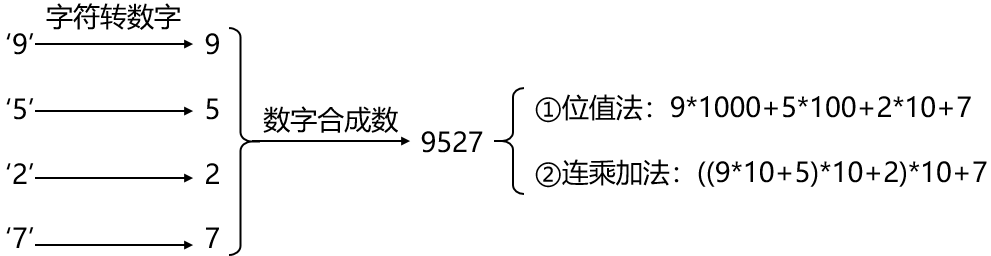
(1)位值法
此算法需要先用一个循环判断数字是几位数(本题转化为找出最后一位数字的下标),再算出这个数字的大小。
只要将default下的代码替换成如下代码即可:
int j, mod;
j=i+1;
mod=1;
n=0;
//求出最后一位数字在数组中的下标
while(s[j]>=48 && s[j]<=57) j++; //原while(s[++j]>=48 && s[++j]<=57);
//计算数字n的大小
for(int k=j-1; k>=i; k--){
n += (s[k]-48)*mod;
mod *= 10;
}
n -= 1;
i = j-1; //更新i的值为第后1位数字的下标但是如果直接替换,编译时报错:
error: a label can only be part of a statement and a declaration is not a statement
这说明在case和default标签下,只能存在语句,不能有变量声明。因此,第一行的变量声明需要放在swith语句之前。
最好是将代码写成函数:int sntoi(char s , int *i),表示返回从字符串s的第i位开始找到的第一个数字。函数代码如下:
int sntoi(char* s, int* i){
int j=*i, mod=1, n=0;
//求出最后一位数字在数组中的下标
while(s[j]>=48 && s[j]<=57) j++;
//计算数字n的大小
for(int k=j-1; k>=*i; k--){
n += (s[k]-48)*mod;
mod *= 10;
}
n -= 1;
*i = j-1; //更新i的值为第后1位数字的下标
return n;
}如此一来default下只需要一行代码:
n=sntoi(s, &i);(2)连乘加法
位值法需要先算出这个数是几位数,因而需要遍历两次。如果用连乘加法,只需要遍历一次,因此用这种方法转换效率更高,应优先使用。代码如下:
int sntoi(char* s, int* i){
int j=*i, n=0;
while(s[j]>=48 && s[j]<=57) {
n = n*10 + s[j] - 48;
j++;
}
n -= 1;
*i = j-1; //更新i的值为第后1位数字的下标
return n;
}二、配套书算法:从遇到的第2个字母开始,每遇到一个新字母结算上一个字母的分子量。
分子式中每个原子的分子量=原子量×原子个数。
显然,问题的关键在于确定原子个数,这个值什么时候能确定呢?就是数字结束时,或者说是遇到下一个字母时。但是因为当只有一个原子时字母后面没有数字,所以只能是遇到下一个字母时结算上一个字母的分子量。
配套书即采用这种算法,代码如下:
#include<stdio.h>
#include<string.h>
#include<ctype.h>
#include<assert.h>
#define _for(i, start, end) for (int i = start; i < end; i++)
int main(){
int T, cnt, sz;
double W[256], ans;
char buf[256], c, s;
W['C'] = 12.01, W['H'] = 1.008, W['O'] = 16.0, W['N'] = 14.01;
scanf("%d\n", &T);
while(T--){
scanf("%s", buf);
ans = 0;
s = 0; cnt = -1; sz = strlen(buf);
_for(i, 0, sz){
char c = buf[i];
if(isupper(c)){
if(i) {
if(cnt == -1) cnt = 1;
ans += W[s] * cnt;
}
s = c;
cnt = -1;
} else {
assert(isdigit(c));
if(cnt == -1) cnt = 0;
cnt = cnt*10 + c - '0';
}
}
if(cnt == -1) cnt = 1;
ans += W[s] * cnt;
printf("%.3lf\n", ans);
}
return 0;
}代码说明:
1.一个变量代表两种含义。代码中的变量n有两种意义:
①标志变量。当遍历到字母时,n=-1。这本质上起得是标志变量的作用。这个标志变量的作用有两个:
a. 结算时,如果n=-1,说明其前一位是个字母,据此将原子个数置为1。
b. 计数时,如果n=-1,说明其前一位是个字母,此位数字是第一个数字,据此将n的初始值置为0,以便后续使用“连乘加法”计数。
②原子个数。当遇到数字开始计数时,n又变为计数的数字。
虽然用一个变量实现了两种功能,很是牛皮Plus。但这种写法降低了代码可读性,老金认为得不偿失。
2.语句宏替换。代码中另有一处高大上的用法,就是使用宏将for语句进行了简洁替换:
#define _for(i, start, end) for (int i = start; i < end; i++)
这样如果代码中有多个for循环,这种简洁的写法就能减少代码量。
3.查找表的应用。代码中再次用数组W[256]实现了查找表,这样可以通过将字母设为数组的下标,元素值设为原子量的值,从而快速获取字母对应的原子量。
4.字符类型判断函数。函数isupper()判断字符是否为大写字母,isdigit()判断字符是否为数字,它们都定义在<ctype.h>头文件中。字符类型判断函数的用法详见老金之前的文章: 字符类型判断库函数合集-CSDN博客
5.assert宏。assert并不是函数,而是一个宏,定义在 <assert.h> 头文件中。它用于在调试期间捕捉不应该发生的错误情况,比如空指针、越界访问等。
如果指定的条件不满足(即条件为假),assert 会打印一条错误消息并终止程序执行。
三、配套书代码优化:取消标志变量
前面说了,配套书的代码存在一个变量两种用途的问题。如果想增加代码的可读性,另设一个标志变量是一个可行方法。老金这里提出一个不用标志变量的方法。
优化思路:
计数无非分两种情况:无数字、有数字。无数字时代表只有一个原子,因此可以设原子数n的默认值为1,当有数字时,计算数字并更新n。优化后的代码如下:
#include<stdio.h>
#include<string.h>
#include<ctype.h>
#include<assert.h>
#define _for(i, start, end) for (int i = start; i < end; i++)
int main(){
int T, n, len;
double W[256], ans;
char buf[256], c, s; //c是当前字母,s是上一个字母
W['C'] = 12.01, W['H'] = 1.008, W['O'] = 16.0, W['N'] = 14.01;
scanf("%d\n", &T);
while(T--){
scanf("%s", buf);
ans = 0;
s = 0; n = 1; len = strlen(buf);
_for(i, 0, len){
char c = buf[i];
if(isupper(c)){
//如果不是第一个字母,结算上一个字母的分子量
if(i) {
ans += W[s] * n;
n = 1; //结算完成,将数字修改为默认值1
}
s = c; //将当前字母赋给s,以备结算
} else {
//遇到数字,修改n的值
assert(isdigit(c));
if(isupper(buf[i-1])) n = 0;//首次遇到数字,n=0
n = n*10 + c - '0';
}
}
//最后一个字母单独结算
ans += W[s] * n;
printf("%.3lf\n", ans);
}
return 0;
}其实完全说取消了标志变量有些牵强,因为下面这行代码本质上还是标志变量的用法,只不过用数组的形式代替了而已。
if(isupper(buf[i-1])) n = 0;//首次遇到数字,n=0优化后的代码不但没了标志变量,还减少了两条if语句,而且代码也更容易理解了。
四、我家娃娃的代码:很难懂
最后附上我家娃写的C++代码,老金看了很久,还是没太弄明白,不过这个代码运行结果是正确的。
#include <iostream>
#include <cstring>
using namespace std;
double a[95];
int f(int x){
int g=1;
for(int i=1;i<=x;i++){
g*=10;
}
return g;
}
int main (){
a[67]=12.01;
a[72]=1.008;
a[79]=16.00;
a[78]=14.01;
int T;
scanf("%d", &T);
while(T--){
int cnt=0,i2,cnt2=0;
double sum=0;
string n;
cin>>n;
for(int i=0;i<n.size();i++){
if(n[i]>='A'&&n[i]<='Z'){
if(i==n.size()-1){
sum+=a[n[i]];
break;
}
i++;
if(n[i]>='0'&&n[i]<='9'){
while(n[i]>='0'&&n[i]<='9'){
cnt++;
i++;
}
i2=i-cnt;
i-=cnt;
while(n[i2]>='0'&&n[i2]<='9'){
cnt2+=(n[i2]-48)*f(cnt-(i2-i+1));
i2++;
}
sum+=cnt2*(a[n[i-1]+0]);
cnt=0;
cnt2=0;
}
else{
sum+=a[n[i-1]];
i--;
}
}
}
cout<<sum<<endl;
}
}不得不吐槽一下C++的cout,代码中是没有指定保留几位小数的。实际测试样例数据输出结果正确,但老金随意输入“C3002H9527O21N”输出结果却是46007.2,而正确的结果应该是46007.246。
因为这个问题娃儿和老金反复分析代码也没发现问题,后来老金将最后一条cout语句改用printf输出结果就正确了。真是不知道cout搞的是什么飞机。
当然了,如果用C++的极其考究记忆力的保留小数位数的语法,也是没问题的。
cout<<fixed<<setprecision(3)<<sum<<endl;真不知道这样的写法有多少孩子能记得住!