文章目录
- 矩阵
- 范数
- 卷积
- 激活函数
- 信息熵
矩阵
- 标量:一个标量就是一个单独的数
- 向量:一个向量是一列数。这些数是有序排列的。通过次序中的索引,我们可以确定每个单独的数
- 矩阵:矩阵是一个二维数组,其中的每个元素被两个索引所确定
- 张量:一般地,一个数组中的元素分布在若干维的规则网格中,我们称之为张量。一般在卷积神经网络中应用
矩阵运算的性质:
- 服从分配率
- 服从结合律,不服从交换率
- 向量的点积服从交换率 x T y = y T x x^Ty = y^Tx xTy=yTx
- 矩阵转置的性质 ( A + B ) T = A T + B T , ( A B ) T = B T A T (A + B)^T = A^T + B^T, (AB)^T = B^T A^T (A+B)T=AT+BT,(AB)T=BTAT
范数
∣
∣
x
∣
∣
p
=
(
∑
i
∣
x
i
∣
p
)
1
p
||x||_p = (\sum_i{|x_i|^p})^{\frac{1}{p}}
∣∣x∣∣p=(i∑∣xi∣p)p1
范数(
L
p
L^p
Lp)是将向量映射到非负值的函数。直观上来说,向量x的范数衡量从原点到点x的距离。
范数满足的性质:
- f ( x ) = 0 ⇒ x = 0 f(x) = 0 \Rightarrow x = 0 f(x)=0⇒x=0
- f ( x + y ) ≤ f ( x ) + f ( y ) ( 三角不等式 ) f(x + y) \leq f(x) + f(y) (三角不等式) f(x+y)≤f(x)+f(y)(三角不等式)
- ∀ α ∈ R , f ( α x ) = ∣ α ∣ f ( x ) \forall \alpha \in R, f(\alpha x) = |\alpha| f(x) ∀α∈R,f(αx)=∣α∣f(x)
二范数:
通常情况下,不进行开平方操作,这样可能产生误差,且较为麻烦
计算一个向量的平方范数用简单的方式就是通过点积的方式
x
T
x
x^Tx
xTx
一范数:
通常情况下靠近原点时,平方范数的变化趋势不大,难以区分,而区分是零的元素和非零但值很小的元素是很重要的。在这些情况下,我们转而使用在各个位置斜率相同,同时保持简单的数学形式的范数
L
1
L^1
L1范数
∣
∣
x
∣
∣
1
=
∑
i
∣
x
i
∣
||x||_1 = \sum_i |x_i|
∣∣x∣∣1=∑i∣xi∣
最大范数
L
∞
L^{\infty}
L∞,这个范数表示向量中具有最大幅值的元素的绝对值
∣
∣
x
∣
∣
∞
=
max
i
∣
x
i
∣
||x||_{\infty} = \max \limits_{i}|x^i|
∣∣x∣∣∞=imax∣xi∣
零范数
L
0
L^0
L0, 表示向量中非零元素的个数
例:

卷积
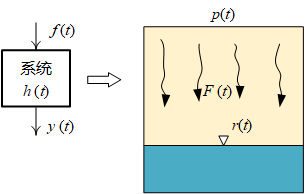
卷积的含义为:系统在 t t t 时刻的输出,不仅与系统在 t t t 时刻的输入有关,还与它在 t t t 时刻之前的输入有关,并且不同时刻的输入,有不同的权重。所以,卷积本质上做的事情是:不同时刻的输入的权重求和。权重是一个关于时间 t t t 的连续函数。
所谓两个函数的卷积,本质上就是现将一个函数翻转,然后进行滑动叠加
(
f
∗
g
)
(
n
)
=
∫
−
∞
∞
f
(
t
)
∗
g
(
n
−
t
)
d
t
(f*g)(n) = \int_{-\infty}^{\infty} f(t) * g(n -t)dt
(f∗g)(n)=∫−∞∞f(t)∗g(n−t)dt
(
f
∗
g
)
(
n
)
=
∑
−
∞
∞
f
(
t
)
∗
g
(
n
−
t
)
d
t
(f*g)(n) = \sum_{-\infty}^{\infty} f(t) * g(n -t)dt
(f∗g)(n)=−∞∑∞f(t)∗g(n−t)dt
先对g函数进行左右翻转,这就是卷积卷的由来,然后再把g函数向右平移n,在这个位置两个函数相乘,然后相加,这个过程就是卷积积的过程
s
(
t
)
=
∫
x
(
a
)
w
(
t
−
a
)
d
a
s(t) = \int x(a) w(t - a) da
s(t)=∫x(a)w(t−a)da
这种运算就叫做卷积。卷积运算通常用星号表示:
s
(
t
)
=
(
x
∗
w
)
(
t
)
s(t) = (x * w) (t)
s(t)=(x∗w)(t)
在卷积网络的术语中,卷积的第一个参数(x)通常叫做输入(input),第二个参数(w)叫做核函数(kernel),输出有时被称作特征映射(feature map)
图像中的卷积
将卷积概念映射到2D图像上:对于2D图像来说,某个位置的输出,不仅与该位置的输入有关,还与此位置周边位置的输入有关,不同位置的输入,具有不同的权重(权重值不宜过大)。由于位置坐标是固定的有限个值,所以权重是一个关于位置的离散函数。
s
(
t
)
=
(
x
∗
w
)
(
t
)
=
∑
a
=
−
∞
∞
x
(
a
)
w
(
t
−
a
)
s(t) = (x*w)(t) = \sum^{\infty}_{a = -\infty} x(a) w(t - a)
s(t)=(x∗w)(t)=a=−∞∑∞x(a)w(t−a)
因为位置输入是二元输入:
图像中的卷积:
S
(
i
,
j
)
=
(
I
∗
K
)
(
i
,
j
)
=
∑
m
∑
n
I
(
m
,
n
)
K
(
i
−
m
,
j
−
n
)
S(i, j) = (I * K ) (i, j) = \sum_m \sum_n I(m, n) K(i - m, j - n)
S(i,j)=(I∗K)(i,j)=m∑n∑I(m,n)K(i−m,j−n)
神经网络是互相关的,因此不进行核函数的翻转:
S
(
i
,
j
)
=
(
I
∗
K
)
(
i
,
j
)
=
∑
m
∑
n
I
(
i
+
m
,
j
+
n
)
K
(
m
,
j
)
S(i, j) = (I * K)(i, j) = \sum_m \sum_n I(i + m, j + n) K (m, j)
S(i,j)=(I∗K)(i,j)=m∑n∑I(i+m,j+n)K(m,j)
激活函数
激活函数是来向神经网络中引入非线性因素的,通过激活函数,神经网络就可以拟合各种曲线
-
sigmoid函数
也称逻辑激活函数,最常用于二分类问题。它有梯度消失问题。在一定epoch数目之后,网络拒绝学习,或非常缓慢学习,因为输入导致输出的变化很小。


-
tanh函数
双曲正切函数 导数:
T
a
n
h
′
(
x
)
=
1
−
T
a
n
h
2
(
x
)
Tanh'(x) = 1 - Tanh^2(x)
Tanh′(x)=1−Tanh2(x)
导数:
T
a
n
h
′
(
x
)
=
1
−
T
a
n
h
2
(
x
)
Tanh'(x) = 1 - Tanh^2(x)
Tanh′(x)=1−Tanh2(x)
-
ReLU函数


- Softmax函数
σ ( x ) j = e x j ∑ k = 1 K e x k , j = 1 , . . . K \sigma(x)_j = \frac{e^{x_j}}{\sum \limits_{k = 1}^{K} e^{x_k}}, j = 1,...K σ(x)j=k=1∑Kexkexj,j=1,...K
该函数的输出等价于类概率分布,输出的和为1。类似于Sigmoid函数,把输出压缩在0和1之间, 所有的概率和为1
信息熵
将热力学中的熵引入信息论,假设有两个不相关的事件X和Y,观察两个事件同时发生时获得的信息量应该等于观察到两个事件各自发生时获得的信息之和:
I
(
x
,
y
)
=
I
(
x
)
+
I
(
y
)
I(x, y) = I(x) + I(y)
I(x,y)=I(x)+I(y)
由于两个事件是独立不相关的,因此P(x, y) = P(x)P(y),定义事件的自信息量为
I
(
x
i
)
=
−
l
o
g
p
(
x
i
)
I(x_i) = - log p(x_i)
I(xi)=−logp(xi)
进一步,对于事件X有n中可能性,每一种可能性都有一个概率p(x_i), 因此就可以计算出每一种可能性的信息量。而熵就是用来表示所有信息量的期望,即:
H
(
X
)
=
−
∑
i
=
1
n
p
(
x
i
)
log
p
(
x
i
)
H(X) = -\sum^n_{i = 1}p(x_i) \log{p(x_i)}
H(X)=−i=1∑np(xi)logp(xi)
因此 H ( x ) H(x) H(x)就被成为随机变量X的熵,它是表示随机变量不确定性的度量,是对所有可能发生的事件产生的信息量的期望
当随机变量的取值个数越多,状态数就越多,信息熵就越大,混乱程度就越大。当随机分布为均匀分布时,熵最大。
熵越少确定性就越强,所以对于我们判断来说,我们希望熵越小越好
将一维随机变量分布推广到多维随机变量分布,则其联合熵(Joint entropy)为
H ( X , Y ) = − ∑ i = 1 n ∑ j = 1 m p ( x i , y j ) log p ( x i , y j ) H(X, Y) = - \sum_{i = 1}^{n} \sum_{j = 1}^m {p(x_i, y_j) \log{p(x_i, y_j)}} H(X,Y)=−i=1∑nj=1∑mp(xi,yj)logp(xi,yj)
条件熵 H ( Y ∣ X ) H(Y | X) H(Y∣X) 表示在已知随机变量X的条件下随机变量Y的不确定性。条件熵定义为X给定条件下Y的条件概率分布的熵对X的数学期望:
H ( Y ∣ X ) = ∑ x p ( x ) H ( Y ∣ X = x ) = − ∑ x , y p ( x , y ) l o g ( y ∣ x ) H(Y | X) = \sum_x p(x) H(Y | X = x) = - \sum_{x, y} p(x, y) log(y|x) H(Y∣X)=x∑p(x)H(Y∣X=x)=−x,y∑p(x,y)log(y∣x)
条件熵 H ( Y ∣ X ) H(Y | X) H(Y∣X) 等于联合熵 H ( X , Y ) H(X, Y) H(X,Y) 减去单独的熵 H ( X ) H(X) H(X)
H ( Y ∣ X ) = H ( X , Y ) − H ( X ) H(Y | X) = H(X, Y) - H(X) H(Y∣X)=H(X,Y)−H(X)
相对熵
相对熵,又称KL散度,是描述两个概率分布P 和Q差异的一种方法。
设
P
(
X
)
P(X)
P(X) 和
Q
(
X
)
Q(X)
Q(X)是X取值的两个离散概率分布,则P对Q的相对熵为
D
(
P
∣
∣
Q
)
=
∑
P
(
x
)
log
P
(
x
)
Q
(
x
)
D(P || Q) = \sum P(x) \log \frac{P(x)}{Q(x)}
D(P∣∣Q)=∑P(x)logQ(x)P(x)
相对熵具有两个主要的性质:
- 不对称性:尽管KL散度从直观上是个度量或距离函数,但它并不是一个真正的度量或者距离,因为它不具有对称性,即 D ( P ∣ ∣ Q ) ≠ D ( Q ∣ ∣ P ) D(P || Q) \neq D(Q||P) D(P∣∣Q)=D(Q∣∣P)
- 非负性:相对熵的值为非负值,即 D ( P ∣ ∣ Q ) ≥ 0 D(P || Q) \geq 0 D(P∣∣Q)≥0
交叉熵
在实际对分类问题中的损失函数一般选用的是交叉熵,它主要用于度量两个概率分布间的差异性信息
假设现在有一个样本集中两个概率分布P和Q,其中P表示真实分布,Q表示非真实分布。假如,按照真实分布P来衡量识别一个样本所需要的编码长度的期望为:
H
(
P
)
=
−
∑
i
P
(
i
)
log
P
(
i
)
H(P) = - \sum_i P(i) \log{P(i)}
H(P)=−i∑P(i)logP(i)
但是,如果采用错误的分布Q来表示真实分布P的平均编码长度,则应该是
H
(
P
,
Q
)
=
−
∑
i
P
(
i
)
log
Q
(
i
)
H(P, Q) = - \sum_i P(i) \log{Q(i)}
H(P,Q)=−i∑P(i)logQ(i)
此时就将H(P, Q)称之为交叉熵
交叉熵和KL散度是机器学习中极其常用的两个指标,用来衡量两个概率分布的相似度,常被作为Loss Function