NVIDIA TensorRT Model Optimizer
NVIDIA TensorRT 模型优化器(ModelOpt)是一个用于优化 AI 模型的库,它通过量化和稀疏性技术减小模型大小并加速推理,同时保持模型性能。ModelOpt 支持多种量化格式和算法,包括 FP8、INT8、INT4,并提供 Python API 以实现轻松优化。它还支持后训练量化和量化感知训练。此外,ModelOpt 提供了稀疏性 API,以减少模型的内存占用,支持 NVIDIA 的稀疏模式和稀疏化方法,并推荐使用微调来最小化精度损失。
1 Install
1-1 System requirements

1-2 pip install
pip install "nvidia-modelopt[all]" --no-cache-dir --extra-index-url https://pypi.nvidia.com
1-3 Check installation
python -c "import modelopt.torch.quantization.extensions as ext; print(ext.cuda_ext); print(ext.cuda_ext_fp8)"
2 Quantization
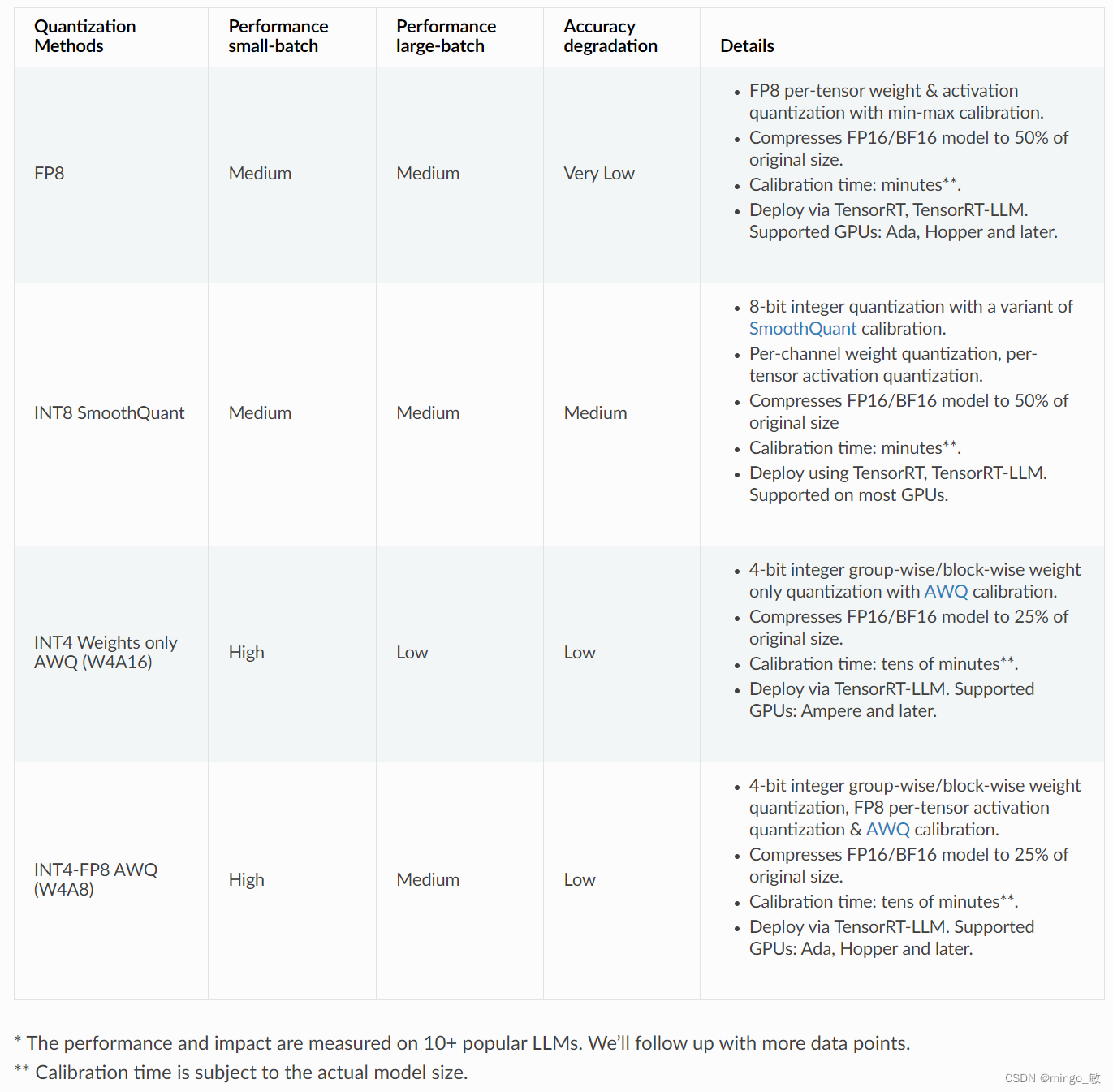
2-1 选择量化方法时需要考虑的权衡因素
2-2 PyTorch Quantization
2-2-1 Post Training Quantization (PTQ)
可以通过在少量训练或评估数据(通常是128-512个样本)上进行简单的校准来实现后训练量化(PTQ)一个PyTorch模型。
import modelopt.torch.quantization as mtq
# Setup the model
model = get_model()
# Select quantization config
config = mtq.INT8_SMOOTHQUANT_CFG
# Quantization need calibration data. Setup calibration data loader
# An example of creating a calibration data loader looks like the following:
data_loader = get_dataloader(num_samples=calib_size)
# Define forward_loop. Please wrap the data loader in the forward_loop
def forward_loop(model):
for batch in data_loader:
model(batch)
# Quantize the model and perform calibration (PTQ)
model = mtq.quantize(model, config, forward_loop)
# Print quantization summary after successfully quantizing the model with mtq.quantize
# This will show the quantizers inserted in the model and their configurations
mtq.print_quantization_summary(model)
torch.onnx.export(model, sample_input, onnx_file)
2-2-2 Quantization-aware Training (QAT)
量化感知训练(QAT)是一种微调量化模型的技术,用于恢复由于量化导致的模型质量下降。尽管QAT比后训练量化(PTQ)需要更多的计算资源,但它在恢复模型质量方面非常有效。
import modelopt.torch.quantization as mtq
# Select quantization config
config = mtq.INT8_DEFAULT_CFG
# Define forward loop for calibration
def forward_loop(model):
for data in calib_set:
model(data)
# QAT after replacement of regular modules to quantized modules
model = mtq.quantize(model, config, forward_loop)
# Fine-tune with original training pipeline
# Adjust learning rate and training duration
train(model, train_loader, optimizer, scheduler, ...)
建议对原始训练epoch的10%进行量化感知训练(QAT)。对于大型语言模型(LLMs),即使对原始预训练持续时间的不到1%进行QAT微调也通常足以恢复模型质量。
2-2-3 Storing and loading quantized model
mto.modelopt_state() 提供了模型的量化器状态。这些量化器状态可以使用 torch.save 来保存。
import modelopt.torch.opt as mto
# Save quantizer states
torch.save(mto.modelopt_state(model), "modelopt_state.pt")
# Save model weights using torch.save or custom check-pointing function
# trainer.save_model("model.pt")
torch.save(model.state_dict(), "model.pt")
要恢复一个量化模型,首先使用 mto.restore_from_modelopt_state 来恢复量化器状态。在量化器状态恢复后,加载模型的权重。
import modelopt.torch.opt as mto
# Initialize the un-quantized model
model = ...
# Load quantizer states
model = mto.restore_from_modelopt_state(model, torch.load("modelopt_state.pt"))
# Load model weights using torch.load or custom check-pointing function
# model.from_pretrained("model.pt")
model.load_state_dict(torch.load("model.pt"))
2-2-4 Advanced Topics
TensorQuantizer
ModelOpt 的 mtq.quantize() 方法会在模型层(如线性层、卷积层等)中插入 TensorQuantizer(量化模块),并修改它们的前向传播方法来执行量化。
要创建 TensorQuantizer 实例,您需要指定 QuantDescriptor,该描述符描述了量化参数,如quantization bits, axis等。
from modelopt.torch.quantization.tensor_quant import QuantDescriptor
from modelopt.torch.quantization.nn import TensorQuantizer
# Create quantizer descriptor
quant_desc = QuantDescriptor(num_bits=8, axis=(-1,), unsigned=True)
# Create quantizer module
quantizer = TensorQuantizer(quant_desc)
quant_x = quantizer(x) # Quantize input x
Customize quantizer config
ModelOpt 在常见的层中插入了输入量化器、权重量化器和输出量化器,但默认情况下禁用了输出量化器。用户如果想要自定义默认的量化器配置,可以使用通配符或过滤器函数匹配来更新提供给 mtq.quantize 的配置字典。
# Select quantization config
config = mtq.INT8_DEFAULT_CFG.copy()
config["quant_cfg"]["*.bmm.output_quantizer"] = {
"enable": True
} # Enable output quantizer for bmm layer
# Perform PTQ/QAT;
model = mtq.quantize(model, config, forward_loop)
Custom quantized module and quantizer placement
modelopt.torch.quantization 提供了一组默认的量化模块(详见 modelopt.torch.quantization.nn.modules 以获取详细列表)和量化器放置规则(输入、输出和权重量化器)。但是也允许自定义的量化模块和/或自定义量化器的放置位置。
from modelopt.torch.quantization.nn import TensorQuantizer
class QuantLayerNorm(nn.LayerNorm):
def __init__(self, normalized_shape):
super().__init__(normalized_shape)
self._setup()
def _setup(self):
# Method to setup the quantizers
self.input_quantizer = TensorQuantizer()
self.weight_quantizer = TensorQuantizer()
def forward(self, input):
# You can customize the quantizer placement anywhere in the forward method
input = self.input_quantizer(input)
weight = self.weight_quantizer(self.weight)
return F.layer_norm(input, self.normalized_shape, weight, self.bias, self.eps)
import modelopt.torch.quantization as mtq
# Register the custom quantized module
mtq.register(original_cls=nn.LayerNorm, quantized_cls=QuantLayerNorm)
# Perform PTQ
# nn.LayerNorm modules in the model will be replaced with the QuantLayerNorm module
model = mtq.quantize(model, config, forward_loop)
Fast evaluation
Weight folding 避免了在每次推理前向传递过程中权重的重复量化,并加速了eval 过程。
# Fold quantizer together with weight tensor
mtq.fold_weight(quantized_model)
# Run model evaluation
user_evaluate_func(quantized_model)
3 Sparsity
3-1 Post-Training Sparsification
后训练稀疏化技术允许您将已经训练好的密集模型转换为更高效的稀疏模型,而无需经过重新训练的过程。这一过程可以通过调用 mts.sparsify API 轻松实现,它通过接受稀疏配置和稀疏格式的参数来输出一个优化后的稀疏模型。
提供的稀疏配置是一个详细的字典,它定义了模型中哪些层需要进行稀疏化处理,并且可以选择性地包含一个数据加载器,用于在数据驱动的稀疏化方法(如 SparseGPT)中进行校准。
mts.sparsify() 提供了两种稀疏化方法的支持:NVIDIA ASP 用于基于权重幅度的稀疏化,而 SparseGPT 用于更高级的数据驱动稀疏化。
import torch
from transformers import AutoModelForCausalLM
import modelopt.torch.sparsity as mts
# User-defined model
model = AutoModelForCausalLM.from_pretrained("EleutherAI/gpt-j-6b")
# Configure and convert for sparsity
sparsity_config = {
# data_loader is required for sparsity calibration
"data_loader": calib_dataloader,
"collect_func": lambda x: x,
}
sparse_model = mts.sparsify(
model,
"sparsegpt", # or "sparse_magnitude"
config=sparsity_config,
)
Save and restore the sparse model
mto.save() 将保存模型的 state_dict,以及稀疏掩码和元数据,以便稍后正确重新创建稀疏模型。
mto.save(sparse_model, "modelopt_sparse_model.pth")
mto.restore() 将恢复模型的 state_dict,以及每个稀疏模块的稀疏掩码和元数据。普通的 PyTorch 模块将被转换为稀疏模块。当访问模型权重时,稀疏掩码将自动被应用。
import modelopt.torch.opt as mto
# Re-initialize the original, unmodified model
model = AutoModelForCausalLM.from_pretrained("EleutherAI/gpt-j-6b")
# Restore the sparse model and metadata.
sparse_model = mto.restore(model, "modelopt_sparse_model.pth")
mts.export() 将稀疏模型导出为普通的 PyTorch 模型。稀疏掩码将被应用到模型权重上,并且所有稀疏相关的元数据都将被移除。导出后,在后续的微调过程中将不再强制执行稀疏性。如果你想继续微调,请不要导出模型。
3-2 Sparsity Concepts
3-2-1 Structured and Unstructured Sparsity
权重稀疏性通过将模型中的部分权重设为零来优化模型。它分为两类:
- 非结构化稀疏性:零权重在权重矩阵中随机分布,灵活但可能导致在GPU等硬件上利用率低。
- 结构化稀疏性:零权重在权重矩阵中有规律地分布,内存访问更高效,支持更高的数学吞吐量。可以通过强制特定的稀疏模式实现。
N:M 稀疏性
3-2-2 N:M Sparsity
N:M 稀疏性是一种特殊的结构化稀疏模式,每个由M个连续元素组成的块中最多有N个非零元素。它在GPU架构上有效,提供以下优势:
- 降低内存带宽需求
- 提高数学吞吐量(如2:4稀疏模式在稀疏张量核心上允许2倍的数学吞吐量)
3-2-3 Sparsification algorithm
实现权重稀疏性的方法有多种,如基于幅度的稀疏性(保留M个元素块中的N个最大元素)和数据驱动的稀疏性(如Optimal Brain Surgeon)。NVIDIA的模型优化器支持基于幅度的(NVIDIA ASP)和数据驱动的稀疏性(SparseGPT)。