大家好,特征选择是机器学习流程中的关键步骤,在实践中通常有大量的变量可用作模型的预测变量,但其中只有少数与目标相关。特征选择包括找到这些特征的子集,主要用于改善泛化能力、助力推断预测、提高训练效率。有许多技术可用于执行特征选择,每种技术的复杂性不同。
本文将介绍一种使用强大的开源优化工具Optuna来执行特征选择任务的创新方法,主要思想是通过有效地测试不同的特征组合(例如,不是逐个尝试它们)来处理各种任务的特征选择的灵活工具。下面,将通过一个实际示例来实施这种方法,并将其与其他常见的特征选择策略进行比较。
1.数据准备
将利用基于Kaggle上的Mobile Price Classification数据集进行分类任务。该数据集包含20个特征,其中包括:'battery_power'、'clock_speed'和'ram' 等,用于预测'price_range'特征,该特征可以分为四个不同的价格范围:0、1、2和3。我们将数据集分成训练集和测试集,并在训练集中准备了一个5折交叉验证分割。
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.model_selection import StratifiedKFold
SEED = 32
# Load data
df = pd.read_csv("mpc_train.csv")
# Train - test split
df_train, df_test = train_test_split(df, test_size=0.2, stratify=df.iloc[:,-1], random_state=SEED)
df_train = df_train.reset_index(drop=True)
df_test = df_test.reset_index(drop=True)
# The last column is the target variable
X_train = df_train.iloc[:,0:20]
y_train = df_train.iloc[:,-1]
X_test = df_test.iloc[:,0:20]
y_test = df_test.iloc[:,-1]
# Stratified kfold over the train set for cross validation
skf = StratifiedKFold(n_splits=5, shuffle=True, random_state=SEED)
splits = list(skf.split(X_train, y_train))
len(splits)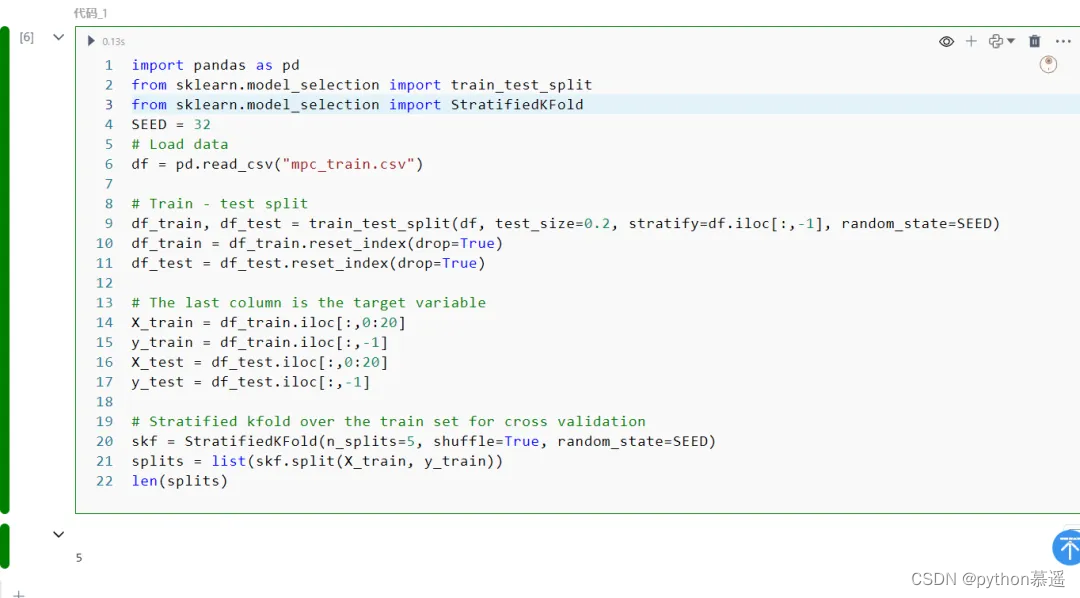
将使用随机森林分类器模型,使用scikit-learn实现并采用默认参数。我们首先使用所有特征训练模型来设置基准。我们将测量的指标是针对所有四个价格范围加权的F1分数。在对训练集进行学习后,我们在测试集上对其进行评估,得到的F1分数约为0.87。
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import f1_score, classification_report
model = RandomForestClassifier(random_state=SEED)
model.fit(X_train,y_train)
preds = model.predict(X_test)
print(classification_report(y_test, preds))
print(f"Global F1: {f1_score(y_test, preds, average='weighted')}")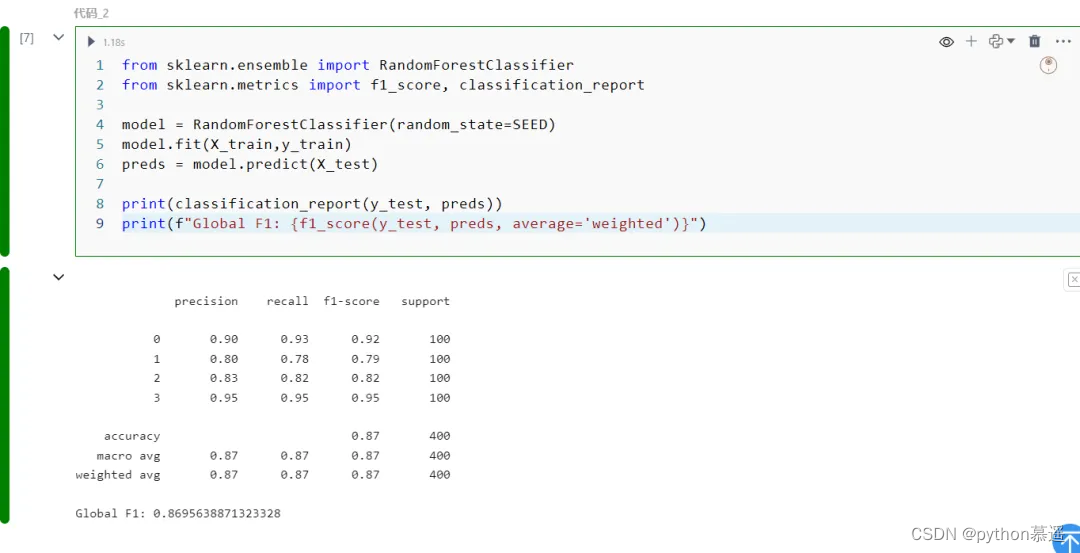
特征选择的目标是通过选择一个较少的特征集来提高评估指标。首先将描述基于Optuna的方法如何工作,然后测试并将其与其他常见的特征选择策略进行比较。
2.用Optuna进行特征选择
Optuna是一个用于超参数调优的优化框架,采用贝叶斯优化技术搜索参数空间。与传统的网格或随机搜索相比,Optuna更高效。我们使用默认的TPESampler采样器,它基于Tree-structured Parzen Estimator算法(TPE)。
在特征选择的情况下,不是调整模型的超参数,而是选择特征。使用训练数据集,分成五个折交叉,在每次试验中训练模型并评估性能。目标是最大化F1分数,同时对使用的特征进行小惩罚以鼓励更小的特征集。
下面是执行特征选择搜索的实现类:
import optuna
class FeatureSelectionOptuna:
"""
This class implements feature selection using Optuna optimization framework.
Parameters:
- model (object): The predictive model to evaluate; this should be any object that implements fit() and predict() methods.
- loss_fn (function): The loss function to use for evaluating the model performance. This function should take the true labels and the
predictions as inputs and return a loss value.
- features (list of str): A list containing the names of all possible features that can be selected for the model.
- X (DataFrame): The complete set of feature data (pandas DataFrame) from which subsets will be selected for training the model.
- y (Series): The target variable associated with the X data (pandas Series).
- splits (list of tuples): A list of tuples where each tuple contains two elements, the train indices and the validation indices.
- penalty (float, optional): A factor used to penalize the objective function based on the number of features used.
"""
def __init__(self,
model,
loss_fn,
features,
X,
y,
splits,
penalty=0):
self.model = model
self.loss_fn = loss_fn
self.features = features
self.X = X
self.y = y
self.splits = splits
self.penalty = penalty
def __call__(self,
trial: optuna.trial.Trial):
# Select True / False for each feature
selected_features = [trial.suggest_categorical(name, [True, False]) for name in self.features]
# List with names of selected features
selected_feature_names = [name for name, selected in zip(self.features, selected_features) if selected]
# Optional: adds a penalty for the amount of features used
n_used = len(selected_feature_names)
total_penalty = n_used * self.penalty
loss = 0
for split in self.splits:
train_idx = split[0]
valid_idx = split[1]
X_train = self.X.iloc[train_idx].copy()
y_train = self.y.iloc[train_idx].copy()
X_valid = self.X.iloc[valid_idx].copy()
y_valid = self.y.iloc[valid_idx].copy()
X_train_selected = X_train[selected_feature_names].copy()
X_valid_selected = X_valid[selected_feature_names].copy()
# Train model, get predictions and accumulate loss
self.model.fit(X_train_selected, y_train)
pred = self.model.predict(X_valid_selected)
loss += self.loss_fn(y_valid, pred)
# Take the average loss across all splits
loss /= len(self.splits)
# Add the penalty to the loss
loss += total_penalty
return loss
将每个特征视为一个参数,可以取True或False值,表示是否应该将该特征包含在模型中。使用suggest_categorical方法,让Optuna为每个特征选择两个可能的值之一。
初始化Optuna研究并进行100次试验的搜索,将第一个试验排入队列,使用所有特征作为搜索的起点,允许Optuna将后续试验与完全特征模型进行比较:
from optuna.samplers import TPESampler
def loss_fn(y_true, y_pred):
"""
Returns the negative F1 score, to be treated as a loss function.
"""
res = -f1_score(y_true, y_pred, average='weighted')
return res
features = list(X_train.columns)
model = RandomForestClassifier(random_state=SEED)
sampler = TPESampler(seed = SEED)
study = optuna.create_study(direction="minimize",sampler=sampler)
# We first try the model using all features
default_features = {ft: True for ft in features}
study.enqueue_trial(default_features)
study.optimize(FeatureSelectionOptuna(
model=model,
loss_fn=loss_fn,
features=features,
X=X_train,
y=y_train,
splits=splits,
penalty = 1e-4,
), n_trials=100)完成了100次试验后,从研究中获取最佳试验和其中使用的特征,如下所示:
[‘battery_power’, ‘blue’, ‘dual_sim’, ‘fc’, ‘mobile_wt’, ‘px_height’, ‘px_width’, ‘ram’, ‘sc_w’]
上述过程从原始的20个特征中,搜索最终只选出了其中的9个特征变量,这是一个显著的减少。这些特征产生了约为-0.9117的最小验证损失,这意味着它们在所有折叠中实现了约为0.9108的平均F1分数(在考虑到惩罚项后)。
下一步是使用这些选定的特征在整个训练集上训练模型,并在测试集上对其进行评估。结果是约为0.882的F1分数:
# Train - test split
c=['battery_power', 'blue', 'dual_sim', 'fc', 'mobile_wt', 'px_height', 'px_width', 'ram', 'sc_w','price_range']
df_c=df[c]
df_train, df_test = train_test_split(df_c, test_size=0.2, stratify=df.iloc[:,-1], random_state=SEED)
df_train = df_train.reset_index(drop=True)
df_test = df_test.reset_index(drop=True)
# The last column is the target variable
X_train = df_train.iloc[:,0:9]
y_train = df_train.iloc[:,-1]
X_test = df_test.iloc[:,0:9]
y_test = df_test.iloc[:,-1]
# Stratified kfold over the train set for cross validation
skf = StratifiedKFold(n_splits=5, shuffle=True, random_state=SEED)
splits = list(skf.split(X_train, y_train))
model = RandomForestClassifier(random_state=SEED)
model.fit(X_train,y_train)
preds = model.predict(X_test)
print(classification_report(y_test, preds))
print(f"Global F1: {f1_score(y_test, preds, average='weighted')}")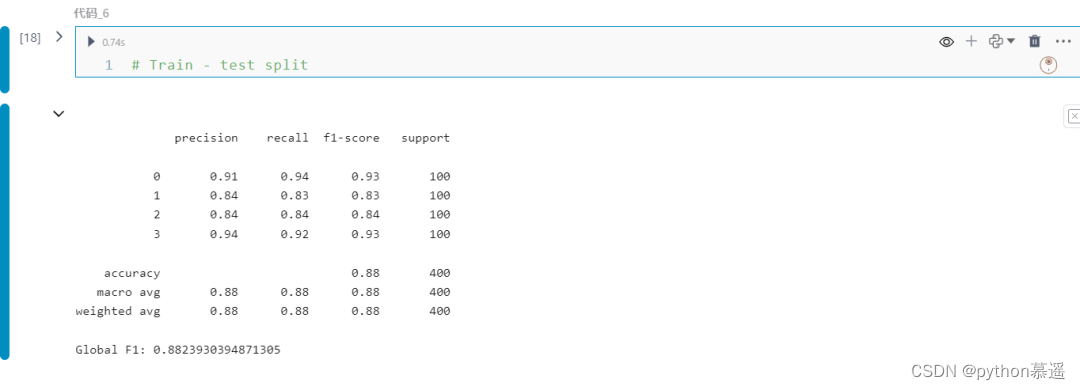
通过选择合适的特征组合,能够将特征集减少了一半以上,同时仍然实现了比全特征集更高的F1分数。下面是Optuna进行特征选择的一些优缺点:
优点:
-
高效地搜索特征集,考虑了哪些特征组合最有可能产生良好的结果。
-
适用于许多场景:只要有模型和损失函数,我们就可以用它来处理任何特征选择任务。
-
看到了整体情况:与评估单个特征的方法不同,Optuna考虑了哪些特征彼此之间往往配合得好,哪些不好。
-
作为优化过程的一部分动态确定特征数量。这可以通过惩罚项进行调节。
缺点:
-
与简单方法相比,不那么直观,对于较小和较简单的数据集可能不值得使用。
-
尽管与其他方法(如穷举搜索)相比需要的试验次数要少得多,但通常仍需要大约100到1000次试验。根据模型和数据集的不同,这可能耗时且计算成本高昂。
3.其他特征选择方法
SelectKBest是scikit-learn库中的一个特征选择工具,用于选择与目标变量相关性最高的k个特征。它基于给定的评分函数对每个特征进行评分,并返回得分最高的k个特征。这个工具通常用于过滤方法中,它不需要构建模型,而是直接对特征进行评估和选择。通过选择与目标变量高度相关的特征,SelectKBest可以帮助提高模型的预测性能和泛化能力。
from sklearn.feature_selection import SelectKBest, chi2
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.model_selection import StratifiedKFold
SEED = 32
# Load data
df = pd.read_csv("mpc_train.csv")
# Train - test split
df_train, df_test = train_test_split(df, test_size=0.2, stratify=df.iloc[:,-1], random_state=SEED)
df_train = df_train.reset_index(drop=True)
df_test = df_test.reset_index(drop=True)
# The last column is the target variable
X_train = df_train.iloc[:,0:20]
y_train = df_train.iloc[:,-1]
X_test = df_test.iloc[:,0:20]
y_test = df_test.iloc[:,-1]
skb = SelectKBest(score_func=chi2, k=10)
X_train_selected = skb.fit_transform(X_train, y_train)
X_test_selected = skb.transform(X_test)
# Train Random Forest Classifier
model = RandomForestClassifier(random_state=SEED)
model.fit(X_train_selected, y_train)
# Predictions
preds = model.predict(X_test_selected)
# Evaluation
print(classification_report(y_test, preds))
print(f"Global F1: {f1_score(y_test, preds, average='weighted')}")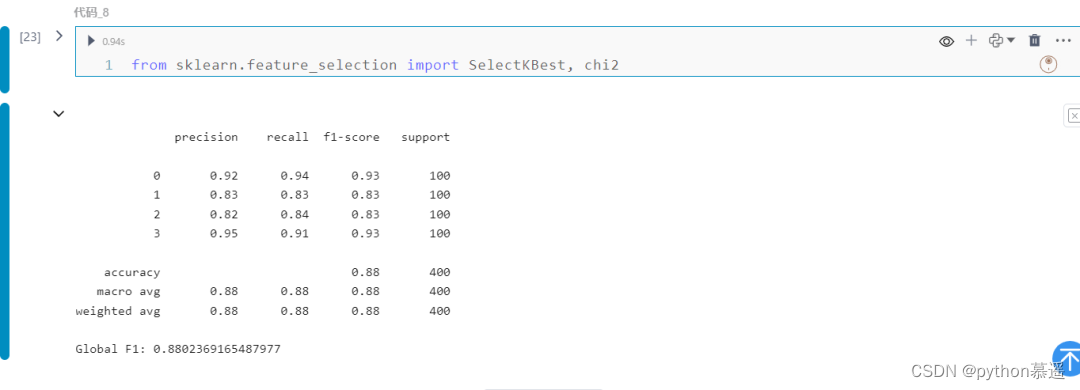
通过上述对比,可以看出通过Optuna进行特征选择有更高的效率和更好的性能指标。使用Optuna这一强大的优化工具来进行特征选择任务,通过有效地搜索空间,它能够在相对较少的试验中找到好的特征子集。而且它还具有灵活性,并且只要定义模型和损失函数,可以适应许多场景。




![weblogic [WeakPassword]](https://img-blog.csdnimg.cn/direct/9b1a614a556840429f89f834ffdab968.png)