文章目录
- 前言
- 一、常用损失函数(后面用到了新的会一一补充)
-
- 1.1 回归中的损失函数
-
- 1.1.1 nn.MSELoss()
-
- 示例1:向量-向量
- 示例2:矩阵--矩阵(维度必须一致才行)
- 1.2 分类中的损失函数
-
- 1.2.1 二分类
-
- (1)nn.BCELoss --- 二分类交叉熵损失函数
-
- 示例1:向量-向量
- 示例2:矩阵--矩阵(维度必须一致才行)
- (2)BCEWithLogitsLoss --- 二分类交叉熵损失函数
-
- 示例1:向量-向量
- 示例2:矩阵--矩阵(维度必须一致才行)
- 1.2.2 多分类
-
- (1)nn.CrossEntropyLoss() --- 多分类交叉熵损失函数
-
- 示例:输出矩阵 --- 目标向量
- 二、正则化技术
- 总结
前言
本博客主要简要记录一下对pytorch内置损失函数的一些理解和正则化技术在pytorch里面是怎么调用的。
一、常用损失函数(后面用到了新的会一一补充)
1.1 回归中的损失函数
1.1.1 nn.MSELoss()
示例1:向量-向量
import torch
import torch.nn as nn
# 创建一个简单的例子,假设有5个样本
outputs = torch.tensor([[0.9],
[0.8],
[0.7],
[0.6],
[0.5]])
# 真实标签,假设每个样本的目标值
targets = torch.tensor([[1],
[0.8],
[0.6],
[0.4],
[0.2]], dtype=torch.float32)
# 创建 MSE Loss 实例,默认情况下计算所有数据点的平均损失
criterion_mean = nn.MSELoss()
# 计算损失
loss_mean = criterion_mean(outputs, targets)
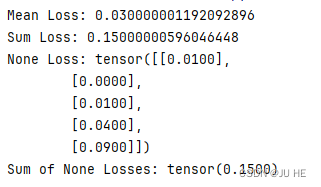
print("Mean Loss:", loss_mean.item())
# 设置 reduction 参数为 'sum',计算所有数据点的损失之和
criterion_sum = nn.MSELoss(reduction='sum')
# 计算损失
loss_sum = criterion_sum(outputs, targets)
print("Sum Loss:", loss_sum.item())
# 设置 reduction 参数为 'none',保持每个数据点的单独损失值
criterion_none = nn.MSELoss(reduction='none')
# 计算损失
loss_none = criterion_none(outputs, targets)
print("None Loss:", loss_none)
print("Sum of None Losses:", loss_none.sum())
输出:
示例2:矩阵–矩阵(维度必须一致才行)
比如在多标签回归中,output就应该是矩阵了,target显然也是矩阵(多标签)
实际上,这段代码中的 input 和 target 都是形状为 (3, 5) 的张量,表示有 3 个样本,每个样本有 5 个输出标签。在均方误差损失函数中,对应位置上的元素会进行相减操作,然后将差的平方求和,最后除以样本数量,得到平均损失。
换句话说,对于每个样本,均方误差损失函数会计算预测值和目标值对应位置上的差的平方,然后对所有位置上的差的平方求和,并求得平均值作为该样本的损失值。然后,对所有样本的损失值再求平均值,得到最终的损失值。
因此,output 是一个标量值,表示所有样本的均方误差损失。
import torch
import torch.nn as nn
loss = nn.MSELoss()
input = torch.randn(3, 5)
target = torch.randn(3, 5)
output = loss(input, target)
print(output)
输出:

【注】:这种操作适用于多标签输出每个标签都采用同一种类型损失函数。如果采用不同类型损失函数就需要再网络设计层过程中做一些处理了,但是这种方法更加灵活。(后面会专门写篇博客演示这个的-----待更新衔接)
1.2 分类中的损失函数
1.2.1 二分类
(1)nn.BCELoss — 二分类交叉熵损失函数
输出层直接用sigmoid激活函数即可。
nn.BCELoss(二元交叉熵损失)是用于二分类问题的损失函数。它的计算步骤如下:
-
将模型的输出视为预测的概率值。对于二分类问题,通常模型的输出是一个单一的概率值,表示正类别的概率。
-
将实际的目标标签视为二进制值,其中1表示正类别,0表示负类别。
-
对于每个样本,
nn.BCELoss会计算预测值与实际标签之间的二元交叉熵损失。损失计算公式如下:
loss = − 1 N ∑ i = 1 N ( y i log ( p