🎉AI学习星球推荐: GoAI的学习社区 知识星球是一个致力于提供《机器学习 | 深度学习 | CV | NLP | 大模型 | 多模态 | AIGC 》各个最新AI方向综述、论文等成体系的学习资料,配有全面而有深度的专栏内容,包括不限于 前沿论文解读、资料共享、行业最新动态以、实践教程、求职相关(简历撰写技巧、面经资料与心得)多方面综合学习平台,强烈推荐AI小白及AI爱好者学习,性价比非常高!加入星球➡️点击链接
✨专栏介绍: 本作者推出全新系列《深入浅出LLM》专栏,将分为基础篇、进阶篇、实战篇等,本文为基础篇具体章节如导图所示(导图为常见LLM问题,导图专栏后续更新!),将分别从各个大模型模型的概念、经典模型、创新点、微调、分布式训练、数据集、未来发展方向、RAG、Agent及项目实战等各种角度展开详细介绍,欢迎大家关注。
💙作者主页: GoAI |💚 公众号: GoAI的学习小屋 | 💛交流群: 704932595 |💜个人简介 : 掘金签约作者、百度飞桨PPDE、领航团团长、开源特训营导师、CSDN、阿里云社区人工智能领域博客专家、新星计划计算机视觉方向导师等,专注大数据与AI 知识分享。
《深入浅出LLM基础篇》目录
《深入浅出LLM基础篇》(一):大模型概念与发展
《深入浅出LLM基础篇》(二):大模型基础知识
《深入浅出LLM基础篇》(三):大模型结构分类
《深入浅出LLM基础篇》(四):主流大模型分类介绍(本篇)
《深入浅出LLM基础篇》(四):主流大模型分类介绍
导读:本篇为《深入浅出LLM基础篇》系列第四篇,《深入浅出LLM基础篇》(四):主流大模型分类介绍主流大模型分类,主要讨论各类模型结构组成、模型特点、数据规模等进行介绍,包括 ChtaGLM、LLAMA等 系列,最后对经典问题进行总结,方便大家交流学习。
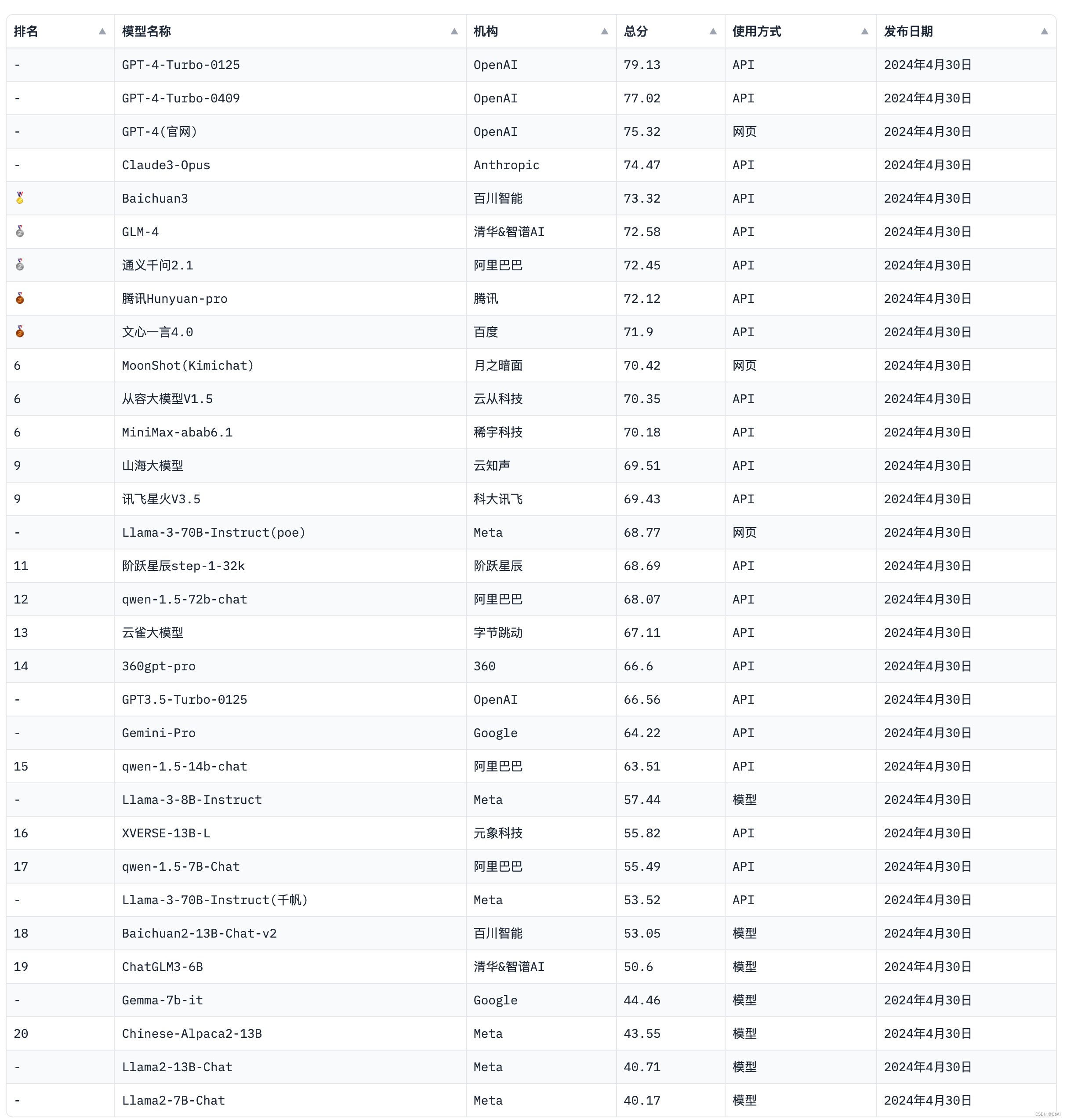
4.1 主流大模型排名
4.2 经典大模型介绍
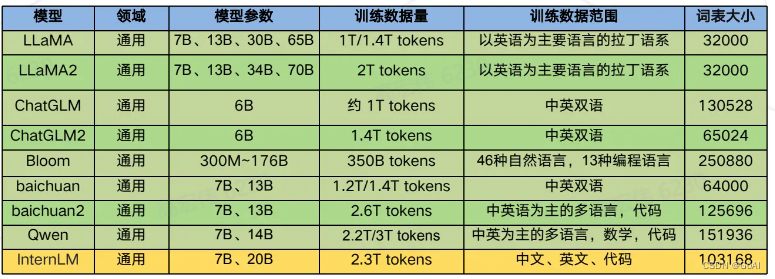
主流模型升级点:
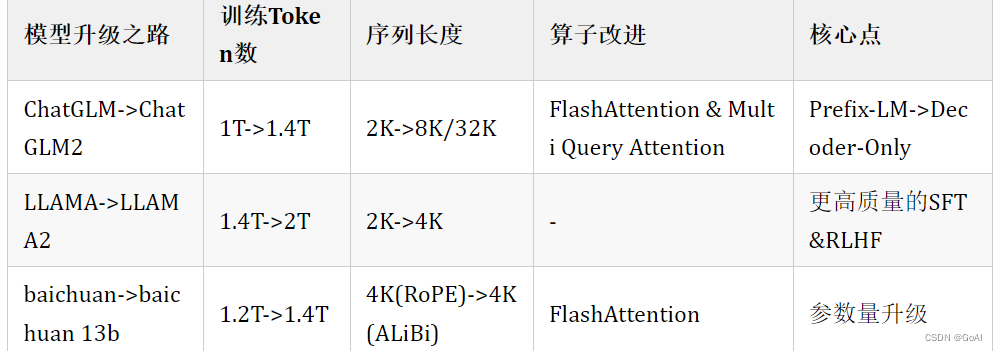
4.2.1 LLAMA 系列
LLaMa
LLaMA采用causal decoder-only的transformer模型结构。与Transformer不同地方采用前置层归一化(Pre-normalization),并使用RMSNorm归一化函数(Normalizing Function)、激活函数更换为SwiGLU,并使用旋转位置嵌入(RoP),整体Transformer架构与GPT-2类似。

- 在训练目标:LLaMA的训练目标是语言模型,即根据已有的上文去预测下一个词。 7B:consolidated.00.pth(13.16G) 13B:25G
- layer normalization:使用RMSNorm均方根归一化函数。作用:为提升训练稳定性,LLaMa对每个Transformer的子层的输入进行归一化,而不是对输出进行归一化。用pre layer Norm(预训练层归一化),去除layer normalization中偏置项。
- 激活函数:没有采用ReLU激活函数,而是采用了SwiGLU激活函数(结合SWISH 和 GLU 两种者的特点)。SwiGLU 主要是为了提升 Transformer 中 的 FFN(feed-forward network) 层的实现。FFN通常有两个权重矩阵,先将向量从维度d升维到中间维度4d,再从4d降维到d。而使用SwiGLU激活函数的FFN增加了一个权重矩阵,共有三个权重矩阵,为了保持参数量一致,中间维度采用了 2/3 x4d ,而不是4d。
- 位置编码:去除了绝对位置编码,采用了旋转位置编码RoPE,可以兼顾相对位置和绝对位置的信息以提高模型的泛化能力。
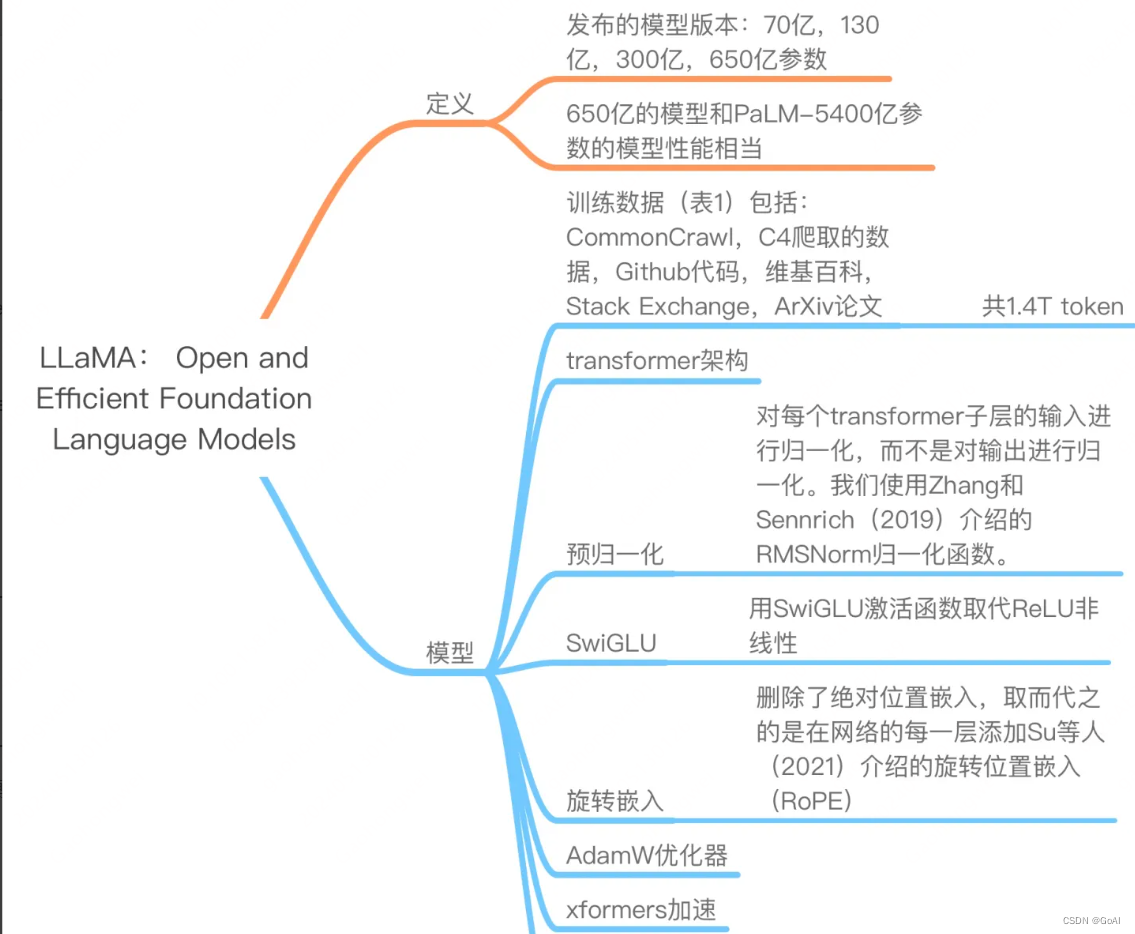
不同LLAMA结构参数:
Llama2
- 官网:https://ai.meta.com/llama/
- 论文名称:《Llama 2: Open Foundation and Fine-Tuned Chat Models》
- 论文地址:https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/
- 演示平台:https://llama2.ai/
- Github 代码:https://github.com/facebookresearch/llama
- 模型下载地址:https://ai.meta.com/resources/models-and-libraries/llama-downloads/
llama-2-open-foundation-and-fine-tuned-chat-models
介绍:此次 Meta 发布的 Llama 2 模型系列包含 70 亿、130 亿和 700 亿三种参数变体。此外还训练了 340亿参数变体,但并没有发布,只在技术报告中提到了。据介绍,相比于 Llama 1,Llama 2 的训练数据多了40%,上下文长度也翻倍,并采用了分组查询注意力机制。具体来说,Llama 2 预训练模型是在 2 万亿的 token 上训练的,精调Chat 模型是在 100 万人类标记数据上训练的。
- 官网:https://ai.meta.com/llama/
- 论文名称:《Llama 2: Open Foundation and Fine-Tuned Chat Models》
- 论文地址:https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/
- 演示平台:https://llama2.ai/
- Github 代码:https://github.com/facebookresearch/llama
- 模型下载地址:https://ai.meta.com/resources/models-and-libraries/llama-downloads/
Chinese-Llama-2-7b
介绍:自打 LLama-2 发布后就一直在等大佬们发布 LLama-2 的适配中文版,也是这几天蹲到了一版由 LinkSoul 发布的Chinese-Llama-2-7b,其共发布了一个常规版本和一个 4-bit 的量化版本,今天我们主要体验下 Llama-2的中文逻辑顺便看下其训练样本的样式,后续有机会把训练和微调跑起来。
- 官网:https://ai.meta.com/llama/
- 论文名称:《Llama 2: Open Foundation and Fine-Tuned Chat Models》
- 论文地址:https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/
- 演示平台:https://huggingface.co/spaces/LinkSoul/Chinese-Llama-2-7b
- Github 代码:https://github.com/LinkSoul-AI/Chinese-Llama-2-7b
- 模型下载地址:
- https://huggingface.co/ziqingyang/chinese-llama-2-7b
- https://huggingface.co/LinkSoul/Chinese-Llama-2-7b-4bit
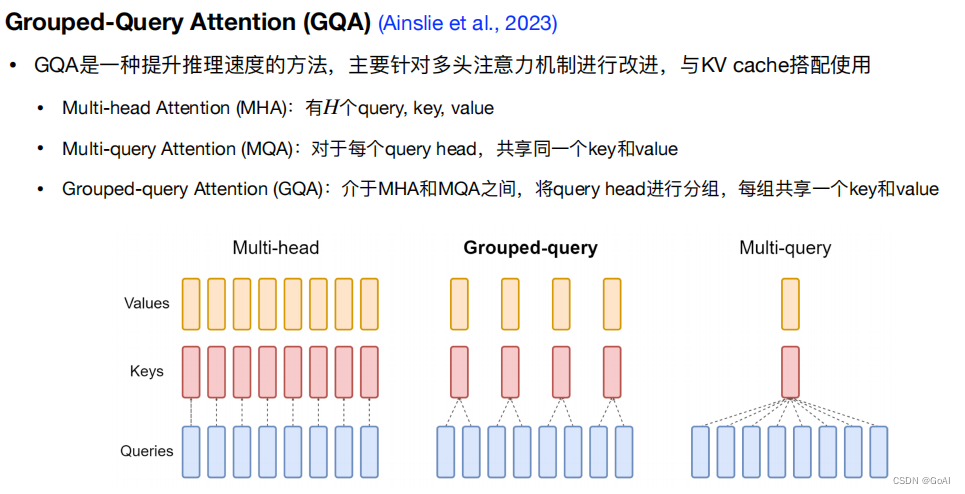
llama2在llama1 上有什么升级: GQA+上下文窗口扩大
- 预训练语料从 1 Trillion tokens -> 2 Trillion tokens; context window 长度从 2048 -> 4096;
- 收集了 100k 人类标注数据进行 SFT+收集了 1M 人类偏好数据进行RLHF;
- 在 reasoning, coding, proficiency, and knowledge tests 上表现超越 MPT 和 Falcon;
- 使用 Group Query Attention,优势在于其将Query进行分组,组内共享KV,使得K和V的预测可以跨多个头共享,显著降低计算和内存需求,提升推理速度 。
4.2.2 ChatGLM 系列
ChatGLM支持中英双语的对话语言模型,基于 General Language Model (GLM) 架构,具有 62 亿参数。

训练目标:ChatGLM-6B的训练任务是自回归文本填空。相比于causal decoder-only结构,采用prefix decoder-only结构的ChatGLM-6B存在一个劣势:训练效率低。causal decoder结构会在所有的token上计算损失,而prefix decoder只会在输出上计算损失,而不计算输入上的损失。
ChatGLM2-6B
- 论文名称:ChatGLM2-6B: An Open Bilingual Chat LLM | 开源双语对话语言模型
- 论文地址:
- Github 代码:https://github.com/THUDM/ChatGLM2-6B
- 动机:在主要评估LLM模型中文能力的 C-Eval 榜单中,截至6月25日 ChatGLM2 模型以 71.1 的分数位居 Rank 0 ,ChatGLM2-6B 模型以 51.7 的分数位居 Rank 6,是榜单上排名最高的开源模型。
- 介绍:ChatGLM2-6B 是开源中英双语对话模型 ChatGLM-6B 的第二代版本,在保留了初代模型对话流畅、部署门槛较低等众多优秀特性的基础之上,ChatGLM2-6B 引入了如下新特性:
- 更强大的性能:基于 ChatGLM 初代模型的开发经验,我们全面升级了 ChatGLM2-6B 的基座模型。ChatGLM2-6B 使用了 GLM 的混合目标函数,经过了 1.4T 中英标识符的预训练与人类偏好对齐训练,评测结果显示,相比于初代模型,ChatGLM2-6B 在 MMLU(+23%)、CEval(+33%)、GSM8K(+571%) 、BBH(+60%)等数据集上的性能取得了大幅度的提升,在同尺寸开源模型中具有较强的竞争力。
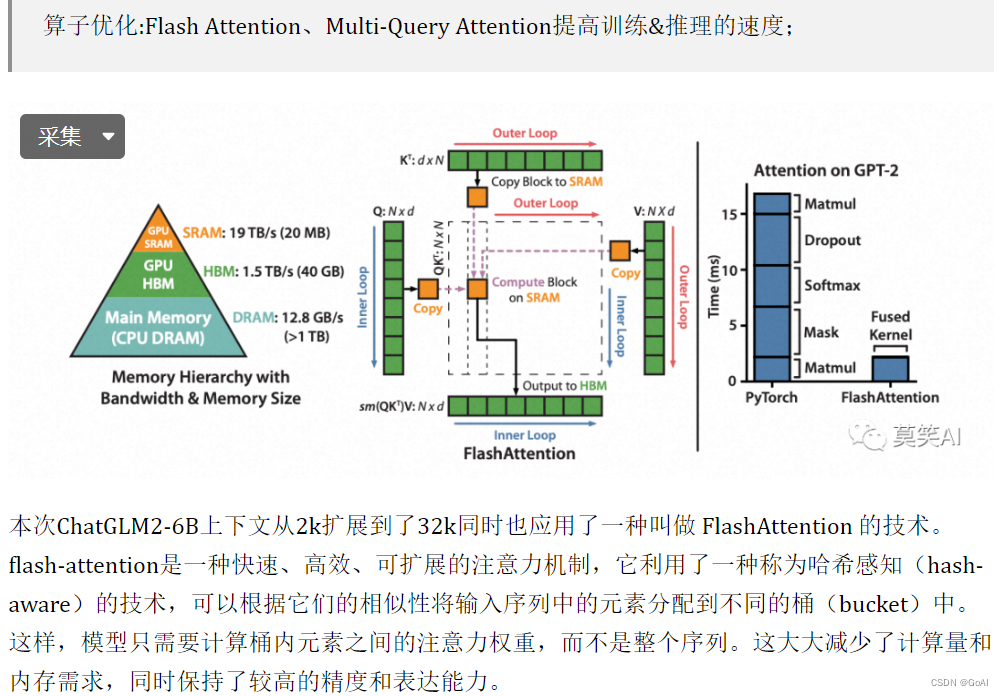
- 更长的上下文:基于 FlashAttention 技术,我们将基座模型的上下文长度(Context Length)由 ChatGLM-6B 的 2K 扩展到了 32K,并在对话阶段使用 8K 的上下文长度训练,允许更多轮次的对话。但当前版本的 ChatGLM2-6B 对单轮超长文档的理解能力有限,我们会在后续迭代升级中着重进行优化。
- 更高效的推理:基于 Multi-Query Attention 技术,ChatGLM2-6B 有更高效的推理速度和更低的显存占用:在官方的模型实现下,推理速度相比初代提升了 42%,INT4 量化下,6G 显存支持的对话长度由 1K 提升到了 8K。
- 更开放的协议:ChatGLM2-6B 权重对学术研究完全开放,在获得官方的书面许可后,亦允许商业使用。如果您发现我们的开源模型对您的业务有用,我们欢迎您对下一代模型 ChatGLM3 研发的捐赠。
ChatGLM3
- 论文名称:ChatGLM3
- Github 代码:https://github.com/THUDM/ChatGLM3
- 模型地址:
- huggingface:https://huggingface.co/THUDM/chatglm3-6b
- modelscope:https://modelscope.cn/models/ZhipuAI/chatglm3-6b/summary
- 动机:2023年10月26日,由中国计算机学会主办的2023中国计算机大会(CNCC)正式开幕,据了解,智谱AI于27日论坛上推出了全自研的第三代基座大模型ChatGLM3及相关系列产品,这也是智谱AI继推出千亿基座的对话模型ChatGLM和ChatGLM2之后的又一次重大突破。
- 介绍:ChatGLM3 是智谱AI和清华大学 KEG 实验室联合发布的新一代对话预训练模型。ChatGLM3-6B 是 ChatGLM3 系列中的开源模型,在保留了前两代模型对话流畅、部署门槛低等众多优秀特性的基础上,ChatGLM3-6B 引入了如下特性:
- 更强大的基础模型: ChatGLM3-6B 的基础模型 ChatGLM3-6B-Base 采用了更多样的训练数据、更充分的训练步数和更合理的训练策略。在语义、数学、推理、代码、知识等不同角度的数据集上测评显示,ChatGLM3-6B-Base 具有在 10B 以下的基础模型中最强的性能。
- 更完整的功能支持: ChatGLM3-6B 采用了全新设计的 Prompt 格式,除正常的多轮对话外。同时原生支持工具调用(Function Call)、代码执行(Code Interpreter)和 Agent 任务等复杂场景。
- 更全面的开源序列: 除了对话模型 ChatGLM3-6B 外,还开源了基础模型 ChatGLM3-6B-Base、长文本对话模型 ChatGLM3-6B-32K。以上所有权重对学术研究完全开放,在填写问卷进行登记后亦允许免费商业使用。
4.2.3 Baichuan系列
Baichuan-13B是由百I川智能继Baichuan-7B之后开发的包含130亿参数的开源可商用的大规模语言模型,在权威的中文和英文,benchmark上均取得同尺寸最好的效果。Baichuan-13B有如下几个特点:
1.更大尺寸、更多数据:Baichuan-13B在Baichuan-7B的基础上进一步扩大参数量到130亿,并且在高质量的语料上训练了1.4万亿tokens,.超过LLaMA-13B40%,是当前开源13B尺寸下训练数据量最多的模型。支持中英双语,使用ALBi位置编码,上下文窗口长度为4096.
2.同时开源预训练和对齐模型:预训练模型是适用开发者的“基座”,而广大普通用户对有对话功能的对齐模型具有更强的需求。因此本次开源同时发布了对齐模型(Baichuan-13B-Chat),具有很强的对话能力,开箱即用,几行代码即可简单的部署。
3.更高效的推理:为了支持更广大用户的使用,本次同时开源了it8和it4的量化版本,相对非量化版本在几乎没有效果损失的情况下大大降低了部署的机器资源门槛,可以部署在如Nvidia3090这样的消费级显卡上。
4.开源免费可商用:13B不仅对学术研究完全开放,开发者也仅需邮件申请并获得官方商用许可后,即可以免费商用。
Baichuan2
- 介绍:Baichuan 2 是百川智能推出的新一代开源大语言模型,采用 2.6 万亿 Tokens 的高质量语料训练。Baichuan 2 在多个权威的中文、英文和多语言的通用、领域 benchmark 上取得同尺寸最佳的效果。本次发布包含有 7B、13B 的 Base 和 Chat 版本,并提供了 Chat 版本的 4bits 量化。
- 论文名称:Baichuan 2: Open Large-scale Language Models
- Github 代码:https://github.com/baichuan-inc/Baichuan2
- 模型:https://huggingface.co/baichuan-inc
- Baichuan-13B 大模型:
- 官方微调过(指令对齐):https://huggingface.co/baichuan-inc/Baichuan-13B-Chat
- 预训练大模型(未经过微调):https://huggingface.co/baichuan-inc/Baichuan-13B-Base
Baichuan-13B
-
baichuan-inc/Baichuan-13B:https://github.com/baichuan-inc/Baichuan-13B
-
Baichuan-13B 大模型:
- 官方微调过(指令对齐):https://huggingface.co/baichuan-inc/Baichuan-13B-Chat
- 预训练大模型(未经过微调):https://huggingface.co/baichuan-inc/Baichuan-13B-Base
-
介绍:Baichuan-13B 是由百川智能继 Baichuan-7B 之后开发的包含 130 亿参数的开源可商用的大规模语言模型,在权威的中文和英文 benchmark 上均取得同尺寸最好的效果。Baichuan-13B 有如下几个特点:
- 更大尺寸、更多数据:Baichuan-13B 在 Baichuan-7B 的基础上进一步扩大参数量到 130 亿,并且在高质量的语料上训练了 1.4 万亿 tokens,超过 LLaMA-13B 40%,是当前开源 13B 尺寸下训练数据量最多的模型。支持中英双语,使用 ALiBi 位置编码,上下文窗口长度为 4096。
- 同时开源预训练和对齐模型:预训练模型是适用开发者的“基座”,而广大普通用户对有对话功能的对齐模型具有更强的需求。因此本次开源同时发布了对齐模型(Baichuan-13B-Chat),具有很强的对话能力,开箱即用,几行代码即可简单的部署。
- 更高效的推理:为了支持更广大用户的使用,本次同时开源了 int8 和 int4 的量化版本,相对非量化版本在几乎没有效果损失的情况下大大降低了部署的机器资源门槛,可以部署在如 Nvidia 3090 这样的消费级显卡上。
- 开源免费可商用:Baichuan-13B 不仅对学术研究完全开放,开发者也仅需邮件申请并获得官方商用许可后,即可以免费商用。
baichuan-7B
介绍:由百川智能开发的一个开源可商用的大规模预训练语言模型。基于Transformer结构,在大约1.2万亿tokens上训练的70亿参数模型,支持中英双语,上下文窗口长度为4096。在标准的中文和英文权威benchmark(C-EVAL/MMLU)上均取得同尺寸最好的效果。
- 论文名称:
- 论文地址:
- Github 代码: https://github.com/baichuan-inc/baichuan-7B
4.2.4 Qwen
自回归语言模型训练目标,训练时上下文长度为2048,推理8k。使用高达3万亿个token的数据进行预训练,数据涵盖多个类型、领域和任务。目前最大上下文长度32K,分词(Tokenization)采用的是基于BPE(Byte Pair Encoding)的方法.
Qwen采用了改进版的Transformer架构。具体来说,采用了最近开源的大型语言模型LLaMA的训
练方法,并做了如下改进:
- embedding和输出映射不进行权重共享,从而达到以内存成本为代价换取获得更好的性能。
使用了RoPE(旋转位置编码)进行位置编码。RoPE在当代大型语言模型中已被广泛采用,比如PLM和LLaMA。为了优先考虑模型性能并获得更高的精确度,使用FP32精确度的逆频率矩
阵,而不是BF16或FP16.在大多数层中移除了BiaS,但在QKV层保留以提升模型的外推能力。 - 使用了预归一化(Pre-Norm)和RMSNormi进行规范化。Pre-Norm是使用最广泛的方法,与
post-normalization相比,它已被证明能提高训练的稳定性。最近的研究提出了提高训练稳定性
的其他方法,官方表示会在模型的未来版本中进行探索。此外,还用RMSNo替代传统的层
归一化技术。这一改变在不损害性能的同时提高了效率。 - 使用了SwiGLU作为激活函数。它是Swsh和门控线性单元GLU的组合。初步实验表明,基于
GLU的激活函数普遍优于其他基线选项,如GLU。按照以往研究中的常见做法,将前馈网络
(FFN)的维度从隐藏大小的4倍降至隐藏大小的8/3。
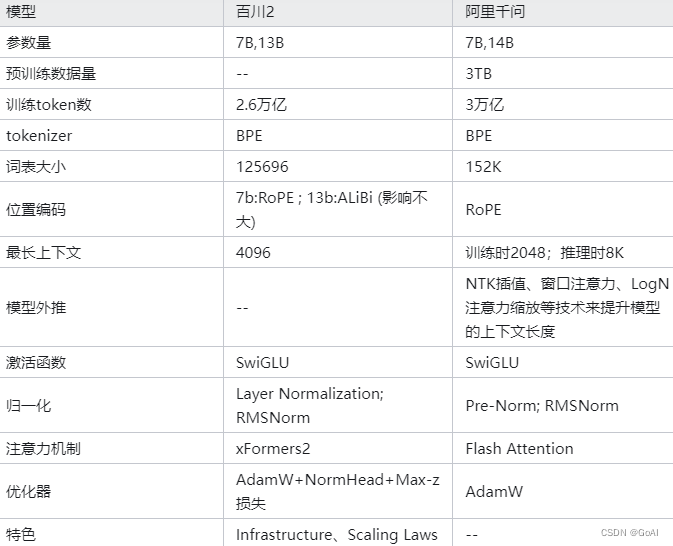
首先,基于开源分词器tiktoken的cl100k基础词表进行初始化。然后,针对中文场景,向词表中增添常用的中文字和词,扩充词表规模。同时,参考GPT-3.5和LLaMA的实现,将数字切分成单个数字,如将"123"分词为"1"、“2”、“3”。最终词表大小约为152K。LLaMA词表大小为3.2W,Qwen为15W;对于一个中文字表示,LLaMA使用了两个token表示,而Qwen使用了一个token;
- 在推理中,更少的Token表示将有更少的推理次数,这意味着更大的词表可以压缩更多的内容,减少推理次数,文本的生成速度会更快;
- 词表增大以后,模型参数量也会增大,然而这对于巨大的模型参数来说不值得一提,推理速度的提升却尤为明显;
4.3 经典问题总结:
"Casual Decoder"和"Prefix Decoder"是两种不同的解码策略,主要应用于序列生成任务,如机器翻译、语音识别等。区别主要体现在处理输入数据和生成输出数据方式上。主要区别如下:

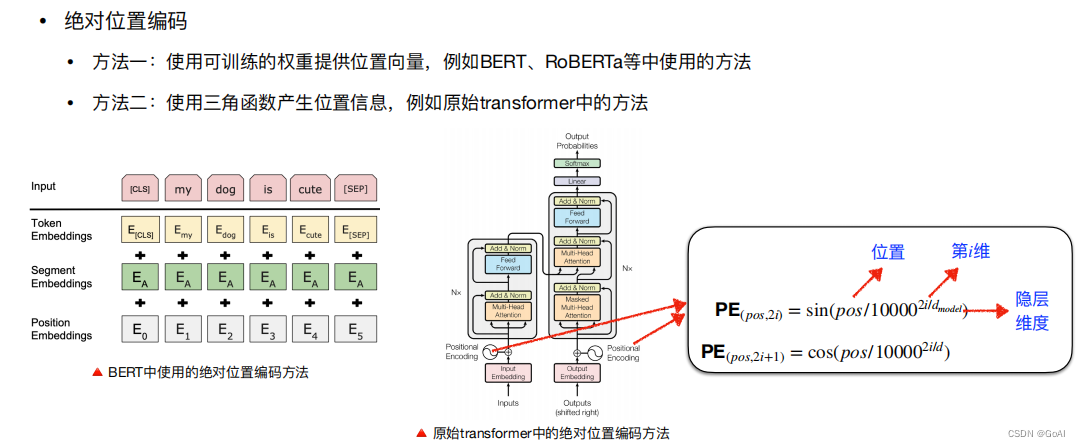
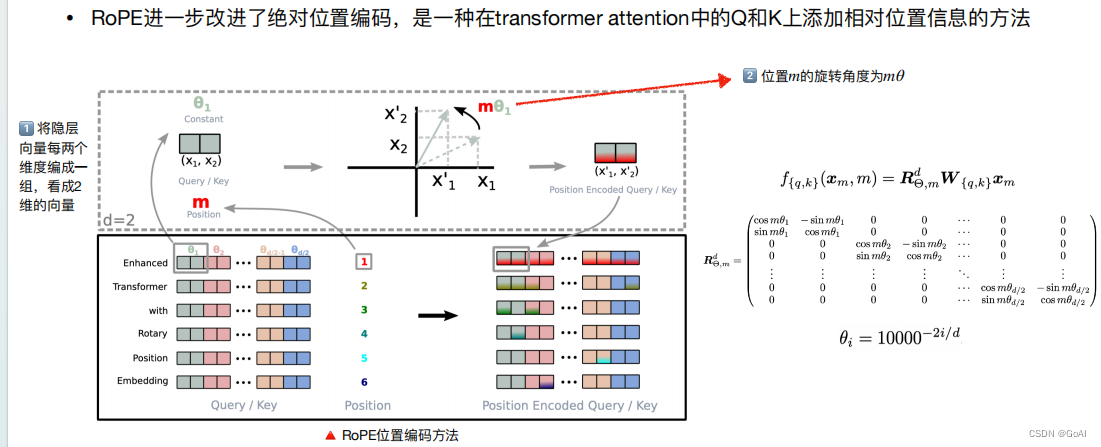
旋转位置编码:
旋转位置向量是用绝对位置编码来表征相对位置编码方法,针对使用 RoPE 位置编码的 LLM,将位置编码压缩,直接缩小位置索引,使得最大位置索引与预训练阶段的上下文窗口限制相匹配。
RoPE的设计思路: 通常会用向量内积来计算注意力系数,如果能够对q、k向量注入了位置信息,然后用更新的q、k向量做内积就会引入位置信息。
训练式的位置编码作用在token embedding上,而旋转位置编码RoPE作用在每个transformer层的self-attention块,在计算完Q/K之后,旋转位置编码作用在Q/K上,再计算attention score。旋转位置编码通过绝对编码的方式实现了相对位置编码,有良好的外推,可直接处理任意长的问题。